一种基于神经网络的毫米波雷达与视觉协同目标检测与识别方法与流程
本发明涉及传感器融合进行目标识别和定位领域,具体地说是一种基于神经网络的毫米波雷达与视觉协同目标检测与识别方法。
背景技术:
目前,公知的图像目标识别和定位算法主要是利用神经网络直接对图像进行处理,主要有rcnn系列,yolo系列,ssd等。这些神经网络的处理方法主要分两种:一种是通过穷举搜索或者神经网络结构提取图像上的感兴趣区域,随后将感兴趣区域送入神经网络进行位置回归和种类识别;另一种是使用神经网络直接对整张图像中的目标位置和类别进行回归。前者获取感兴趣区域步骤占用大量时间,成为目标检测算法的主要时间瓶颈;后者在识别小物体时精度较低,容易产生漏检现象。
技术实现要素:
针对现有单传感器进行图像目标识别和定位方法的不足,本发明提供了一种基于神经网络的毫米波雷达与视觉协同目标检测与识别方法,将毫米波雷达获得的位置信息映射到图像获得感兴趣区域,借助当前先进的深度学习图像处理技术,达到既快又准地检测图像中目标的位置和距离信息的目的。
本发明为实现上述目的所采用的技术方案是:
一种基于神经网络的毫米波雷达与视觉协同目标检测与识别方法,其特征在于:包括以下步骤:
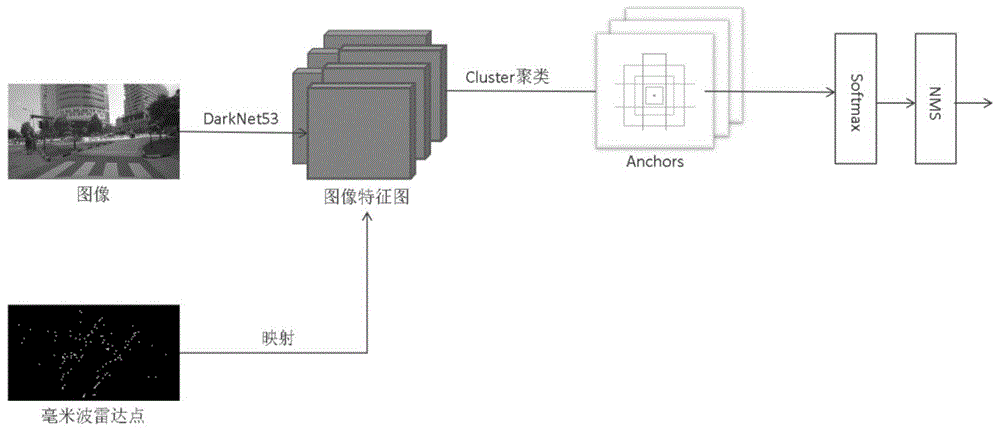
s1:毫米波雷达扫描获得点云数据,相机获取视觉图像信息;
s2:将所述的图像信息缩放至256x256像素大小,并送入darknet-53网络结构进行处理获得特征图;
s3:将毫米波点云映射到所述的s2的图像特征图中,得到每个毫米波点在图像特征图中的位置;
s4:设定先验框大小;
s5:在s3获得的每个位置上按照s4的所述的先验框大小划定感兴趣区域,并计算每个框的特征值;
s6:将s5的感兴趣区域送入神经网络softmax层进行处理,获得图像中目标的定位和识别结果;
s7:对s6中获得的所有目标识别框进行非极大值抑制处理,获得最终目标定位框和每个框的识别结果。
进一步地,所述的s3的将毫米波点云映射到所述的s2的图像特征图中的具体步骤如下:
某毫米波点坐标为p=[x;y;z;1],其对应的图像坐标为p=[u;v],中间坐标值m=[a;b;c],此时图像和毫米波的大小为3x4标定矩阵为h,其中
m=hp
u=a/c
v=b/c
h即毫米波点云坐标系和相机图像坐标系间的空间标定矩阵,通过相机内参矩阵及两坐标系间的旋转平移关系即可确定。
图像到darknet53最后一个特征图间的缩放倍数s,毫米波点p在特征图中的坐标为f,其中
f=p/s
进一步地,所述的先验框大小通过kmeans聚类算法对真实目标定位框进行聚类得到,具体步骤为:
s4.1:选用带有标注框作为真实值的检测数据集作为聚类原始数据,该检测集中的每一个真实值标框即为一个样本;
s4.2:首先选定k个框的高和宽作为聚类中心;
s4.3:通过下式计算每个标注框与每个聚类中心的距离d,并将每个标注框分配给距离d最近的聚类中心;
d=1–iou
其中,iou为所述的标注框与所述的聚类中心的左上角点重合后的交并比;
s4.4:所有标注框分配完毕后,对每个簇重新计算聚类中心,即求该簇中所有标注框的高和宽的平均值;
s4.5:重复s4.3-s4.4,直到聚类中心不再改变;最终聚类出的k个聚类中心的高和宽即为所述的先验框的大小。
进一步地,所述的s5的具体步骤如下:
s5.1:以s3获得的每个毫米波点在图像特征图中的坐标f为中心点,根据s4聚类出的先验框大小在图像特征图上圈定感兴趣区域;
s5.2:计算每个先验框单元网格的中心点位置;
s5.3:计算中心点的特征值,并将该值作为所在单元网格的特征值。
进一步地,所述的s5.3中,采用双线性插值的方法计算中心点的特征值。
本发明的有益效果是,
本发明采用传感器融合的方式,使用毫米波雷达获得的点云数据直接定位图像中的感兴趣区域,并借助深度学习神经网络对目标位置和种类进行进一步的回归。一方面利用毫米波提供的位置信息大大缩减了感兴趣区域的提取时间,另一方面保留了目标检测算法的精度,减少小物体漏检现象的产生。
附图说明
图1是本发明的方法流程图;
图2是darknet-53的网络结构图;
图3是毫米波点映射到图像特征图提取先验框的示意图;
图4是采用本发明的方法识别人的结果图。
具体实施方式
下面根据附图和优选实施例详细描述本发明,本发明的目的和效果将变得更加明白,应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
图1是本发明的算法流程图。
毫米波雷达发射高频毫米波,经过目标反射后被接收系统收集,通过测频来确定目标的距离,从而形成点云数据。将同一时刻相机捕捉到的图像数据缩放至256x256大小后,送入darknet-53网络结构中进行处理,得到大小为n×n×c的图像特征图。如图2是darknet-53的网络结构图。
接下来将点云数据和图像数据进行配准,首先利用工具对雷达和相机所处坐标系进行调整,使其坐标轴之间尽量相互平行,没有夹角误差,然后对相机的内外参以及两个坐标系之间的距离进行标定,最后根据图像坐标系与点云坐标系之间的关系,进行坐标轴转换,将毫米波点云坐标转换为图像坐标。
具体转换关系为:
(x,y,z,1)为点云坐标系下的坐标,(xc,yc,zc)为相机坐标系下的坐标,(u,v)为相应的图像坐标,dx,dy为像素的物理尺寸,f是焦距,(u0,v0)为相机光心在图像坐标系下的坐标,r和t为相机坐标系和点云坐标系之间的旋转和平移矩阵。则有等式:
得到毫米波点云在图像上的坐标后,接下来进一步求得毫米波点云在图像特征图上的坐标。s为经过darknet-53后特征图相比于图像的缩放倍数,则毫米波点(x,y,z,1)在特征图上的坐标为(u/s,v/s,1)
选用有标注框作为真实值的检测数据集作为聚类原始数据,该检测集中的每一个真实值标框即为一个样本,使用两个标注框间的交并比作为距离衡量标准,kmeans作为聚类算法,对所有真实标注框进行聚类,聚类中心即为本算法的先验框的大小。
由上述步骤已得毫米波点在图像特征图的位置以及先验框的大小,如图3是毫米波点映射到图像特征图提取先验框的示意图,其中8x8网格表示图像特征图,2x2网格表示以毫米波映射点为中心,聚类出高和宽为框大小画出的先验框,计算每个先验框的网格中心点后,随后使用双线性插值法计算该位置的特征值,并把该值作为中心点所在网格的特征值。
将上述步骤中获得的框送入深度学习神经网络中的softmax层进行回归,获得每个框的准确位置和类别,随后通过极大值抑制算法对所有标注框进行筛选,获得最终结果,即图像上所有目标的定位和识别结果,如图4所示,给出了识别人的结果。
本领域普通技术人员可以理解,以上所述仅为发明的优选实例而已,并不用于限制发明,尽管参照前述实例对发明进行了详细的说明,对于本领域的技术人员来说,其依然可以对前述各实例记载的技术方案进行修改,或者对其中部分技术特征进行等同替换。凡在发明的精神和原则之内,所做的修改、等同替换等均应包含在发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!