一种基于大数据确定疑似侵权数据的方法及设备与流程
本发明涉及企业知识产权保护技术领域,特别涉及一种基于大数据确定疑似侵权数据的方法及设备。
背景技术:
随着互联网技术的飞速发展,在充斥海量信息的网络中,互联网电商知识产权侵权行为也肆意泛滥,如低价/乱价、商标侵权、假货/仿货、虚假授权、不正当竞争、专利侵权等,严重损害了被侵权企业正当利益,因此,如何在海量的数据中监测到上述侵权行为变得尤为重要。
现有技术中一般通过人工在各电商平台检索侵权行为,其检索过程效率低,准确度不高,也有相关的企业知识产权保护平台,但其无法使用户在相关平台自主进行操作,可操作性不好,不能针对企业用户的自身情况确定相应的疑似侵权数据,从而无法有效对企业用户的知识产权进行保护。
技术实现要素:
本发明提供一种基于大数据确定疑似侵权数据的方法,用以解决现有技术中在确定疑似侵权数据时,效率低、准确度不高、可操作性不好的技术问题,该方法应用于b/s结构及mvvm架构的设备中,包括:
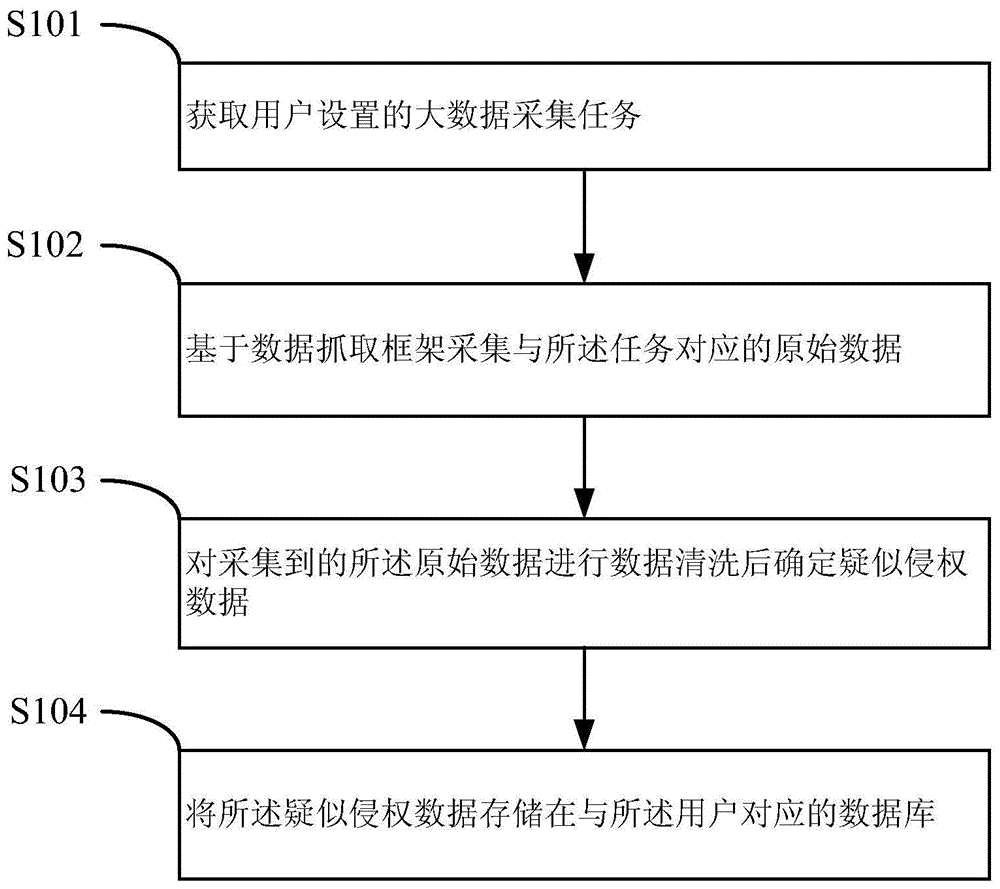
获取用户设置的大数据采集任务;
基于数据抓取框架采集与所述任务对应的原始数据;
对采集到的所述原始数据进行数据清洗后确定疑似侵权数据;
将所述疑似侵权数据存储在与所述用户对应的数据库。
优选的,在获取用户设置的大数据采集任务之前,还包括:
对所述用户进行身份认证;
当所述身份认证通过后授权所述用户登录。
优选的,所述数据抓取框架具体为scrapy框架或pyspider框架,基于抓取框架采集与所述任务对应的原始数据,具体为:
获取与所述任务对应的采集项目及采集平台,其中,所述采集项目具体包括:店铺相关信息、和或产品相关信息,所述采集平台具体包括:微信平台、和或微博平台、和或各电子商务平台;
根据所述采集项目在所述采集平台采集所述原始数据。
优选的,对采集到的所述原始数据进行数据清洗后确定疑似侵权数据,具体为:
对所述原始数据进行数据清洗,获取清洗后的数据,其中,所述数据清洗具体包括:检查一致性,处理无效值和缺失值;
对所述清洗后的数据进行多维度分析后确定所述疑似侵权数据,其中,所述多维度分析至少包括:销售金额分析、销售量分析、产品单价分析以及售后评价分析。
优选的,在将所述疑似侵权数据存储在与所述用户对应的数据库之后,还包括:
将所述疑似侵权数据进行可视化处理后在前端视图展示。
相应地,本发明还提出了一种基于大数据确定疑似侵权数据的设备,所述设备为b/s结构及mvvm架构,包括:
获取模块,用于获取用户设置的大数据采集任务;
采集模块,用于基于数据抓取框架采集与所述任务对应的原始数据;
确定模块,用于对采集到的所述原始数据进行数据清洗后确定疑似侵权数据;
存储模块,用于将所述疑似侵权数据存储在与所述用户对应的数据库。
优选的,还包括认证模块,具体用于:
对所述用户进行身份认证;
当所述身份认证通过后授权所述用户登录。
优选的,所述数据抓取框架具体为scrapy框架或pyspider框架,所述采集模块,具体用于:
获取与所述任务对应的采集项目及采集平台,其中,所述采集项目具体包括:店铺相关信息、和或产品相关信息,所述采集平台具体包括:微信平台、和或微博平台、和或各电子商务平台;
根据所述采集项目在所述采集平台采集所述原始数据。
优选的,所述确定模块,具体用于:
对所述原始数据进行数据清洗,获取清洗后的数据,其中,所述数据清洗具体包括:检查一致性,处理无效值和缺失值;
对所述清洗后的数据进行多维度分析后确定所述疑似侵权数据,其中,所述多维度分析至少包括:销售金额分析、销售量分析、产品单价分析以及售后评价分析。
优选的,还包括展示模块,用于将所述疑似侵权数据进行可视化处理后在前端视图展示。
与现有技术对比,本发明具备以下有益效果:
本发明公开了一种基于大数据确定疑似侵权数据的方法,该方法应用于b/s结构及mvvm架构的设备中,包括:获取用户设置的大数据采集任务;基于数据抓取框架采集与所述任务对应的原始数据;对采集到的所述原始数据进行数据清洗后确定疑似侵权数据;将所述疑似侵权数据存储在与所述用户对应的数据库,通过根据用户设置的采集任务自动确定疑似侵权数据,从而高效地确定与用户自身情况相关地疑似侵权数据,并提高了用户的可操作性。
附图说明
图1为本发明实施例提出的一种基于大数据确定疑似侵权数据的方法的流程示意图;
图2为本发明实施例提出的一种基于大数据确定疑似侵权数据的设备的结构示意图。
具体实施方式
如背景技术所述,现有技术中在确定疑似侵权数据时,效率低、准确度不高、可操作性不好。
为解决上述问题,本申请实施例提出了一种基于大数据确定疑似侵权数据的方法,通过根据用户设置的采集任务自动确定疑似侵权数据,从而高效地确定与用户自身情况相关地疑似侵权数据,并提高了用户的可操作性。
如图1所示为本发明实施例提出的一种基于大数据确定疑似侵权数据的方法的流程示意图,该方法应用于b/s结构及mvvm架构的设备中,包括以下步骤:
s101,获取用户设置的大数据采集任务。
用户在需要确定疑似侵权数据时,会设置相应地大数据采集任务,用户会设置指定采集项目,如产品的相关信息以及店铺的相关信息,用户还可设置指定采集平台,从而获取基于采集项目和采集平台的大数据采集任务,在本申请的具体应用场景中,通过用户在前端视图设置大数据采集任务,从而获取大数据采集任务。
为保证用户操作的合法性,在本申请的优选实施例中,在获取用户设置的大数据采集任务之前,还包括:
对所述用户进行身份认证;
当所述身份认证通过后授权所述用户登录。
如上所述,对用户进行身份认证,并在身份认证通过后授权所述用户登录,用户登录后才能设置大数据采集任务,保证了用户操作的合法性。在本申请的具体应用场景中,每个用户都有一套独立的账户,用户输入正确的账号和密码后即可登录并进行后续操作。可采用oauth(openauthorization,开放授权)身份认证和授权的安全登录方式、也可采用第三方登录认证模式,如微信扫码登录等。
需要说明的是,本领域技术人员可根据实际需要灵活选用不同的身份认证方式,这并不影响本申请的保护范围。
s102,基于数据抓取框架采集与所述任务对应的原始数据。
具体的,由于大数据采集任务对应的原始数据存在于互联网中,可通过数据抓取框架对该原始数据进行采集。
本领域技术人员可根据实际需要选择不同的数据抓取框架进行数据采集。
为采集到与大数据采集任务对应的原始数据,在本申请的优选实施例中,所述数据抓取框架具体为scrapy框架或pyspider框架,基于抓取框架采集与所述任务对应的原始数据,具体为:
获取与所述任务对应的采集项目及采集平台,其中,所述采集项目具体包括:店铺相关信息、和或产品相关信息,所述采集平台具体包括:微信平台、和或微博平台、和或各电子商务平台;
根据所述采集项目在所述采集平台采集所述原始数据。
具体的,在大数据采集任务中包括了用户指定的采集项目和采集平台,采集项目可包括店铺相关信息、产品的相关信息,采集平台可以为微信平台、和或微博平台、和或各电子商务平台,从而根据用户指定的采集项目到指定的采集平台采集原始数据,可利用scrapy框架或pyspider框架的数据采集框架执行大数据采集任务。
需要说明的是,以上优选实施例的方案仅为本申请所提出的一种具体实现方案,其他基于数据抓取框架采集与所述任务对应的原始数据的方式均属于本申请的保护范围。
s103,对采集到的所述原始数据进行数据清洗后确定疑似侵权数据。
具体的,由于采集到的原始数据可能是杂乱无章的,还可能包含无效数据,因此需要对原始数据进行数据清洗后才能确定疑似侵权数据。
为准确从原始数据中确定疑似侵权数据,在本申请的优选实施例中,对采集到的所述原始数据进行数据清洗后确定疑似侵权数据,具体为:
对所述原始数据进行数据清洗,获取清洗后的数据,其中,所述数据清洗具体包括:检查一致性,处理无效值和缺失值;
对所述清洗后的数据进行多维度分析后确定所述疑似侵权数据,其中,所述多维度分析至少包括:销售金额分析、销售量分析、产品单价分析以及售后评价分析。
如上所述,通过对采集的原始数据进行数据清洗,包括检查一致性,处理无效值和缺失值,并对清洗后的数据进行多维度分析,包括销售金额分析、销售量分析、产品单价分析以及售后评价分析,从而准确的确定疑似侵权数据。
需要说明的是,以上优选实施例的方案仅为本申请所提出的一种具体实现方案,本领域技术人员可采用不同的数据清洗方式和不同的多维度分析手段,其他对采集到的所述原始数据进行数据清洗后确定疑似侵权数据的方式均属于本申请的保护范围。
s104,将所述疑似侵权数据存储在与所述用户对应的数据库。
具体的,由于用户是通过身份认证进行登录后操作的,在本申请的具体应用场景中,每个用户都专有与其对应的数据库,将疑似侵权数据存储在与所述用户对应的数据库,从而可使用户可从其专有的数据库中获取疑似侵权数据,保证了用户的可操作性。
为对疑似侵权数据进行展示,在本申请的优选实施例中,在将所述疑似侵权数据存储在与所述用户对应的数据库之后,还包括:
将所述疑似侵权数据进行可视化处理后在前端视图展示。
具体的,在本申请的具体应用场景中,采用微软银光microsoftsilverlight技术将疑似侵权数据进行可视化处理后在前端视图展示,使视图更加细节化、可定制化。本领域技术人员也可采用其他不同的手段对疑似侵权数据进行展示,例如采用前端框架技术angularjs或jquery。
通过应用以上技术方案,获取用户设置的大数据采集任务;基于数据抓取框架采集与所述任务对应的原始数据;对采集到的所述原始数据进行数据清洗后确定疑似侵权数据;将所述疑似侵权数据存储在与所述用户对应的数据库,通过根据用户设置的采集任务自动确定疑似侵权数据,从而高效地确定与用户自身情况相关地疑似侵权数据,并提高了用户的可操作性。
为了进一步阐述本发明的技术思想,现结合具体的应用场景,对本发明的技术方案进行说明。
本申请实施例提供了一种基于大数据确定疑似侵权数据的方法,每个客户都有一套独立的账户密码和大型关系型数据库,客户可以自主的布置采集任务、选定采集平台,数据采集程序读取任务后会在选定的平台上采集数据,将采集的数据进行数据清洗后确定疑似售假数据,再把疑似售假数据存储在客户数据库中,大大减少了因沟通带来的时间成本,也增强了客户粘性。
b/s(browser/server,浏览器/服务器)结构是web(worldwideweb,万维网)兴起后的一种网络结构模式,web浏览器是客户端最主要的应用软件。这种模式统一了客户端,将系统功能实现的核心部分集中到服务器上,简化了系统的开发、维护和使用。客户机上只要安装一个浏览器,服务器安装有数据库。浏览器通过web服务器便可同数据库进行数据交互。
mvvm(model-view-viewmodel,模型-视图-视图模型)的架构具有以下特点:
(1)双向绑定技术,当模型变化时,视图模型会自动更新,视图也会自动变化,从而保持数据的一致性。
(2)视图的功能进一步的强化,具有控制器的部分功能,若想无限增强它的功能,甚至控制器的全部功能几乎都可以迁移到各个视图上。
(3)由于控制器的功能大都移动到视图上处理,从而对控制器进行了瘦身。
(4)可以对视图或视图控制器的数据处理部分抽象出来一个函数处理模型,使它们专职页面布局和页面跳转。
上述方法应用于b/s结构及mvvm架构的设备中,包括以下步骤:
步骤一,对用户进行身份认证,当身份认证通过后可授权用户登录。
具体的,每个用户都有一套独立的账户,用户输入正确的账号和密码后即可登录并进行后续操作。可采用oauth身份认证和授权的安全登录方式,也可采用第三方登录认证模式,如微信扫码登录等。
步骤二、获取用户设置的大数据采集任务。
用户进行登录后,可在前端视图中对大数据采集任务进行设置,如设置采集项目和采集平台,采集项目具体可包括:店铺相关信息、和或产品相关信息,采集平台具体可包括:微信平台、和或微博平台、和或各电子商务平台,从而获取大数据采集任务。
步骤三、利用数据抓取框架采集大数据采集任务对应的原始数据。
获取与所述任务对应的采集项目及采集平台,利用数据抓取框架根据采集项目在采集平台上采集原始数据,数据抓取框架可以为scrapy框架,scrapy框架运行流程如下:
1)、引擎从调度器中取出一个链接url用于接下来的抓取;
2)、引擎把url封装成一个请求request传给下载器;
3)、下载器把资源下载下来,并封装成应答包response;
4)、爬虫解析response;
5)、解析出实体item,则交给实体管道进行进一步的处理;
6)、解析出的是链接url,则把url交给调度器等待抓取。
还可采用pyspider框架作为数据抓取框架,其具体流程为现有技术,在此不再赘述。
步骤四、对采集到的原始数据进行数据清洗后确定疑似侵权数据。
数据清洗时会将采集回来的海量原始数据与用户的官方产品库分别做对比,把杂乱无章的数据分类、检查一致性,处理无效值和缺失值,并对数据清洗后的数据进行人工分析,进行销售总金额、销售量、产品单价、售后评价等多维度分析,最终得出疑似售假数据。
步骤五、将所述疑似侵权数据存储在与所述用户对应的数据库。
每个用户都专有与其对应的数据库,将疑似侵权数据存储在与所述用户对应的数据库,数据库可以是sqlserver(structuredquerylanguageserver,结构化查询语言服务器)或基于分布式文件存储的数据库mogodb。在数据库中可使用大量的视图来支持复查的数据检索查询,可对数据进行批量处理,用户可从其专有的数据库中获取疑似侵权数据,保证了用户的可操作性。
步骤六、将疑似侵权数据进行可视化处理后在前端视图展示。
采用微软银光microsoftsilverlight技术将疑似侵权数据进行可视化处理后在前端视图展示,使视图更加细节化、可定制化。也可采用其他前端框架技术进行数据展示,例如angularjs或jquery。前端视图中还可展示数据概览、假冒地点地图、店铺列表、宝贝列表、数据清洗、监测任务布置、官方产品库设置。
通过应用以上技术方案,对微信、微博及电商平台上的假货进行追踪,在充斥海量信息的网络中锁定侵权行为,不仅能够帮助用户找到侵权线索,还能通过应用交易数据分析,导向制售假不法团伙的目标上下游,最终完成关联目标交易信息的梳理,这改变了互联网维权的业态。
为了达到以上技术目的,本申请实施例还提出了一种基于大数据确定疑似侵权数据的设备,所述设备为b/s结构及mvvm架构,如图2所示,包括:
获取模块201,用于获取用户设置的大数据采集任务;
采集模块202,用于基于数据抓取框架采集与所述任务对应的原始数据;
确定模块203,用于对采集到的所述原始数据进行数据清洗后确定疑似侵权数据;
存储模块204,用于将所述疑似侵权数据存储在与所述用户对应的数据库。
在具体的应用场景中,还包括认证模块,具体用于:
对所述用户进行身份认证;
当所述身份认证通过后授权所述用户登录。
在具体的应用场景中,所述数据抓取框架具体为scrapy框架或pyspider框架,所述采集模块202,具体用于:
获取与所述任务对应的采集项目及采集平台,其中,所述采集项目具体包括:店铺相关信息、和或产品相关信息,所述采集平台具体包括:微信平台、和或微博平台、和或各电子商务平台;
根据所述采集项目在所述采集平台采集所述原始数据。
在具体的应用场景中,所述确定模块203,具体用于:
对所述原始数据进行数据清洗,获取清洗后的数据,其中,所述数据清洗具体包括:检查一致性,处理无效值和缺失值;
对所述清洗后的数据进行多维度分析后确定所述疑似侵权数据,其中,所述多维度分析至少包括:销售金额分析、销售量分析、产品单价分析以及售后评价分析。
在具体的应用场景中,还包括展示模块,用于将所述疑似侵权数据进行可视化处理后在前端视图展示。
通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到本发明可以通过硬件实现,也可以借助软件加必要的通用硬件平台的方式来实现。基于这样的理解,本发明的技术方案可以以软件产品的形式体现出来,该软件产品可以存储在一个非易失性存储介质(可以是cd-rom,u盘,移动硬盘等)中,包括以若干指令的形式使一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本发明各个实施场景所述的方法。
本领域技术人员可以理解附图只是一个优选实施场景的示意图,附图中的模块或流程并不一定是实施本发明所必须的。
本领域技术人员可以理解装置中的模块可以按照实施场景描述分布于实施场景的装置中,也可以进行相应变化位于不同于本实施场景的一个或多个装置中。上述实施场景的模块可以合并为一个模块,也可以进一步拆分成多个子模块。
上述本发明序号仅仅为了描述,不代表实施场景的优劣。
以上公开的仅为本发明的几个具体实施场景,但是,本发明并非局限于此,任何本领域的技术人员能思之的变化都应落入本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!