一种像素级标签自动生成模型构建、自动生成方法及装置与流程
本发明涉及图像标签生成方法,具体涉及一种像素级标签自动生成模型构建、自动生成方法及装置。
背景技术:
语义图像分割是计算机视觉中的一项重要任务,它为图像中的每个像素分配一个特定的语义标签,也就是说,图像中的每一个像素都会有一个标签,例如在对图像进行分割时,分割出前景目标和背景图像两类,其中前景目标的标签为1,背景图像的标签为0,每一个像素都会有0或1的像素级标签,则在图像上来看,一副图像被处理成一个二值化后的结果,即实现了图像分割。
近年来,深度卷积神经网络在语义图像分割方面表现出了优异的性能,取得了令人瞩目的成绩,其中深层语义图像分割算法的成功在很大程度上取决于大规模带有手工像素级标注的训练图像,但手动标签大规模图像在像素级别费时费力的,并且人工标注的质量也很难满足需求。
为了减轻手工提供像素级图像标签的巨大负担,一些支持深度语义图像分割的弱监督方法被提出。这种弱监督方法不需要像素级的图像标签,而是使用较弱的图像标签比如boundingboxes和scribbles。为了进一步减少人类对图像标签的参与,一些方法仅仅使用图像级的标签作为训练数据,但是这些弱监督方法的性能远远不能取得令人满意的结果,尤其是这些标签生成方法所生成的图像标签与原图像的标签差异过大。
技术实现要素:
本发明的目的在于提供一种像素级标签自动生成模型构建及自动生成方法,用以解决现有的强监督语义分割缺乏大量训练标签和弱监督语义分割效果不好的问题。
为了实现上述任务,本发明采用以下技术方案:
一种像素级标签自动生成模型构建方法,用于获得待标注图像的标签自动生成模型,按照以下步骤执行:
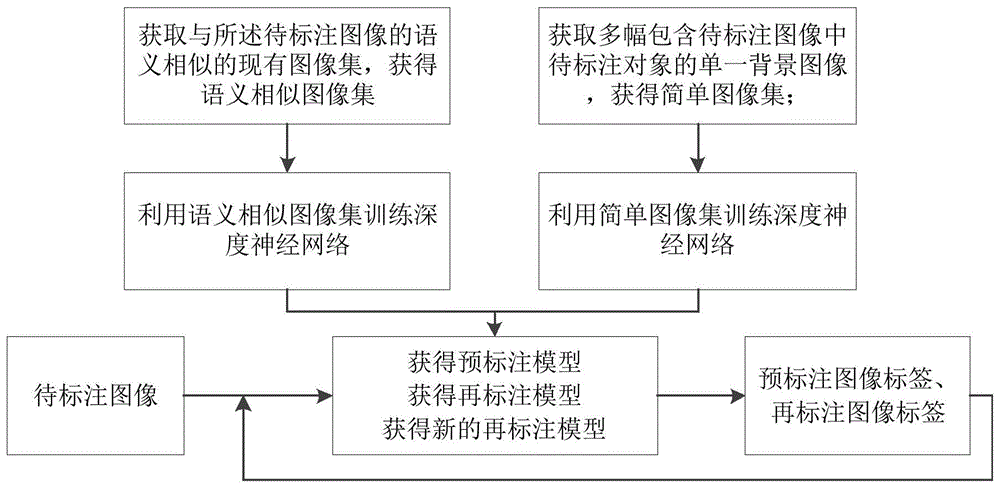
步骤1、获取与所述待标注图像的语义相似的现有图像集,获得语义相似图像集;
或
获取多幅包含待标注图像中待标注对象的单一背景图像,获得简单图像集;
利用所述的语义相似图像集或简单图像集对深度神经网络训练获得预标注模型;
步骤2、将所述的待标注图像输入至获得的预标注模型中,获得预标注图像标签;
将所述待标注图像作为输入,将所述的预标注图像标签作为ground-truth,训练网络,所述的网络包括依次设置的深度神经网络以及指导滤波器;
获得再标注模型;
步骤3、将所述的待标注图像输入至再标注模型或新的再标注模型中,获得再标注图像标签;
将所述待标注图像作为输入,将所述的再标注图像标签作为ground-truth,训练所述的再标注模型,获得新的再标注模型;
步骤4、重复n次执行步骤3,n大于1,将最后一次执行步骤3获得的新的再标注模型作为标签自动生成模型,结束。
进一步地,所述的再标注模型以及新的再标注模型中的损失函数l为:
其中h表示待标注图像在高度方向上包含的像素点个数,w表示待标注图像在宽度方向上包含的像素点个数,
其中βc采用式ii获得:
其中tc表示待标注图像的每个像素点属于第c类预标注图像标签的概率之和,rc表示待标注图像的每个像素点属于第c类再标注图像标签的概率之和。
进一步地,所述的步骤1按照以下步骤执行:
步骤1.1、在现有的带有像素级的标签数据集中找到所述待标注图像的语义相似图像集,若存在语义相似图像集,获得语义相似图像集对应的标签集后执行步骤1.2;否则执行步骤1.3;
步骤1.2、利用所述的语义相似图像集以及所述语义相似图像集对应的图像标签集训练深度神经网络,获得预标注模型;
步骤1.3、采集多幅包含待标注图像中待标注对象的单一背景图像,获得简单图像集;利用阈值分割的方法对所述的简单图像集中的每一幅图像进行标签标注,获得简单图像集对应的图像标签集;
利用所述的简单图像集以及简单图像集对应的图像标签集训练深度神经网络,获得预标注模型。
进一步地,所述的深度神经网络为deeplabv3+网络。
一种像素级标签自动生成方法,按照以下步骤执行:
步骤a、获取待标注图像;
步骤b、利用像素级标签自动生成模型构建方法构建待标注图像的标签自动生成模型;
步骤c、将所述的待标注图像输入至步骤b获得的标签自动生成模型,输出图像像素级标签。
一种像素级标签自动生成模型构建装置,用于实现像素级标签自动生成模型构建方法,所述的装置包括预标注模型获得模块、再标注模型获得模块以及标签自动生成模型获得模块;
其中所述的预标注模型获得模块获取与所述待标注图像的语义相似的现有图像集,获得语义相似图像集;
或
获取多幅包含待标注图像中待标注对象的单一背景图像,获得简单图像集;
利用所述的语义相似图像集或简单图像集对深度神经网络训练获得预标注模型;
所述的再标注模型获得模块用于将所述的待标注图像输入至获得的预标注模型中,获得预标注图像标签;
将所述待标注图像作为输入,将所述的预标注图像标签作为ground-truth,训练网络,所述的网络包括依次设置的深度神经网络以及指导滤波器;
获得再标注模型;
所述的标签自动生成模型获得模块用于重复n次将所述的待标注图像输入至再标注模型或新的再标注模型中,获得再标注图像标签,n大于1;
将所述待标注图像作为输入,将所述的再标注图像标签作为ground-truth,训练所述的再标注模型,获得新的再标注模型;
将最后一次执行步骤3获得的新的再标注模型作为标签自动生成模型。
进一步地,所述的再标注模型以及新的再标注模型中的损失函数l为:
其中h表示待标注图像在高度方向上包含的像素点个数,w表示待标注图像在宽度方向上包含的像素点个数,
其中βc采用式ii获得:
其中tc表示待标注图像的每个像素点属于第c类预标注图像标签的概率之和,rc表示待标注图像的每个像素点属于第c类再标注图像标签的概率之和。
进一步地,所述的预标注模型获得模块包括现有图像生成子模块以及采集图像生成子模块:
所述的现有图像生成子模块用于在现有的带有像素级的标签数据集中找到所述待标注图像的语义相似图像集后利用所述的语义相似图像集以及所述语义相似图像集对应的标签集训练深度神经网络,获得预标注模型;
所述的采集图像生成子模块用于采集多幅包含待标注图像中待标注对象的单一背景图像,获得简单图像集;利用阈值分割的方法对所述的简单图像集中的每一幅图像进行标签标注,获得简单图像集对应的标签集;
利用所述的简单图像集以及简单图像集对应的标签集训练深度神经网络,获得预标注模型。
进一步地,所述的深度神经网络为deeplabv3+网络。
一种像素级标签自动生成装置,包括图像获取模块、像素级标签自动生成模型构建装置以及标签输出模块;
所述的图像获取模块用于获取待标注图像;
标签输出模块用于将所述的待标注图像输入至所述的标签自动生成模型,输出像素级图像标签。
本发明与现有技术相比具有以下技术特点:
1、本发明提供的像素级标签自动生成模型构建及自动生成方法,提供了两种预标注模型获得的方法,能够对自然界的大部分目标图像进行像素级标签的标注,扩大了像素级标注的应用范围,提高了语义分割效果;
2、发明提供的像素级标签自动生成模型构建及自动生成方法在模型中加入了指导滤波器,从图像本身出发能够标注出目标的更多像素级标签(细节信息),能够很好地分割出目标边缘,提高了语义分割效果;
3、发明提供的像素级标签自动生成模型构建及自动生成方法在模型中通过设计了损失函数,能够过滤掉噪声标签,从而提高分割精度,提高了语义分割效果。
附图说明
图1为本发明提供的像素级标签自动生成模型构建方法流程图;
图2为本发明的一个实施例中提供的待标注图像;
图3为本发明的一个实施例中提供的像素级图像标签示意图;
图4为本发明的又一个实施例中提供的待标注图像;
图5为本发明的又一个实施例中提供的单一背景图像;
图6为本发明的又一个实施例中提供的像素级图像标签示意图。
具体实施方式
下面结合附图和实施例对本发明进行详细说明。以便本领域的技术人员更好的理解本发明。需要特别提醒注意的是,在以下的描述中,当已知功能和设计的详细描述也许会淡化本发明的主要内容时,这些描述在这里将被忽略。
以下对本发明涉及的定义或概念内涵做以说明:
语义相似:在本发明中语义相似是指属于同一大类的图像,包括植物、动物、生活用品等,例如生物学家将自然中很多目标都按照科属种等进行分类,比如植物是大类,那么它的子类就包含兰花、菊花、杨树等,因此兰花和菊花就属于语义相似类。
单一背景图像:图像中只包含目标,且背景非常简单,比如一张以树枝为目标的图片,仅仅包含树枝,背景可以是很简单的天空。
图像标签:在本发明中图像标签是像素级标签,每个像素都有一个标签。
实施例一
在本实施例中公开了一种像素级标签自动生成模型构建方法,用于获得待标注图像的标签自动生成模型。
如图1所示,按照以下步骤执行:
步骤1、获取与所述待标注图像的语义相似的现有图像集,获得语义相似图像集;
或
获取多幅包含待标注图像中待标注对象的单一背景图像,获得简单图像集;
利用所述的语义相似图像集或简单图像集对深度神经网络训练获得预标注模型;
在本实施例中利用两种方式选其一获得预标注模型,当现有的图像集中有与待标注的图像中待标注对象类似的图像集时,直接利用现有的图像集训练深度神经网络,获得预标注模型;当现有图像集中没有与待标注的图像中待标注对象类似的图像集时,需要获取多幅包含待标注图像中待标注对象的单一背景图像,获得简单图像集,再利用简单图像集训练深度神经网络,获得预标注模型。
在本步骤中深度神经网络还可以是fcn、u-net、segnet、refinenet、deeplabv2、deeplabv3等语义分割网络
优选地,所述的深度神经网络为deeplabv3+网络。
可选地,所述的步骤1按照以下步骤执行:
步骤1.1、在现有的带有像素级的标签数据集中找到所述待标注图像的语义相似图像集,若存在语义相似图像集,获得语义相似图像集对应的图像标签集后执行步骤1.2;否则执行步骤1.3;
在本实施例中,对于一个给定的要分割的目标类,首先在公开的带有像素级的标签数据集中找它的语义相似类。如果能够找到它的语义相似类那么就进行步骤1.2,否则进行步骤1.3。
步骤1.2、利用所述的语义相似图像集以及所述语义相似图像集对应的标签集训练深度神经网络,获得预标注模型;
在本实施例中,在公共的带有像素级标签的数据集上(比如:pascalvoc2012,microsoftcoco,bsd)找到了目标类的语义相似类,训练深度神经网络,比如deeplabv3+网络,得到一个预标注模型。
步骤1.3、采集多幅包含待标注图像中待标注对象的单一背景图像,获得简单图像集;利用阈值分割的方法对所述的简单图像集中的每一幅图像进行标签标注,获得简单图像集对应的图像标签集;
利用所述的简单图像集以及简单图像集对应的图像标签集训练深度神经网络,获得预标注模型。
在本实施例中,如果在公共的带有像素级标签的数据集上没有找到目标类的语义相似类,那么首先要收集目标类的简单背景图像,然后利用阈值分割检测器,例如otsu检测器来生成简单图像的像素级标签,再利用这些简单图像和生成的像素级标签来训练深度神经网络,比如deeplabv3+网络,得到一个预标注模型。
步骤2、将所述的待标注图像输入至获得的预标注模型中,获得预标注图像标签;
将所述待标注图像作为输入,将所述的预标注图像标签作为ground-truth,训练网络,所述的网络包括依次设置的深度神经网络以及指导滤波器;
获得再标注模型;
在本实施例中,将待标注图像输入至获得的预标注模型中时,获得的预标注图像标签是一个粗标签,通过这种方法不能获得满意的结果,这种方法只能得到目标的大体位置,并不能得到更加精细的目标分割区域。
利用这个粗标签作为监督,再一次的训练网络,但是与预标注模型不同的是,本次的网络中加入了指导滤波器,指导滤波通常能够得到头发丝级的分割结果,因此在本实施例中采用指导滤波来进一步细化分割结果。通过指导滤波能够有效的分割图像的边缘细节。
步骤3、将所述的待标注图像输入至再标注模型或新的再标注模型中,获得再标注图像标签;
将所述待标注图像作为输入,将所述的再标注图像标签作为ground-truth,训练所述的再标注模型,获得新的再标注模型;
在本实施例中,经过引导滤波后得到了细化后的目标标签,然而,一个更加细化的目标标签依赖于在目标域上训练分割网络。解决这一问题的一种方法是对目标域上的分割网络进行微调。为此在本实施例中将步骤3中生成的再标注图像标签作为groundtruth,采用deeplabv3+作为分割网络。再标注图像标签是一种相比与粗粒度标签的细粒度的目标标签。
但是当用步骤3中生成的再标注图像标签即细粒度目标标签来训练网络时,这些标签生成的标签可能含有噪声标签,噪声标签可能会影响语义分割结果。
可选地,所述的深度神经网络为deeplabv3+网络。
因此作为一种优选的实施方式,定义了再标注模型以及新的再标注模型中的损失函数l为:
其中h表示待标注图像在高度方向上包含的像素点个数,w表示待标注图像在宽度方向上包含的像素点个数,
其中βc采用式ii获得:
其中tc表示待标注图像的每个像素点属于第c类预标注图像标签的概率之和,rc表示待标注图像的每个像素点属于第c类再标注图像标签的概率之和。
在本实施例中,若对图像进行分割时,像素级标签包括前景目标0和背景图像1,此时c=2,即共有两类标签。
通过定义了以上的损失函数,从直观上看,粗标签与精细标签之间的比例越大,说明在指导滤波器的作用下,其微调效果较好。通过这种方法,贡献因子βc可以自动提高训练中可靠标签的权重,使模型专注于精确的精细标签。通过对目标域的不断学习,逐步优化分割网络,细化后的标签将更加准确。经过多次迭代,最终得到了具有详细像素级结构/目标域边界的细粒度对象标签。
步骤4、重复n次执行步骤3,n大于1,将最后一次执行步骤3获得的新的再标注模型作为标签自动生成模型,结束。
反复进行步骤3直到产生满意的分割结果为止。也就是说步骤4是在产生分割标签和用产生的分割标签作为监督信息来训练网络之间不断的迭代。
实施例二
一种像素级标签自动生成方法,按照以下步骤执行:
步骤a、获取待标注图像;
步骤b、利用实施例一中的像素级标签自动生成模型构建方法构建待标注图像的标签自动生成模型;
步骤c、将所述的待标注图像输入至步骤b获得的标签自动生成模型,输出图像像素级标签。
在本实施例中收集了“兰花”科中不同植物物种图像作为待标注图像如图2所示。
利用实施例一中的像素级标签自动生成模型构建方法构建待标注图像的标签自动生成模型时,其中获得预标注模型利用现有的图像集pascalvoc2012数据集作为语义相似图像集,pascalvoc2012数据集包含了20个目标类1个背景类,其中训练集、测试集和验证集各有1464,1449和1456张图像。这些图像都有像素级的语义标签,且pascalvoc2012中的“盆栽”跟“兰花”属于语义相似类。
选择deeplabv3+中的resnet101作为深度神经网络,获得了预标注模型,再通过预标注模型训练获得标签自动生成模型,在训练时使用一个小批量大小为8的batchsize,初始学习率设置为0.007,每隔5个epoch除以10。重量衰减和动量分别设置为0.0002和0.9。
将图2所示的待标注图像输入至获得的标签自动生成模型中,输出如图3所示的像素级图像标签,如图3所示的图像标签具有详细的像素级结构/边界。从这些实验结果可以很容易地看出,我们的方法可以自动生成像素级的标注(即细粒度对象标注),并且生成的标签质量非常接近手工标记的标签。
对本实施例中获得的图像标签采用miou方法评价,miou被广泛用于评价深度语义图像分割方法的性能,在本实施例中对“兰花科植物”图像的评价结果为80.3%。
利用了与本实施例相同的方法对“飞机”图像进行了标签标注,其中现有数据集为fgvcaircraft数据集,fgvcaircraft数据库包含了10000张飞机图像,将其分为了训练集和测试集,其中训练集占有9000张图像,测试集有1000张,这1000张测试图像有我们手工标注的像素级语义标签,采用本实施例中的方法对“飞机”图像的评价结果为91.5%。
实施例三
在本实施例中,获取复杂背景图像中的树枝图像作为待标注图像如图4所示。
利用实施例一中的像素级标签自动生成模型构建方法构建待标注图像的标签自动生成模型时,其中获得预标注模型由于在公开的带有像素级标签的数据集上没有找到域“树枝“语义相似的类别,因此首先通过采集单一背景图像来获得简单图像集,如图5所示,选择deeplabv3+中的resnet101作为深度神经网络,获得了预标注模型,再通过预标注模型训练获得标签自动生成模型,在训练时使用一个小批量大小为8的batchsize,初始学习率设置为0.007,每隔5个epoch除以10。重量衰减和动量分别设置为0.0002和0.9。
将图4所示的待标注图像输入至获得的标签自动生成模型中,输出如图6所示的图像标签,如图3所示的图像标签具有详细的像素级结构/边界。从这些实验结果可以很容易地看出,我们的方法可以自动生成像素级的标注(即,细粒度对象标注),并且生成的标签质量非常接近手工标记的标签。
对本实施例中获得的图像标签采用miou方法评价,miou被广泛用于评价深度语义图像分割方法的性能,在本实施例中对“树枝”图像的评价结果为70.1%。
实施例四
一种像素级标签自动生成模型构建装置,用于实现实施例一中像素级标签自动生成模型构建方法,所述的装置包括预标注模型获得模块、再标注模型获得模块以及标签自动生成模型获得模块;
其中所述的预标注模型获得模块获取与所述待标注图像的语义相似的现有图像集,获得语义相似图像集;
或
获取多幅包含待标注图像中待标注对象的单一背景图像,获得简单图像集;
利用所述的语义相似图像集或简单图像集对深度神经网络训练获得预标注模型;
所述的再标注模型获得模块用于将所述的待标注图像输入至获得的预标注模型中,获得预标注图像标签;
将所述待标注图像作为输入,将所述的预标注图像标签作为ground-truth,训练网络,所述的网络包括依次设置的深度神经网络以及指导滤波器;
获得再标注模型;
所述的标签自动生成模型获得模块用于重复n次将所述的待标注图像输入至再标注模型或新的再标注模型中,获得再标注图像标签,n大于1,;
将所述待标注图像作为输入,将所述的再标注图像标签作为ground-truth,训练所述的再标注模型,获得新的再标注模型;
将最后一次获得的新的再标注模型作为标签自动生成模型。
可选地,所述的再标注模型以及新的再标注模型中的损失函数l为:
其中h表示待标注图像在高度方向上包含的像素点个数,w表示待标注图像在宽度方向上包含的像素点个数,
其中βc采用式ii获得:
其中tc表示待标注图像的每个像素点属于第c类预标注图像标签的概率之和,rc表示待标注图像的每个像素点属于第c类再标注图像标签的概率之和。
可选地,所述的预标注模型获得模块包括现有图像生成子模块以及采集图像生成子模块:
所述的现有图像生成子模块用于在现有的带有像素级的标签数据集中找到所述待标注图像的语义相似图像集后利用所述的语义相似图像集以及所述语义相似图像集对应的标签集训练深度神经网络,获得预标注模型;
所述的采集图像生成子模块用于采集多幅包含待标注图像中待标注对象的单一背景图像,获得简单图像集;利用阈值分割的方法对所述的简单图像集中的每一幅图像进行标签标注,获得简单图像集对应的标签集;
利用所述的简单图像集以及简单图像集对应的标签集训练深度神经网络,获得预标注模型。
可选地,所述的深度神经网络为deeplabv3+网络。
实施例五
一种像素级标签自动生成装置,包括图像获取模块、像素级标签自动生成模型构建装置以及标签输出模块;
所述的图像获取模块用于获取待标注图像;
标签输出模块用于将所述的待标注图像输入至所述的标签自动生成模型,输出图像像素级标签。
- 还没有人留言评论。精彩留言会获得点赞!