一种基于关系模型的RDF图和属性图统一存储方法与流程
本发明涉及知识图谱领域,rdf存储与和属性图存储。
背景技术:
知识图谱作为符号主义发展的最新成果,是人工智能的重要基石。各领域中大规模知识图谱的构建和发布对知识图的数据管理提出了新的挑战。知识图数据模型基于图结构,用顶点表示实体、边表示实体之间的关系,这种通用的数据表示可以自然地描述现实世界中事物之间的广泛联系。
目前,知识图谱有两种主流数据模型,即rdf(resourcedescriptionframework,资源描述框架)模型和属性图模型。前者已由w3c(worldwidewebconsortium)标准化,后者已广泛用于图形数据库。rdf图模型具有较强的逻辑理论背景和较完善的数据模型特征。与rdf模型类似,属性图模型内置了对结点和边的属性的支持。虽然属性图还没有标准化,但是随着图数据库的应用,属性图在工业界中已经得到了广泛的认可。rdf图的超图结构证明了rdf图模型比属性图模型具有更强的表达能力,但至今依然没有一个统一的存储方案来有效地对知识图谱进行存储和管理。
经过几十年的发展,关系模型已经具有了很高的成熟度。关系数据模型(relationaldatamodel)具有简洁而通用的关系结构,并且使用具有严格数学定义的关系代数表达式来表示关系上的操作和约束。因此,这为使用关系数据模型来统一存储rdf和属性图提供了坚实的理论基础。
1.现有的rdf图存储方案:
现有的rdf图数据典型的管理方案主要有两种:即基于关系的方法和基于图的方法。基于关系的方法以多种方式将rdf图数据映射到关系表中,然后对它们执行sparql查询。另一种基于图的管理方案将rdf和sparql查询建模为图,并通过子图匹配来进行查询。
(1)基于关系的存储方案
关系数据库是目前应用最广泛的数据库管理系统。基于关系数据库的存储方案是目前知识图谱数据的主要存储方法。三元组表直接存储rdf数据;水平表每行记录一个主语的所有谓语和宾语;属性表根据主语的类来构建数据表,并提出了属性表方案和技术来解决三元组表方案中的查询性能问题;垂直划分根据谓词来构建数据;六重索引将三元组全部6种排列对应的建立为6张表。以及最近几年的db2rdf通过建立面向实体的存储结构来削减查询中求笛卡尔积的操作以提升查询的效果。
(2)基于图的存储方案
基于图的存储方案优点是它能够给维护rdf数据的原始表示并强制执行sparql的预期语义。例如gstore和chameleon-db系统都遵循这种方案。这种方案的缺点是子图匹配的代价过大,图同态是np完全的。
2.现有属性图存储方案:
属性图模型对于结点属性和边属性具备内置的支持。属性图是有向的,带标记的,多属性的图。neo4j是一个支持事务应用程序和图形分析的原生图数据库,支持事务应用程序。它是目前最流行的属性图数据库。
技术实现要素:
针对上述现有技术,本发明根据知识图谱的两种数据模型rdf图模型和属性图模型的定义、特点以及关系表的存储理念,设计了知识图谱的统一的存储方案,保留rdf图和属性图的全部语义信息,来解决rdf图和属性图的语义表达能力的差异的问题,并降低了大规模数据的冗余,实现高效的查询。
为了解决上述技术问题,本发明予以实现的技术方案是:基于关系模型的rdf图和属性图统一存储方法,将rdf图和属性图两种逻辑模型在底层以关系表的物理模型存储,包括rdf图的底层存储和属性图的底层存储。
进一步讲,本发明基于关系模型的rdf图和属性图统一存储方法,其中,所述rdf图的底层存储,包括对于rdf图中点的转换,对于rdf图中边的转换和对于rdf中的具体化技术的转换;
对于rdf图中点的转换,步骤如下:
1-1)读入rdf三元组;若为<u1><rdf:type><u2>形式的rdf三元组,执行1-2),若为<u1><u2><l>形式的rdf三元组,且u1为结点类型关系表中的元组,执行1-4);
1-2)检查是否已经创建记录结点类型u2的关系表,若已创建结点类型u2的关系表,执行1-3);若未创建,则先创建结点类型u2的关系表,该关系表具有两列属性:id、properties;
1-3)为结点u1设置一个id值,将u1作为一个元组插入结点关系表u2中,执行1-1)循环读入rdf三元组;
1-4)将{u2:l}添加到u1元组的properties属性中,执行1-1)循环读入rdf三元组;
对于rdf图中边的转换,步骤如下:
2-1)读入rdf三元组;若为<u1><u2><u3>形式的rdf三元组,执行2-2);若为<u1><u2><l>形式的rdf三元组,且u1为边类型关系表中元组,执行2-4);
2-2)检查是否已经创建了记录边类型为u2的关系表;若已创建边结点类型u2的关系表,执行2-3);若未创建,则先创建边类型u2的关系表,该关系表具有四列属性:id、start、end、properties;
2-3)为该关系设置一个id值,将结点u1的id赋给start,将结点u3的id赋给end,将该元组插入边类型u2的关系表;执行2-1)循环读入rdf三元组;
2-4)将{u2:l}添加到u1元组的properties属性中,执行2-1)循环读入rdf三元组;
本发明中,所述rdf图的底层存储是,rdf三元组形式<u1><rdf:type><u2>在底层以存储点的关系表u2中一个元组u1形式存储;rdf三元组形式<u1><u2><l>在底层以存储点的关系表中在properties列中具有属性u2其值为l{u2:l}一个元组u1形式存储;rdf三元组形式<u1><u2><u3>在底层以存储边的关系表u2中以具有起始点u1的id值、终结点u3的id值为属性的一个元组形式存储。
本发明对于rdf中的具体化技术设计了针对其特有的存储形式:即一个三元组中谓语,作为另一个三元组中的主语或者宾语。在对这种rdf图数据进行存储时,将这个谓语分别在存储边的表和存储点的关系表中进行存储,用唯一的点id和边id进行标识,系统中额外维护一张edge_vertex表,用于存放该谓语在边和点两张关系表中存储的id值之间的一一对应关系。对于rdf中的具体化技术的转换方式如下:
3-1)读入<u1><u2><u3>三元组,u1为边类型关系表中的元组;检查是否已经创建了记录边类型为u2的关系表;若已创建边结点类型u2的关系表,执行3-2);若未创建,则先创建边类型u2的关系表,具有四列属性:id、start、end、properties;
2)为边u1设置点id,并将u1的点id和边id插入系统表edge_vertex中;
3)为该关系设置一个id值,将边u1的点id赋给start,将结点u3的id赋给end,将该元组插入边类型u2的关系表;执行3-1)循环读入rdf三元组。
本发明基于关系模型的rdf图和属性图统一存储方法,其中,所述属性图的底层存储,包括:对于属性图中具有同一标签的结点或边,用一个该标签命名的关系表进行存储,并维护属性图中各点和边的属性及属性值;其中,点标签的关系表中有两个属性,包括结点的唯一标识符id和结点的属性properties;边标签的关系表中有四个属性,包括边的唯一标识符id,边的起始点标识start,边的终点标识end,及边的属性properties。
本发明中,所述属性图的底层存储是,属性图的结点在系统底层存储点的关系表中,以一个元组(id,properties)的形式进行存储;属性图的边在系统底层存储边的关系表中的一个元祖(id,start,end,properties)的形式进行存储。
与现有技术相比,本发明的有益效果是:
本发明提出的基于关系模型的rdf图和属性图统一存储方法,可以同时实现对rdf图和属性图的存储查询,并有效实现了rdf在数据库中管理。本发明存储方法在开源数据库agensgraph上进行验证,实现大规模rdf数据和图数据的存储与查询,初步实现了rdf图和属性图的互操作。
附图说明
图1是本发明基于关系模型的rdf图和属性图统一存储方法设计流程图;
图2是本发明基于关系表的rdf图和属性图统一存储方法示意图;
图3是本发明中rdf图在底层关系表中的存储形式;
图4是本发明中具体化的rdf图在底层关系表中的存储形式;
图5是本发明中属性图在底层关系表中的存储形式
图6是本发明存储方法中存储时间随存储量的变化趋势;
图7是本发明存储方法中存储空间随存储量的变化趋势;
图8是本发明中存储方法和转换后使用agensgraph导入存储时间对比图。
具体实施方式
下面结合附图及具体实施例对本发明做进一步的说明,但下述实施例绝非对本发明有任何限制。
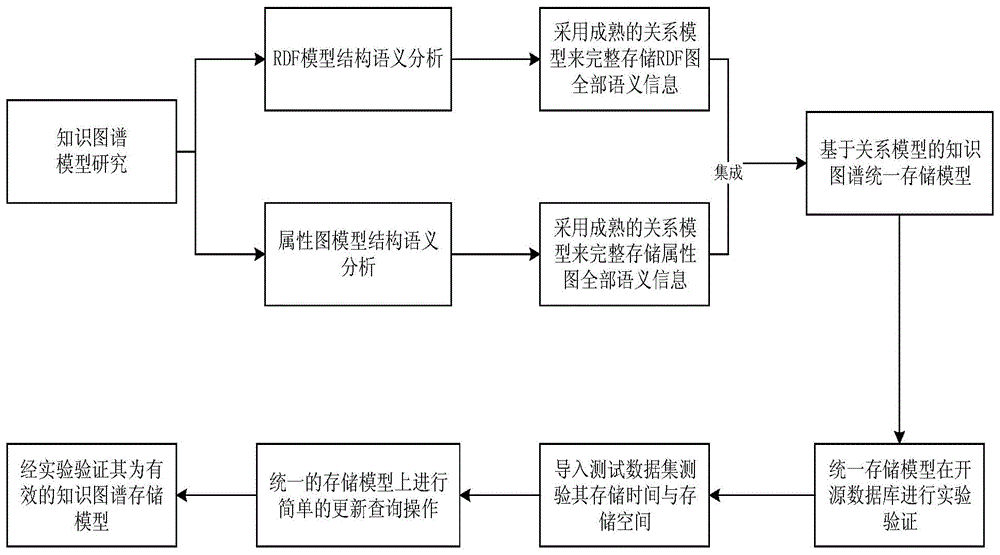
如图1所示,本发明基于关系模型的rdf图和属性图统一存储方法的设计思路是,对知识图谱的主流数据模型——rdf模型和属性图模型的结构和语义进行分析,采用关系模型来存储其表达的语义信息,设计基于关系模型的知识图谱统一存储模型,并基于开源数据库,导入并存储知识图谱,测试存储空间和存储时间,进行简单的更新查询操作从而验证知识图谱存储方案的有效性。
如图2所示,本发明提出的一种基于关系模型的rdf图和属性图统一存储方法,是将rdf图和属性图两种逻辑模型在底层以关系表的物理模型存储,包括rdf图的底层存储和属性图的底层存储。即将rdf图和属性图的全部语义信息在底层以关系表形式存储,对于rdf三超图结构,维护一张系统表实现管理rdf图中某些边的边点双份存储。
一、本发明中的所述rdf图的底层存储
参见图3,本发明中的所述rdf图的底层存储包括对于rdf图中点的转换,对于rdf图中边的转换和对于rdf中的具体化技术的转换;具体内容如下:
对于rdf图中点的转换,步骤如下:
1-1)读入rdf三元组;若为<u1><rdf:type><u2>形式的rdf三元组,执行1-2),若为<u1><u2><l>形式的rdf三元组,且u1为结点类型关系表中的元组,执行1-4);
1-2)检查是否已经创建记录结点类型u2的关系表,若已创建结点类型u2的关系表,执行1-3);若未创建,则先创建结点类型u2的关系表,该关系表具有两列属性(id、properties);
1-3)为结点u1设置一个id值,将u1作为一个元组插入结点关系表u2中,执行1-1)循环读入rdf三元组;
1-4)将{u2:l}添加到u1元组的properties属性中,执行1-1)循环读入rdf三元组;
对于rdf图中边的转换,步骤如下:
2-1)读入rdf三元组;若为<u1><u2><u3>形式的rdf三元组,执行2-2);若为<u1><u2><l>形式的rdf三元组,且u1为边类型关系表中元组,执行2-4);
2-2)检查是否已经创建了记录边类型为u2的关系表;若已创建边结点类型u2的关系表,执行2-3);若未创建,则先创建边类型u2的关系表,该关系表具有四列属性(id、start、end、properties);
2-3)为该关系设置一个id值,将结点u1的id赋给start,将结点u3的id赋给end,将该元组插入边类型u2的关系表;执行2-1)循环读入rdf三元组;
2-4)将{u2:l}添加到u1元组的properties属性中,执行2-1)循环读入rdf三元组;
本发明中,rdf图的底层存储有下述情形:
rdf三元组形式<u1><rdf:type><u2>在底层以存储点的关系表u2中一个元组u1形式存储。
rdf三元组形式<u1><u2><l>在底层以存储点的关系表中在properties列中具有属性u2其值为l{u2:l}一个元组u1形式存储。
rdf三元组形式<u1><u2><u3>在底层以存储边的关系表u2中以具有起始点(u1的id)、终结点(u3的id)属性的一个元组形式存储。
rdf中的具体化技术:即一个三元组中谓语,作为另一个三元组中的主语或者宾语。在对这种rdf图数据进行存储时,将这个谓语分别在存储边的表和存储点的关系表中进行存储,用唯一的点id和边id进行标识,系统中额外维护一张edge_vertex表,用于存放该谓语在边和点两张关系表中存储的id值之间的一一对应关系。
如图3所示,结点u1和u2各有一条指向u3且类型为rdf:type的边,则在关系表u3中存储两个结点的id,并且结点u1有一条类型为u5,属性值为l1的边。则在u3关系表的id1的元组中,添加properties的属性值为{u5:l1}。
系统维护一个特殊的关系表(edge_vertex)的具体化技术是,
3-1)读入<u1><u2><u3>三元组,u1为边类型关系表中的元组;检查是否已经创建了记录边类型为u2的关系表;若已创建边结点类型u2的关系表,直接执行3-2);若未创建,则先创建边类型u2的关系表,具有四列属性(id、start、end、properties)
3-2)为边u1设置点id,并将u1的点id和边id插入系统表edge_vertex中;
3)为该关系设置一个id值,将边u1的点id赋给start,将结点u3的id赋给end,将该元组插入边类型u2的关系表。执行3-1)循环读入rdf三元组。
图4中,u1、u2和u3均有rdf:type的边指向u4,即其类型都为u4,在u4关系表中存储三个结点的id。u1和u2之间的边u5,通过边u6与结点u3相连,在系统表edge_vertex中插入u5的边id(id5)和点id(id5')来实现具体化。
rdf图中结点指向边以及边指向边的情况与上述情况类似。
二、本发明中的所述属性图的底层存储
rdf图为三超图结构,而属性图为有向图结构,所以属性图的表达能力要弱于rdf图。因此,对于属性图在关系表中的存储,只需要按照基本的存储方案进行转换即可。
对于属性图中的结点和边,分别为其创建对应标签类型的存储结点和边的关系表,将属性图中所有的结点和边及其各自的属性和属性值作为新的元组插入到对应标签的关系表中。
对于属性图中具有同一标签的结点或边,用一个该标签命名的关系表进行存储,并维护属性图中各点和边的属性及属性值;其中,点标签的关系表中有两个属性,包括结点的唯一标识符id和结点的属性properties;边标签的关系表中有四个属性,包括边的唯一标识符id,边的起始点标识start,边的终点标识end,及边的属性properties。
如图5所示,展示了属性图在底层关系表中存储形式,结点n1和n2通过r3相连,结点n1和n2对应关系表中vlabel0的id1和id2,保存其各自的属性properties1和properties2,边r3对应关系表中的elabel0,保存边的起始和结束结点的id以及属性值properties3。
本发明中,对属性图中的点和边进行存储:属性图的结点在系统底层存储点的关系表中,以一个元组(id,properties)的形式进行存储;属性图的边在系统底层存储边的关系表中的一个元祖(id,start,end,properties)的形式进行存储。
三、实验验证
实验环境,硬件配置:联想笔记本一台(thinkpad),2核cpu,inteli5处理器,频率为2.31ghz,内存8gb,磁盘容量为512gb。软件配置:操作系统为64位centos7.0。实现语言为c语言。
对标准合成数据集lubm中的lubm10,lubm20,lubm30,lubm40和lubm50进行划分。
将本发明存储方法在开源数据库agensgraph中进行验证,测得lubm10,lubm20,lubm30,lubm40和lubm50导入agensgraph的存储时间(如图6所示)、存储空间(如图7所示)、数据集特征(见表1),存储的点的数量和边的数量(见表2)。
参见图8,将rdf数据集转化为agensgraph支持的属性图数据格式导入和将rdf数据集直接映射为底层关系表存储时间进行对比,发现本方案显著减少了rdf数据集存储的时间,本发明存储方法更适合大规模rdf图的存储。
本发明存储方法在开源图数据库agensgraph中导入的rdf数据集,参见表3,在lubm50数据集中将14种lubm标准sprql查询转换为cypher进行查询,得到了正确的查询结果和较少的查询时间,实现sprql和cypher查询互操作。
表1实验数据集的特征
表2实验数据集中的rdf图的点边数量
表3在lubm50的数据集上的查询性能测试
经过实验验证,本发明存储方法实现了大规模的知识图谱数据存储与管理,并有效减少了数据的冗余,具有较强的应用价值。
尽管上面结合附图对本发明进行了描述,但是本发明并不局限于上述的具体实施方式,上述的具体实施方式仅仅是示意性的,而不是限制性的,本领域的普通技术人员在本发明的启示下,在不脱离本发明宗旨的情况下,还可以做出很多变形,这些均属于本发明的保护之内。
- 还没有人留言评论。精彩留言会获得点赞!