一种基于图文融合的生成式摘要生成方法与流程
本发明属于人工
技术领域:
,涉及一种基于图文融合的生成式摘要生成方法。
背景技术:
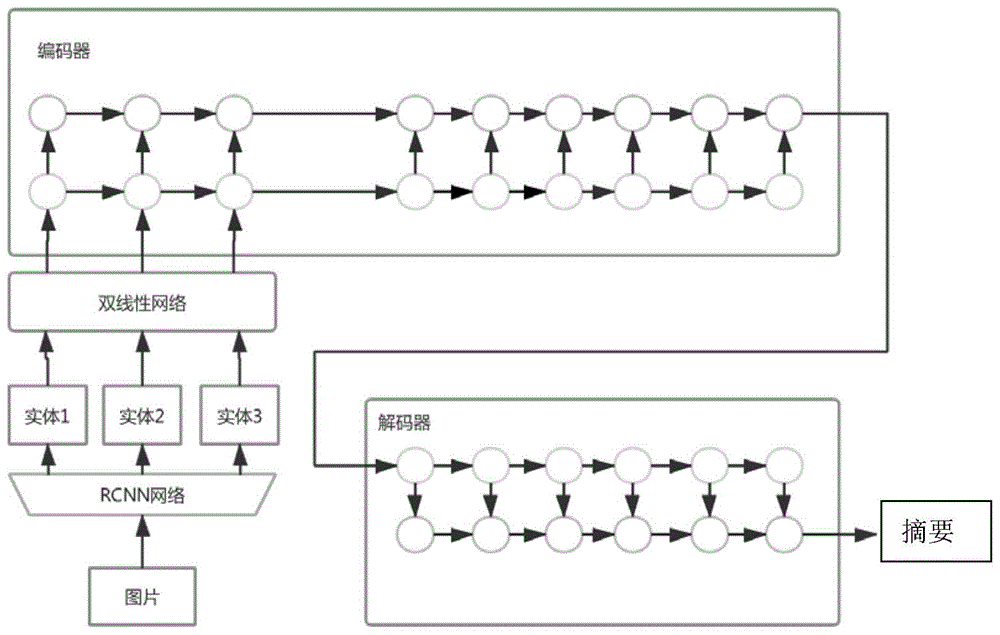
:现有的生成式摘要方法主要基于深度学习的seq2seq框架和注意力机制实现的。seq2seq框架主要由编码器(encoder)和解码器(decoder)组成,编码和解码都由神经网络实现,神经网络可以是递归神经网络(rnn)或卷积神经网络(cnn)。其具体过程如下,编码器将输入的原文本编码成一个向量(context),该向量是原文本的一个表征。然后,解码器负责从这个向量提取重要信息、生成文本摘要。注意力机制为了解决长序列到定长向量转化而造成的信息损失的瓶颈,即在解码器中将注意力关注于对应的上下文。虽然基于深度学习的seq2seq框架和注意力机制在摘要生成领域取得了一定的成绩,但是其趋向于生成高频词,从而会导致关键实体偏差的问题。一般情况下,关键实体的偏差有两种形式:第一、由于硬件资源的限制,一般会采用有限的词表,文章中的某些生僻关键实体词并不会出现在词表中,导致生成的摘要中缺失这些关键实体;第二、相对低频实体被忽略。为了关键实体偏差的问题,本发明提出一种基于图文融合的生成式摘要方法,该方法引入图片区域信息,联合注意力机制将图片特征有机融合于文本内容中,动态调整关键实体信息的权重,从而提升生成摘要的质量。技术实现要素:本申请提案能解决现有生成式摘要关键实体缺失的问题,从而提升生成摘要的质量以及可读性。以上的技术问题是通过下列技术方案解决的:一种基于图文融合的生成式摘要生成方法,所述摘要生成过程如下:步骤1,对给定的文本数据集进行去停用词、特殊词标记等数据预处理操作,将数据混洗后划分为训练集、验证集和测试集。文本数据集中的每一样本是一三元组(x,i,y);其中,x是文本,i是对应的图像(即与x匹配的图像),y是文本x的摘要。步骤2,对步骤1中文本数据集对应的图像提取主要特征实体,并将其表示成与文本同维度的图像特征。特征实体包括全文的图表示以及关键实体的三个图像表示;以文本a为例,如有30个词,词向量长度为128维,则文本是30个128维的向量,图像特征包括全局,最大区域的三个实体,所以是4个128维的向量,合在一起,是34个128维的向量。步骤3,一种基于图文融合的生成式摘要模型,并使用步骤1的训练集和步骤2处理后的训练集对应的图像特征对模型训练。步骤4,待摘要生成模型训练完毕,用测试集测试模型的性能,可以使用rouge评价指标。步骤5,在实际应用中,在交互界面输入一条文本和对应图像并生成该图像的图像特征,然后将输入文本及其对应的图像特征输入到训练后的生成式摘要模型,得到一条对应的摘要。所述步骤1中,对文本数据进行预处理过程如下:步骤1.1,将给定的原始数据集进行文本,摘要和图像一一对应,得到每一样本的三元组(x,i,y)。步骤1.2,同时对文本和摘要去除特殊字符、表情符、全角字符等。步骤1.3,将步骤1.2得到的数据集,使用“tagurl”替换所有超链接url,使用“tagdata”替换所有日期,使用“tagnum”替换所有数字,使用“tagpun”替换所有标点符号。步骤1.4,将1.3清洗后的数据使用停用词表过滤停用词。步骤1.5,将文本、摘要和图像一一对应地同时混洗,按比例切分成训练集、验证集和测试集。步骤1.6,根据数据集构建一定长度的词表,并将文本和摘要中的字没有出现在字典中的表示成“unk”,在文档开始添加标记“bos”,结束添加“eos”,将文本和摘要分别处理成固定长度,多余的字直接截断,小于长度的用占位符“pad”填充。步骤1.7,使用gensim的wordembedding工具包,将文本摘要数据集中的每个字用一个固定维度k的字向量表示,包括步骤1.6的特殊标记。所述步骤2中,一种基于图文融合的生成式摘要模型如图1所示,包含三个模块:分别是特征提取模块、特征融合模块以及摘要生成模块,步骤2是详细的特征提取方法,详情如下:步骤2.1,将步骤1.5中的图像一一使用区域卷积神经网络(regioncnn,rcnn)工具来捕获对应图像的关键实体特征。区域卷积神经网络算法包括四个步骤,分别是候选区域生成、特征提取、类别标志以及位置修整,详细过程如下:步骤2.1.1,首先应用过分割技术,将每一图像分割成尽可能多的独立的区域,通常该区域数超过1000个。然后,对同一图像的各区域按照一定规则进行合并,合并规则有相近颜色合并、近似纹理合并等。最后,将该过程中合并后出现的所有区域作为初步候选区域。步骤2.1.2,使用一个cnn网络对步骤2.1.1中出现的每一个初步候选区域进行特征提取。步骤2.1.3,将每个初步候选区域得到的特征表示输入到支持向量机(svm)分类器中,判别是否是对应的实体标签,如是标记为1,进行步骤2.1.4,如不是,标记为0,删除该候选区域。步骤2.1.4,使用回归(regression)模型,根据类别标志的结果修正初步候选区域的边框位置。具体地,对每一类目标,使用一个线性脊回归器(linerridgeregression,lrr)进行精修。步骤2.2,将2.1中得到的每个图像的区域实体特征按照区域大小排序,选取区域最大的前三个区域实体特征作为候选区域。步骤2.3,统一使用vgg-16网络,如图2所示,将2.2得到的每一个候选区域特征使用fc7层表示成4096维度的图像特征,将候选区域的全局向量也表示成4096维度的图像特征。所述步骤3中,特征融合以及摘要生成详细步骤如下:步骤3.1,使用双线性网络将2.3得到的每一个4096维图像特征转化为与文本同维度的特征,可以表示为it=wiiv,其中iv表示步骤2.3得到的图像特征,wi是双线性网络的参数,it表示与文本同维度的图像特征向量。步骤3.2,对于同一样本,将步骤1.7得到的该样本的文本向量和步骤3.1得到的该样本的图像特征向量进行拼接,文本和图像拼接记为a,与原有摘要y合起来得到二元组(a,y),重新得到向量化表示的训练集、验证集和测试集。步骤3.3,将步骤3.2得到新的训练集采样k个样本,依次输入到编码器中,得到文本和图像的联合编码hs,通过中间语义向量ct,计算解码器在当前状态ht,从而实现特征融合,详细设置如下:摘要生成模块使用融合的特征生成摘要。将训练集的输入样本表示成(a,y),其中a={a1,a2,…,an}表示文本和图像n个特征,人工摘要表示y={y1,y2,…,ym},生成摘要用表示。在编码阶段,将当前时刻i的输入的特征向量表示为ai(文本和图像拼接的向量),上一时刻的隐层输出记为hs-1,那么当前时刻i的隐层输出为hs=f(hs-1,ai)。在编码阶段,使用ht表示当前时刻i解码器的隐状态。通过转移矩阵wa计算当前状态下的ht与hs的关联程度,即score(ht,hs)=htwahs,将其归一化后,有从而得到中间语义向量ct=at(s)·hs,及对应的解码器得到的隐状态是通过参数网络wc和对应的激活函数得到的,其表达式是步骤3.4,将步骤3.3当前状态下的解码器的隐状态通过softmax层,得到生成摘要,表示为其中,yt是生成摘要y的第t个词,a是样本的文本向量和图像特征向量拼接特征,ws是参数矩阵。步骤3.5,使用优化目标重复步骤3.3和3.4训练模型,直至模型收敛;n是训练集中的样本量总个数,θ是为模型参数,yn是摘要的第n个词。所述步骤4中,评测模型如下所示:步骤4.1,将步骤3.2得到的测试集的特征输入到步骤3.5训练好的模型中,得到对应的摘要;步骤4.2,将测试集对应的人工摘要与步骤4.1对应的生成摘要一一对应,得到步骤4.3,将送入到rouge工具包评测rouge-1,rouge-2和rouge-l的f-测度。所述步骤4中,应用模型步骤类同于步骤4.1。与现有技术相比,本发明的积极效果为:本发明是多模态生成式摘要系统,引入了图像特征,图像特征是主要实体的信息,因此对应引入了实体的权重,相比于纯文本的生成系统,本发明生成的摘要可以有效地调整文本中实体的权重,在一定程度缓解未登录词的问题。附图说明图1为一种基于图文融合的生成式摘要模型图;图2为vgg-16网络模型图。具体实施方式为了使本发明的目的、技术方案及优点更加清楚明白,以下参照附图,对本发明作进一步详细说明。本实施方案采用多模态句子摘要数据集mmss,其是个一个包含文本、图像和摘要(x,y,i)三元组的数据集,其中文本和摘要来自广泛评测摘要系统的gigawords数据集,图像通过搜索引擎检索获得。最后,经过人工筛选获得(x,y,i)三元组数据集,其中包括训练集为66000个样本,验证集和测试集分别为2000个样本。步骤1,对数据集进行预处理。步骤1.1,将给定的原始数据集进行文本,摘要和图像一一对应,即(x,y,i)。步骤1.2,同时对文本和摘要去除特殊字符、表情符、全角字符,如“¥”,“300”等。步骤1.3,将步骤1.2得到的数据集,使用“tagurl”替换所有超链接url,使用“tagdata”替换所有日期,使用“tagnum”替换所有数字,使用“tagpun”替换所有标点符号。步骤1.4,由于mmss是句子级别的摘要,文本较短,因此在该数据集上不过滤对应的停用词。步骤1.5,将预处理好的文本摘要图像(x,y,i)一一对应地同时混洗,按比例切分成训练集、验证集和测试集。步骤1.6,根据数据集构建5千的字典,并将文本和摘要中的字没有出现在字典中的表示成“unk”,在文档开始添加标记“bos”,结束添加“eos”,将文本长度最长限制为120字,摘要为30字,多余的字直接截断,小于长度的用占位符“pad”填充。步骤1.7,使用gensim的wordembedding工具包,将文本摘要数据集中的每个词用一个固定维度256维的词向量表示,包括步骤1.6的特殊标记。步骤2,对步骤1中文本数据集对应的图像i提取主要特征实体,并将其表示成与文本同维度的图像特征。步骤2.1,将步骤1.5中的图像一一使用区域卷积神经网络(regioncnn,rcnn)工具来捕获对应图像的关键实体特征。步骤2.2,将2.1中得到的每个图像的区域实体特征按照区域大小排序,选取区域最大的前三个作为候选区域。步骤2.3,统一使用vgg-16网络,将2.2得到的每一个区域特征使用fc7层表示成4096维度的特征。步骤3,一种基于图文融合的生成式摘要模型,并使用步骤1和步骤2的训练集对模型训练。步骤3.1,使用双线性网络将2.3得到的每一个区域4096维特征转化为与文本同维度的256维特征。步骤3.2,将3.1得到的图像特征与1.7得到的文本拼接,图像特征放到文本最前面,bos标记后,重新得到向量化表示的训练集、验证集和测试集。步骤3.3,将步骤3.2得到新的训练集采样64个样本,依次输入到模型中训练。步骤3.4,重复步骤3.3,直至模型在训练集上收敛且在验证集上最优。步骤4,待摘要生成模型训练完毕,用测试集测试模型的性能,可以使用rouge评价指标步骤4.1,将步骤3.2得到的测试集的特征输入到步骤3训练好的模型中,得到对应的摘要;步骤4.2,将测试集对应的人工摘要与步骤4.1对应的生成摘要一一对应,得到步骤4.3,将送入到rouge工具包评测rouge-1,rouge-2和rouge-l的f-测度。为了比较本发明的基于图文融合的生成式摘要生成方法(简记为mse)相较于现有纯文本模型的优缺点,现分别采用直接选取前8个单词的lead,使用句法结构压缩的compress,原始seq2seq模型(abs),seq2seq模型+attention机制(abs+),使用分层注意力机制来学习多源数据的seq2seq框架(multi-source),记录各个模型对测试集生成摘要的rouge分的f-测度,实验结果如下表所示:系统rouge-1rouge-2rouge-llead33.4613.4031.84compress31.5611.0228.87abs35.9518.2131.89abs+a41.1121.7539.92multi-source39.6719.1138.03mse43.9423.1541.56实验结果表明基于图文融合的生成式摘要方法在引入图像信息后,三个rouge评分上均有一定的提升,尤其是rouge2的提升,更有效地说明了图文融合所带来的有效性。在实际应用中,在交互界面输入一条文本,应用阶段可以省略图像输入,使用“pad”填充,得到一条对应的摘要:例如输入文本:“japan’scollapsedkizucreditunion,thelargestsuchinstitutioninthecountry,hadincurredlossesof###billionyen-lrb-#.#billiondollars-rrb-,thebankofjapansaidwednesday.”得到摘要:“japan‘sbanklosses###billionyen”。可以从实际案例中得出,本发明所生成的摘要可以有效地生成“bank”这一实体。尽管为说明目的公开了本发明的具体内容、实施算法以及附图,其目的在于帮助理解本发明的内容并据以实施,但是本领域的技术人员可以理解:在不脱离本发明及所附的权利要求的精神和范围内,各种替换、变化和修改都是可能的。本发明不应局限于本说明书最佳实施例和附图所公开的内容,本发明要求保护的范围以权利要求书界定的范围为准。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1