一种基于知识图谱融合的犯罪预测方法及系统与流程
本发明涉及神经网络技术领域,具体涉及一种基于知识图谱融合的犯罪预测方法及系统。
背景技术:
随着大数据时代发展,人类大多数行为可被预测。犯罪预防也成为是大数据应用之一。当收集足够多纬度信息和有效数据后可以预测出潜在犯罪分子。大数据融入公安侦查过程中,运用海量数据做辅助侦查、改变侦查模式或通过分析嫌疑人自然属性等特征符号,同时利用大数据思维模式分析案件有效打击和减少犯罪,但这并不能挽回已发生犯罪行为所造成的损失,也无法阻止即将发生的潜在犯罪行为。
在犯罪预测领域中,gerberms通过回归分析、核内积密度(kde)、支持向量机(svm)等方法分析tweeter中的数据集,进行预测27类犯罪。但结果准确率、实验数据完整性较低。文章《城市高密度区域的犯罪吸引机制》表明,城市密度及环境也是导致犯罪重要因素之一。liaor加入地理、环境等信息,建立一种基于地区的犯罪预测模型。该实验,具有局部性且并无法准确预测结果,只做到标识出区域犯罪可能性。
因此研究犯罪行为与对象的多维信息之间的关系将具有重要意义,如何通过对对象的多维信息的分析构建一个理论体系与数学模型来预警犯罪事件的发生显得尤为重要。
技术实现要素:
本发明目的在于提供一种基于知识图谱融合的犯罪预测方法及系统,具有能根据对象的多维信息预测对象的犯罪概率的优点。
为实现上述目的,本发明所采用的技术方案是:一种基于知识图谱融合的犯罪预测方法,包括以下步骤:
s1:获取待测试对象的多维度信息,对所述多维度信息进行数据处理,得到待测试对象的个体知识图谱画像,执行s2;
s2:使用语料库对待测试对象的个体知识图谱画像进行向量化,将待测试对象的个体知识图谱画像转化为多个向量化矩阵,执行s3;
s3:多个所述向量化矩阵输入至综合判决神经网络中,判决神经网络判断待测试对象是否有犯罪嫌疑。
优选的,所述s1包括以下步骤:
s11:获取待测试对象的多维度信息,所述多维度信息为多个词汇组成的文字信息,执行s12;
s12:对所述多维度信息的多个词汇进行归一化处理,将多个词汇替换成多个标准词汇,将所述多维度信息转变为多个标准词汇组成的文字信息,执行s13;
s13:对所述多维度信息数据的多个标准词汇进行三元组化,得到待测试对象的个体知识图谱画像。
优选的,所述s1还包括以下步骤:
s121:使用语料库对待测试对象的多个词汇进行向量化,得到多个词向量,执行s122;
s122:计算单个词向量与多个标准词汇的对应概率,选择对应概率最大的标准词汇为该单个词向量的对应标准词汇,并将该单个词向量转化为该对应标准词汇,直至所述多维度信息的多个词汇均转变为标准词汇。
优选的,所述s122中使用连续词袋模型计算单个词向量与多个标准词汇的对应概率。
优选的,所述cbow模型以huffman树作为基础,huffman树中存在一条从根结点到词相对应路径pw,在pw路径上存在lw-1个分支,将每次分支都看成一次二分类,
其中,
优选的,所述连续词袋模型中词向量更新采用随机梯度上升法。
优选的,所述综合判决神经网络包括ddpg网络和cnn网络,ddpg网络对cnn网络的卷积核进行更新。
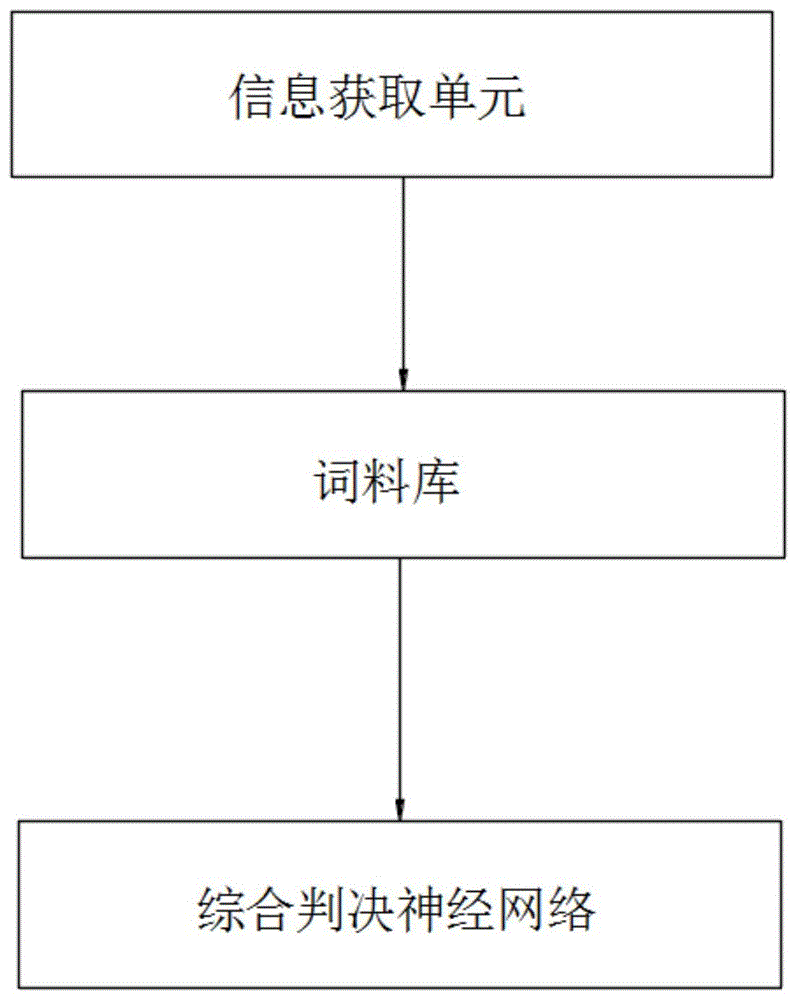
一种基于知识图谱融合的犯罪预测系统,包括:
信息获取单元,用于获取待测试对象的多维度信息并生成待测试对象的个体知识图谱画像;
词料库,用于对待测试对象的个体知识图谱画像进行向量化,将所述多维度信息转变为多个标准词汇组成的文字信息,并将待测试对象的个体知识图谱画像转化为多个向量化矩阵;
综合判决神经网络,根据词料库转化的多个向量化矩阵判决神经网络判断待测试对象是否有犯罪嫌疑。
优选的,所述词料库包括连续词袋模型。
优选的,所述综合判决神经网络包括ddpg网络和cnn网络,ddpg网络对cnn网络的卷积核进行更新。
综上所述,本发明的有益效果为:
1、本发明的过程中,用户无需另外收纳棋子,也无需将棋子套接在多个立柱上,具有方便用户使用的优点;
2、本发明的综合判决神经网络包括ddpg网络和cnn网络,ddpg网络对cnn网络的卷积核进行更新,具有对cnn网络的每个卷积核进行精准更新的优点。
附图说明
图1为本发明的一种基于知识图谱融合的犯罪预测系统的结构示意图;
图2为本发明的一种基于知识图谱融合的犯罪预测方法的示意图;
图3为本发明的实施例用于展示对多维度信息进行向量化处理的示意图
图4为本发明的实施例用于展示对多维度信息进行数据处理的示意图;
图5为本发明的实施例用于展示对将多维度信息转变为多个标准词汇组成的文字信息的示意图;
图6为本发明用于展示词料库的cbow模型的示意图;
图7为本发明用于展示综合判决神经网络的示意图;
图8为本发明用于展示综合判决神经网络对待测试对象的个体知识图谱画像的多维属性进行特征提取的示意图;
图9为本发明的实施例用于展示预测模型kfdcp的数据集大小与正确率的示意图;
图10为本发明的实施例用于展示预测模型kfdcp的迭代次数大小与正确率的示意图。
具体实施方式
下面结合本发明的附图1~10,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
参照图1,一种基于知识图谱融合的犯罪预测系统,包括:
信息获取单元,用于获取待测试对象的多维度信息并生成待测试对象的个体知识图谱画像;结合图3,本实施例中,信息获取单元从已知待测试对象的多维度信息中,提取出待测试对象的姓名、身高及体重等各项数据实体,将各实体之间通过关系连接,得到待测试对象的个体知识图谱画像。
词料库,用于对待测试对象的个体知识图谱画像进行向量化,将多维度信息转变为多个标准词汇组成的文字信息,并将待测试对象的个体知识图谱画像转化为多个向量化矩阵。
综合判决神经网络,根据词料库转化的多个向量化矩阵判决神经网络判断待测试对象是否有犯罪嫌疑。
参照图2,一种基于知识图谱融合的犯罪预测方法,包括以下步骤:
s1:获取待测试对象的多维度信息,对多维度信息进行数据处理,从各种类型数据源中提取出实体、属性以及实体间的相互关系,在此基础上形成本体化的知识表达,结合图4,本实施例中,从已知待测试对象的多维度信息中,提取出待测试对象的姓名、身高及体重等各项数据实体,将各实体之间通过关系连接,得到待测试对象的个体知识图谱画像,执行s2。
值得说明的是,本实施例中,待测试对象的多维度信息包括但不限于待测试对象的姓名信息、性别信息、出生地信息、居住地信息……
s2:使用语料库对待测试对象的个体知识图谱画像进行向量化,将待测试对象的个体知识图谱画像转化为多个向量化矩阵,执行s3。
s3:多个向量化矩阵输入至综合判决神经网络中,判决神经网络判断待测试对象是否有犯罪嫌疑。
一种基于知识图谱融合的犯罪预测方法中s1还包括以下步骤:
s121:使用语料库对待测试对象的多个词汇进行向量化,得到多个词向量,执行s122;
s122:计算单个词向量与多个标准词汇的对应概率,选择对应概率最大的标准词汇为该单个词向量的对应标准词汇,并将该单个词向量转化为该对应标准词汇,直至多维度信息的多个词汇均转变为标准词汇。
s12:对多维度信息的多个词汇进行归一化处理,将多个词汇替换成多个标准词汇,将多维度信息转变为多个标准词汇组成的文字信息,执行s13。
参照图6,词料库使用连续词袋模型计算单个词向量与多个标准词汇的对应概率。cbow模型以huffman树作为基础,huffman树中存在一条从根结点到词相对应路径pw,在pw路径上存在lw-1个分支,将每次分支都看成一次二分类,
其中,
整理得,
连续词袋模型的目标函数为
整理后最终的目标函数为
其中,c为语料库,w代表单词,neg(w)表示负样本集。
参数
化简后,
可得
本实施例中,词向量更新也采用随机梯度上升法,
整理得,context(w)的更新公式为
参照图3,s13:对多维度信息数据的多个标准词汇进行三元组化,得到多个向量化矩阵。结合图,本实施例中,假设根据待测试对象的多维度信息,语料库对待测试对象的多维度信息进行归一化工作后,提取出三个标准词汇:小明、小红、打。此时每个单词在语料库中唯一对应向量可设为[1,0,0]、[0,0,1]、[0,1,0]。
参照图7,综合判决神经网络包括ddpg网络和cnn网络,ddpg网络对cnn网络的卷积核进行更新,使得cnn网络的每个卷积核精准更新。ddpg是网络分为两部分,一部分为actor网,做出动作,另一类为critic网,即对a网做出的动作进行评判。当一个动作得到奖励多,则增加该动作概率,反之则减少该动作概率,以达到调整每一层参数,找到每层之间最优参数,具体步骤如下:
(1)a网中,根据behavior策略─是一个根据当前online策略μ和随机nt噪声生成的随机过程,从这个随机过程采样获得行动(at)值,at=μ(st|θμ)+nt(10),其中,st表示当前状态,θμ表示a网参数,nt表示噪声。
(2)做出动作得到回报ri和新状态,然后将(st,at,ri,st+1)存入记忆库中,作为训练数集。
(3)c网的θq更新公式为
其中,yi=ri+γq′(si+1,μ(si+1|θμ′)|qθ′),r表示reward,γ表示学习率。
(4)a网参数θμ的更新公式为:
其中,gradq从c网得来,表示:a下一个动作是什么才能获得最大q值。gradμ从a网得来,表示:a要怎么样修改自身参数才能使得a做这个动作概率最大。
参照图8,待测试对象的个体知识图谱画像具有多维属性,将个体知识图谱画像向量化后,实际就是含有n个向量形式的三元组集。在语义相似化后,将个体知识图谱画像中具有相同含义的r1三元组提取,构成矩阵,分发给神经网络提取该属性特征,最后输出1*m的属性矩阵,再将不同属性进行组合成n*m的结果矩阵。再将n*m的结果矩阵输入到综合判决神经网络,综合判决神经网络运算后得出结果r,判断待测试对象是否有犯罪嫌疑。本实施例中,综合判决神经网络输出结果为“0”,判断该待测试对象没有犯罪嫌疑,综合判决神经网络输出结果为“1”,判断该待测试对象有犯罪嫌疑。
值得说明的是,本实施例中,根据一种基于知识图谱融合的犯罪预测方法建立了预测模型kfdcp,与多模信息融合犯罪预测模型mifcp和核密度估计模型kde进行比较,对预测模型kfdcp的性能进行了研究。
参照图9,本实施例,对预测模型kfdcp的数据集大小和正确率关系进行了研究,当采用小数据集时,核密度估计模型kde和多模信息融合犯罪预测模型mifcp具有优势。当数据量提升,数据完整性提升。核密度估计模型kde和多模信息融合犯罪预测模型mifcp正确率逐渐达到瓶颈分别稳定在63.3%和73.01%。预测模型kfdcp建立数据之间的联系性并有效提取信息特征,有效特征数量增多,算法正确度随之提升,最高可达83.38%。
参照图10,本实施例,对预测模型kfdcp的迭代次数与正确率的关系进行了研究。随着迭代次数增加,各算法正确率都逐渐增长,但多模信息融合犯罪预测模型mifcp和核密度估计模型kde趋于瓶颈,分别稳定在75.1%和67.32%,而预测模型kfdcp随着迭代次数的增加,正确率可以达到88.3%。但需要大量时间和算力,低迭代次数(70<x<100)时,性能较多模信息融合犯罪预测模型mifcp和核密度估计模型kde也具有良好表现。
在本发明的描述中,需要理解的是,术语“逆时针”、“顺时针”“纵向”、“横向”、“上”、“下”、“前”、“后”、“左”、“右”、“竖直”、“水平”、“顶”、“底”、“内”、“外”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。
- 还没有人留言评论。精彩留言会获得点赞!