数据库制作装置以及检索系统的制作方法
本发明涉及制作检索用的数据库的数据库制作装置等。
背景技术:
以往,作为数据库制作装置,已知有专利文献1(日本特开2011-48527号公报)所记载的数据库制作装置。在该数据库制作装置中,从日语的文本信息提取感性表现,使用制作完成的感性表现数据库,将感性信息和检索对象建立关联,由此来制作检索对象数据库。
另外,作为数据库制作装置,已知有专利文献2(日本特开2010-272075号公报)所记载的数据库制作装置。在该数据库制作装置中,根据日语的文本信息,使用感性表现辞典以及感性表现提取规则提取感性表现,并使用感性向量辞典,针对每个检索对象生成感性信息,由此制作检索对象数据库。
技术实现要素:
根据上述专利文献1以及专利文献2的数据库制作装置,只是根据日语的文本信息制作数据库,数据收集范围受到制约,因而存在数据库的有用性低的问题。其结果,检索数据库时的检索结果的有用性也下降。
本发明是为了解决上述课题而完成的,其目的在于提供一种能够在提高有用性的同时制作数据库的数据库制作装置等。
用于解决课题的手段
为了实现上述目的,本发明的数据库制作装置的特征在于,具备:文本信息获取单元,通过对由规定媒介公开的公开信息实施规定的滤波处理,获取包含规定的第1语言作为文本的第1语言文本信息、以及包含规定的第1语言以外的一个以上的第2语言作为文本的第2语言文本信息作为与规定领域关联的文本信息;翻译文本信息制作单元,通过利用规定翻译方法将第2语言文本信息翻译成规定的第1语言来制作翻译文本信息;混合文本信息制作单元,通过将翻译文本信息作为第1语言文本信息的一部分与第1语言文本信息组合来制作混合文本信息;以及,数据库制作单元,在执行了从混合文本信息中提取感性信息的提取处理以及从混合文本信息中去除构成噪声的噪声信息的噪声去除处理之后,通过将感性信息与去除了噪声信息的混合文本信息建立关联,来制作检索用的数据库。
根据该数据库制作装置,通过对由规定媒介公开的公开信息实施规定的滤波处理,获取包含规定的第1语言作为文本的第1语言文本信息、以及包含规定的第1语言以外的一个以上的第2语言作为文本的第2语言文本信息作为与规定领域关联的文本信息。另外,通过利用规定翻译方法将第2语言文本信息翻译成规定的第1语言来制作翻译文本信息,通过将翻译文本信息作为第1语言文本信息的一部分与第1语言文本信息组合来制作混合文本信息。并且,由于使用该混合文本信息来制作检索用的数据库,与专利文献1、2的情况不同,能够使用包含在由规定媒介公开的公开信息中的两个以上的语言作为文本的信息来制作数据库。由此,例如,在检索该数据库时,与专利文献1、2的情况相比,因能够检索更广泛的信息,能够提高数据库的有用性。
而且,执行从混合文本信息提取感性信息的提取处理以及从混合文本信息中去除构成噪声的噪声信息的噪声去除处理。然后,通过将感性信息与去除了噪声信息的混合文本信息建立关联,来制作数据库。由此,例如,在检索该数据库时,能够在避免检索到构成噪声的信息的同时检索到合适的信息。由此,能够进一步提高数据库的有用性(需要说明的是,本说明书中的“规定媒介”包括tv、收音机和报纸等大众媒体、电子公告板、博客和sns等网络媒体、多媒体)。
在本发明中,优选的是,在噪声去除处理中,在混合文本信息中包含与规定领域关联的规定名词的情况下,连接在规定名词之后的词性是主格、宾格以及所有格的任一格助词以外的情况时,将包含规定名词的混合文本信息作为噪声信息将其去除。
根据该数据库制作装置,在噪声去除处理中,在混合文本信息中包含与规定领域关联的规定名词的情况下,连接在规定名词之后的词性是主格、宾格以及所有格的任一格助词以外时,将包含规定名词的混合文本信息作为噪声信息将其去除。在该情况下,连接在规定名词之后的词性是主格、宾格以及所有格的任一格助词以外的情况时,该规定名词被用作名词以外的语言的一部分的可能性高。因此,能够避免包含这类容易混淆的语言的噪声信息混入数据库,从而能够进一步提高数据库的有用性。
本发明的检索系统的特征在于,具备:上述数据库制作装置;存储数据库的数据库存储单元;检索单元,基于与规定领域关联的规定关键词检索存储在数据库存储单元中的数据库;区分单元,将检索单元的检索结果中的感性信息区分为多个分类的感性信息;以及,显示单元,将多个分类的感性信息以互不相同的颜色进行颜色区分来显示。
根据该检索系统,基于与规定领域关联的规定关键词对数据库存储单元所存储的数据库进行检索,检索单元的检索结果中的感性信息被区分为多个分类的感性信息。并且,由于以互不相同的颜色显示多个分类的感性信息,检索系统的用户能够一眼掌握检索结果中的多个分类的感性信息,从而能够提高其便利性。
本发明的检索系统的特征在于,具备:上述数据库制作装置;存储数据库的数据库存储单元;检索单元,基于与规定领域关联的规定关键词检索存储在数据库存储单元中的数据库;区分单元,将检索单元的检索结果中的感性信息区分为从最上位到最下位的多个阶段的分类的感性信息;以及,显示单元,按从最上位到最下位的顺序阶段性地显示多个阶段的分类的感性信息。
根据该检索系统,基于与规定领域关联的规定关键词对数据库存储单元所存储的数据库进行检索,检索单元的检索结果中的感性信息被区分为从最上位到最下位的多个阶段的分类的感性信息。并且,按从最上位到最下位的顺序阶段性地显示多个阶段的分类的感性信息。这样,检索系统的用户能够以从最上位到最下位的顺序阶段性地参照检索结果中的感性信息,由此能够详细地研究检索结果中包含怎样的感性信息。
本发明的检索系统的特征在于,具备:上述数据库制作装置;存储数据库的数据库存储单元;检索单元,基于规定检索期间检索存储在数据库存储单元中的数据库;以及,显示单元,在显示检索单元的检索结果中的多个感性信息的同时,当多个感性信息中的任一信息被选择时,显示与被选择的感性信息对应的关联词以及数据库的信息。
根据该检索系统,基于规定检索期间检索数据库存储单元所存储的数据库,并显示检索单元的检索结果中的多个感性信息。然后,在多个感性信息中的任一信息被选择时,显示与被选择的感性信息对应的关联词以及数据库的信息。由此,检索系统的用户能够参照与被选择的感性信息对应的关联词以及数据库的信息,从而能够提高其便利性。
附图说明
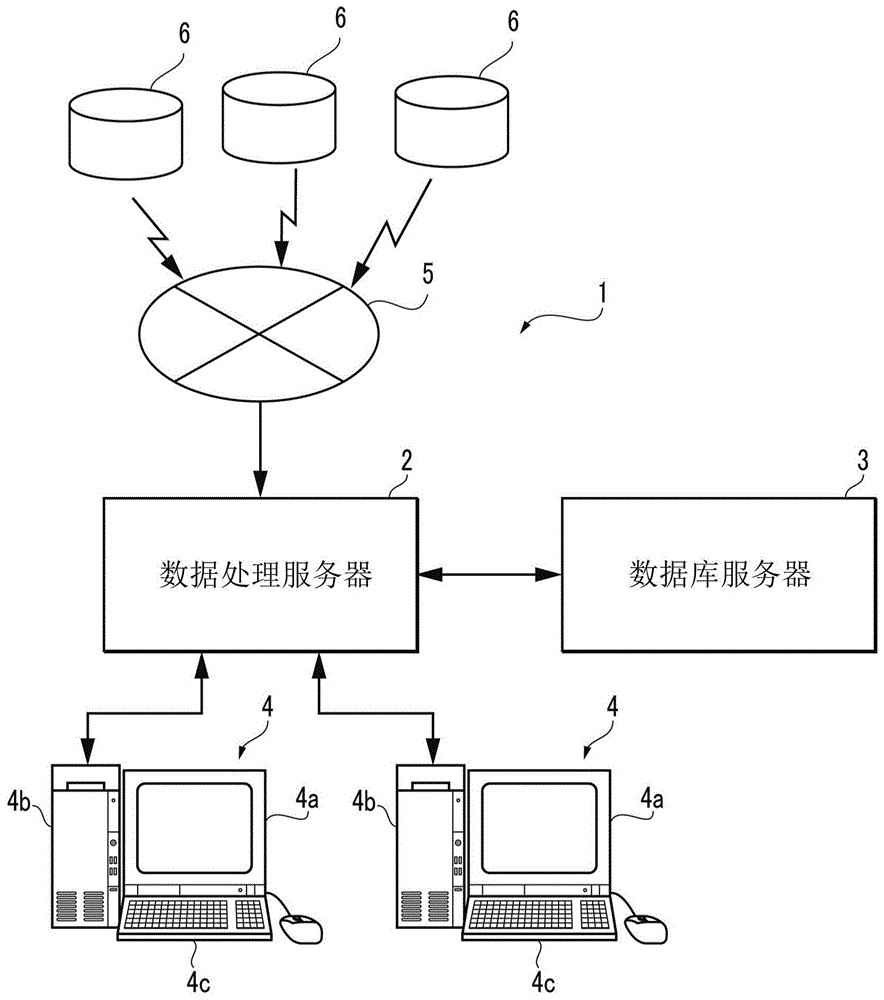
图1是示意性地表示本发明的一实施方式所涉及的数据库制作装置以及检索系统的结构的图。
图2是表示保存数据制作处理的流程图。
图3是表示所获取的文本数据的一例的图。
图4是表示日语数据的一例的图。
图5是表示外语数据的一例的图。
图6是表示不需要翻译的数据的一例的图。
图7是表示翻译用数据的一例的图。
图8是表示机器翻译数据的一例的图。
图9是表示准日语数据的一例的图。
图10是表示混合数据的一例的图。
图11是表示不需要分析的数据的一例的图。
图12是表示分析用数据的一例的图。
图13是表示感性信息的大分类以及小分类的一例的图。
图14是表示保存数据的一例的图。
图15是表示检索系统的第1检索处理时的通信动作的图。
图16是表示关联词的显示例的图。
图17是表示感性信息的大分类的显示例的图。
图18是表示感性信息的小分类的显示例的图。
图19是表示数据库的原文的显示例的图。
图20是表示检索系统的第2检索处理时的通信动作的图。
具体实施方式
以下,参照附图对本发明的一个实施方式的检索系统以及数据库制作装置进行说明。由于本实施方式的数据库制作装置包含于检索系统,在以下的说明中,在对检索系统进行说明的同时,其中也对数据库制作装置的功能以及结构进行说明。
如图1所示,本实施方式的检索系统1具备数据处理服务器2、数据库服务器3以及多个检索终端4(图中仅示出两个)。
数据处理服务器2具备处理器、存储器(ram、rom等)以及i/o接口等,基于存储器内的运算程序执行后述的保存数据制作处理等。
在该数据处理服务器2上,经由网络5(例如,因特网)连接有多个外部服务器6(图中仅示出三个)。在该情况下,各种sns服务器、规定媒介(例如,报社)的服务器以及检索网站的服务器等相当于外部服务器6。需要说明的是,在本实施方式中,由外部服务器6构成的媒介相当于规定媒介,外部服务器6内的数据相当于在规定媒介中公开的公开信息。
在后述的保存数据制作处理中,数据处理服务器2从这些外部服务器6获取文本信息,制作保存数据,并且将其输出到数据库服务器3。
需要说明的是,在本实施方式中,数据处理服务器2相当于数据库制作装置、文本信息获取单元、翻译文本信息制作单元、混合文本信息制作单元、数据库制作单元、检索单元以及区分单元。
另外,数据库服务器3与数据处理服务器2同样地具备处理器、存储器以及i/o接口等。在该数据库服务器3中,从数据处理服务器2输入的保存数据作为数据库的一部分存储在存储器内。需要说明的是,在本实施方式中,数据库服务器3相当于数据库存储单元。
而且,检索终端4是个人计算机型的终端,具备显示器4a、存储器(storage)4b以及输入接口4c等。在该存储器(storage)4b中安装有检索处理用的应用软件(以下称为“检索软件”),输入接口4c由用于操作检索终端4的键盘以及鼠标等构成。
在该检索终端4中,如后所述,在检索软件的启动过程中,伴随用户对输入接口4c的操作,由数据处理服务器2执行数据库的检索等。需要说明的是,在本实施方式中,检索终端4相当于检索单元以及显示单元。
接着,参照图2对上述保存数据制作处理进行说明。如下所述,该处理使用从前述外部服务器6输入到数据处理服务器2的文本数据,制作构成数据库的一部分数据库的保存数据,在数据处理服务器2中以规定的控制周期执行该处理。
需要说明的是,在该保存数据制作处理中获取的数据、所制作的数据以及计算而得的数据均被存储在数据处理服务器2的存储器的ram内。
如该图所示,首先,获取数据(图2/步骤1)。具体而言,通过对从外部服务器6输入到数据处理服务器2的数据实施规定的滤波处理,获取包含车辆关联用语的文本数据。在该情况下,例如如图3所示获取文本数据。该图中,“x”表示车名,“y公司”表示造车企业名。
另外,车辆关联用语是二轮车以及四轮车等车辆关联领域的用语,具体而言,车辆名、造车企业名、造车企业的社长(总经理)名称、车辆部件用语、车辆竞技用语以及赛车手名字等相当于车辆关联用语。需要说明的是,在本实施方式中,车辆关联领域相当于规定领域。
接着,执行语言分类处理(图2/步骤2)。具体而言,将如上述的方式获取的文本数据分类为日语数据和外语数据。例如,是在图3所示的文本数据的情况下,分类成图4所示的日语数据和图5所示的外语数据。
接着,如上所述的方式对文本数据进行分类时,判定是否存在外语数据(图2/步骤3)。在该判定为否定时(图2/步骤3…no(否)),即不存在外语数据,在文本数据仅为日语数据时,进入后述的分析用数据选择处理(图2/步骤8)。
另一方面,在该判定为肯定时(图2/步骤3…yes(是)),执行翻译用数据选择处理(图2/步骤4)。在该处理中,从如上述的方式分类的外语数据中选择需要翻译的数据作为翻译用数据。例如,是在图5所示的外语数据的情况下,由于不需要对图6所示的url数据进行翻译,选择图7所示的数据作为需要翻译的翻译用数据。
接着,执行机器翻译处理(图2/步骤5)。在该处理中,通过对翻译用数据实施机器翻译,得到机器翻译数据。例如,在对图7所示的翻译用数据实施机器翻译的情况下,得到图8所示的机器翻译数据。
接着,制作准日语数据(图2/步骤6)。在该情况下,在上述翻译用数据选择处理中存在未被选择的数据、即没有被实施机器翻译的数据时,通过将其与机器翻译数据组合,制作准日语数据。例如,通过在图8所示的机器翻译数据中组合图6所示的url数据,制作图9所示的准日语数据。另一方面,在不存在被实施机器翻译的数据时,机器翻译数据原样地被设定为准日语数据。
接着,制作混合数据(图2/步骤7)。具体而言,通过在日语数据中组合准日语数据来制作混合数据。例如,通过对图4所示的日语数据组合图9所示的准日语数据,制作出图10所示的混合数据。
通过这种方式制作了混合数据时或者在前述的判定中不存在外语数据时,执行分析用数据选择处理(图2/步骤8)。
在该处理中,从混合数据或日语数据中选择需要分析的分析用数据。例如,在制作了图10所示的混合数据的情况下,图11所示的数据只是标题、名词的罗列,不需要进行分析,因此将图12所示的数据选择为分析用数据。
接着,执行感性提取处理(图2/步骤9)。在该处理中,使用对文章的结构或单词的连接关系进行理解/判断的语言理解算法,对分析用数据的感性信息进行分类并提取。具体而言,如图13所示,分析用数据的感性信息分类为三个大分类“积极(positive)”、“中性(neutral)”、“消极(negative)”以及各大分类的下位的许多小分类这两个阶段来进行提取。
在该图中,分类“高兴”、……、“想买”相当于大分类“积极”的下位的小分类,分类“惊讶”、………“邀请”相当于大分类“中性”的下位的小分类。另外,分类“愤怒”、…………“不想买”相当于大分类“消极”的下位的小分类。
接着,执行噪声去除处理(图2/步骤10)。在该处理中,首先,对分析用数据实施形态解析(morphologicalanalysis)。然后,在分析用数据中包含有车辆关联用语的规定名词的情况下,基于连接在该规定名词之后的词性,判定是否是噪声数据。
具体而言,连接在规定名词之后的词性是格助词(日语:格助詞),在该格助词是主格、宾格及所有格中的任意一种助词时,判定为不是噪声数据,否则,判定为是噪声数据。并且,在判定为是噪声数据时,从分析用数据中除去该数据。
例如,是图12所示的分析用数据的情况时,虽然在no.8的数据中包含有车辆名“fit(フィット)”,但连接在该名词“fit”之后的语言不是格助词,而是“进行(する)”这一动词,由此判定为该数据是噪声数据。由此,从图12的分析用数据中去除no.8的数据。
接着,制作保存数据(图2/步骤11)。具体而言,通过对在上述的噪声去除处理中去除了噪声后的分析用数据关联在前述的感性提取处理中提取出的感性信息,来制作保存数据。例如,通过将图12所示的分析用数据中除去no.8的数据后的数据与感性信息建立关联,来制作图14所示的保存数据。
接着,将通过上述方式制作的保存数据输出到数据库服务器3(图2/步骤12)。然后,结束本处理。由此,保存数据作为数据库的一部分而被存储在数据库服务器3内。
接着,参照图15对由检索系统1执行的第1检索处理进行说明。在检索终端4上前述检索软件启动的过程中,在通过用户对输入接口4c的操作而被输入了关键词及检索期间时,该第1检索处理被执行。
如该图所示,首先,在检索终端4中,通过用户对输入接口4c的操作,输入作为检索信息的关键词及检索期间(图15/步骤30)。以下,对用户输入了作为关键词的企业名“本田(honda)”时的例子进行说明。
接着,从检索终端4向数据处理服务器2发送检索信息信号(图15/步骤31)。该检索信息信号包含作为数据的关键词及检索期间。
在数据处理服务器2中,当接收到该检索信息信号时,执行感性信息统计处理(图15/步骤32)。在该处理中,基于检索信息信号中包含的关键词及检索期间,检索数据库服务器3内的数据库,统计该检索结果中的感性信息的命中数。具体而言,统计前述感性信息中的三个大分类各自的命中数或/和多个小分类各自的命中数。
接着,根据该感性信息的统计结果,制作关联词以及感性大分类显示数据(图15/步骤33)。该关联词以及感性大分类显示数据是用于显示与关键词相关联的语言和感性信息中的三个大分类的比例的数据。
接着,从数据处理服务器2向检索终端4发送关联词及感性大分类显示信号(图15/步骤34)。该关联词及感性大分类显示信号包含上述的关联词及感性大分类显示数据。
当在检索终端4上接收到该关联词及感性大分类显示信号时,在检索终端4的显示器4a上,与关联词及感性大分类显示数据对应地显示关联词及感性大分类(图15/步骤35)。在该情况下,如图16所示,关联词以关键词“本田(honda)”为中心,以文字云(wordclouds)形式显示与该关键词相关联且命中数多的语言。
另外,例如如图17所示,感性信息的大分类以圆环状的图表(圆环图表)形式显示。如该图所示,在该图表中,感性信息中的三个大分类“积极”、“中性”、“消极”被区分显示在三个区域中。这些区域的面积根据各大分类的命中数的比例来设定,并且以互不相同的颜色进行颜色区分来显示。
然后,当用户在视觉确认显示器4a上显示的感性信息的大分类之后,由用户选择了三个大分类类中的任一大分类时(图15/步骤36),从检索终端4向数据处理服务器2发送感性大分类选择信号(图15/步骤37)。
该感性大分类选择信号表示由用户选择的大分类。另外,用户对大分类的选择是通过下述方式来实施:操作输入接口4c,按下显示器4a上的被区分成三个大分类的区域(图17的圆环状的区域)中的任意一个区域。以下,对用户选择了作为感性信息的大分类的“积极”时的例子进行说明。
在数据处理服务器2中,当接收到该感性大分类选择信号时,制作感性小分类显示数据(图15/步骤38)。该感性小分类显示数据作为下述数据而被制作,该数据是用于基于感性大分类选择信号而显示由用户选择的感性信息的大分类的下位中的小分类。
接着,从数据处理服务器2将感性小分类显示信号发送到检索终端4(图15/步骤39)。该感性小分类显示信号包含上述感性小分类显示数据。
当检索终端4接收到该感性小分类显示信号时,在检索终端4的显示器4a上,与感性小分类显示数据对应地显示感性信息的小分类(图15/步骤40)。在该情况下,感性信息的小分类例如如图18所示以柱状图形式显示,并且该柱状图的柱长根据命中数而被设定。
然后,当用户在视觉确认显示器4a上显示的感性信息的小分类之后,由用户选择了众多小分类中的任一小分类时(图15/步骤41),从检索终端4向数据处理服务器2发送感性小分类选择信号(图15/步骤42)。
该感性小分类选择信号表示由用户选择的小分类。另外,用户对小分类的选择是通过下述方式来被实施的:操作输入接口4c并按下显示器4a上显示的小分类的众多显示区域(点描所示的柱状图的区域)中的任一区域。以下,对用户选择“表扬/赞赏”作为感性信息的小分类时的例子进行说明。
在数据处理服务器2中,当接收到该感性小分类选择信号时,制作关联词及原文显示数据(图15/步骤43)。该关联词及原文显示数据作为用于在显示与用户输入的关键词关联的语言的同时显示与用户选择的感性信息的小分类对应的数据库的原文的数据而被制作。
接着,从数据处理服务器2将关联词及原文显示信号发送到检索终端4(图15/步骤44)。该关联词及原文显示信号包含上述的关联词及原文显示数据。
当在检索终端4接收到该关联词及原文显示信号时,在检索终端4的显示器4a上,与关联词及原文显示数据对应地显示数据库的原文以及关联词(图15/步骤45)。
在该情况下,与前述的图16相同,以最多命中数的字为中心,以文字云形式显示关联词。由此,用户能够判断在由外部服务器6构成的媒介中,与关键词“本田(honda)”以及所选择的感性信息的小分类相关联的怎样的关联词在检索期间内被大量地公开。
另外,数据库的原文例如如图19所示以表格形式排列以与日期、媒介名以及感性信息的小分类对应的文章的状态进行显示。由此,用户能够判断在上述媒介中与关键词“本田(honda)”相关联的包含怎样的感性信息的文本数据在检索期间内被大量地公开。第1检索处理通过上述方式被执行。
接下来,参照图20,对由检索系统1执行的第2检索处理进行说明。该第2检索处理是在检索终端4中前述的检索软件启动的过程中由用户对输入接口4c的操作仅输入检索期间时被执行。
如该图所示,首先,在检索终端4中,通过用户对输入接口4c的操作,仅将检索期间作为检索信息进行输入(图20/步骤50)。
由此,从检索终端4向数据处理服务器2发送检索信息信号(图20/步骤51)。该检索信息信号包含检索期间作为数据。
在数据处理服务器2中,当接收到该检索信息信号时,执行感性信息统计处理(图20/步骤52)。在该处理中,基于检索信息信号中包含的检索期间,检索数据库服务器3内的数据库,并统计该检索结果中的感性信息。具体而言,统计上述感性信息中的多个小分类各自的命中数。
然后,根据该感性信息的统计结果,制作感性小分类显示数据(图20/步骤53)。如上所述,该感性小分类显示数据作为用于显示感性信息的小分类的数据而被制作。
接着,从数据处理服务器2向检索终端4发送感性小分类显示信号(图20/步骤54)。该感性小分类显示信号包含上述感性小分类显示数据。
当在检索终端4接收到该感性小分类显示信号时,在检索终端4的显示器4a上,与感性小分类显示数据对应地显示感性信息的小分类(图20/步骤55)。在该情况下,感性信息的小分类例如与上述的图18同样地以柱状图形式进行显示。
然后,当用户在视觉确认显示器4a上显示的感性信息的小分类之后,通过用户对输入接口4c操作,选择众多小分类中的任一小分类时(图20/步骤56),从检索终端4向数据处理服务器2发送感性小分类选择信号(图20/步骤57)。
在数据处理服务器2中,当接收到该感性小分类选择信号时,制作关联词及原文显示数据(图20/步骤58)。该关联词及原文显示数据作为下述数据而被制作,该数据用于显示与用户选择的感性信息的小分类对应的关联词和与用户选择的感性信息的小分类对应的数据库的原文。
接着,从数据处理服务器2向检索终端4发送关联词及语言显示信号(图20/步骤59)。该关联词及语言显示信号包含上述的关联词及原文显示数据。
当在检索终端4上接收到该关联词及原文显示信号时,在检索终端4的显示器4a上,与关联词及原文显示数据对应地显示关联词以及数据库的原文(图20/步骤60)。
在该情况下,例如,与前述的图16相同,以文字云形式显示关联词。另外,例如与前述的图19相同,以表格形式排列有日期、媒介名以及与感性信息的小分类对应的文章的状态显示数据库的原文。第2检索处理通过上述方式被执行。
如上所述,根据本实施方式的检索系统1的数据处理服务器2,执行图2所示的保存数据制作处理。在该处理中,从外部服务器6内的数据中获取包含日语作为文本的日语数据和包含日语以外的外语作为文本的外语数据作为车辆关联领域的文本数据(步骤1)。然后,通过将外语数据机器翻译成日语,制作机器翻译数据(步骤5),并通过将机器翻译数据作为日语数据的一部分进行组合,制作混合数据(步骤7)。接着,从该混合数据中选择分析用数据(步骤8),根据分析用数据制作保存数据(步骤9~11)。然后,该保存数据在数据库服务器3中作为数据库的一部分而被存储。
因此,与专利文献1、2的情况不同,能够使用由外部服务器6构成的媒介所公开的数据中包含两个以上的语言作为文本的文本数据来制作数据库。由此,例如,在检索该数据库时,与专利文献1、2的情况相比,能够检索更广泛的信息,由此能够提高数据库的有用性。
另外,在根据分析用数据制作保存数据时,执行提取感性信息的感性提取处理(步骤9)、以及从分析用数据中去除构成噪声的噪声信息的噪声去除处理(步骤10)。然后,通过将感性信息与去除了噪声信息的分析用数据建立关联,来制作保存数据(步骤11)。由此,例如,在检索数据库时,能够在避免检索构成噪声的信息的同时检索合适的信息。由此,能够进一步提高数据库的有用性。
另外,在噪声去除处理中,在分析用数据中包含有车辆关联用语的规定名词的情况下,在连接于该规定名词之后的词性不是主格、宾格以及所有格中的任一格助词以外的情况下,将包含规定名词的混合数据作为噪声信息而将其去除。在该情况下,连接在规定名词之后的词性是除了主格、宾格以及所有格的任一格助词以外的情况下,该规定名词被用作名词以外的语言的一部分的可能性高。因此,能够避免包含这类容易混淆的语言的噪声信息混入数据库,能够进一步提高数据库的有用性。
另外,在图15所示的第1检索处理中,基于关键词及检索期间来检索数据库。并且,该检索结果中的感性信息以图17所示那样被区分为三个大分类“积极”、“中性”、“消极”的圆环图表的形式进行显示。在该图表中,三个大分类的区域的面积根据其命中数的比例来设定,并且以互不相同的颜色进行颜色区分来显示。由此,用户能够一眼就判断出检索结果中的感性信息的三个大分类的比例。
并且,在选择了感性信息中的三个大分类中的任一大分类时,该被选择的大分类的下位的众多小分类通过图18所示那样与命中数对应的柱状图形式来进行显示。由此,用户在选择了三个大分类的感性信息中的任一大分类的感性信息时,能够一眼就判断出其下位的众多小分类的比例。如上所述,用户能够首先确认到三个大分类的感性信息的比例,进一步在选择了大分类中的任一大分类时,能够阶段性地确认到其下位的众多小分类的比例,从能够确保较高的便利性。
另一方面,在图20所示的第2检索处理中,仅基于检索期间来检索数据库。并且,该检索结果中的众多小分类的感性信息以图18所示那样以与命中数对应的柱状图形式进行显示。由此,用户能够一眼就判断出该检索期间内的众多小分类的感性信息的比例,能够确保较高的便利性。
需要说明的是,实施方式是将车辆关联领域作为规定领域的例子,但是也可以将车辆关联领域以外的领域作为规定领域。例如,也可以将服饰关联领域、食品关联领域以及玩具关联领域等作为规定领域。
另外,实施方式是将第1语言设为日语的例子,但也可以将第1语言设为英语、德语等日语以外的外语。另外,第2语言只要是第1语言以外的语言即可。例如,在第1语言为英语时,也可以将第2语言设为日语或德语等。
而且,实施方式是将由外部服务器6构成的媒介设为规定媒介的例子,但本发明的规定媒介不限于此,也可以是tv、收音机和报纸等大众传媒、电子公告板、博客及sns等网络传媒。在该情况下,在将tv、收音机和报纸等大众传媒作为规定媒介时,将在tv、收音机和报纸上公开的公开信息(视频信息、语音信息以及文字信息)经由个人计算机等的输入接口,作为文本数据输入到数据处理服务器2内即可。
另一方面,实施方式是使用机器翻译方法作为规定翻译方法的例子,但本发明的规定翻译方法不限于此,只要是能够将第2语言文本信息翻译成第1语言的方法即可。例如,也可以利用人为的翻译作业将第2语言文本信息翻译成第1语言。
另外,实施方式是将感性信息区分成大分类和小分类这两个阶段的例子,但本发明的感性信息不限于此,只要区分成从最上位到最下位的多个阶段的分类即可。例如,也可以将感性信息区分成三个阶段以上的分类。
- 还没有人留言评论。精彩留言会获得点赞!