一种基于半监督与弱监督学习的曲形场景文字检测方法与流程
本发明涉及图像文字检测
技术领域:
,具体涉及一种基于半监督与弱监督学习的曲形场景文字检测方法。
背景技术:
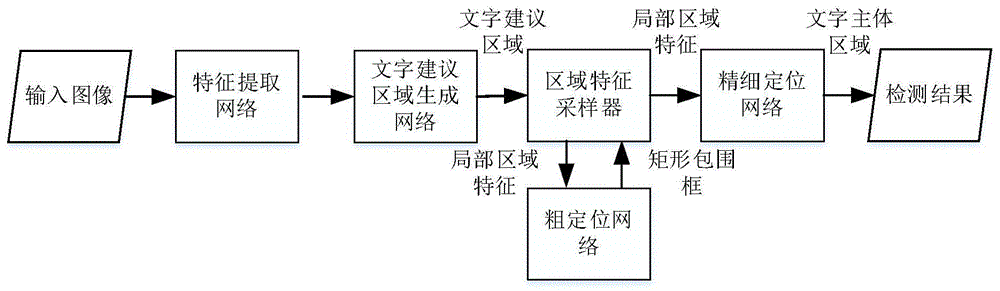
:场景文字通常出现在车牌、产品包装、广告牌等上,是图像中最常见的对象之一,携带有丰富的语义信息。阅读自然场景图像中的文字是各种复杂任务,如车辆自动导航和产品自动检索等任务的一个基本任务。场景文字因其重要性和基础性,吸引了学术界和工业界越来越多的关注。与图像中的通用目标相比,场景文字天生具有多个方向、大宽高比、形状任意、背景复杂等特点,给文字的检测和识别带来了巨大困难和挑战。场景文字的早期研究主要集中在横向文字上,随着技术及数据集的发展与进步,多向文字逐渐成为研究的主要对象。近年来,曲形文本作为自然场景文字中的一种常见对象,吸引了大量的关注。目前,场景文字检测识别方法都主要基于卷积神经网络。曲形文字检测方法主要包括基于语义分割[8]和实例分割[9]的方法。ch’ng等[1]利用反卷积网络对图像进行语义分割得到文字区域。liu等[2]利用r-fcn[10]网络结构回归得到包围文字的十四边形。lyu等[7]利用实例分割方法maskr-cnn[6],同时得到文字实例的矩形包围框及文字区域的像素级二值表示。long等[5]将曲形文字建模成多个沿中心线的圆盘,同时回归圆盘的半径及角度,最后得到文字区域的重建结果。利用以上这些全监督方法可以取得不错的性能,然而这些方法大多依赖于准确的多形性或像素级标注,大大加重了人工标注的负担。li等[3]提出一种利用图像有无文字的类别标签来产生类别激活图的弱监督方法。之后进行最大极值稳定区域提取,并将其聚类得到文字建议区域。tian等[4]提出一种利用少量字符级标签和大量单词集标签来训练一个文字检测器的框架。然而,这种方法需要复杂的、耗费大量人力的字符级标注,而且,最后将字符聚集成单词或文本行无法扩展到除横向文字以外的情况。基于监督学习的曲形文本检测方法虽然可以取得不错的效果,但是他们依赖于精确的多边形或像素级标注,人工标注成本高。li等[3]提出的方法可以产生较好的水平矩形建议区域,却无法对曲形文字进行准确的定位;wetext[4]方法需要复杂的字符级标签,且其后处理方法扩展性不佳。技术实现要素:为了减少曲形文字检测算法所需要的人工标注,同时让整个算法框架更加简洁,本发明提供了一种基于半监督与弱监督学习的曲形场景文字检测方法。利用少量精确的像素级标注数据及大量的无标注或由水平包围框标注的数据就能训练得到一个准确的曲形文字检测器,能够对场景曲形文字进行准确检测。本发明采用的技术方案如下:一种基于半监督与弱监督学习的曲形场景文字检测方法,包括以下步骤:构建一个检测器,利用少量全标注数据对检测器进行初次训练;根据半监督与弱监督学习策略,利用无标注或弱标注数据对初次训练好的检测器进行微调训练;利用微调训练好的检测器检测曲形场景文字,检测步骤包括:从目标图像中提取多尺度的图像特征表示;利用图像特征表示得到可能含有文字的候选区域;根据候选区域的局部特征,利用粗定位网络回归得到文字的水平矩形包围框;利用水平矩形包围框重新提取更精确的局部特征,根据该更精确的局部特征,利用精细定位网络得到水平矩形包围框中主体文字区域的二值表示。其中,半监督与弱监督学习策略包括三种策略。朴素半监督学习策略,该朴素半监督学习策略为:利用初次训练好的检测器对无标注数据进行伪标注,得到标注候选集,经过阈值筛选得到伪标注数据集,将伪标注数据与已标注数据合并在一起,对初次训练好的检测器进行微调训练。基于过滤的弱监督学习策略,该基于过滤的弱监督学习策略为:在朴素半监督学习策略的基础上,利用数据的弱标签来对标注候选集进行过滤,弱标签包含重要的语义信息,利用弱标注框与检测结果的交并比,过滤误检测得到的结果,减少朴素半监督学习中引入的噪声。基于局部监督的弱监督学习策略,该基于局部监督的弱监督学习策略为:粗定位网络采用全监督,将弱标注水平矩形包围框直接输入到精细定位网络中,得到相应的二值标注,利用得到标注来训练精细定位网络。一种曲形场景文字检测器,包括:文字特征提取网络模块,用于从目标图像中提取得到多尺度的图像特征表示;文字建议区域生成网络模块,用于利用图像特征表示得到可能含有文字的候选区域;区域特征采样器,用于根据候选文字区域得到局部特征,以及根据水平矩形包围框重新提取更精确的局部特征;粗定位网络模块,用于根据局部特征回归得到文字的水平矩形包围框;精细定位网络模块,用于根据更精确的局部特征得到水平矩形包围框中主体文字区域的二值表示。进一步地,文字特征提取网络模块由resnet50和fpn组成。进一步地,文字建议区域生成网络模块采用全卷积层,在fpn的五个阶段分别设置不同长宽比为0.2、0.5、1、2和5的锚框。进一步地,区域特征采样器采用roi-align。进一步地,粗定位网络模块采用两个全连接层。进一步地,精细定位网络模块采用卷积层。本发明取得的技术效果如下:1、基础检测器可端到端训练,直接得到曲形文字检测结果,无须中间步骤。2、半监督学习与弱监督学习策略只影响标签生成过程,不会影响训练过程,使得整体框架简洁有效。3、学习策略3将检测器视为多个部分组成,有效的利用了弱标签,同时减少了伪标注过程中引入的噪声,大大提高了模型的性能。附图说明图1是本发明的曲形场景文字检测方法流程图。图2是本发明的检测器框架图。具体实施方式为使本发明的上述特征和优点能更明显易懂,下文特举实施例,并配合所附图作详细说明如下。本实施例提出一种基于半监督学习与弱监督学习的曲形场景文字检测方法,该方法通过提出的高效利用弱标签进行学习的弱监督学习策略对构建的检测器进行训练,利用训练好的训练器来检测曲形场景文字。该检测器包括以下几个网络模块:(1)文字特征提取网络,由resnet50和fpn组成。(2)文字建议区域生成网络,由全卷积层构成,在fpn的五个阶段设置大小不同长宽比为0.2、0.5、1、2和5的锚框。(3)区域特征采样器,采用roi-align对布局特征进行提取。(4)粗定位网络,由两个全连接层组成,回归得到文字实例的水平矩形包围框。(5)精细定位网络,由四个连续的卷积及一个反卷积层组成,得到水平矩形包围框中主体文字区域的二值表示。本检测器通过训练实现由粗到精的过程,具体地,首先利用少量全标注数据进行初次训练,为表述方便,此处将初次训练好的检测器称为基准检测器,再采用半监督与弱监督学习策略,利用大量无标注或弱标注数据进行微调训练,通过迭代标注和训练,最终得到准确的曲形文字检测器。半监督与弱监督学习策略包括以下三种学习策略:1.朴素半监督学习策略。该策略利用训练好的基准检测器来对无标注数据进行伪标注,得到的标注候选集,经过简单的阈值筛选得到伪标注数据集,将伪标注数据与已标注数据合并在一起,对基准检测器进行微调训练。2.基于过滤的弱监督学习策略。该策略在策略1的基础上,利用数据的弱标签来对标注候选集进行过滤,弱标签包含重要的语义信息,利用弱标注框与有粗定位网络回归得到的矩形框的交并比,来过滤误检测得到的结果,减少朴素半监督学习中引入的噪声。3.基于局部监督的弱监督学习策略。该策略不再将整个检测器当作一个黑盒,而是作为一个由多个模块有机结合的整体。将弱标注水平矩形包围框直接输入到精细定位网络中,得到相应的二值标注,利用得到标注来训练精细定位网络。相比于策略2,本策略中,粗定位网络为全监督,大大减少了策略2引入的噪声。为验证本发明的有效性,选取了公共数据集scut-ctw1500以及total-text来进行验证。scut-ctw1500中包含1500张图片,其中训练集和测试集中分别有1000张和500张图片,每个实例均由十四边形标注,标注级别为文本行级。total-text中包含1555张场景图像,其中训练集包含1255张图像,验证集包含300张图像,每个实例均由多边形标注,标注级别为单词级。本发明在采用10%的完全标注数据集和90%无标注或弱标注的数据集训练得到的模型上与其他全监督模型进行对比。在scut-ctw1500和total-text上本发明与近年来其他主流检测算法的对比如表1和表2所示,其中f-measure是一个综合考虑了准确率和召回率的指标。请注意本段段首说明了我们的弱监督方法是和全监督方法来比较的,在这种前提下,策略三在两个曲形文字数据集上依然比现有的全监督方法要好,前两种策略相对于其他方法也具有一定的竞争性,说明了本文方法的优越性实验结果表明本发明在大幅度减少标注劳动力(少用了90%的精确标注)的同时,仍可获得更佳的检测效果,仍然比现有的全监督方法要好。表1本发明与其他算法在scut-ctw1500上的结果对比算法准确率召回率f-measure本发明策略一67%72%70%本发明策略二75%68%71%本发明策略三74%78%76%liu[2]77%70%73%long[5]68%85%75%表2本发明与其他算法在total-text上的结果对比算法准确率召回率f-measure本发明策略一71%77%74%本发明策略二80%74%77%本发明策略三78%82%80%ch’ng[1]33%40%36%lyu[7]69%55%61%long[5]83%74%78%参考文献:[1]cheekhengch'ngandcheesengchan,“total-text:acomprehensivedatasetforscenetextdetectionandrecognition”,in201714thiaprinternationalconferenceondocumentanalysisandrecognition(icdar).ieee,2017,pp.935-942.[2]yuliangliu,lianwenjin,shuaitaozhangandshengzhang,“detectingcurvetextinthewild:newdatasetandnewsolution”,arxivpreprintarxiv:1712.02170,2017.[3]rongli,mengyien,jianqiangliandhaibinzhang,“weaklysupervisedtextattentionnetworkforgeneratingtextproposalsinsceneimages”,in201714thiaprinternationalconferenceondocumentanalysisandrecognition(icdar).ieee,2017,pp.324-330.[4]shangxuantian,shijianlu,andchongshouli,“wetext:scenetextdetectionunderweaksupervision”,in2017ieeeinternationalconferenceoncomputervision(iccv).ieee,2017,pp.1492-1500.[5]shangbanglong,jiaqiangruan,wenjiezhang,xinhe,wenhaowu,congyao,“textsnake:aflexiblerepresentationfordetectingtextofarbitraryshapes”,intheeuropeanconferenceoncomputervision(eccv).springer,2018,pp.20-36.[6]kaiminghe,georgiagkioxari,piotrdoll′ar,androssgirshick,“maskr-cnn”,in2017ieeeinternationalconferenceoncomputervision(iccv).ieee,2017,pp.2980–2988.[7]pengyuanlyu,minghuiliao,congyao,wenhaowuandxiangbai,“masktextspotter:anend-to-endtrainableneuralnetworkforspottingtextwitharbitraryshapes”,intheeuropeanconferenceoncomputervision(eccv).springer,2018,pp.67-83.[8]jonathanlong,evanshelhamerandtrevordarrell,“fullyconvolutionalnetworksforsemanticsegmentation”,in2015ieeeconferenceoncomputervisionandpatternrecognition(cvpr).ieee,2015,pp.3431-3440.[9]yili,haozhiqi,jifengdai,xiangyangjiandyichenwei,“fullyconvolutionalinstance-awaresemanticsegmentation”,in2017ieeeconferenceoncomputervisionandpatternrecognition(cvpr).ieee,2017,pp.4438-4446.[10]jifengdai,yili,kaimingheandjiansun,“r-fcn:objectdetectionviaregion-basedfullyconvolutionalnetworks”,inadvancesinneuralinformationprocessingsystems(nips),2016,pp.379-387.以上实施例仅用以说明本发明的技术方案而非对其进行限制,本领域的普通技术人员可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明的精神和范围,本发明的保护范围应以权利要求书所述为准。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1