一种基于Unicode编码的信息嵌入与提取方法与流程
本发明涉及一种数据通信的方法,特别涉及一种基于unicode编码的信息嵌入与提取方法,属于通信(如数据通信技术等)领域。
背景技术:
在卫星通信系统与导航系统中,发送端与目的端之间会传输一定格式的文本消息,该消息主要由汉字、各种字符以及各种符号组成。在卫星数据的传输过程中,可将敏感信息嵌入卫星数据中,在不增加传输容量的基础上,将卫星数据与敏感信息协同传输。
常见的文本消息信息嵌入与隐藏方法主要针对文本的字体大小、颜色、行间距等格式展开研究,通过不同的文本格式来隐藏嵌入信息。如移位编码,利用文本相对位置关系来隐藏信息,包括行间距与字间距编码;特征编码,通过改变字符某一特征来嵌入标记,包括区分中英文标点所占字符宽度及修改字体等;同义词替换方法、文本伪装等。
但是无论上述哪种方法,在通信信道被占用的情况下,想要再发送其他消息必须得间隔一定时间才能再次发送。这样导致了效率低下,信道资源没有充分被利用。
技术实现要素:
本发明的技术解决问题是:克服现有技术的不足,提供一种基于unicode编码的信息嵌入与提取方法,在不增加额外附加信息的情况下,将敏感信息嵌入传输消息中,并无损恢复原始信息与嵌入信息,在不增加信道资源的情况下,提高了系统容量。
本发明的技术解决方案是:一种基于unicode编码的信息嵌入与提取方法,该方法包括:
基于unicode编码的信息嵌入方法:
(1.1)、对unicode编码后的文本消息字符高字节h、低字节l进行预处理,使各字符高字节和低字节的数值范围集中,便于根据预处理之后的高字节、低字节的数值进行分段处理;
(1.2)、对预处理后的高字节h'、低字节l'进行分段性编码计算,使编码之后的高字节h”、低字节l”集中在某些数据位;
(1.3)、将编码后的高字节h”、低字节l”中未使用到的数据位用于信息嵌入;
基于unicode编码的信息提取方法:
(2.1)、根据含有嵌入信息的消息的高字节h”与低字节l”所处的区段,提取出嵌入信息m;
(2.2)、对含有嵌入信息的消息的高字节h”与低字节l”进行译码,得到去除编码信息的消息的高字节h'与低字节l';
(2.3)、对去除编码信息的消息的高字节h'与低字节l',进行反预处理,恢复原有数据的高字节h与低字节l。
所述步骤(1.1)对unicode编码后的信息字符高字节h、低字节l进行预处理的具体方法为:
(1.1.1)、当字符为汉字字符时,对字符高字节h、低字节l进行如下处理:
h'=h-78
l'=l
其中,h'为预处理后的高字节,从高到低每比特可表示为h'7、h'6、h'5、h'4、h'3、h'2、h'1、h'0;l'为预处理后的低字节,从高到低每比特可表示为l'7、l'6、l'5、l'4、l'3、l'2、l'1、l'0;
(1.1.2)、当字符为字母或符号时,对字符高字节h、低字节l进行如下处理:
首先,将低字节l表达成l=2n+i的形式,其中i为0或1;
然后,按照如下公式计算得到预处理后的高字节h'和低字节l';
h'=n+66;
l'7=i,l'0至l'6均置0。
当预处理之后的字符高字节h'位于[82,127]之间时,所述步骤(1.2)对预处理后的高字节h'、低字节l'进行分段性编码计算的具体方法为:
编码后的高字节h”的第7位赋值为1,其余位赋值为预处理后的高字节h'对应数据位,低字节l”的第7位为预处理后的低字节l'对应数据位,低字节l”的第0位至第6位用于信息嵌入;
当预处理之后的字符高字节h'位于[0,81]之间且预处理之后的字符低字节l'<64时,所述步骤(1.2)对预处理后的高字节h'、低字节l'进行分段性编码计算的具体方法为:
将编码后的高字节h”的第7位赋值为1,其余位赋值为预处理后的高字节h'对应数据位;编码后的低字节l”的第0位至第5位赋值为预处理后的低字节l'对应数据位,低字节l”的第6位与第7位用于信息嵌入。
当预处理之后的字符高字节h'位于[0,81]之间且预处理之后的字符低字节l'位于[128,255]之间时,所述步骤(1.2)对预处理后的高字节h'、低字节l'进行分段性编码计算的具体方法为:
编码后的高字节h”的第7位赋值为0,其余位赋值为预处理后的高字节h'对应数据位;编码后的低字节l”赋值为预处理后的低字节l'减去128,低字节l”的第7位用于信息嵌入。
当预处理之后的字符高字节h'位于[0,81]之间且预处理之后的字符低字节l'位于[64,109]之间时,所述步骤(1.2)对预处理后的高字节h'、低字节l'进行分段性编码计算的具体方法为:
编码后的高字节h”的第7位赋值为0,其余位赋值为预处理后的低字节l'加上18;编码后的低字节l”赋值为预处理后的高字节h',低字节l”的第7位用于信息嵌入,具体为:
h”7=0,h”=l'+18;l”=h';
当预处理之后的字符高字节h'位于[0,45]之间且预处理之后的字符低字节l'位于[110,127]之间时,所述步骤(1.2)对预处理后的高字节h'、低字节l'进行分段性编码计算的具体方法为:
编码后的高字节h”的第7位赋值为0,其余位赋值为预处理后的高字节h'加上82;编码后的低字节l”赋值为预处理后的低字节l',低字节l”的第7位用于信息嵌入。
当预处理之后的字符高字节h'位于[46,81]之间且当预处理之后的字符高字节l'位于[110,127]之间时,所述步骤(1.2)对预处理后的高字节h'、低字节l'进行分段性编码计算的具体方法为:
编码后的高字节h”的第7位赋值为0,其余位赋值为预处理后的高字节h'加上36;编码后的低字节l”赋值为预处理后的低字节l'减去28,低字节l”的第7位用于信息嵌入。
当含有嵌入信息的消息的高字节h”位于[0,81]之间时:
嵌入信息为m为含有嵌入信息的消息低字节l”的第7位。
去除编码信息的字符高字节h'为含有嵌入信息的字符高字节h”;
去除编码信息的字符低字节l'为含有嵌入信息的消息低字节l”第7位置0后加上128;
原始字符的高字节h为去除编码信息的消息的高字节h'加上78;
原始字符的低字节l为去除编码信息的消息的低字节l'。
当含有嵌入信息的字符高字节h”位于[82,127]之间且含有嵌入信息的字符低字节l”位于[0,81]或[128,209]时:
嵌入信息为m为含有嵌入信息的消息低字节l”的第7位。
去除编码信息的字符高字节h'的第7位赋值为0,其余位赋值为含有嵌入信息的字符低字节l”;
去除编码信息的字符低字节l'的第7位赋值为0,其余位赋值为含有嵌入信息的字符高字节h”减去18;
原始字符的高字节h赋值为去除编码信息的字符高字节h'加上78;
原始字符的低字节l赋值为去除编码信息的字符低字节l';
当含有嵌入信息的字符高字节h”位于[82,127]之间且含有嵌入信息的字符低字节l”位于[110,127]或[238,255]之间时:
嵌入信息为m为含有嵌入信息的消息低字节l”的第7位。
去除编码信息的字符高字节h'赋值为含有嵌入信息的信息高字节h”减去82;
去除编码信息的字符低字节l'的第7位赋值为0,其余位赋值为含有嵌入信息的字符低字节l”对应数据位;
原始字符的高字节h赋值为去除编码信息的字符高字节h'加上78;
原始字符的低字节l赋值为去除编码信息的字符低字节l';
含有嵌入信息的字符高字节h”位于[82,117]之间且含有嵌入信息的字符低字节l”位于[82,99]或[210,227]之间时:
嵌入信息为m为含有嵌入信息的消息低字节l”的第7位。
去除编码信息的字符高字节h'赋值为含有嵌入信息的字符高字节h”减去36;
去除编码信息的字符低字节l'的第7位赋值为0,其余位赋值为含有嵌入信息的字符低字节l”对应数据位加上28;
原始字符的高字节h赋值为去除编码信息的字符高字节h'加上78;
原始字符的低字节l赋值为去除编码信息的字符低字节l';
含有嵌入信息的字符高字节h”位于[128,209]之间时:
嵌入信息为m为含有嵌入信息的消息低字节l”的第7位和第6位。
去除编码信息的字符高字节h'赋值为含有嵌入信息的字符高字节h”减去128;
去除编码信息的字符低字节l'的第7位和第6位赋值为0,其余位赋值为含有嵌入信息的字符低字节l”对应数据位;
原始字符的高字节h赋值为去除编码信息的字符高字节h'加上78;
原始字符的低字节l赋值为去除编码信息的字符低字节l';
含有嵌入信息的字符高字节h”位于[210,255]之间时:
嵌入信息为m为含有嵌入信息的字符低字节l”的低7位;
去除编码信息的字符高字节h'的第7位赋值为0,其余位赋值为含有嵌入信息的字符高字节h”对应数据位;
去除编码信息的字符低字节l'的第0至第6位赋值为0,其余位赋值为含有嵌入信息的字符低字节l”对应数据位;
原始字符的高字节h赋值为0;
原始字符的低字节l赋值为:l=(h'-66)×2+l'7。
本发明与现有技术相比的有益效果是:
本发明在不增加额外附加信息的情况下,将敏感信息嵌入传输消息中,并无损恢复原始信息与嵌入信息,在不增加信道资源的情况下,提高了系统容量。
附图说明
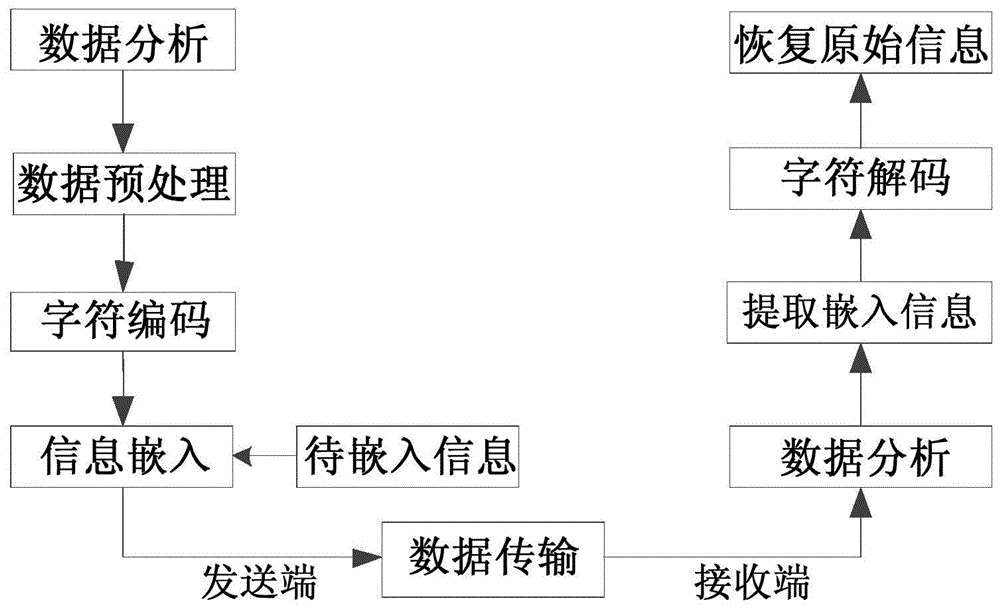
图1基于unicode编码的信息嵌入与信息提取实现框图;
具体实施方式
以下结合附图和具体实施方式进行详细说明。
unicode是世界上比较通用的一种用于计算机的字符编码,该编码方式由ascii字符集扩展而来,其主要特征为每个字符使用两个字节编码。它能够满足跨平台的文本处理和转换需求,因此本发明针对基于unicode编码的文本消息进行无损信息嵌入方法的研究。首先研究分析该编码的特点,通过对消息字符(汉字字符、字母字符及其他符号)进行处理、分段性编码计算及不同区域之间变换,在无需任何附加信息的前提下,向每个字符中无损嵌入1~7个比特信息。该方法可实现在卫星消息与敏感信息的协同传输,可达到1/16~7/16的信息嵌入率,能够无失真恢复原始消息及嵌入信息,在不增加信道资源的情况下,提高系统的传输容量。
本发明中研究的嵌入信息载体为卫星通信系统及导航系统中传输的文本消息,该消息主要由汉字、字母及各种符号组成。在unicode编码范围中,[0x4e00,0x9fbf](十六进制)(或十进制[19968,40869])为中文汉字范围,[0x0021,0x007c](十六进制)(或十进制[33,124])为字母、数字、常用符号范围。因此,本发明针对unicode编码中[0x4e00,0x9fbf](十六进制)和[0x0021,0x007c](十六进制)这两个区位进行分析研究。
在unicode编码中,由于每个字符采用两个字节编码,本发明将每个字符的编码分为高字节和低字节。其中,高字节指的是高8位比特数据,低字节指的是低8位比特数据。首先分析unicode编码中这两个区位数值的特点及数值范围,根据数值的不同将字符的高低字节编码至不同的区间,使文本消息字符的数值范围更为集中,从而得到信息嵌入位置。
针对卫星通信系统与导航系统中传输的由汉字、各种字符以及各种符号组成的消息,本发明研究一种无额外附加信息、无损的信息嵌入方法。
如图1所示,本发明提供的一种基于unicode编码的信息嵌入过程与提取过程,具体实现步骤为:
一、基于unicode编码的信息嵌入方法:
(1.1)、对unicode编码后的文本消息字符高字节h、低字节l进行预处理,使各字符高字节和低字节的数值范围集中,便于根据预处理之后的高字节、低字节的数值进行分段处理;
假设每个字符unicode编码后可表示为[h,l],其中h指高字节,共8比特,从高到低每比特可表示为(h7、h6、h5、h4、h3、h2、h1、h0);l指低字节,共8比特,从高到低每比特可表示为(l7、l6、l5、l4、l3、l2、l1、l0)。本节中字符对应的高低字节数值h、l均为转换后的十进制数值;h7、h6、h5、h4、h3、h2、h1、h0为h对应的8位二进制数值;l7、l6、l5、l4、l3、l2、l1、l0为l对应的8位二进制数值。
预处理具体为:
(1.1.1)、当字符为汉字字符时(即:h位于[78,59]之间),对字符高字节h、低字节l进行如下处理:
h'=h-78
l'=l
其中,h'为预处理后的高字节,从高到低每比特可表示为h'7、h'6、h'5、h'4、h'3、h'2、h'1、h'0;l'为预处理后的低字节,从高到低每比特可表示为l'7、l'6、l'5、l'4、l'3、l'2、l'1、l'0;预处理后h'位于[0,81]之间,l'位于[0,255]之间;
(1.1.2)、当字符为字母或符号时(h为0,l位于[33,124]之间),对字符高字节h、低字节l进行如下处理:
首先,将低字节l表达成l=2n+i的形式,其中i为0或1;
然后,按照如下公式计算得到预处理后的高字节h'和低字节l';
h'=n+66;
l'7=i,l'0至l'6均置0;预处理后h'位于[82,127]之间,l'为0或128。
(1.2)、对预处理后的高字节h'、低字节l'进行分段性编码计算,使编码之后的高字节h”、低字节l”集中在某些数据位;
对预处理后的高字节h'、低字节l'进行分段性编码计算的具体方法为:
(1.2.1)、当预处理之后的字符高字节h'位于[82,127]之间时,则说明该字符为字母或符号,在这种情况下,低字节只可能为0或128,那么,编码后的高字节h”的第7位赋值为1,其余位赋值为预处理后的高字节h'对应数据位,低字节l”的第7位为预处理后的低字节l'对应数据位,低字节l”的第0位至第6位用于信息嵌入,具体为:
h”7=1,h”6=h'6,h”5=h'5,h”4=h'4,h”3=h'3,h”2=h'2,h”1=h'1,h”0=h'0;
l”7=l'7;
在这种情况下该字符能够嵌入7位信息,编码后h”位于[210,255]之间。
(1.2.2)、当预处理之后的字符高字节h'位于[0,81]之间且预处理之后的字符低字节l'<64时(即l'位于[0,63]之间),将编码后的高字节h”的第7位赋值为1,其余位赋值为预处理后的高字节h'对应数据位;编码后的低字节l”的第0位至第5位赋值为预处理后的低字节l'对应数据位,低字节l”的第6位与第7位用于信息嵌入,具体为:
h”7=1,h”6=h'6,h”5=h'5,h”4=h'4,h”3=h'3,h”2=h'2,h”1=h'1,h”0=h'0;
l”5=l'5,l”4=l'4,l”3=l'3,l”2=l'2,l”1=l'1,l”0=l'0;
在这种情况下该字符能够嵌入2位信息,编码后h”位于[128,209]之间。
(1.2.3)、当预处理之后的字符高字节h'位于[0,81]之间且预处理之后的字符低字节l'位于[128,255]之间时,编码后的高字节h”的第7位赋值为0,其余位赋值为预处理后的高字节h'对应数据位;编码后的低字节l”赋值为预处理后的低字节l'减去128,低字节l”的第7位用于信息嵌入,具体为:
h”7=0,h”6=h'6,h”5=h'5,h”4=h'4,h”3=h'3,h”2=h'2,h”1=h'1,h”0=h'0;
l”=l'-128;
在这种情况下该字符能够嵌入1位信息,且h”位于[0,81]之间,l”位于[0,127]之间。
(1.2.4)、当预处理之后的字符高字节h'位于[0,81]之间且预处理之后的字符低字节l'位于[64,109]之间时,编码后的高字节h”的第7位赋值为0,其余位赋值为预处理后的低字节l'加上18;编码后的低字节l”赋值为预处理后的高字节h',低字节l”的第7位用于信息嵌入,具体为:
h”7=0,h”=l'+18;l”=h';
在这种情况下该字符能够嵌入1位信息,且h”位于[82,127]之间,l”位于[0,81]之间。
(1.2.5)、当预处理之后的字符高字节h'位于[0,45]之间且预处理之后的字符低字节l'位于[110,127]之间时,编码后的高字节h”的第7位赋值为0,其余位赋值为预处理后的高字节h'加上82;编码后的低字节l”赋值为预处理后的低字节l',低字节l”的第7位用于信息嵌入,具体为:
h”7=0,h”=h'+82;l”=l';
在这种情况下该字符能够嵌入1位信息,且h”位于[82,127]之间,l”位于[110,127]之间。
(1.2.6)、当预处理之后的字符高字节h'位于[46,81]之间且当预处理之后的字符低字节l'位于[110,127]之间时,编码后的高字节h”的第7位赋值为0,其余位赋值为预处理后的高字节h'加上36;编码后的低字节l”赋值为预处理后的低字节l'减去28,低字节l”的第7位用于信息嵌入,具体为:
h”7=0,h”=h'+36;l”=l'-28;
在这种情况下该字符能够嵌入1位信息,且h”位于[82,117]之间,l”位于[82,99]之间。
(1.3)、将编码后的高字节h”、低字节l”中未使用到的数据位用于信息嵌入;
对本发明分段编码和信息嵌入情况汇总如下表所示:
表1信息嵌入前后字符高、低字节的数值范围
二、基于unicode编码的信息提取方法:
接收端收到含有嵌入信息的消息后,将收到数据分为高字节h”与低字节l”,首先分析数据高低字节的特征,根据分析结果对数据进行译码及处理,然后提取出嵌入信息m,同时恢复原有数据h、l,即unicode编码后的文本消息字符高字节h、低字节l。
判断高字节h”与低字节l”的范围,并对h”和l”进行不同区域的变换运算。
(2.1)、根据含有嵌入信息的消息的高字节h”与低字节l”所处的区段,提取出嵌入信息m;
(2.1.1)、h”位于[0,81]之间时,该字符低字节的第7位中嵌入了1位信息。因此,嵌入信息为m为含有嵌入信息的消息低字节l”的第7位。
(2.1.2)、h”位于[82,127]之间且l”位于[0,81]或[128,209]时,该字符低字节的第7位中嵌入了1位信息。因此,嵌入信息为m为含有嵌入信息的消息低字节l”的第7位。
(2.1.3)、h”位于[82,127]之间且l”位于[110,127]或[238,255]之间时,原始数据为汉字字符,该字符低字节的第7位中嵌入了1位信息。因此,嵌入信息为m为含有嵌入信息的消息低字节l”的第7位。
(2.1.4)、h”位于[82,117]之间且l”位于[82,99]或[210,227]之间时,该字符低字节的第7位中嵌入了1位信息。因此,嵌入信息为m为含有嵌入信息的消息低字节l”的第7位。
(2.1.5)、h”位于[128,209]之间时,原始数据为汉字字符,该字符低字节的第6、7位中嵌入了2位信息。因此,嵌入信息为m为含有嵌入信息的消息低字节l”的第7位和第6位。
(2.1.6)、h”位于[210,255]之间时,原始数据为字母或符号字符,该字符低字节的第0、1、2、3、4、5、6位中嵌入了7位信息,因此,嵌入信息为m为含有嵌入信息的字符低字节l”的低7位;
(2.2)、对含有嵌入信息的消息的高字节h”与低字节l”进行译码,得到去除编码信息的消息的高字节h'与低字节l';所述译码方法如下:
(2.2.1)、h”位于[0,81]之间时,译码方法为:
去除编码信息的字符高字节h'为含有嵌入信息的字符高字节h”;
去除编码信息的字符低字节l'为含有嵌入信息的消息低字节l”第7位置0后加上128。
(2.2.2)、h”位于[82,127]之间且l”位于[0,81]或[128,209]时:
去除编码信息的字符高字节h'的第7位赋值为0,其余位赋值为含有嵌入信息的字符低字节l”;
去除编码信息的字符低字节l'的第7位赋值为0,其余位赋值为含有嵌入信息的字符高字节h”减去18;
(2.2.3)、h”位于[82,127]之间且l'位于[110,127]或[238,255]之间时:
去除编码信息的字符高字节h'赋值为含有嵌入信息的信息高字节h”减去82;
去除编码信息的字符低字节l'的第7位赋值为0,其余位赋值为含有嵌入信息的字符低字节l”对应数据位;
(2.2.4)h”位于[82,117]之间且l”位于[82,99]或[210,227]之间
去除编码信息的字符高字节h'赋值为含有嵌入信息的字符高字节h”减去36;
去除编码信息的字符低字节l'的第7位赋值为0,其余位赋值为含有嵌入信息的字符低字节l”对应数据位加上28;
(2.2.5)h”位于[128,209]之间
去除编码信息的字符高字节h'赋值为含有嵌入信息的字符高字节h”减去128;
去除编码信息的字符低字节l'的第7位和第6位赋值为0,其余位赋值为含有嵌入信息的字符低字节l”对应数据位;
(2.2.6)h”位于[210,255]之间时:
去除编码信息的字符高字节h'的第7位赋值为0,其余位赋值为含有嵌入信息的字符高字节h”对应数据位;
去除编码信息的字符低字节l'的第0至第6位赋值为0,其余位赋值为含有嵌入信息的字符低字节l”对应数据位;
(2.3)、对去除编码信息的消息的高字节h'与低字节l',进行反预处理,恢复原有数据的高字节h与低字节l。
(2.3.1)、h”位于[0,81]之间时
原始字符的高字节h为去除编码信息的消息的高字节h'加上78;
原始字符的低字节l为去除编码信息的消息的低字节l';
h位于[78,159]之间,l位于[128,255]之间。
(2.3.2)、h”位于[82,127]之间且l”位于[0,81]或[128,209]时:
原始字符的高字节h赋值为去除编码信息的字符高字节h'加上78;
原始字符的低字节l赋值为去除编码信息的字符低字节l';
h位于[78,159]之间,l位于[64,109]之间。
(2.3.3)、h”位于[82,127]之间且l'位于[110,127]或[238,255]之间
原始字符的高字节h赋值为去除编码信息的字符高字节h'加上78;
原始字符的低字节l赋值为去除编码信息的字符低字节l';
h位于[78,123]之间,l位于[110,127]之间。
(2.3.4)、h”位于[82,117]之间且l”位于[82,99]或[210,227]之间时:
原始字符的高字节h赋值为去除编码信息的字符高字节h'加上78;
原始字符的低字节l赋值为去除编码信息的字符低字节l';
h位于[124,159]之间,l位于[110,127]之间。
(2.3.5)、h”位于[128,209]之间时:
原始字符的高字节h赋值为去除编码信息的字符高字节h'加上78;
原始字符的低字节l赋值为去除编码信息的字符低字节l';
h位于[78,159]之间,l位于[0,63]之间。
(2.3.6)、h”位于[210,255]之间时:
原始字符的高字节h赋值为0;
原始字符的低字节l赋值为:l=(h'-66)×2+l'7。
h为0,l位于[33,124]之间。
至此,完成了基于unicode编码的嵌入信息提取并恢复了原始消息。
本发明在信息嵌入时,将unicode编码后数据高低字节拆分开,对高低字节的不同范围进行分析处理及编码,增加了字符信息的嵌入量。
在基于unicode编码的消息中,假设字母及各类其他字符所占比例为m,汉字字符中低字节小于64的字符所占比例为n,其他汉字字符所占比例为k,即m+n+k=1,那么在整个消息中,信息嵌入率r为:r=m×7/16+n×2/16+k/16
·若整个消息中字母及各种符号所占比例m=1,则这种情况下信息嵌入量最大,整个消息中可嵌入43.75%的数据;
·若整个消息中无字母及其他符号,且汉字字符中低字节值均大于63,即k=1,则这种情况下信息嵌入量最小,整个消息中可嵌入6.25%的数据;
·其他情况下,整个消息中可嵌入数据率在6.25%-43.75%之间。
综上所述,本发明提供了一种基于unicode编码的信息嵌入与提取方法,该方法在基于unicode编码的文本消息中,通过对字符高低字节的数据分析、分段性编码及不同域变换处理,提出了一种无额外附加信息、无损的信息嵌入与提取方法。该方法能够在在不增加信道资源的情况下,提高系统的传输容量,适用于各种不同类型数据传输系统中。因此,本发明适合在空间信息网络中使用,特别是在卫星通信系统和导航系统中,具有广阔的应用前景和实用性。
本发明说明书中未作详细描述的内容属于本领域技术人员的公知技术。
- 还没有人留言评论。精彩留言会获得点赞!