一种方位角可控的SAR目标图像生成方法与流程
本发明属于sar目标图像生成技术领域,具体涉及一种方位角可控的aer目标图像生成方法。
背景技术:
sar在地球遥感、海洋研究、资源勘探、灾情预报和军事侦查等领域有广泛的应用。在随着sar的欺骗技术和sar图像的解译技术研究的进行,常常面临sar图像数据集不足的问题。sar图像使用实测的方法进行产生的成本太高,现在sar图像的解译技术常常用到深度学习算法,深度学习的训练需要大量的数据集作为模型的训练集。所以在实践中常常需要人为的扩充数据集。
目前图像生成模型也有很多的研究,例如生成对抗网络等深度的提出,就给图像的生成的研究带来了很大的突破。在研究中,使用深度卷积生成对抗网络(dcgan)等算法去生成sar图像可以很轻易的得到比较逼真的sar图像,但是这种算法所产生sar目标图像方位角指向是随机的,不可控制,要得到指定方位角的sar图像需要先使用该算法产生大量的sar图像然后再使用方位角判别器进行判别,从而获得想要的方位角的sar图像。条件生成对抗网络(cgan)是将生成对抗网络和条件控制相结合的深度生成模型,该算法是在生成模型和判别模型中均引入条件,这种将条件加入到原始gan模型中,就可以令gan的生成模型在条件的控制下产生数据。
研究的sar目标的方位角,其取值范围[0-359],对于希望利用方位角标签去指导cgan产生特定方位角的sar图像,需要对方位角特征进行编码,机器学习中常见的特征编码方式有labenconding和one-hotencoding两种。但是这两种编码在cgan可控生成sar图像时,cgan都无法收敛到理论的纳什平衡状态,同时基于labenconding特征编码方法训练的cgan模型产生的sar图像的方位角不准确,基于one-hotencoding的方位角标签维度为360,其维度较高,需要使用维度更高的噪声。其中,基于这种不足本发明针对sar目标方位角的特征提出一种新的标签编码方式n-progressive编码方法解决cgan中方位角编码的问题。
技术实现要素:
针对现有技术中的上述不足,本发明提供的方位角可控的sar目标图像生成方法解决了背景技术中的上述问题。
为了达到上述发明目的,本发明采用的技术方案为:一种方位角可控的sar目标图像生成方法,包括以下步骤:
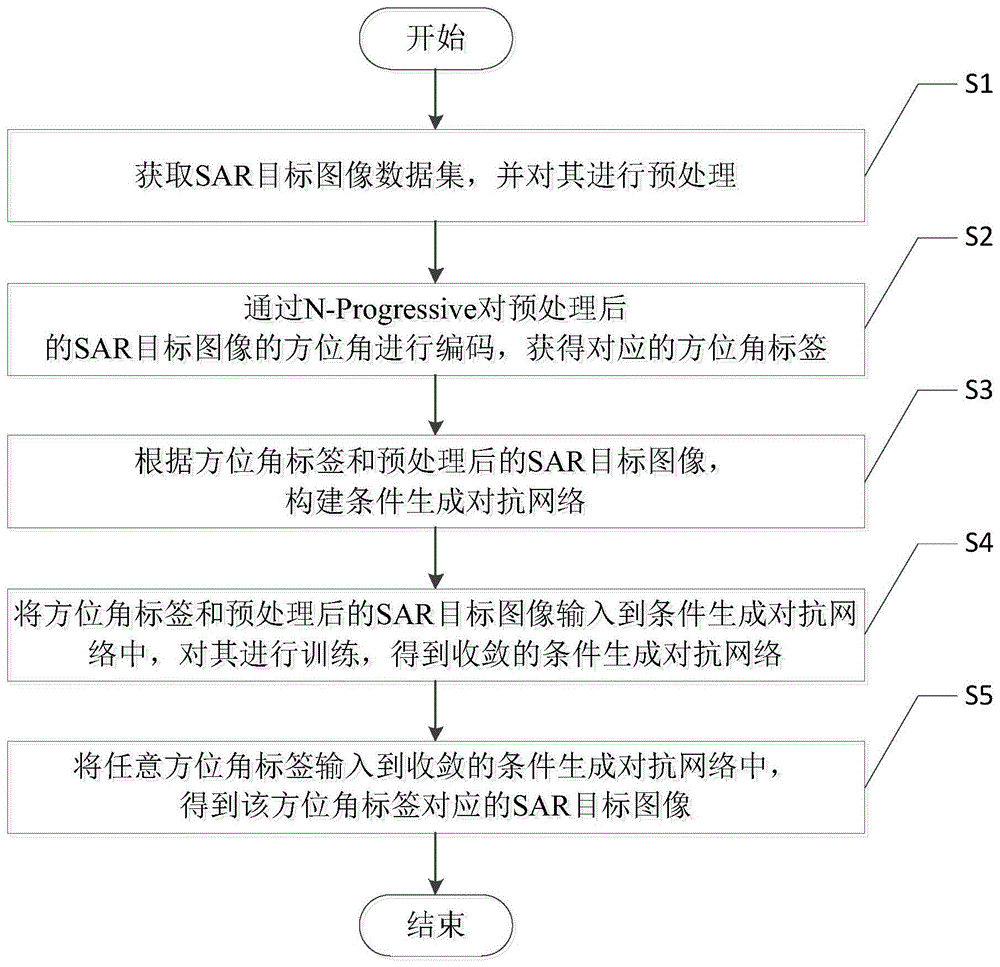
s1、获取sar目标图像数据集,并对其进行预处理;
s2、通过n-progressive对预处理后的sar目标图像的方位角进行编码,获得对应的方位角标签;
s3、根据方位角标签和预处理后的sar目标图像,构建条件生成对抗网络;
s4、将方位角标签和预处理后的sar目标图像输入到条件生成对抗网络中,对其进行训练,得到收敛的条件生成对抗网络;
s5、将任意方位角标签输入到收敛的条件生成对抗网络中,得到该方位角标签对应的sar目标图像。
进一步地,所述步骤s1具体为:
将sar目标图像数据集中的各sar目标图像转换为单通道的灰度图像,并将其大小调整为128×128×1。
进一步地,所述步骤s2具体为:
s21、在预处理后的sar目标图像中,将0-359度的方位角以60度的标签范围进行one-hot编码,获得第一组6位标签;
s22、将第一组6位标签中的每位标签内的方位角以10度的标签范围进行one-hot编码,获得第二组6为标签;
s23、将第二组6位标签中的每位标签内的方位角以1度的标签范围进行one-hot编码,获得10位标签;
s24、将第一组6位标签、第二组6为标签和10位标签拼接起来,使维度为22的one-hot编码表示变化范围为0-359度的方位角;
s25、将每个方位角对应的one-hot编码作为对应的方位角标签。
进一步地,所述步骤s3中的条件生成对抗网络包括相互连接的生成模型和判别模型;
进一步地,所述生成模型对输入数据生成图像的处理方法具体为:
a1、产生一个100维的均匀噪声,并将其与sar目标图像的方位角标签进行拼接;
a2、将拼接后的数据经过一个全连接神经网络后,变换成对应的16×16×128的数据矩阵;
a3、将16×16×128的数据矩阵经过三层反卷积神经网络,生成对应的128×128×1的fake图像;
进一步地,所述判别模型对输入图像处理的方法具体为:
b1、将fake图像和预处理后的sar目标图像经过一层卷积层,将其转换为64×64×16的数据矩阵;
b2、将64×64×16的数据矩阵与方位角标签进行拼接;
b3、将拼接后的数据经过三层卷积层转换为8×8×64的矩阵,然后通过一个全连接层;
b4、将全连接层的输出作为判别模型的判别输出。
进一步地,所述条件生成对抗网络的目标函数带有条件概率的极小极大值博弈;
所述目标函数为:
式中,
v(d,g)为条件生成对抗网络的目标函数;
进一步地,所述生成模型的损失函数lossg为:
式中,n_fake为生成样本的数量;
i为采样次数;
d(g(z|y)i|y)为第i次采样时,方位角标签为y时生成模型产生的生成样本在判别模型中的判别结果;
g(z|y)i为第i次采样时,方位角标签为y时生成模型生成的生成样本;
所述判别模型的损失函数lossd为:
式中,
n_real为真实样本的数量;
d(xi|y)为第i次采样时取出的真实样本的判别模型的损失值。
进一步地,所述步骤s4中对条件生成对抗网络进行训练的方法为:
将sar目标图像和所有方位角标签输入到条件生成对抗网络中,交替训练判别模型和生成模型,直到达到纳什平衡的条件生成对抗网络收敛状态。
本发明的有益效果为:
(1)通过cgan算法训练sar目标图像,当模型收敛后可以直接生成可控方位角的sar图像,不需要方位角判别器进行筛选。
(2)n-progressive编码可以解决cgan训练过程中模型崩溃的情况,同时使用n步递进编码产生的sar目标图像的方位角更准确。
(3)当cgan模型收敛后,可以快速的产生大量的sar目标图像,不需要再提取sar图像特征。
附图说明
图1为本发明提供的方位角可控的sar目标图像生成方法流程图。
图2为本发明中条件生成对抗网络构建结构图。
图3为本发明提供的实施例中基于n-progressiveencoding的cgan的判别模型和生成模型的损失值变化示意图。
图4为本发明提供的实施例中基于n-progressiveencoding的cgan产生的sar图像。
图5为本发明提供的实施例中基于labelencoding的cgan的判别模型和生成模型的损失值变化。
图6为本发明提供的实施例中基于labelencoding的cgan产生的sar图像。
图7为本发明提供的实施例中基于one-hotencoding的cgan的判别模型和生成模型的损失值变化。
图8为本发明提供的实施例中基于one-hotencoding的cgan产生的sar图像。
图9为本发明提供的实施例中n-progressiveencoding产生的60°,220°,300°方位角的sar图像与真实图像对比示意图。
具体实施方式
下面对本发明的具体实施方式进行描述,以便于本技术领域的技术人员理解本发明,但应该清楚,本发明不限于具体实施方式的范围,对本技术领域的普通技术人员来讲,只要各种变化在所附的权利要求限定和确定的本发明的精神和范围内,这些变化是显而易见的,一切利用本发明构思的发明创造均在保护之列。
如图1所示,一种方位角可控的sar目标图像生成方法,包括以下步骤:
s1、获取sar目标图像数据集,并对其进行预处理;
本发明中的sar目标图像数据集为美国空军实验室mstar数据集中的t72图像,在对其进行预处理时:将sar目标图像数据集中的各sar目标图像转换为单通道的灰度图像,并将其大小调整为128×128×1。
s2、通过n-progressive对预处理后的sar目标图像的方位角进行编码,获得对应的方位角标签;
s3、根据方位角标签和预处理后的sar目标图像,构建条件生成对抗网络;
s4、将方位角标签和预处理后的sar目标图像输入到条件生成对抗网络中,对其进行训练,得到收敛的条件生成对抗网络;
s5、将任意方位角标签输入到收敛的条件生成对抗网络中,得到该方位角标签对应的sar目标图像。
上述步骤s2中n-progressive设计思想就是先将标签以一个大的范围划分为多个小标签,将这些小标签以one-hot的编码方法进行编码,然后在这个标签范围上再取一个更小标签范围继续划分,以此类推逐步细化,最后将所有标签的编码结果连接在一起。因此上述步骤s2具体为:
s21、在预处理后的sar目标图像中,将0-359度的方位角以60度的标签范围进行one-hot编码,获得第一组6位标签;
上述过程对应的6位标签如表1所示;
表1:0-359度的方位角和第一组6位标签的转换结果
s22、将第一组6位标签中的每位标签内的方位角以10度的标签范围进行one-hot编码,获得第二组6为标签;
上述过程对应的6位标签如表2所示:
表2:0-60度的方位角和第二组6位标签的转换结果
s23、将第二组6位标签中的每位标签内的方位角以1度的标签范围进行one-hot编码,获得10位标签;
上述过程对应的10位标签如表3所示:
表3:0-9度的方位角和10位标签的转换结果
s24、将第一组6位标签、第二组6为标签和10位标签拼接起来,使维度为22的one-hot编码表示变化范围为0-359度的方位角;
经过步骤s21-s24获得的n-progressiveencoding的方位角和标签的转换结果如表4所示:
s25、将每个方位角对应的one-hot编码作为对应的方位角标签。
经过上述方位角编码过程,可以抽象的增加相邻角度的训练样本,当目标角度变化较小时,前几位标签是保持不变的,比如前12位标签是相同的,后10位变化时,目标的方位角变化范围是10度,这样前12位的标签可以使用10度范围的数据,整个22位就能区分出每一度的变化。这样既能控制目标的角度又能增加相邻角度的训练样本增强模型的稳定性。
上述步骤s3中的条件生成对抗网络如图2所示,包括相互连接的生成模型和判别模型;
生成模型对输入数据生成图像的处理方法具体为:
a1、产生一个100维的均匀噪声,并将其与sar目标图像的方位角标签进行拼接;
a2、将拼接后的数据经过一个全连接神经网络后,变换成对应的16×16×128的数据矩阵;
a3、将16×16×128的数据矩阵经过三层反卷积神经网络,生成对应的128×128×1的fake图像;
判别模型对输入图像处理的方法具体为:
b1、将fake图像和预处理后的sar目标图像经过一层卷积层,将其转换为64×64×16的数据矩阵;
b2、将64×64×16的数据矩阵与方位角标签进行拼接;
b3、将拼接后的数据经过三层卷积层转换为8×8×64的矩阵,然后通过一个全连接层;
b4、将全连接层的输出作为判别模型的判别输出。
在上述构建条件生成对抗网络中,方位角标签被同时加入到生成模型和判别模型中,前一层输出的原始数据都会联合方位角标签形成新的信息传递到下一层。故条件生成对抗网络可以表示为带有条件概率的极小极大值博弈;
所述目标函数为:
式中,
v(d,g)为条件生成对抗网络的目标函数;
生成模型的目标是能够生成欺骗判别模型的样本,因此生成模型的损失函数lossg为:
式中,n_fake为生成样本的数量;
i为采样次数;
d(g(z|y)i|y)为第i次采样时,方位角标签为y时生成模型产生的生成样本在判别模型中的判别结果;
g(z|y)i为第i次采样时,方位角标签为y时生成模型生成的生成样本;
上述判别模型的目标是将输入的真实样本标记为真,输入的生成样本标记为假,故在判别模型中会有两个损失值:其一为将真实样本标记为假的损失,其二为将生成样本标记为真的损失;因此,判别模型的损失函数lossd为:
式中,
n_real为真实样本的数量;
d(xi|y)为第i次采样时取出的真实样本的判别模型的损失值。
上述步骤s4中对条件生成对抗网络进行训练的方法为:
将sar目标图像和所有方位角标签输入到条件生成对抗网络中,交替训练判别模型和生成模型,直到达到纳什平衡的条件生成对抗网络收敛状态。
在上述过程中,本发明通过条件生成对抗网络和n-progressive编码训练sar图像,当模型收敛后可以直接生成可控方位角的sar图像,不需要方位角判别器进行筛选。当cgan模型收敛后,可以快速的产生大量的sar图像,不需要再提取sar图像特征。
在本发明的一个实施例中,提供了利用本发明方法进行可控方位角sar目标图像生成的仿真实例:
在本实施例中,图3和图4为本发明中条件生成对抗网络的训练结果,其中图3为n-progressive编码的cgan模型训练过程中判别模型和生成模型的损失值的变化,图4为基于n-progressive编码的cgan模型产生的sar图像。同时实验对比了基于labelencoding和one-hotencoding两种编码方法的cgan的实验结果如图5、图6、图7和图8所示。
根据生成模型和判别模型的损失函数得到在模型收敛后,生成模型和判别模型的理论值分别为:
g_loss=-log[d(fake)]=-log(0.5)=0.693
d_loss=-[log(d(real))+log(1-d(fake))]
=-[log(0.5)+log(1-0.5)]
=1.386
从图5和图7,可以看到使用label-encoding、one-hotencoding设计的标签的不能很好的稳定在理论值附近,而n-progressiveencoding在收敛后其模型可以稳定在理论值附近,其中四种标签设计方式的生成器和判别器的损失值在[50000-60000]个iteration之间的平均值如下表5所示。通过公式得到d(real)和d(fake)如下:
d(fake)=exp(-(g_loss))
d(real)=exp[-(d_loss)-log(1-d(fake))]=exp[-(d_loss)-log(1-exp(-(g_loss)))]
故计算生成的sar图像和真实sar图像在经过判别器判别为真的概率如表6所示,n-progressiveencoding的判别器判别的真实图像的概率和生成图像的概率都接近0.5,故生成器和判别器收敛在纳什平衡附近,其他两种标签产生的图像都不能欺骗判别器,从而达到纳什平衡。
表1:四种标签设计方式的生成器和判别器的后10000个iteration平均损失值
表2:生成的sar图像和真实sar图像在经过判别器判别为真的概率
从图6、图8和图4可以看到label-encoding产生的图像的质量不高,而且方位角不准确,例如label-encoding产生的图像方位角为10°,50°等的图像方位角明显不正确,而one-hotencoding和n-progressiveencoding产生的图像质量较高,方位角准确。但one-hotencoding的方位角标签维度为360,噪声输入为1000维的噪声,而n-progressiveencoding使用22维方位角标签,和100维的噪声,故n-progressiveencoding标签编码方式既能够准确的产生图像,又能有效的降低标签维度。
n-progressiveencoding标签编码方式产生sar图像与真实图像的t72图像进行对比,其结果图9所示,使用n-progressiveencoding标签编码方式产生sar图像的方位角与真实图像的方位角几乎一致,而且目标轮廓也很接近。
图9(a)中,左图为方位角为60度的真实sar图像,右图为对应的生成图像;图9(b)中,左图为方位角为220度的真实sar图像,右图为对应的生成图像;图9(c)中,左图为方位角为300度的真实sar图像,右图为对应的生成图像。
本发明的有益效果为:
(1)通过cgan算法训练sar目标图像,当模型收敛后可以直接生成可控方位角的sar图像,不需要方位角判别器进行筛选。
(2)n-progressive编码可以解决cgan训练过程中模型崩溃的情况,同时使用n步递进编码产生的sar目标图像的方位角更准确。
(3)当cgan模型收敛后,可以快速的产生大量的sar目标图像,不需要再提取sar图像特征。
- 还没有人留言评论。精彩留言会获得点赞!