基于ASIC与VGG16的图像分类加速方法及装置与流程
基于asic与vgg16的图像分类加速方法及装置
技术领域
[0001]
本发明涉及的是一种人工智能处理领域的技术,具体是一种基于asic与vgg16的图像分类加速方法及装置。
背景技术:
[0002]
现有的深度神经网络一般采用gpu进行加速运算,为了满足嵌入式系统中低功耗小体积的需求,则广泛使用专用于集成电路(asic)图像分类的卷积神经网络vgg16进行处理。
技术实现要素:
[0003]
本发明针对现有深度学习技术必须依赖功耗高、体积大的gpu的问题,提出一种基于asic与vgg16的图像分类加速方法及装置,通过将检测图片与网络权重预先存储在外部存储中,加速模块读取外部存储的数据,以专用集成电路芯片或高性能现场可编程逻辑阵列为平台,利用专用集成电路芯片或高性能现场可编程逻辑阵列高效率的运算能力,对深度学习网络vgg16图像分类网络进行加速,从而实现小体积、低功耗的图像分类加速模块。
[0004]
本发明是通过以下技术方案实现的:
[0005]
本发明涉及一种基于asic与vgg16的图像分类加速方法,通过将待实现的卷积神经网络配置为相应的asic控制指令,然后通过读取预先存储在外部存储中的检测图片与网络权重,通过asic并行实现vgg16图像分类神经网络的运算并得到图像分类结果。
[0006]
所述的待实现的卷积神经网络为vgg16。
[0007]
所述的asic控制指令包括:读指令、写指令、读操作或写操作时连续读取或写入数据burst的次数、数据类型的判别信号、计算该层时读取的次数和写入的次数、多次进行读写操作时每一次操作的地址偏移量。技术效果
[0008]
与现有技术相比,目前大部分asic加速卷积神经网络中,主要以对网络的加速为主,而本发明以asic芯片或高性能fpga为平台,利用asic与fpga高效率的运算能力,对神经网络中得vgg16图像分类网络进行实现,从而实现小体积、低功耗的图像分类加速。
附图说明
[0009]
图1为实施例流程示意图;
[0010]
图2为实施加速系统示意图;
[0011]
图3为运算单元簇示意图;
[0012]
图4为基本运算单元示意图;
[0013]
图5为控制指令示意图;
[0014]
图6为基本运算单元的卷积计算的数据流组织形式示意图;
[0015]
图7为实施例效果示意图。
具体实施方式
[0016]
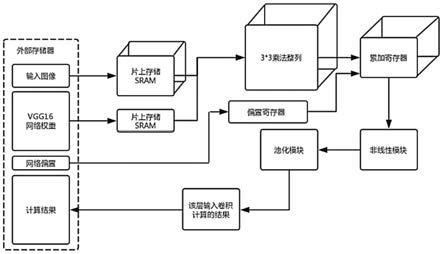
如图2所示,本实施例涉及的一种基于asic与vgg16的图像分类加速系统,包括:综合控制模块、存储控制模块、数据读入模块、运算单元簇模块、池化模块和输出缓存模块,其中:综合控制模块控制网络的分层处理流程,存储控制模块处理ddr与片上ram间的数据搬移,数据读入模块将ddr控制器从存储控制模块的存储器中读入的数据分配给片上权重缓存单元和数据缓存单元,并控制各个缓存单元到运算单元簇模块的基本运算单元的数据输出,池化模块读取运算单元簇模块的数据缓存单元,并进行池化操作,输出给输出缓存输出缓存模块,输出缓存模块收到池化模块的输出结果,组织成为适合ddr写操作的数据并在满足条件时向fifo中写入ddr写操作指令。
[0017]
所述的分层处理流程包括:启动vgg16的数据处理、向ddr发出当前层的数据搬移指令、广播当前层的各类信息、发出换层复位信号和换输出通道信。
[0018]
当每一层卷积计算开始时,存储控制模块接收微控制器发给指令队列(fifo)的数据搬移指令,依次从ddr中读取权值和输入数据;有输出数据生成需要写回时,由输出缓存模块发出请求,经由ddr控制器将数据写回;ddr控制器同时处理来自asic的控制指令队列,并将广播信号发送至各模块,告知各模块当前层的运算方式。当前ddr带宽为256bits,ddr一次burst为4/8/16个ddr带宽。
[0019]
所述的数据读入模块包括1个权重缓存单元,114x4个分布式的数据缓存单元,其中:权重缓存单元中存放当前层所有的权值,数据缓存单元中存放输入数据。
[0020]
所述的数据缓存单元分成四组,每组有114个,从四组中选取三组分别对应作为pe的三组(9个)输入,每个数据缓存单元设计成为一个16-bit宽的寄存器。
[0021]
如图3所示,所述的运算单元簇模块由112个基本运算单元(pe)组成,每个pe为3级流水架构,用于处理一个3x3卷积操作。第一级做9个乘法,第二级做三输入的加法,第三级做四输入的加法(三个前级输出、一个来自数据缓存单元的累加数据)。每个pe分别接收9个数据缓存单元的数据输入、来自权重缓存单元的9个权值输入以及来自存储控制模块的前n个输入通道的累加结果。每个pe将当前层当前pe对应的所有临时数据输出至数据缓存单元。
[0022]
优选地,当当前层需要进行池化操作,则每读取两拍数据,做一次(2,2)池化;如果不需要池化,则每读取一组数据,直接输出给输出缓存模块。
[0023]
如图4所示,为每个基本运算单元(pe)。本实施例以3*3的pe阵列为例,同时完成一个尺寸为3的卷积窗口的乘加操作,其他尺寸的卷积也可以通过配置参数完成对pe结构的更新。
[0024]
如图1所示,为本实施例基于上述系统的图像分类加速方法,预先将所要检测图片以224x224像素的尺寸与预先训练好的网络权重及偏置存储于片外ddr上。
[0025]
步骤1)将vgg16的每一层的结构,输入尺寸、输出尺寸、输入通道、输出通道、卷积核大小,设置为相应的控制指令,每一层的结构数据以二进制数字的方式分别存入控制指令队列中对应的位置,运算时直接可由存储的位置信息判断读取的数据为该卷积层的何种信息。
[0026]
如图5所示,所述的控制指令的队列,包括:读指令、写指令、读操作与写操作的起始地址read_addr、write_addr,每个地址占用32bit,每条fifo控制指令为6x32bit;rd_bl、
wr_bl分别为读操作或写操作时连续读取或写入数据burst的次数,ot*为数据类型的判别信号,判断读取的数据是feature map还是网络权重,read_num、write_num分别为计算该层时读取的次数和写入的次数,相当于该层输入的通道个数与该层输出的通道个数,read_offset、write_offset为多次进行读写操作时,每一次操作的地址偏移量。
[0027]
步骤2)将ddr中的图像、网络权重和偏置暂存入数据缓存单元与寄存器中;
[0028]
步骤3)当暂存的数据量达到预设值后,将其输入3*3的乘法阵列进行神经网络的卷积运算;
[0029]
步骤4)完成一次卷积运算结束后,将计算结果暂存于片上寄存器中,当这一层的运算全部计算完成之后,将整层计算结果累加得到该层的计算结果;
[0030]
本实施例中采用的基本运算单元(pe)为112个,每次完成112个3*3大小的卷积运算,在基本运算单元一次计算完112个卷积之后将计算出的中间值的结果暂存于存储控制模块中,等待这一次的输出通道所有的卷积运算全部计算完成,再将存储控制模块中的卷积计算结果进行累加操作,从而得出一次输出通道的正确结果。
[0031]
如图6所示,为运算单元簇模块中的基本运算单元的卷积计算的数据流组织形式,具体包括:
[0032]
1)遍历输入层的特征向量:将该层的特征向量与该次计算的权重进行滑窗式的卷积计算。
[0033]
2)对输入各层进行遍历,将每一层的特征向量都与该次计算的权重进行卷积计算,之后将各输入层的计算结果进行相加,得到对应输出层的结果。
[0034]
3)对该层的所有权重进行遍历,计算出不同输出层的所有卷积结果。
[0035]
步骤5)将整层计算结果输入池化模块进行池化处理后,将池化运算结果排序后选出计算结果最高的前5个数据与其编号,并对照图像分类标签输出图像分类的结果。
[0036]
如图7所示,为候选图库ilsvrc2012验证集图库,选中的图片为ilsvrc2012_val_00000001、ilsvrc2012_val_00000002、ilsvrc2012_val_00000003。
[0037]
表1图像分类结果准确率
[0038]
表2加速模块使用资源量片上寄存器数量片上存储大小dsp使用数量片外存储大小5552236mb896150mb
[0039]
上述具体实施可由本领域技术人员在不背离本发明原理和宗旨的前提下以不同的方式对其进行局部调整,本发明的保护范围以权利要求书为准且不由上述具体实施所限,在其范围内的各个实现方案均受本发明之约束。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1