基于向量自回归模型的结构局部缺陷检测方法与流程
本发明属于结构监控监测领域。
技术背景
结构健康监测(shm)指利用现场的无损传感技术,通过包括结构响应在内的结构系统特性分析,达到检测结构缺陷或退化的目的。其中的缺陷识别是指通过一定的技术和方法,识别结构是否出现缺陷,确定缺陷的位置以及严重程度,为结构的维护与维修提出建议,使得结构能在寿命周期内更好地发挥使用价值。无论是环境振动,还是风荷载与地震荷载,在动态效应对结构产生不利影响并产生灾害性破坏前,能否快速有效地识别缺陷,对于降低经济损失、保证结构使用性能具有重要意义。目前,国内外学者提出了很多缺陷识别方法。
目前缺陷识别方法主要有以下几种类型,传统无损识别技术、基于结构振动响应的缺陷识别方法。传统无损识别技术指以不会破坏结构的方式来检测结构物缺陷现象及其程度的一种检测方法,其借助某种介质,如声,光,电,磁等进行间接的监测,如红外热成像法、超声波法、涡流或温度场法等。基于结构振动响应的缺陷识别方法通过分析结构振动响应获取结构模态特性和物理参数的变化,完成缺陷识别。
传统无损识别技术存在工作量大、耗费高、探伤区域小等诸多局限性:
(1)该方法要求事先知道结构缺陷的大概位置,才能更为有效的完成缺陷的检测;
(2)被检测的部位需要满足检测仪器能够直接接触的要求,导致了其在缺陷检测应用中的局限性;
(3)该方法需要专业设备支撑,但设备往往较为昂贵,难以广泛推广。
基于结构振动响应的缺陷识别方法可以大致分为基于模态驱动的方法和基于数据驱动的方法两种。基于模态驱动的方法通常利用识别得到的频率、振型等模态指标以及模态柔度、模态应变能等衍生指标识别是否发生缺陷以及确定缺陷发生的部位,并可进一步结合模型更新等手段量化缺陷程度。但是该方法具有如下局限:
(1)该方法具有全局属性,对局部缺陷不敏感;
(2)该方法在环境激励下得到的模态指标不确定程度较高;
(3)复杂结构的基准有限元模型较难准确获取。
基于数据驱动的方法多借助自回归模型、小波变换和希尔伯特黄变换等数学模型从结构响应信号中提取缺陷判别指标,然后通过结构缺陷前后指标的统计模式对比实现缺陷识别。基于数据驱动的方法只需要对结构响应信号进行分析,而不需要结构的基准有限元模型,这极大地扩大了其应用范围,同时该类方法对结构的局部缺陷敏感。但是,现有的基于数据驱动的方法大部分仅能判别结构是否出现缺陷,若想确定结构缺陷的位置,则需要做多测定重复计算才能完成,无疑极大地增大了缺陷识别的计算量。
技术实现要素:
本发明针对现有技术的确定,提出了一种基于向量自回归模型的结构局部缺陷识别方法,该方法能够有效的利用结构的振动响应,借助向量自回归模型对结构的振动响应进行分析,能够快速有效地完成结构的局部缺陷识别。
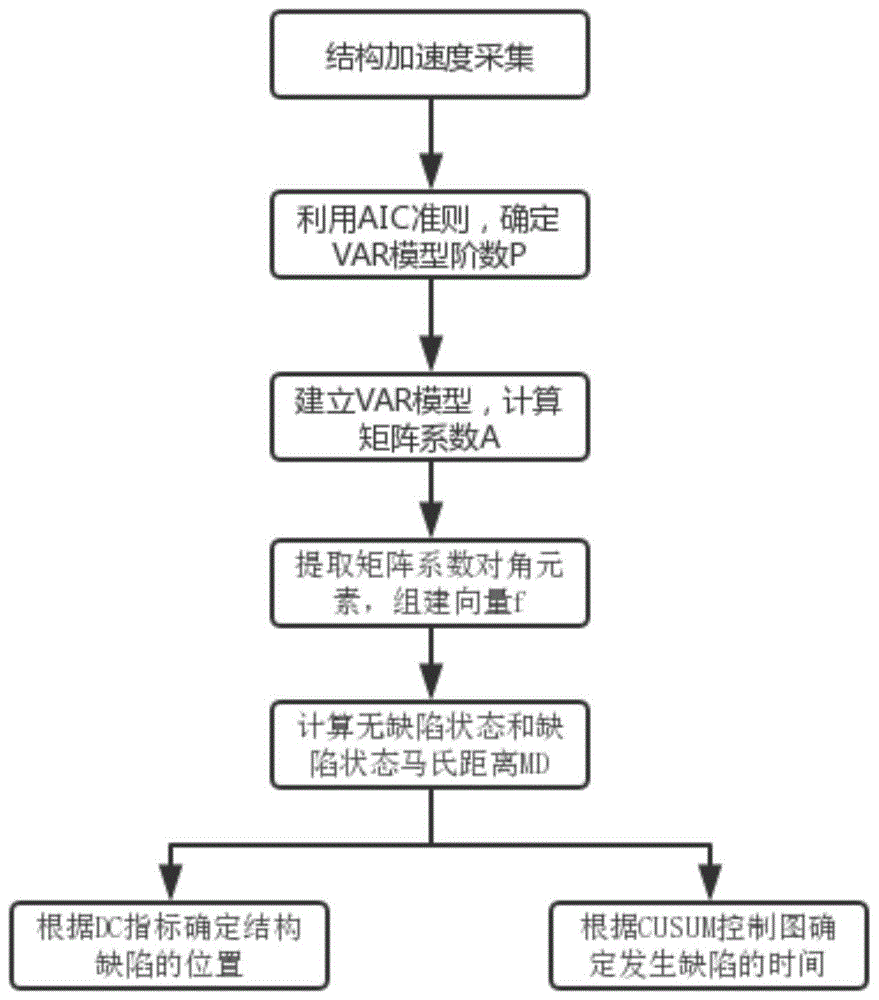
一种基于向量自回归模型的结构局部缺陷识别方法,通过以下步骤实现,包括
步骤一:采集缺陷结构和无缺陷结构的加速度α响应,将采集得到的加速度响应分解成数据长度相同的多个样本,用于后续向量自回归模型(var)的建立;
步骤二:利用aic准则确定步骤一中得到的各个样本的var模型阶数,
步骤三:根据步骤二中确定的var模型阶数,建立各个样本var模型,
步骤四:提取步骤三种各个var模型中系数矩阵的对角元素,并定义全新的特征向量f,
步骤五:根据步骤四中的向量f,分别计算缺陷状态和无缺陷状态的马氏距离,
步骤六:根据步骤五中计算得到的缺陷状态和无缺陷状态的马氏距离进行后续的结构缺陷识别。
所述步骤一中的结构加速度响应是指利用加速度传感器采集结构的加速度响应信号,共涉及无缺陷结构和存在缺陷结构两种结构,将无缺陷结构的加速度响应划分为前后两部分,前半部分定义为参考状态,后半部分定义为无缺陷状态;将存在缺陷结构定义为缺陷状态。随后分别将三种状态的加速度响应划分成数据长度相同的多个样本,用于后续的结构缺陷识别。
所述步骤二中的aic准则于1973年由akaike提出,主要从两个方面考察模型拟合的效果:模型的极大似然函数值和模型中未知参数的个数。似然函数值越大,拟合的效果越好;模型中的未知参数的数量越多,虽模型变化较灵活,但模型参数估计工作量将增大,故需综合这两方面的影响.因此,该准则以提取最大信息量为出发点进行模型阶数的选取,其数学表达式为:
aic=2k-2ln(l)
式中,k是模型参数个数,l是似然函数。从一组可供选择的模型中选择最佳模型时,通常选择aic最小的模型。计算不同阶数下的aic值,选取aic值最小所对应的阶数为模型的最优阶数。
所述步骤三中的var模型通过对多维变量的滞后值进行回归,从而建立起各个变量之间的动态关系。
步骤三是指对步骤一中获得的无缺陷测试状态、参考状态和存在缺陷状态的加速度时程分别建立var模型:
yt=a1yt-1+a2yt-2+…+apyt-p+εt
式中yt={y1t,y2t,…,ykt}t,每次试验均有k个测点;εt是为插值向量,表示数据的整体偏移;ai是k×k阶系数矩阵
所述步骤四中的提取系数矩阵是指提取上述系数矩阵ai中的对角线元素。
所述步骤四中的新向量是指将各系数矩阵中的对角线元素组合成为新向量f1,f2,…,fk
所述步骤五中马氏距离是由印度统计学家马哈拉诺比斯(p.c.mahalanobis)提出的,表示数据的协方差距离。它是一种有效的计算两个未知样本集的相似度的方法。可以按照下式计算:
式中
所述步骤六中结构缺陷识别包括两部分,第一根据dc指标进行结构缺陷位置识别,第二使用cusum控制图来检测马氏距离的突变。
dc指标是衡量有缺陷结构马氏距离和无缺陷结构马氏距离间变化的一个指标,当结构出现缺陷时,即结构刚度特性出现突变,距离缺陷越近测点处的马氏距离将会变化越明显,也就是dc指标将会越高。故采用dc指标可以作为识别结构缺陷位置的指标。
式中
cusum控制图是指一种时间加权控制图,显示每个样本值与目标值的偏差的累积和。通常cusum控制图分为参数化和非参数化,在实际应用中由于难以对参数进行估计,特别是获取信号的概率分布比较难时,因此大多数选择非参数cusum控制图。在变点检测中,主要是对变点是否发生变化以及发生时刻进行估计。其计算方法如下式:
s0=0
当cusum控制图中s统计量出现拐点时,则表明在该时间点处md的平均值出现突变,即结构出现了缺陷。
本发明关键技术点如下:
(1)建立向量自回归(var)模型对结构的加速度响应的滞后值进行回归分析,得到各系数矩阵;
(2)以参考状态为基准,分别计算无缺陷状态和有缺陷状态的马氏距离md;
(3)采用各测点的dc指标来完成结构缺陷位置的识别过程;
(4)采用cusum控制图法做统计过程的变点分析,根据曲线的变化,判断md的平均值在何时出现突变,即结构在何时出现缺陷。
与现有技术相比,本发明具有以下优点:
(1)基于向量自回归模型的结构局部缺陷识别方法不依赖于实际的物理模型或复杂的有限元模型,极大地提高了该结构缺陷识别的适用性;
(2)向量自回归模型中的系数矩阵对应于结构的刚度和阻尼矩阵,因此只与结构的本身特性有关,与结构的激振类型等无关。
(3)该方法可利用有限测点的观测信号进行缺陷识别;
(4)该方法通过统计手段可衡量不确定性因素的影响;
(5)该方法计算方法简单,极大地提升了计算效率。
附图说明
图1.基于向量自回归模型的结构局部缺陷识别方法流程图.
具体实施方式
实施例1
如图1所示,本发明涉及一种基于向量自回归模型的结构局部缺陷识别方法,通过以下步骤实现,包括
步骤一:采集缺陷结构和无缺陷结构的加速度α响应,将采集得到的加速度α响应分解成数据长度相同的多个样本,用于后续向量自回归模型(var)的建立;
步骤二:利用aic准则确定步骤一中得到的各个样本的var模型阶数,
步骤三:根据步骤二中确定的var模型阶数,建立各个样本var模型,
步骤四:提取步骤三种各个var模型中系数矩阵的对角元素,并定义全新的特征向量f,
步骤五:根据步骤四中的向量f,分别计算缺陷状态和无缺陷状态的马氏距离,
步骤六:根据步骤五中计算得到的缺陷状态和无缺陷状态的马氏距离进行后续的结构缺陷识别。
所述步骤一中的结构加速度响应是指利用加速度传感器采集结构的加速度响应信号,共涉及无缺陷结构和存在缺陷结构两种结构,将无缺陷结构的加速度响应划分为前后两部分,前半部分定义为参考状态,后半部分定义为无缺陷状态;将存在缺陷结构定义为缺陷状态。随后分别将三种状态的加速度响应划分成数据长度相同的多个样本,用于后续的结构缺陷识别。
步骤一中每种状态的试验数可以根据实际情况确定。
所述步骤二中的aic准则于1973年由akaike提出,主要从两个方面考察模型拟合的效果:模型的极大似然函数值和模型中未知参数的个数。似然函数值越大,拟合的效果越好;模型中的未知参数的数量越多,虽模型变化较灵活,但模型参数估计工作量将增大,故需综合这两方面的影响.因此,该准则以提取最大信息量为出发点进行模型阶数的选取,其数学表达式为:
aic=2k-2ln(l)
式中,k是模型参数个数,l是似然函数。从一组可供选择的模型中选择最佳模型时,通常选择aic最小的模型。计算不同阶数下的aic值,选取aic值最小所对应的阶数为模型的最优阶数。
所述步骤三中的var模型通过对多维变量的滞后值进行回归,从而建立起各个变量之间的动态关系。
步骤三是指对步骤一中获得的无缺陷测试状态、参考状态和存在缺陷状态的加速度时程分别建立var模型:
yt=a1yt-1+a2yt-2+…+apyt-p+εt
式中yt={y1t,y2t,…,ykt}t,每次试验均有k个测点;εt是为插值向量,表示数据的整体偏移;ai是k×k阶系数矩阵
所述步骤四中的提取系数矩阵是指提取上述系数矩阵ai中的对角线元素。
所述步骤四中的新向量是指将各系数矩阵中的对角线元素组合成为新向量f1,f2,…,fk
所述步骤五中马氏距离是由印度统计学家马哈拉诺比斯(p.c.mahalanobis)提出的,表示数据的协方差距离。它是一种有效的计算两个未知样本集的相似度的方法。可以按照下式计算:
式中
所述步骤六中结构缺陷识别包括两部分,第一根据dc指标进行结构缺陷位置识别,第二使用cusum控制图来检测马氏距离的突变。
dc指标是衡量有缺陷结构马氏距离和无缺陷结构马氏距离间变化的一个指标,当结构出现缺陷时,即结构刚度特性出现突变,距离缺陷越近测点处的马氏距离将会变化越明显,也就是dc指标将会越高。故采用dc指标可以作为识别结构缺陷位置的指标。
式中
s0=0
当cusum控制图中s统计量出现拐点时,则表明在该时间点处md的平均值出现突变,即结构出现了缺陷。
实施例2
实施例1步骤二中的根据aic准则可以替换成bic准则来确定var模型的阶数。bic(bayesianinformationcriterion)贝叶斯信息准则与aic相似,用于模型选择,1978年由schwarz提出。训练模型时,增加参数数量,也就是增加模型复杂度,会增大似然函数,但是也会导致过拟合现象,针对该问题,aic和bic均引入了与模型参数个数相关的惩罚项,bic的惩罚项比aic的大,考虑了样本数量,样本数量过多时,可有效防止模型精度过高造成的模型复杂度过高。
bic=kln(n)-2ln(l)
其中,k为模型参数个数,n为样本数量,l为似然函数。kln(n)惩罚项在维数过大且训练样本数据相对较少的情况下,可以有效避免出现维度灾难现象。
实施例3
实施例1步骤六中的cusum控制图法可以采用ewma替代。
ewma(加权移动平均法)是一种类型的时间加权控制图,图中标绘了指数加权移动平均值。每个ewma点都根据用户定义的加权因子结合了来自之前所有子组或观测值的信息。ewma控制图的优点是,当较小值或较大值进入计算时不会严重影响到这些控制图。通过更改使用的权重以及控制限制的s数量,可以构建控制图,该图可以检测过程中几乎任何大小的偏移。由于此原因,通常使用ewma控制图来监控受控制过程,以检测偏离目标的较小偏移。其ewma统计量z如下式计算:
z0=λmd1
zj=λmdj+1+(1-λ)mdj-1,0.05≤λ≤0.25
- 还没有人留言评论。精彩留言会获得点赞!