一种基于音视频处理系统的音视频智能识别处理方法与流程
本发明属于音视频处理技术领域,具体地讲涉及一种基于音视频处理系统的音视频智能识别处理方法。
背景技术:
近几年,随着平安城市建设的推进和反恐进程的加快,音视频监控应用越来越广泛,已经成为平安城市的重要组成部分。在今后的平安城市建设中,街道、商业区、重点部位等公共场所都会安置、部署视频摄像头和音频拾音器同步音视频监控,其能够实时有效的捕捉和拍摄犯罪分子的作案过程,提供犯罪分子的面部肖像,采集重要语音信息。
对获取到的前端音频数据和视频数据进行深入挖掘,帮助公安机关对犯罪活动及时采取行动并为后期办案提供有力证据,这对预防和打击违法犯罪行动有着重要的意义,可以在很大程度上提高公安系统的工作效率和工作质量,保障了公共安全。因此,提出一种对音频数据和视频数据进行识别处理的方法很有必要。
技术实现要素:
根据现有技术中存在的问题,本发明提供了一种基于音视频处理系统的音视频智能识别处理方法,其能够对音频数据和视频数据进行融合处理,得到人、语音、图像的关联信息,为公安系统的工作提供了依据。
本发明采用以下技术方案:
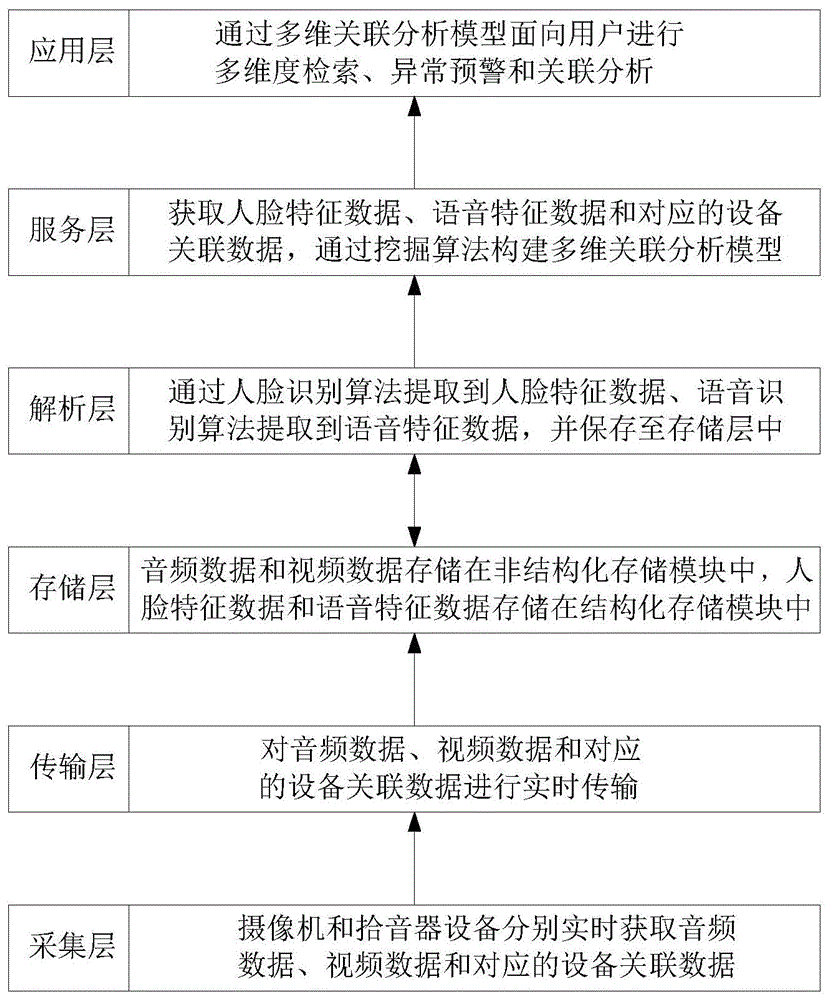
一种基于音视频处理系统的音视频智能识别处理方法,所述音视频处理系统包括采集层、传输层、存储层、解析层、服务层和应用层;所述采集层的输出端连接传输层的输入端,传输层的输出端连接存储层的输入端,存储层与解析层双向通信连接,解析层的输出端连接服务层的输入端,服务层的输出端连接应用层的输入端;所述基于音视频处理系统的音视频智能识别处理方法包括如下步骤:
s1,通过采集层的摄像机和拾音器设备分别实时获取音频数据和视频数据,并通过传输层将音频数据、视频数据以及对应的设备关联数据传输至存储层保存;
s2,解析层由存储层获取音频数据和视频数据,通过解析层上的人脸识别算法对视频数据进行人脸特征数据提取,提取得到的人脸特征数据存储至存储层中;通过解析层上的语音识别算法对语音数据进行语音特征数据提取,提取得到的语音特征数据存储至存储层中;
s3,服务层获取存储层中的人脸特征数据、语音特征数据以及对应的设备关联数据,通过服务层中的挖掘算法构建多维关联分析模型;
s4,应用层通过多维关联分析模型面向用户进行多维度检索、异常预警、关联分析。
优选的,步骤s1中,所述传输层采用基于gpon网络的p2mp组网方式,并部署有接入交换机;所述采集层的摄像机和拾音器设备经由gpon网络光纤与接入交换机联通,且接入交换机分别与存储层中的存储服务器、解析层中的解析服务器联通,实现将获取到的音频数据和视频数据进行实时传输和实时保存;所述设备关联信息包括摄像机设备编号、拾音器设备编号、音频数据采集时间和视频数据采集时间。
进一步优选的,所述存储层中的存储服务器包括结构化存储模块和非结构化存储模块;由摄像机和拾音器设备分别实时获取到的音频数据和视频数据均存储在非结构化存储模块中,步骤s2中提取得到的人脸特征数据和语音特征数据对应存储在结构化存储模块中的人脸库和语音库。
更进一步优选的,步骤s2中,对视频数据进行人脸特征数据提取包括如下步骤:
s21,解析层中的解析服务器获取非结构化存储模块中的视频数据,解析服务器对视频中的人脸图像进行采集,并将采集到的含有人脸图像的人脸图片进行灰度矫正、噪声过滤的预处理,得到处理后的人脸图片;通过人脸识别算法准确标定出处理后的人脸图片中人脸图像的位置和大小,进而输出处理后的人脸图片以及处理后的人脸图片中人脸图像的位置和大小数据;
s22,基于处理后的人脸图片、人脸图像的位置和大小数据信息,通过人脸识别算法对人脸图像中的眼睛、鼻子、嘴、下巴进行特征提取,获得人脸特征数据。
更进一步优选的,步骤s2中,对语音数据进行语音特征数据提取包括如下步骤:
s211,解析层中的解析服务器获取非结构化存储模块中的语音数据,并对语音数据进行滤波、预加重、分帧、加窗的预处理,得到处理后的语音数据;
s212,通过语音识别算法对处理后的语音数据按帧进行特征提取,获得帧特征矢量,连续音频片段经过特征提取后得到一个矢量矩阵,即语音特征数据。
更进一步优选的,步骤s3中,服务层获取结构化存储模块中的人脸特征数据、语音特征数据以及对应的设备关联数据,通过分类、回归、聚类、交叉检验、降维的挖掘算法,基于人脸图像、语音数据、摄像机设备编号、拾音器设备编号、音频数据采集时间和视频数据采集时间构建多维关联分析模型,进而判别人物关系;所述多维关联分析模型包括如下部分:
同一个人,即将结构化存储模块中的两个人脸特征数据进行相似度比较,当相似度大于设定阈值时,则表示为同一个人,当相似度小于设定阈值时,表示非同一个人;
语音归属人,即将结构化存储模块中的两个语音特征数据对应的矢量矩阵进行相似度计算,相似度用两个矢量矩阵之间的距离表示,距离越小,相似度越高;当相似度大于设定阈值时,则语音匹配通过,两个对应语音数据归属一个人,当相似度小于设定阈值时,表示语音匹配不通过,两个对应语音数据不归属一个人;
同行人,即两个人在同一摄像机设备中,同时出现的次数超过设置阈值时,则认定为同行人,否则,认定为非同行人;
人、语音同行,基于多维数据碰撞的同行分析,基于语音归属人和同行人关系,分析判断出不在一处的摄像机设备和拾音器设备对应采集到的人、语音同行关系。
更进一步优选的,所述结构化存储模块中还包括对比图片数据库和对比语音数据库;所述对比图片数据库中保存有在逃人员图片、上访人员图片、吸毒人员图片、刑满释放人员图片,所述对比语音数据库中保存有枪声、爆炸声、哭声、尖叫声的语音片段。
更进一步优选的,步骤s4中,应用层通过多维关联分析模型面向用户进行多维度检索、异常预警、关联分析的具体过程如下:
多维度检索:用户通过摄像机设备编号、拾音器设备编号、音频数据采集时间、视频数据采集时间、人脸特征数据的属性、语音特征数据的关键字进行单个或者多个条件检索;
布控告警:用户将一段异常声音片段作为目标对象单独上传至对比语音数据库,或将一张人脸图片作为目标对象单独上传至对比图片数据库,并设置好相应的相似度阈值,基于步骤s3,当相似度超过设定阈值时,在应用层给出红色告警提示;
关联分析:基于步骤3中多维关联分析模型判别得到的人物关系,用户输入人员的一张人脸图片或一段语音片段,即可查询到与该人员或语音片段关联的同行人图片、同行语音片段。
本发明的优点和有益效果在于:
1)本发明的音视频智能识别处理方法是在视频监控的同时引入音频作为对视频的补充,解决了视频监控中存在的“死角”现象,并且分别采集人的语音数据和人像图片数据,经过提取后进而保存至语音库和人脸库,通过将目标对象与语音库或人脸库做比对,对音频数据和视频数据进行融合处理,得到人、语音、图像的关联信息,为公安系统的工作提供了依据,提高了公安系统的工作效率和工作质量。
2)本发明由采集层的摄像机和拾音器设备采集并提取得到的人脸特征数据和语音特征数据对应存储在结构化存储模块中的人脸库和语音库,且结构化存储模块中还包括对比图片数据库和对比语音数据库;人脸库和语音库内部的人脸特征数据、语音特征数据之间可以进行对比,也可将人脸库和语音库内部的人脸特征数据、语音特征数据,与对比图片数据库和对比语音数据库中的数据进行对比,实现了对特定对象的动态跟踪和过往踪迹的探寻。
附图说明
图1为本发明的音视频智能识别处理方法的流程示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
如图1所示,音视频处理系统包括采集层、传输层、存储层、解析层、服务层和应用层;所述采集层的输出端连接传输层的输入端,传输层的输出端连接存储层的输入端,存储层与解析层双向通信连接,解析层的输出端连接服务层的输入端,服务层的输出端连接应用层的输入端。
一种基于音视频处理系统的音视频智能识别处理方法包括如下步骤:
1、通过采集层的摄像机和拾音器设备分别实时获取音频数据和视频数据,并通过传输层将音频数据、视频数据以及对应的设备关联数据传输至存储层保存;
具体的,所述传输层采用基于gpon网络的p2mp组网方式,并部署有接入交换机;所述采集层的摄像机和拾音器设备经由gpon网络光纤与接入交换机联通,且接入交换机分别与存储层中的存储服务器、解析层中的解析服务器联通,实现将获取到的音频数据和视频数据进行实时传输和实时保存;所述设备关联信息包括摄像机设备编号、拾音器设备编号、音频数据采集时间和视频数据采集时间
所述存储层中的存储服务器包括结构化存储模块和非结构化存储模块;由摄像机和拾音器设备分别实时获取到的音频数据和视频数据均存储在非结构化存储模块中。
2、解析层由存储层获取音频数据和视频数据,通过解析层上的人脸识别算法对视频数据进行人脸特征数据提取,提取得到的人脸特征数据存储至存储层中;通过解析层上的语音识别算法对语音数据进行语音特征数据提取,提取得到的语音特征数据存储至存储层中;
具体的,提取得到的人脸特征数据和语音特征数据对应存储在结构化存储模块中的人脸库和语音库;
具体的,对视频数据进行人脸特征数据提取包括如下步骤:
1)解析层中的解析服务器获取非结构化存储模块中的视频数据,解析服务器对视频中的人脸图像进行采集,并将采集到的含有人脸图像的人脸图片进行灰度矫正、噪声过滤的预处理,得到处理后的人脸图片;通过人脸识别算法准确标定出处理后的人脸图片中人脸图像的位置和大小,进而输出处理后的人脸图片以及处理后的人脸图片中人脸图像的位置和大小数据;
2)基于处理后的人脸图片、人脸图像的位置和大小数据信息,通过人脸识别算法对人脸图像中的眼睛、鼻子、嘴、下巴进行特征提取,获得人脸特征数据;
具体的,对语音数据进行语音特征数据提取包括如下步骤:
1)解析层中的解析服务器获取非结构化存储模块中的语音数据,并对语音数据进行滤波、预加重、分帧、加窗的预处理,得到处理后的语音数据;
2)通过语音识别算法对处理后的语音数据按帧进行特征提取,获得帧特征矢量,连续音频片段经过特征提取后得到一个矢量矩阵,即语音特征数据。
3、服务层获取存储层中的人脸特征数据、语音特征数据以及对应的设备关联数据,通过服务层中的挖掘算法构建多维关联分析模型;
具体的,服务层获取结构化存储模块中的人脸特征数据、语音特征数据以及对应的设备关联数据,通过分类、回归、聚类、交叉检验、降维的挖掘算法,基于人脸图像、语音数据、摄像机设备编号、拾音器设备编号、音频数据采集时间和视频数据采集时间构建多维关联分析模型,进而判别人物关系;所述多维关联分析模型包括如下部分:
同一个人,即将结构化存储模块中的两个人脸特征数据进行相似度比较,当相似度大于设定阈值时,则表示为同一个人,当相似度小于设定阈值时,表示非同一个人;
语音归属人,即将结构化存储模块中的两个语音特征数据对应的矢量矩阵进行相似度计算,相似度用两个矢量矩阵之间的距离表示,距离越小,相似度越高;当相似度大于设定阈值时,则语音匹配通过,两个对应语音数据归属一个人,当相似度小于设定阈值时,表示语音匹配不通过,两个对应语音数据不归属一个人;
同行人,即两个人在同一摄像机设备中,同时出现的次数超过设置阈值时,则认定为同行人,否则,认定为非同行人;
人、语音同行,基于多维数据碰撞的同行分析,基于语音归属人和同行人关系,分析判断出不在一处的摄像机设备和拾音器设备对应采集到的人、语音同行关系。
具体的,所述结构化存储模块中还包括对比图片数据库和对比语音数据库;所述对比图片数据库中保存有在逃人员图片、上访人员图片、吸毒人员图片、刑满释放人员图片,所述对比语音数据库中保存有枪声、爆炸声、哭声、尖叫声的语音片段。
4、应用层通过多维关联分析模型面向用户进行多维度检索、异常预警、关联分析。
具体的,应用层通过多维关联分析模型面向用户进行多维度检索、异常预警、关联分析的具体过程如下:
多维度检索:用户通过摄像机设备编号、拾音器设备编号、音频数据采集时间、视频数据采集时间、人脸特征数据的属性、语音特征数据的关键字进行单个或者多个条件检索;
布控告警:用户将一段异常声音片段作为目标对象单独上传至对比语音数据库,或将一张人脸图片作为目标对象单独上传至对比图片数据库,并设置好相应的相似度阈值,当相似度超过设定阈值时,在应用层给出红色告警提示;
关联分析:基于多维关联分析模型判别得到的人物关系,用户输入人员的一张人脸图片或一段语音片段,即可查询到与该人员或语音片段关联的同行人图片、同行语音片段。
目前的视频监控主要是根据人像图片进行追踪和踪迹探寻,局限性比较大。而本发明的方法是在视频监控的同时引入音频作为对视频的补充,解决了视频监控中存在的“死角”现象,并且分别采集人的语音数据和人像图片数据,经过提取后进而保存至语音库和人脸库,通过将目标对象与语音库或人脸库做比对,对音频数据和视频数据进行融合处理,得到人、语音、图像的关联信息,为公安系统的工作提供了依据,提高了公安系统的工作效率和工作质量。
同时,提取得到的人脸特征数据和语音特征数据对应存储在结构化存储模块中的人脸库和语音库,且结构化存储模块中还包括对比图片数据库和对比语音数据库;通过人脸库、语音库、对比图片数据库和对比语音数据库之间进行对比,实现对特定对象的动态跟踪和过往踪迹探寻。
综上所述,本发明提供了一种基于音视频处理系统的音视频智能识别处理方法,其能够对音频数据和视频数据进行融合处理,得到人、语音、图像的关联信息,为公安系统的工作提供了依据。
- 还没有人留言评论。精彩留言会获得点赞!