一种兼容异构系统的防伪编码方法与流程
本发明涉及防伪编码识别技术领域,尤其涉及一种兼容异构系统的防伪编码方法。
背景技术:
防伪,是指为防止以假冒为手段,对未经商标所有权人准许而进行仿制、复制或伪造和销售他人产品所主动采取的一种措施。
所谓产品编码标识,是以一种有规律性的数字、符号、文字等等表示方式将每一件产品进行标识,使得每件产品附上系统分配的唯一编码,从而实现产品全程的信息管理。
目前,对全球的编码标识体系大致梳理归类后,它包括通行编码标识体系、niot编码标识体系(物联网体系)、私有编码标识体系(中钢),其中通行编码标识体系又包括国际通行编码标识体系(例如gs1,epc,isbn、handle、oid)、国内通行编码标识体系(例如ecode),行业编码标识体系(例如cpc)。可以看出,现如今传统编码标识体系种类繁多、标准不一,不同行业、不同产品类别,各个传统编码体系之间兼容存在很大问题。
除此之外,随着公众对于生活质量要求的提高,产品的真伪性也变得越发重要,而传统产品编码标识在鉴定产品真伪性方面较为薄弱,即使是存在校验码的编码标识也是仅仅对编码标识前几位进行验证,防猜门槛低,公众鉴别真伪性很大程度上需要依赖于后端数据库。同时,传统编码标识一般组成为数字,且位数不多,其携带的信息量过少,很容易对其进行盗用。如此看来,传统编码标识在防伪方面能改进还有不少空间。
为解决传统编码识别的兼容性以及防伪性问题,需要我们研发一种以字节为单元的新型编码方式,该编码方式以全球性已购编码体系为出发点,可以兼容不同国家、不同组织、不同行业所签发的编码,同时可以根据编码自身,做信息编码和校验,可以对编码进行初步的筛选真伪,防止低级猜测撞门的做伪动机,再通过不同方式来编排编码,进一步提高编码信息量,使得后端可以做多个维度的信息检查和校验,提高做伪的难度和成本。
技术实现要素:
本发明的目的是为了解决现有技术中异构不兼容,编码携带信息量过少,鉴别真伪过程复杂的缺点,而提出的一种兼容异构系统的防伪编码方法。
为实现上述目的,本发明采用了如下技术方案:
一种兼容异构系统的防伪编码方法,包括编码方法和解码方法,所述编码方法具体步骤如下:
步骤s11:采集产品信息,包括编码版本、编码规范、国家代码、厂商id、产品品种编码和产品核心编码;
步骤s12:主码明文编码,将采集到的产品信息根据主码编码规范的编码结构和适配规则转换为18字节的明文组码;
步骤s13:主码明文加密,将明文组码进行一系列数学变换后得到主码密文;
步骤s14:生成校验码,先将主码密文通过keccak256算法输出成keccak256编码,然后截取前4个字节作为校验码,2字节高校验放置在18字节主码密文之前,2字节低校验放置在18字节主码密文之后;
步骤s15:颜色编排处理,对产品核心编码的每一位数字进行模五运算,得出0-4的余数,令0-4的余数分别对应不同颜色;
步骤s16:字符大小写处理,对产品核心编码中出现的字符,如果是奇数位按照大写处理,偶数位按照小写处理;进一步增加了编码防伪验证的维度。
步骤s17:二维码生成,对生成的22个字节的编码根据二维码生成规范生成二维码。
所述解码方法具体步骤如下:
步骤s21:扫码,使用扫码终端扫描产品包装印刷的二维码;
步骤s22:检验码比对,对生成的22个字节编码的2字节高校验和2字节低校验进行比对;
步骤s23:主码密文解码,通过变换码进行逆向运算,还原出主码明文;
步骤s24:产品信息转译,将还原出的主码明文根据主码编码规范的编码结构和适配规则逆推得出产品信息。
优选地,所述编码结构为本编码结构包括2字节高检验、18字节主码密文和2字节低校验,所述主码明文内容为码头、国家码、厂商id、品种类别编号和产品核心编码,所述码头又包括高2位版本号和低6位的编码规范组成,支持64种已有或者创新的编码标准。
优选地,所述编码版本和编码规范组成码头,共1字节,所述国家代码共2字节,所述厂商id共3字节,所述产品品种编码共4字节,所述产品核心编码共8字节。
优选地,所述步骤s13主码明文加密的具体步骤如下:
步骤s31:将18字节的主码明文截取成[a|b|c]3段,字符段a为0-7字节,字符段b为8-15字节,字符段c为16-17字节;
步骤s32:定义一个8×15的素数列表zs,一个3×15的随机数列表kn,一个魔法数列表margicnums,将字段c对15取模为j,执行8轮循环,每一轮循环执行操作:
a=(a^kn[j][i%3])^zs[j][i]
b=(b^kn[j][(i+1)%3])^zs[j][7-i]
得到重新赋值的a、b;
步骤s33:将c重新赋值为c^margicnums[j];
步骤s34:得出18字节的主码密文为[c|a|b]。
优选地,所述keccak256算法采用海绵结构,所述海绵结构有两个阶段,一个叫吸收阶段,另外一个叫压缩阶段,采用keccak256算法有效降低了验证码的碰撞率。
优选地,步骤s15所述的0-4的余数对应的不同颜色,分别为0对应红色,1对应绿色,2对应黄色,3对应蓝色,4对应黑色。通过此方法提高了编码的信息量,并且增加了编码防伪验证的维度,使得防伪验证不单单只是在数字验证方面。
优选地,所述步骤s23主码密文解码的具体步骤如下:
步骤s41:将18字节的主码密文截取成[c|a|b]3段,字符段c为0-1字节,字符段a为2-9字节,字符段b为10-17字节;
步骤s42:定义一个8×15的素数列表zs,一个3×15的随机数列表kn,一个魔法数列表margicnums,将字段c对15取模为j,执行8轮循环,每一轮循环执行操作:
b=b^zs[j][7-i]^kn[j][(i+1)%3]
a=a^zs[j][i]^kn[j][i%3]
得到重新赋值的a、b;
步骤s43:将c重新赋值为c^margicnums[j];
步骤s44:得出18字节的主码明文为[a|b|c]。
优选地,所述产品信息转译将还原出的主码明文根据主码编码规范的编码结构和适配规则逆推得出产品信息后,将产品信息以文字的形式呈现在扫码终端上。
优选地,所述编码共22个字节,44个[0-9,a-f,a-f]字符。
优选地,所述扫码终端包括智能移动终端和二维码扫码器。
优选地,所述编码为16进制。
与现有技术相比,本发明的有益效果为:
1、通过编码规范的设置,实现了兼容不同国家、不同组织、不同行业所签发的编码;
2、通过对编码的颜色、大小写进行处理,提高了编码的信息量,并且增加了编码防伪验证的维度;
3、通过最终二维码的生成,简化了消费者检验产品真伪的过程;
4、采用keccak256算法生成校验码,有效降低了验证的碰撞率。
附图说明
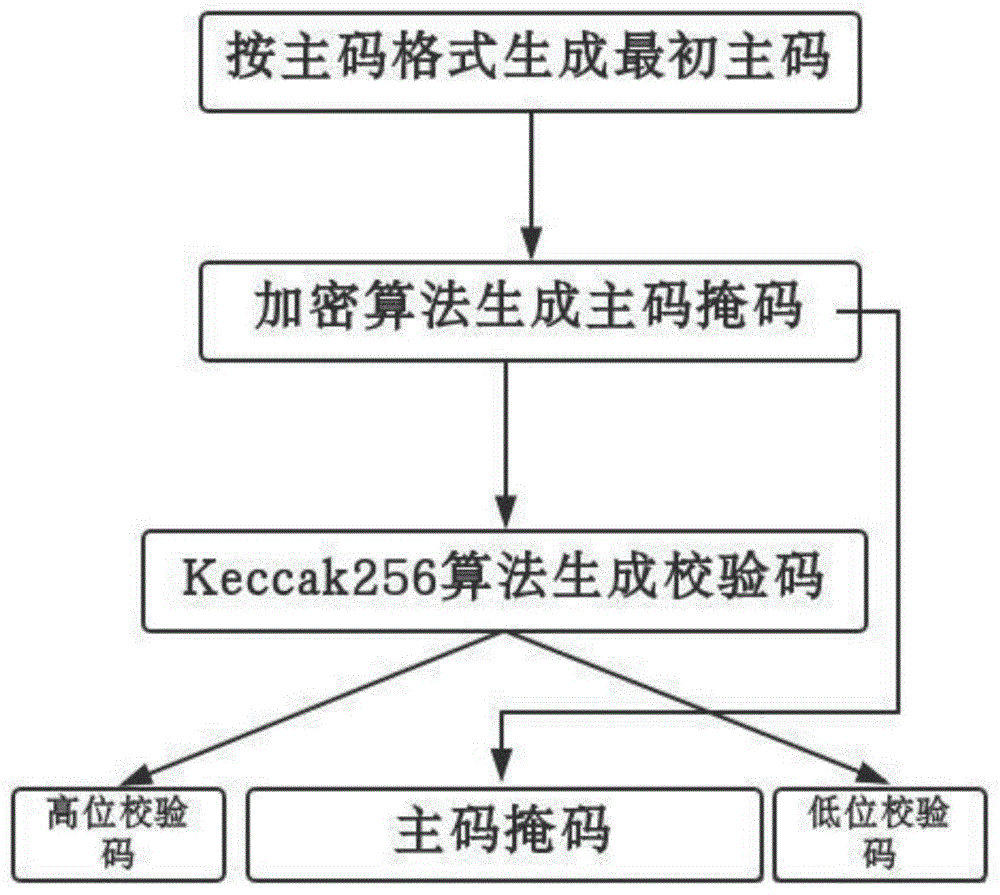
图1为本发明实施例1的编码生成流程图;
图2为本发明实施例1的编码算法流程图;
图3为本发明实施例1的解码算法流程图;
图4为本发明实施例1的keccak算法海绵结构图;
图5为本发明实施例1的编码密文摘要流程图;
图6为本发明实施例1的颜色编排处理流程图;
图7为本发明实施例1的字符处理流程图。
具体实施方式
为使对本发明的目的、构造、特征、及其功能有进一步的了解,兹配合实施例详细说明如下。
实施例1
请参见图1,一种兼容异构系统的防伪编码方法,包括编码方法和解码方法,所述编码方法具体步骤如下:
步骤s11:采集产品信息,包括编码版本、编码规范、国家代码、厂商id、产品品种编码和产品核心编码;
步骤s12:主码明文编码,将采集到的产品信息根据主码编码规范的编码结构和适配规则转换为18字节的明文组码;
步骤s13:请参见图2,主码明文加密,将明文组码进行一系列数学变换后得到主码密文;
步骤s14:请参见图5,生成校验码,先将主码密文通过keccak256算法输出成keccak256编码,然后截取前4个字节作为校验码,2字节高校验放置在18字节主码密文之前,2字节低校验放置在18字节主码密文之后;
步骤s15:请参见图6,颜色编排处理,对产品核心编码的每一位数字进行模五运算,得出0-4的余数,令0-4的余数分别对应不同颜色;
步骤s16:请参见图7,字符大小写处理,对产品核心编码中出现的字符,如果是奇数位按照大写处理,偶数位按照小写处理;进一步增加了编码防伪验证的维度。
步骤s17:二维码生成,对生成的22个字节的编码根据二维码生成规范生成二维码。
所述解码方法具体步骤如下:
步骤s21:扫码,使用扫码终端扫描产品包装印刷的二维码;
步骤s22:检验码比对,对生成的22个字节编码的2字节高校验和2字节低校验进行比对;
步骤s23:请参见图3,主码密文解码,通过变换码进行逆向运算,还原出主码明文;
步骤s24:产品信息转译,将还原出的主码明文根据主码编码规范的编码结构和适配规则逆推得出产品信息。
具体的,所述编码结构为本编码结构包括2字节高检验、18字节主码密文和2字节低校验,所述主码明文内容为码头、国家码、厂商id、品种类别编号和产品核心编码,所述码头又包括高2位版本号和低6位的编码规范组成,支持64种已有或者创新的编码标准。
具体的,所述编码版本和编码规范组成码头,共1字节,所述国家代码共2字节,所述厂商id共3字节,所述产品品种编码共4字节,所述产品核心编码共8字节。
具体的,具体编码结构如下:
(1)码头1个字节由高2位版本和低6位编码规范组成:
版本号:高2bit,代表该类编码的版本,00-11,支持4个版本的演进;
编码规范:低6bit,代表采用或者兼容的编码规范,最大支持64种已有或者创新的编码标准,目前定义值:
0x1-0x8:预留给本发明自用编码;
0x9:最新ean和ucc正式合并后的gs1规范;
0xa:epc;
0xb:isbn;
0xc:handle;
0xd:oid;
0xe:ecode;
0xf:cpc;
0x10:niot;
更多规范,可以根据需要逐次定义。
(2)国家代码:
大小为2byte,可容纳65535个单位,全球共有226个国家和地区,故此标志位1byte即可用,对于人口密集、国土面积较大的国家可再次细分,以便快速定位和查找,例如中国可分配00-11,分别代表北方、南方、西北、青藏四个区域。
(3)厂商id:
大小为3byte,可容纳16777216个单位,由各个国家分配,可分配大约1600万个厂商,从0x000000~0xffffff。
(4)产品品种编码(或产品订单编码):
大小为4byte,可容纳指定企业或者组织内4294967296个产品品种门类或者订单模式编号,由各个厂商分配,从0x00000000~0xffffffff。
(5)产品核心编码:
大小为8byte,可容纳指定企业或者组织内某种产品的4294967296个物流或者产品编号,由各个厂商分配,从0x0000000000000000~0xffffffffffffffff。
具体的,请进一步参见图2,所述步骤s13主码明文加密的具体步骤如下:
步骤s31:将18字节的主码明文截取成[a|b|c]3段,字符段a为0-7字节,字符段b为8-15字节,字符段c为16-17字节;
步骤s32:定义一个8×15的素数列表zs,一个3×15的随机数列表kn,一个魔法数列表margicnums,将字段c对15取模为j,执行8轮循环,每一轮循环执行操作:
a=(a^kn[j][i%3])^zs[j][i]
b=(b^kn[j][(i+1)%3])^zs[j][7-i]得到重新赋值的a、b;
步骤s33:将c重新赋值为c^margicnums[j];
步骤s34:得出18字节的主码密文为[c|a|b]。
进一步地,所述解码编码算法如下:
定义:
主码明文为ctx(18字节);
主码密文为ectx(18字节);
step1:
//ctx=[a|b|c]
a=ctx[0-7]byte
b=ctx[8-15]byte
c=ctx[16-17]byte
step2:
step3:
c=c^margicnums[j]
step4:
ectx=[c|a|b]
具体的,请参见图4,所述keccak256算法采用了一种叫海绵的结构,所述海绵结构有两个阶段,一个叫吸收阶段,另外一个叫压缩阶段,采用keccak256算法有效降低了验证码的碰撞率。
具体的,请进一步参见图4,keccak算法采用了一种叫海绵的结构,如图所示。m为任意长度的输入消息,z为散列之后的摘要输出,f[b]称作置换函数,其它参数r为比特率,c为容量,且b=r+c,参数c要求是hash摘要输出长度n的2倍,即c=2n。海绵结构有两个阶段,一个叫吸收阶段absorbing,另外一个叫压缩阶段squeezing。压缩阶段,输入消息m后串联一个数字串10…01,其中0的个数是将消息m填充为长度为r的最小正整数倍;接着将填充后的输入消息分组,每组有r个比特,最小填充的长度为2,最大为r+1。同时b个初始状态全部初始化为0。海绵结构处理完输入的压缩过程之后,转换到挤压状态,挤压后输出的块数可根据用户需要做选择。
由于keccak采用了不同于之前sha1/2的md(merkeldamgard)结构,所以针对md结构的攻击对keccak不再有效,因此到目前为止,还没有出现能够对实际运用中的keccak算法形成威胁。
具体的,请进一步参见图6,步骤s15所述的0-4的余数对应的不同颜色,分别为0对应红色,1对应绿色,2对应黄色,3对应蓝色,4对应黑色。通过此方法提高了编码的信息量,并且增加了编码防伪验证的维度,使得防伪验证不单单只是在数字验证方面。
具体的,请进一步参见图3,所述步骤s23主码密文解码的具体步骤如下:
步骤s41:将18字节的主码密文截取成[c|a|b]3段,字符段c为0-1字节,字符段a为2-9字节,字符段b为10-17字节;
步骤s42:定义一个8×15的素数列表zs,一个3×15的随机数列表kn,一个魔法数列表margicnums,将字段c对15取模为j,执行8轮循环,每一轮循环执行操作:
b=b^zs[j][7-i]^kn[j][(i+1)%3]
a=a^zs[j][i]^kn[j][i%3]
得到重新赋值的a、b;
步骤s43:将c重新赋值为c^margicnums[j];
步骤s44:得出18字节的主码明文为[a|b|c]。
进一步地,所述解码编码算法如下:
定义:
主码明文为ctx(18字节);
主码密文为ectx(18字节);
step1:
c=ectx[0-1]byte
a=ectx[2-9]byte
b=ectx[10-17]byte
step2:
step3:
c=c^margicnums[j]
step4:
ctx=[a|b|c]
具体的,所述产品信息转译将还原出的主码明文根据主码编码规范的编码结构和适配规则逆推得出产品信息后,将产品信息以文字的形式呈现在扫码终端上。
具体的,所述编码共22个字节,44个[0-9,a-f,a-f]字符。
具体的,所述扫码终端包括智能移动终端和二维码扫码器。
具体的,所述编码为16进制。
本发明已由上述相关实施例加以描述,然而上述实施例仅为实施本发明的范例。必需指出的是,已揭露的实施例并未限制本发明的范围。相反地,在不脱离本发明的精神和范围内所作的更动与润饰,均属本发明的专利保护范围。
- 还没有人留言评论。精彩留言会获得点赞!