一种基于自然语言生成技术的知识图谱辅助理解系统的制作方法
本发明涉及知识图谱技术领域,尤其涉及一种基于自然语言生成技术的知识图谱辅助理解系统。
背景技术:
知识图谱是一个语义知识库,它通常采用主语-谓语-宾语的三元组形式表示一个知识点,相比较于本体对于逻辑和语义的严苛要求,知识图谱强调了弱语义和弱逻辑,因此在学术界和工业界,知识图谱得到了较好地推广,以谷歌为首的大型互联网公司纷纷开始研究知识图谱以提高搜索的质量。根据2014年的报告显示,目前谷歌的知识图谱已经搜集到了超过16亿的事实,其中2.71亿个事实的真实性被认为超过90%。在2016年5月的google搜索中,知识图谱大约回答了该月1000亿次搜索中的三分之一的问题。
自然语言生成技术是自然语言处理技术的其中一大技术。不同于自然语言理解,自然语言生成技术关注的是计算机如何以自然语言文本来表达给定的含义、思想等。对于知识图谱,尤其是特定领域的知识图谱,其对于实际应用的知识图谱的准确性要求非常高,例如医学相关的知识图谱,其知识图谱的质量严重关系到整个系统的准确性。然而构建知识图谱的编程语言和本体一样,主要是rdf(resourcedescriptionframework,资源描述框架)、owl(webontologylanguage,网络本体语言),采用的软件主要是斯坦福大学开发的protégé等。这些语言和软件专业性强,如果没有经过长期学习和培训,非相关人员很难理解其具体含义。同时以owl和rdf存储的知识点是无序的,同一内容相关的知识点存储在程序的不同部位,这进一步加大了领域专家直接理解知识图谱的源代码的难度。知识图谱大多由计算机行业从事者建立,但使用者则是该知识图谱内容相关的领域的学者和专家,两者的不匹配性导致了领域专家无法理解知识图谱的内容,只能通过使用来进一步完善知识图谱,而不能提前对知识图谱的内容有直观的理解并进行改善。这间接导致了知识图谱质量的不稳定性以及相同内容的知识图谱二次开发现象的严重性。有学者在2017年随机抽取了美国国家生物医学本体中心中的200个生物医学相关的本体,发现在其相应的设计文档中,只有17个得到了专家们的正式评估。
许多领域的知识图谱在使用前需要领域专家对其表示内容进行深入而全面的了解,以便保障其在实际使用过程中的准确性。但知识图谱的相关语言和软件专业性强,相同主题的知识点分布零散,领域专家很难在短期内掌握并了解它们。目前辅助理解知识图谱的软件大多是通过搜索,以可视化的手段呈现不同知识节点的关联,这样呈现的知识是局部知识,且没有涉及到知识图谱本身。同时这些方法都是在知识图谱使用过程中来发现其存在的问题,而没有在其使用之前对其进行全面的了解和评估。
技术实现要素:
本发明的目的是针对于目前知识图谱质量把控不足、领域专家难以理解领域相关的知识图谱的基础上,提出一种基于自然语言生成技术的知识图谱辅助理解系统,本发明根据现实需要,利用自然语言生成技术根据知识图谱的内容生成自然语言文本,并对同一主题的短句进行句子的适当聚合,并且每一个句子都与知识图谱中程序语言一一对应,以方便领域专家在较短时间内对知识图谱进行快速、全面和深入的了解,进行知识图谱质量的把控。
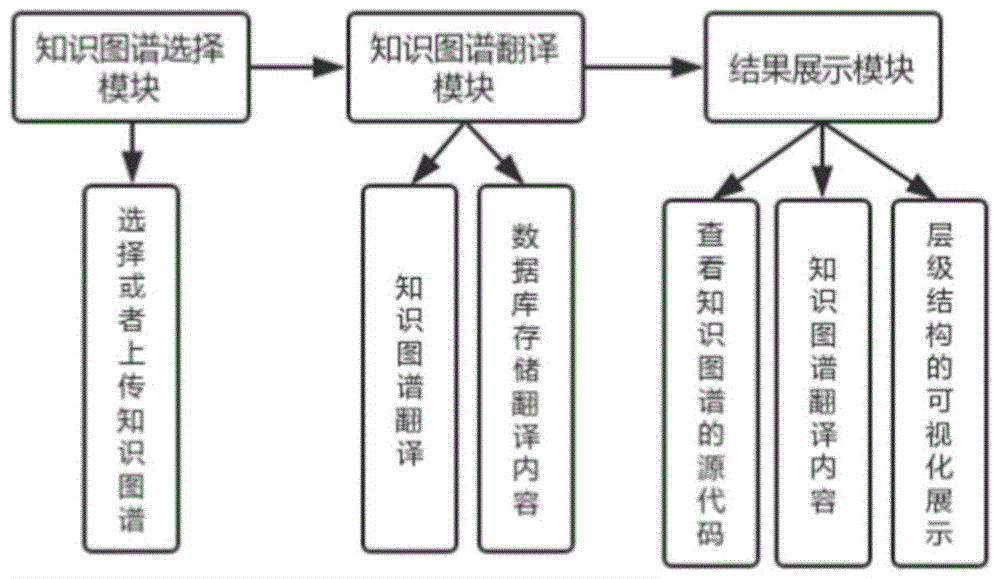
本发明是通过以下技术方案来实现:一种基于自然语言生成技术的知识图谱辅助理解系统,该系统包括知识图谱选择模块、知识图谱翻译模块和结果展示模块;
所述知识图谱选择模块用于获取符合rdf或owl语法规范的目标知识图谱;
所述知识图谱翻译模块:首先提取目标知识图谱的三元组,对提取的三元组进行字符串分割得到三个动态数组:主语数组、谓语数组、宾语数组,三者之间具有一一对应关系,然后通过嵌套循环,利用simplenlg工具对主语、谓语和宾语进行组装,形成一句完整的短句;同时对于主语-谓语-宾语的关系存在一对一对多和一对多对多的情况,在谓语数组和宾语数组中加入特殊字符进行标识,以确定该谓语对应某一主语以及该宾语对应某一主语和某一谓语,然后在嵌套循环中判断这些特殊字符以确定主语、谓语、宾语的对应关系,利用simplenlg工具对对应的主语、谓语和宾语进行组装,形成一个完整的长句;其中注解部分对应的三元组不单独成句,而是作为补充其他句子的注解信息;然后将目标知识图谱翻译成短句和长句,句子得到进一步规范后被存入本地数据库(可以采用mysql数据库)中,并从主语、谓语、宾语三个动态数组中选出类与子类、类与实例关系的内容组装成json格式的文件。
所述结果展示模块从本地数据库调取目标知识图谱的翻译内容(即短句和长句),将翻译内容以及目标知识图谱的源文件(rdf(资源描述框架),owl(网络本体语言))进行共同展示,同时获取json格式的文件,通过可视化工具(可以采用d3工具)绘制树状图,对知识图谱中的类与子类以及类与实例的层级结构进行可视化展示。
进一步地,所述知识图谱选择模块获取目标知识图谱的途径包括两种:
途径一:从开源知识图谱数据库(该系统应用生物医学领域的知识图谱辅助理解时,开源知识图谱数据库可以选择美国国家生物医学本体中心(nationalcenterforbiomedicalontology,ncbo))中爬取符合rdf或owl语法规范的知识图谱,对爬取的知识图谱通过知识图谱翻译模块进行翻译,将翻译结果存入本地数据库中;当用于在系统中搜索某一主题的知识图谱时,输入名称与知识图谱的英文名称进行相似度计算,按相似度从大到小进行排序,得到待选目标知识图谱;
途径二:用户上传符合rdf或owl语法规范的知识图谱作为目标知识图谱。
进一步地,获取目标知识图谱的途径一中,相似度判断系数采用jaccard相似系数(杰卡德系数),它常用于比较有限样本集之间的相似性与差异性,jaccard系数值越大,样本相似度越高。
将用户输入名称的概念集合记为c1,知识图谱英文名称的概念集合记为c2,则两者之间的jaccard相似系数j(c1,c2)为:
如果c1和c2完全相同,则j(c1,c2)值为1;每次搜索结果按照相似度大小排序,呈现相似度较高的n个结果,n为用户自定义。
进一步地,所述知识图谱翻译模块中提取目标知识图谱的三元组的步骤具体如下:利用sparql(sparqlprotocolandrdfquerylanguage,sparql协议和rdf查询语言)提取目标知识图谱中全部知识点(类、实例、对象属性、数据属性、注解等)对应的主语、谓语和宾语,并将其编码成资源描述框架的三元组(rdftriple)。
进一步地,所述知识图谱翻译模块中目标知识图谱的短句生成步骤具体如下:首先对获取的三元组进行字符串分割,获得主语、谓语和宾语的名称,构建三个动态数组。在短句生成中,由于主语、谓语和宾语关系是一对一对一的关系,所以通过嵌套循环,将对应的主语、谓语、宾语利用simplenlg直接组装成短句即可。
进一步地,所述知识图谱翻译模块中目标知识图谱的长句生成的步骤具体如下:首先对获取的三元组进行字符串分割,获得主语、谓语和宾语的名称,构建三个动态数组。在长句生成中,考虑到一个主语可以对应多个谓语,而每个谓语又可以对应多个宾语,因此在谓语数组中,不同主语对应的谓语之间用特殊标识符进行标记;在宾语数组中,不同主语对应的不同谓语的宾语之间采用另一特殊标识符进行标记,实现主语、谓语、宾语的一一对应关系,然后采用嵌套循环,对这些特殊标识符进行判断,将对应的主语、谓语和宾语利用simplenlg进行组装。其中同一主语不同谓语各自构成一个句子,同一主语的所有句子构成一个段落,不同宾语之间用连接词(和、或)进行连接。
进一步地,所述知识图谱翻译模块中目标知识图谱的补充句子的注解信息步骤具体如下:首先对谓语数组进行循环,如果谓语为“comment”(表示宾语为主语的注释),则将对应的主语和宾语提取,形成一个新的动态数组-注解数组,其中奇数下标的数组元素存储主语,偶数下标的数组元素存储宾语。然后进行主语数组、谓语数组和宾语数组的嵌套循环,判断主语、宾语是否在注解数组中,如果存在,则在该主语或者宾语后面添加括号,括号内为其注解,然后判断谓语,如果谓语不是“comment”,则进行组装,否则不组装。
进一步地,所述知识图谱翻译模块中目标知识图谱的短句和长句插入数据库的步骤具体如下:利用jdbc(javadatabaseconnectivity)api进行数据库的连接,首先创建存放翻译结果的数据库以及数据表,定义表名、表字段、确认主键等,然后将知识图谱的英文名称与数据库中存储的名称进行匹配,如果该知识图谱的翻译结果已经存在于知识库中,则不进行插入操作,如果没有,则将生成的短句数组和长句数组添加到数据表中。
进一步地,所述结果展示模块中翻译内容和源文件展示的具体步骤如下:在网页界面中选定目标知识图谱后,利用ajax从数据库中调取该知识图谱对应的所有翻译内容显示在界面上,并且从本地服务器读取目标知识图谱的源文件,共同显示在界面中。
进一步地,所述结果展示模块中可视化展示的具体步骤如下:在网页界面中选定目标知识图谱后,利用ajax获取后端相应的json格式的文件,绘制树状图;在树状图中,每个节点表示主语或者宾语,每个节点通过连线与其他关联的节点进行连接。
本发明的有益效果是:本发明利用自然语言生成技术将知识图谱转换为自然语言文本,方便领域专家在不了解知识图谱的源代码和软件的基础上,在使用知识图谱前,对于其领域的知识图谱有准确、深入且全面的了解。同时每一个短句与知识图谱本身对应的源代码相关联,如果发现知识图谱存在的冗余和错误信息,可以及时对其进行纠正,且该方法通用性较强。本发明利用可视化方法进一步加快领域专家对于知识图谱的理解。
附图说明
图1为本发明基于自然语言生成技术的知识图谱辅助理解系统的结构框图;
图2为本发明基于自然语言生成技术的知识图谱辅助理解系统的实现流程图;
图3为本发明知识图谱翻译模块的自然语言生成流程图;
图4为某一知识图谱的部分源代码示意图;
图5为利用自然语言技术生成的短句示意图;
图6为利用自然语言技术生成的长句示意图;
图7为类与子类的树状图。
具体实施方式
下面结合附图和具体实施例对本发明作进一步详细说明。
如图1、2所示,本发明提供的一种基于自然语言生成技术的知识图谱辅助理解系统,包括知识图谱选择模块、知识图谱翻译模块和结果展示模块;
一、知识图谱选择模块
知识图谱选择模块用于获取符合rdf或owl语法规范的目标知识图谱;获取目标知识图谱的途径包括两种:
途径一:从开源知识图谱数据库(该系统应用生物医学领域的知识图谱辅助理解时,开源知识图谱数据库可以选择美国国家生物医学本体中心(nationalcenterforbiomedicalontology,ncbo))中爬取符合rdf或owl语法规范的知识图谱,对爬取的知识图谱通过知识图谱翻译模块进行翻译,将翻译结果存入本地数据库中;当用于在系统中搜索某一主题的知识图谱时,输入名称与知识图谱的英文名称进行相似度计算,按相似度从大到小进行排序,得到待选目标知识图谱;
相似度判断系数可以采用jaccard相似系数(杰卡德系数),它常用于比较有限样本集之间的相似性与差异性,jaccard系数值越大,样本相似度越高。
将用户输入名称的概念集合记为c1,知识图谱英文名称的概念集合记为c2,则两者之间的jaccard相似系数j(c1,c2)为:
如果c1和c2完全相同,则j(c1,c2)值为1;每次搜索结果按照相似度大小排序,呈现相似度较高的n个结果,n为用户自定义,n可以设置为15。
途径二:用户上传符合rdf或owl语法规范的知识图谱作为目标知识图谱。
二、知识图谱翻译模块
具体流程如图3所示,首先提取目标知识图谱的三元组,对提取的三元组进行字符串分割得到三个动态数组:主语数组、谓语数组、宾语数组,三者之间具有一一对应关系,然后通过嵌套循环,利用simplenlg工具对主语、谓语和宾语进行组装,形成一句完整的短句;同时对于主语-谓语-宾语的关系存在一对一对多和一对多对多的情况,在谓语数组和宾语数组中加入特殊字符进行标识,以确定该谓语对应某一主语以及该宾语对应某一主语和某一谓语,然后在嵌套循环中判断这些特殊字符以确定主语、谓语、宾语的对应关系,利用simplenlg工具对对应的主语、谓语和宾语进行组装,形成一个完整的长句;其中注解部分对应的三元组不单独成句,而是作为补充其他句子的注解信息;然后将目标知识图谱翻译成短句和长句,同时生成的句子需要进一步规范,例如句子开头的英文字母大写,部分名称添加超链接等。规范后的句子被插入本地数据库中,并从主语、谓语、宾语三个动态数组中选出类与子类、类与实例关系的内容组装成json格式的文件。本地数据库可采用mysql数据库,mysql是目前比较流行的一个开源的关系型数据库管理系统,它可以将数据保存在不同的表中,而不是把数据全部放在一个的仓库里,这样就增加了速度。
提取目标知识图谱的三元组的步骤具体如下:利用sparql(sparqlprotocolandrdfquerylanguage,sparql协议和rdf查询语言)提取目标知识图谱中全部知识点(类、实例、对象属性、数据属性、注解等)对应的主语、谓语和宾语,并将其编码成资源描述框架的三元组(rdftriple)。
目标知识图谱的短句生成步骤具体如下:首先对获取的三元组进行字符串分割,获得主语、谓语和宾语的名称,构建三个动态数组。在短句生成中,由于主语、谓语和宾语关系是一对一对一的关系,所以通过嵌套循环,将对应的主语、谓语、宾语利用simplenlg直接组装成短句即可。
目标知识图谱的长句生成的步骤具体如下:首先对获取的三元组进行字符串分割,获得主语、谓语和宾语的名称,构建三个动态数组。在长句生成中,考虑到一个主语可以对应多个谓语,而每个谓语又可以对应多个宾语,因此在谓语数组中,不同主语对应的谓语之间用特殊标识符进行标记;在宾语数组中,不同主语对应的不同谓语的宾语之间采用另一特殊标识符进行标记,实现主语、谓语、宾语的一一对应关系,然后采用嵌套循环,对这些特殊标识符进行判断,将对应的主语、谓语和宾语利用simplenlg进行组装。其中同一主语不同谓语各自构成一个句子,同一主语的所有句子构成一个段落,不同宾语之间用连接词(和、或)进行连接。
目标知识图谱的补充句子的注解信息步骤具体如下:首先对谓语数组进行循环,如果谓语为“comment”(表示宾语为主语的注释),则将对应的主语和宾语提取,形成一个新的动态数组-注解数组,其中奇数下标的数组元素存储主语,偶数下标的数组元素存储宾语。然后进行主语数组、谓语数组和宾语数组的嵌套循环,判断主语、宾语是否在注解数组中,如果存在,则在该主语或者宾语后面添加括号,括号内为其注解,然后判断谓语,如果谓语不是“comment”,则进行组装,否则不组装。
目标知识图谱的短句和长句插入数据库的步骤具体如下:利用jdbc(javadatabaseconnectivity)api,实现java与数据库的连接,首先创建存放翻译结果的数据库以及数据表,定义表名、表字段、确认主键等,然后将知识图谱的英文名称与数据库中存储的名称进行匹配,如果该知识图谱的翻译结果已经存在于知识库中,则不进行插入操作,如果没有,则将生成的短句数组和长句数组添加到数据表中。
三、结果展示模块
结果展示分为三部分。当网页端选中目标知识图谱或者在网站上传目标知识图谱时,通过ajax会将该文件或者参数递交给后端,文件被传入后端后,其源代码会显示在网页上,并自动进行自然语言生成,生成的结果会被插入数据库中,然后从数据库中读取相关内容显示在网页端。同时系统从主语、谓语、宾语三个动态数组中选出类与子类、类与实例关系的内容组装成json格式的文件,传送到前端,并利用可视化工具d3绘制树状图,显示其主要的层级结构。以美国生物医学本体中心公开的一个有关慢性肾病的知识图谱为例,其运行结果如图4-7所示,图7展示了树状图的部分内容。
利用本发明系统,把目标知识图谱上传到网站上或者在网站上选择库中的知识图谱后,系统会自动查询知识图谱里的相关内容,分割字符串,将rdftriple翻译成短句和长句,并进一步规范句式,最后将生成的文本展示给领域专家,其中每一条句子都与其知识图谱的源代码相对应。同时系统对知识图谱中重要的类与子类、类与实例关系以树状图的形式呈现,帮助专家快速理解和掌握该知识图谱的内容和信息,以便在短时间内进行质量的把控。
以上仅为本发明的实施实例,并非用于限定本发明的保护范围。凡在本发明的精神和原则之内,不经过创造性劳动所作的任何修改、等同替换、改进等,均包含在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!