一种基于磁盘队列实现Kafka集群同步的方法及系统与流程
本发明涉及kafka集群技术领域,特别是涉及一种基于磁盘队列实现kafka集群同步的方法及系统。
背景技术:
近年来,随着互联网行业的不断发展,各种业务的数据量不断增多,在大数据处理环境下,类似如股票交易、实时天气预报、网络运维监控、电商实时推荐等推动了storm、s4、sparkstreaming等实时计算框架的部署应用。这些应用对业务系统的水平扩展、数据可靠性要求越来越高,同时系统对实现异步通信,高吞吐率和数据实时性处理要求不断提高,因此kafka的出现就理所当然了,目前,越来越多的开源分布式处理系统都支持与kafka的集成。
kafka是一种分布式消息队列,用于发布和订阅消息。kafka根据主题和分区将数据复制到多个服务器。kafka可以高效处理数据处理,通过批处理和压缩记录有效地使用io。因此越来越多的系统采用kafka作为中间件,将各类数据汇聚到数据湖、大数据应用和实时流分析系统中。在建设多个大数据平台时,实时同步kafka集群可以使多个大数据平台的数据互通和汇聚数据。在此基础上进行数据分析和可视化,为大数据决策提供完整的数据基础。由于kafka集群同步传输介质可能是广域网,在这种情况下,面对网络带宽的制约如何有效利用有限的带宽成为了关注的问题,此外由于数据在各类应用场景中日益重要,如何保证数据传输过程中的完整性,和如何在网络异常情况下保证数据传输的连续性都是值得关注的问题。目前,kafka提供mirrormaker虽然可以实现kafka之间的同步,但是没有考虑数据压缩问题,而数据压缩是提高网络带宽使用率的主要方法,因此实有必要提出一种技术手段,以解决上述问题。
技术实现要素:
为克服上述现有技术存在的不足,本发明之目的在于提供一种基于磁盘队列实现kafka集群同步的方法及系统,以实现一种具有高性能、可压缩、高可靠性、可扩展的kafka同步技术。
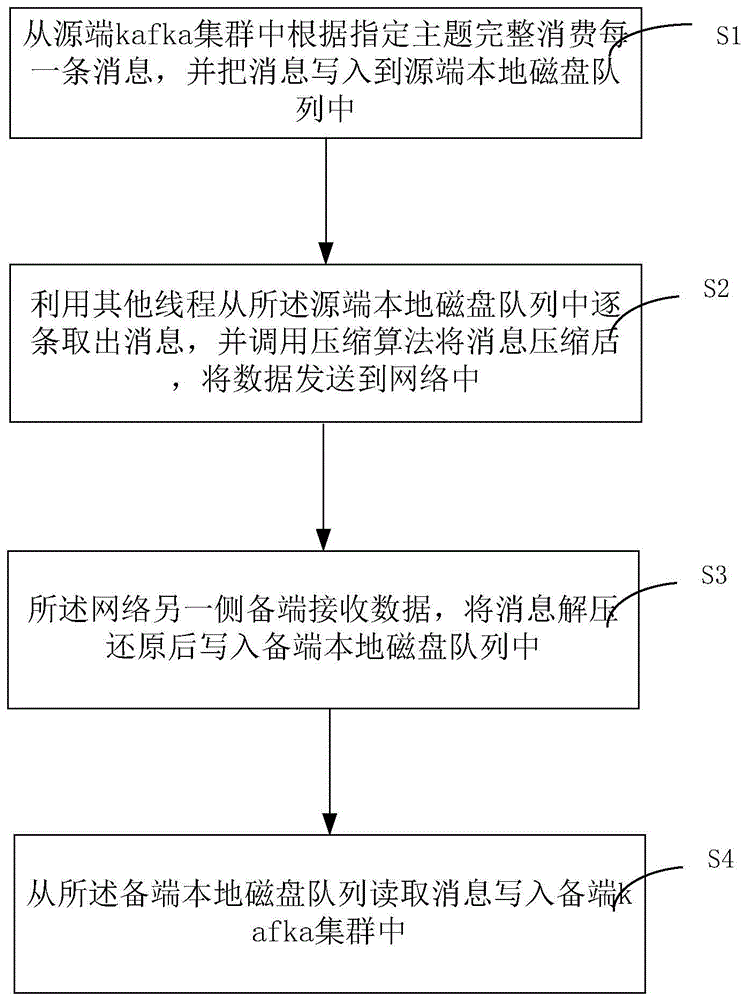
为达上述目的,本发明提出一种基于磁盘队列实现kafka集群同步的方法,包括如下步骤:
步骤s1,从源端kafka集群中根据指定主题完整消费每一条消息,并把消息写入到源端本地磁盘队列中;
步骤s2,利用其他线程从所述源端本地磁盘队列中逐条取出消息,并调用压缩算法将消息压缩后,将数据发送到网络中;
步骤s3,所述网络另一侧备端接收数据,将消息解压还原后写入备端本地磁盘队列中;
步骤s4,从所述备端本地磁盘队列读取消息写入备端kafka集群中。
优选地,于步骤s1中,源端消费者通过所述源端kafka集群提供的生产者应用程序接口,逐条将完整的消息从所述源端kafka集群上消费到本地,将消息逐条写入预先生成的所述源端本地磁盘队列中。
优选地,于步骤s1中将各条消息编写序号逐条写入预先生成的所述源端本地磁盘队列中。
优选地,于步骤s4中,备端生产者从所述备端本地磁盘队列中读取消息写入所述备端kafka集群中。
优选地,所述方法还包括如下步骤:
当网络出现异常时,源端根据其网络异常前发送的消息的序号,于所述源端本地磁盘队列中获得下一条消息,将该序号后的消息重新发送给所述备端,实现断点续传。
优选地,所述方法还包括如下步骤:
当两侧系统出现异常或宕机时,系统重启进程运行后,两侧系统通过协议交互获得之前的传输状态,继续之前的数据传输工作。
优选地,当系统重启进程运行后,所述备端告诉源端其收到的最后一个消息的序号,所述源端根据该序号在所述源端本地磁盘队列中查找下一条消息,并将该序号之后的消息发送给所述源端继续之前的传输工作。
为达到上述目的,本发明还提供一种基于磁盘队列实现kafka集群同步的系统,包括:
源端系统,包括源端kafka集群、源端消费者、源端本地磁盘队列、压缩模块以及发送模块,所述源端消费者从所述源端kafka集群中根据指定主题完整消费每一条消息,并把消息写入到所述源端本地磁盘队列,所述压缩模块利用其它线程从所述磁盘队列中逐条取出消息,调用压缩算法将消息压缩后,由所述发送模块将数据发送到数据网络中;
数据网络,用于所述源端系统与备端系统之间的数据传送交互;
备端系统,包括接收模块、解压模块、备端本地磁盘队列、备端生产者、备端kafka集群,所述接收模块通过所述数据网络接收所述源端系统发送的消息数据,所述解压模块将消息解压还原后写入所述备端本地磁盘队列,所述备端生产者从所述备端本地磁盘队列中读取消息写入所述备端kafka集群中。
优选地,所述源端消费者将各条消息编写序号后逐条写入预先生成的所述源端本地磁盘队列中。
优选地,当所述源端系统与/或备端系统出现异常或宕机时,系统重启进程运行后,两侧系统通过协议交互获得之前的传输状态,继续之前的数据传输工作。
与现有技术相比,本发明一种基于磁盘队列实现kafka集群同步的方法及系统通过kafka提供的生产者应用程序接口,将完整的消息从kafka队列上消费到本地,然后将消息编写序号逐条写入预先生成的磁盘队列中,再有其他线程从磁盘队列中逐条取出消息,并调用压缩算法将消息压缩后发送到网络中,而网络的另一侧接收数据后将消息解压还原写入另一侧本地磁盘队列,备端生产者从磁盘队列中读取消息写入另一侧的kafka中,实现了一种具有高性能、可压缩、高可靠性、可扩展的kafka同步技术。当网络出现异常时,本发明由于两侧都有较长队列,每条消息在队列中编有序号,从而可以实现断点续传;当两侧系统出现异常或宕机时,由于数据都落入磁盘队列完成了持久化操作,系统重启进程运行后就可以继续之前的传输工作,不会产生数据丢失的现象;当源端有大量数据时,两侧的磁盘长队列可以起到削峰,平缓流量的作用。
附图说明
图1为本发明一种基于磁盘队列实现kafka集群同步的方法的步骤流程图;
图2为本发明一种基于磁盘队列实现kafka集群同步的系统的系统架构图;
图3为本发明中基于磁盘队列实现kafka集群同步的具体实施场景示意图。
具体实施方式
以下通过特定的具体实例并结合附图说明本发明的实施方式,本领域技术人员可由本说明书所揭示的内容轻易地了解本发明的其它优点与功效。本发明亦可通过其它不同的具体实例加以施行或应用,本说明书中的各项细节亦可基于不同观点与应用,在不背离本发明的精神下进行各种修饰与变更。
图1为本发明一种基于磁盘队列实现kafka集群同步的方法的步骤流程图。如图1所示,本发明一种基于磁盘队列实现kafka集群同步的方法,包括如下步骤:
步骤s1,从源端的kafka集群中根据指定主题完整消费每一条消息,并把消息写入到本地的磁盘队列。具体地说,源端的消费者通过kafka集群提供的生产者应用程序接口,逐条将完整的消息从kafka集群上消费到本地,然后将消息逐条写入预先生成的磁盘队列中,在本发明具体实施例中,会将各条消息编写序号逐条写入预先生成的磁盘队列中。
步骤s2,利用其他线程从所述磁盘队列中逐条取出消息,并调用压缩算法将消息压缩后,将数据发送到网络中。在本发明具体实施例中,压缩算法可以任意选择,针对不同的网络环境可以根据压缩速率、压缩比选择最优算法,本发明不以此为限。
步骤s3,所述网络另一侧的备端接收数据,将消息解压还原后写入本地磁盘队列。在本发明具体实施例中,解压缩算法也可以任意选择,针对不同的网络环境可以根据压缩速率、压缩比选择最优算法,本发明不以此为限。
步骤s4,从所述本地磁盘队列读取消息写入备端的kafka集群中。具体地说,备端的生产者会从其本地磁盘队列中读取消息写入备端的kafka集群中。
优选地,本发明一种基于磁盘队列实现kafka集群同步的方法,还包括如下步骤:
当网络出现异常时,源端根据其网络异常前发送的消息的序号,在源端本地磁盘队列中获得下一条消息,将该序号后的消息发送给备端实现断点续传。也就是说,由于本发明的源端备端两侧都有较长队列,每条消息在队列中都编有序号,从而可以实现断点续传。
优选地,本发明一种基于磁盘队列实现kafka集群同步的方法,还包括如下步骤:
当两侧系统出现异常或宕机时,由于采用了磁盘队列,数据传输状态做了持久化保存,系统重启进程运行后,两侧系统可以通过协议交互获得之前的传输状态,继续之前的数据传输工作。具体地,由于数据都落入磁盘队列完成了持久化操作,当系统重启进程运行后,就可以通过协议交互获得之前的传输状态,备端告诉源端它收到的最后一个消息的序号,源端根据此序号在磁盘队列中查找下一条消息,并将该序号之后的消息发送给备端继续之前的传输工作。整个传输过程不会由于系统异常产生数据丢失的现象。当源端有大量数据时,两侧的磁盘长队列还可以起到削峰,平缓流量的作用。普通的内存队列虽然可以做到断点续传,但是当出现宕机时,内存中的数据就全部丢失了,无法继续之前的数据传输工作,可见,本发明通过使用磁盘队列,不仅可以处理网络异常,还可以应对主机异常。
图2为本发明一种基于磁盘队列实现kafka集群同步的系统的系统架构图。如图2所示,本发明一种基于磁盘队列实现kafka集群同步的系统,包括:
源端系统20,包括源端kafka集群201、源端消费者202、源端本地磁盘队列203、压缩模块204以及发送模块205,其中源端消费者202从源端kafka集群201中根据指定主题完整消费每一条消息,并把消息写入到源端本地磁盘队列203,压缩模块204利用其它线程从所述磁盘队列中逐条取出消息,调用压缩算法将消息压缩后,由发送模块205将数据发送到数据网络21中。具体地说,源端消费者202通过源端kafka集群201提供的生产者应用程序接口,逐条将完整的消息从源端kafka集群201上消费到源端本地磁盘队列203,并将消息逐条写入预先生成的源端本地磁盘队列203中,在本发明具体实施例中,源端消费者302会将各条消息编写序号逐条写入预先生成的磁盘队列中,然后压缩模块304利用其他线程从源端本地磁盘队列203中逐条取出消息,调用压缩算法将消息压缩,发送模块205则将压缩后的数据发送到数据网络21中。在本发明具体实施例中,压缩算法可以任意选择,针对不同的网络环境可以根据压缩速率、压缩比选择最优算法,本发明不以此为限。
数据网络21,用于源端系统20与备端系统22之间的数据传送交互。
备端系统22,包括接收模块221、解压模块222、备端本地磁盘队列223、备端生产者224、备端kafka集群225,其中,接收模块221通过数据网络21接收源端系统发送的消息数据,解压模块222将消息解压还原后写入备端本地磁盘队列223,备端生产者224从所述备端本地磁盘队列223中读取消息写入备端kafka集群225中。在本发明具体实施例中,解压缩算法也可以任意选择,针对不同的网络环境可以根据压缩速率、压缩比选择最优算法,本发明不以此为限。
在本发明中,当网络出现异常时,源端根据其网络异常前发送的消息的序号,在源端本地磁盘队列中获得下一条消息,将该序号后的消息发送给备端实现断点续传。也就是说,由于本发明的源端备端两侧都有较长队列,每条消息在队列中都编有序号,从而可以实现断点续传。
在本发明中,当两侧系统(源端系统与备端系统)出现异常或宕机时,两侧系统重启进程运行后,两侧系统通过协议交互获得之前的传输状态,继续之前的数据传输工作。在本发明具体实施例中,由于数据都落入磁盘队列完成了持久化操作,当两侧系统重启进程运行后,两侧系统就可以通过协议交互获得之前的传输状态,备端系统告诉源端系统它收到的最后一个消息的序号,源端系统则根据此序号在源端本地磁盘队列中查找下一条消息,并将该序号之后的消息发送给备端系统继续之前的传输工作。整个传输过程不会由于系统异常产生数据丢失的现象。当源端有大量数据时,两侧的磁盘长队列还可以起到削峰,平缓流量的作用。
图3为本发明中基于磁盘队列实现kafka集群同步的具体实施场景示意图。在该实施例中,源端的kafka集群有不同的生产者,数据被消费到同侧的大数据平台,kafka集群镜像系统作为另一各消费者同时从源端kafka集群消费,消费后的消息通过磁盘队列和数据压缩被高效可靠的传送到另一侧(备端);备端的kafka集群有自己的生产者,同时也被写入了来自源端的消息,备端的大数据平台,既获得了源端的生产消息,又获得了本地的生产消息,达到了汇聚两侧生产信息的目的,备侧的大数据平台,在数据完备的基础上,可以进行数据分析和可视化展示。
当系统有扩展化需求时,利用相同的原理可以将更多的kafka集群上的数据汇聚到同一kafka集群上。从而实现系统的扩展。
综上所述,本发明一种基于磁盘队列实现kafka集群同步的方法及系统通过kafka提供的生产者应用程序接口,将完整的消息从kafka队列上消费到本地,然后将消息编写序号逐条写入预先生成的磁盘队列中,再有其他线程从磁盘队列中逐条取出消息,并调用压缩算法将消息压缩后发送到网络中,而网络的另一侧接收数据后将消息解压还原写入另一侧本地磁盘队列,备端生产者从磁盘队列中读取消息写入另一侧的kafka中,实现了一种具有高性能、可压缩、高可靠性、可扩展的kafka同步技术。当网络出现异常时,本发明由于两侧都有较长队列,每条消息在队列中编有序号,从而可以实现断点续传;当两侧系统出现异常或宕机时,由于数据都落入磁盘队列完成了持久化操作,系统重启进程运行后就可以继续之前的传输工作,不会产生数据丢失的现象;当源端有大量数据时,两侧的磁盘长队列可以起到削峰,平缓流量的作用。
上述实施例仅例示性说明本发明的原理及其功效,而非用于限制本发明。任何本领域技术人员均可在不违背本发明的精神及范畴下,对上述实施例进行修饰与改变。因此,本发明的权利保护范围,应如权利要求书所列。
- 还没有人留言评论。精彩留言会获得点赞!