一种基于改进因子分解机的个性化推荐方法与流程
本发明涉及推荐算法的
技术领域:
,尤其涉及到一种基于改进因子分解机的个性化推荐方法。
背景技术:
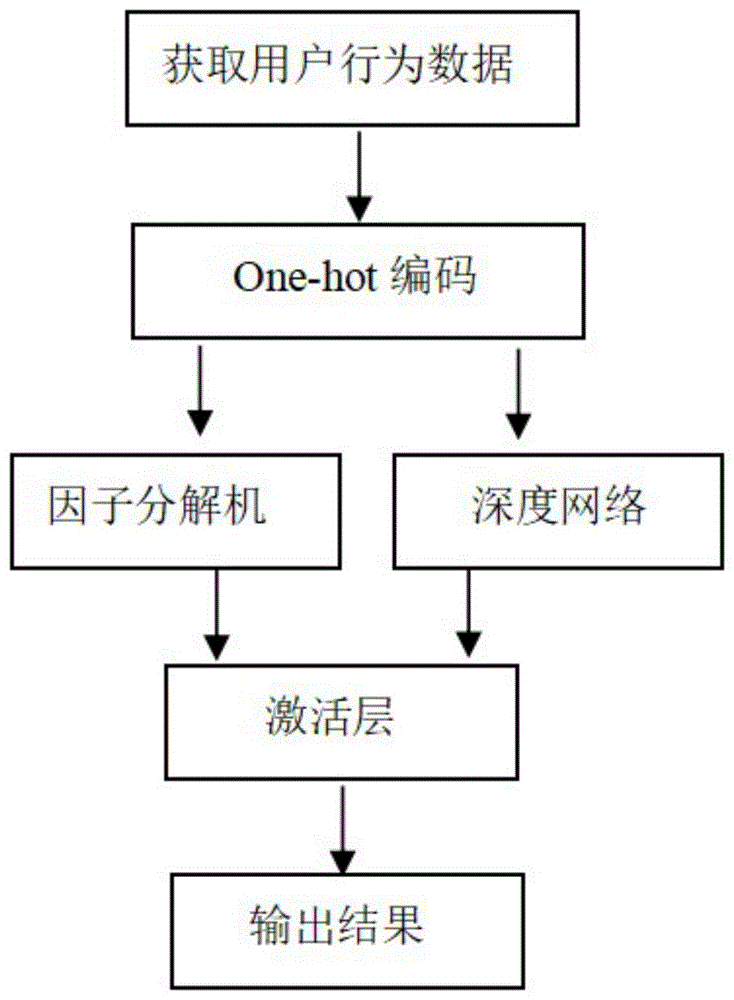
:随着大数据时代科技高速发展,用户通过互联网和电子产品获得的信息资源越来越丰富。每天有数以千万计的信息涌入生活,造成了”信息过载”的问题,用户经常需要从海量的商品中挑选出自己需要的,尤其在用户没有明确目标的情况下,挑选商品既费时又费力。如何从海量商品中快速且有针对性地对用户作出推荐便成为一个商机。鉴于这种情况,推荐系统应运而生。现如今已经有很多网站推出了“猜你喜欢”,“今日推荐”等功能,旨在给用户推荐符合心意的商品,如果这些推荐符合用户兴趣,则既可以增加网站利润和用户黏度;也可以节省用户获取自己想要物品的时间。因此推荐系统可谓是一种“双赢”的技术。而推荐算法作为推荐系统的核心,对推荐结果起着关键的作用,同时面临着极大的挑战,如何准确而迅速的为用户推荐符合心意的商品(这里的商品可以是音乐,电影,物品等)引起人们的思考。其中,常见的推荐方法比如基于用户的协同过滤推荐方法和基于物品的协同过滤推荐方法,本质上与机器学习中的最近邻思想相似,但存在缺点:当用户数据和商品数据量增大的时候,运算负担十分大,准确率下降;无法提取无法提取用户行为数据中的隐含特征和序列特征。因此推荐效果不理想。在深度学习领域,基于卷积神经网络的方法并未考虑用户行为数据的上下文相关的本质,提取到的特征并没有完全发挥深度学习的优势;基于循环神经网络的推荐方法可以提取序列特征,但是在数据处于高维且稀疏的情况下效果不佳。技术实现要素:本发明的目的在于克服现有技术的不足,提供一种可以更好的提取数据的序列特征、隐含特征、低阶特征以及高阶特征,从而为用户进行更为精准推荐的基于改进因子分解机的个性化推荐方法。为实现上述目的,本发明所提供的技术方案为:一种基于改进因子分解机的个性化推荐方法,包括以下步骤:s1.获取用户历史行为数据;s2.将用户历史行为数据转换成用户数*物品数的矩阵格式,并进行one-hot编码处理;处理后的数据分为训练数据和测试数据;s3.构建由因子分解机和深度神经网络组成的模型;s4.通过步骤s2得到的训练数据对模型进行训练,得到优化模型;s5.将步骤s2得到的测试数据输入到优化模型中,得出个性化推荐结果。进一步地,所述步骤s3中,因子分解机的模型增添特征组合,具体如下:上式中,特征xi和特征xj之间的关联特征权重wij由特征xi和特征xj所对应的隐向量vi和vj的内积表示。进一步地,将所述因子分解机中隐向量的内积改进为平方欧式距离;具体为:通过学习每个特征xi的嵌入向量和平移向量用平方欧氏距离代替内积来度量特征之间的交互强度:进一步地,所述步骤s3构建的由因子分解机和深度神经网络组成的模型如下:因子分解机yfm和深度神经网络ydnn的输出共同经过sigmoid激活函数得到的输出作为整个模型的输出进一步地,所述深度神经网络ydnn中,其中m表示输入的个数,xk表示第k个输入,wk表示第k个特征的权重,b表示偏差。与现有技术相比,本方案原理及优点如下:(1)对因子分解机算法进行改进,将原始因子分解机模型中特征之间的交互强度的权重度量不再利用内积,而是利用平方欧氏距离,既传承了因子分解机本身具有的优点,又具有了提取序列特征的优势。(2)将改进后的因子分解机模型与深度神经网络结合,克服了因子分解机提取二阶以上关联特征计算量巨大的缺点,因子分解机模型负责提取低阶特征(即一阶及二阶特征)之间的关联特征及用户行为的序列特征,深度神经网络负责提取更高阶的特征,从而更加准确高效的进行推荐。(3)作为端到端模型,与其它神经网络模型相比,不需要特征工程的操作,更加方便。附图说明为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的服务作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。图1为本发明一种基于改进因子分解机的个性化推荐方法的工作流程图;图2为因子分解机原理图;图3为深度神经网络示意图。具体实施方式下面结合具体实施例对本发明作进一步说明:本实施例所述的一种基于改进因子分解机的个性化推荐方法,包括以下步骤:s1.获取用户历史行为数据;原始数据的格式为:{用户,物品,评分};s2.将用户历史行为数据转换成用户数*物品数的矩阵格式,并进行one-hot编码处理;处理后的数据分为训练数据和测试数据;s3.构建由因子分解机和深度神经网络组成的模型;其中,因子分解机的模型增添特征组合,具体如下:上式中,特征xi和特征xj之间的关联特征权重wij由特征xi和特征xj所对应的隐向量vi和vj的内积表示。然后,将因子分解机中隐向量的内积改进为平方欧式距离;具体为:通过学习每个特征xi的嵌入向量和平移向量用平方欧氏距离代替内积来度量特征之间的交互强度:这部分因子分解机的原理如图2所示。而深度神经网络中,其输入和输出之间会学习到一个线性关系:其中m表示输入的个数,xk表示第k个输入,wk表示第k个特征的权重,b表示偏差。构建得到的由因子分解机和深度神经网络组成的模型如下:即:因子分解机yfm和深度神经网络ydnn的输出共同经过sigmoid激活函数得到的输出作为整个模型的输出s4.通过步骤s2得到的训练数据对模型进行训练,得到优化模型;在训练过程中,需要调节和学习的参数有因子分解机模型的参数w0,wi,vi,vj,和深度神经网络的参数wk,模型损失函数定义为均方误差函数通过梯度下降法来更新参数,当损失函数训练到最小的时候,得到最优训练参数。s5.将步骤s2得到的测试数据输入到优化模型中,得出个性化推荐结果。下面对上述方法步骤作详细解析:由于步骤s2数据进行one-hot编码之后,将会变得高维且稀疏。举个例子:原始数据如下表1所示:用户物品是否点击用户1物品11用户2物品20用户3物品31表1进行one-hot编码之后,如下表2所示:表2依次类推,如果用户和物品很多,那么经过one-hot编码后的数据将变得高维且稀疏。另外,推荐过程还存在着特征组合问题:传统机器学习进行建模的时候,都是将各个特征独立考虑,并没有考虑到特征与特征之间的相互关系。一般的线性模型为:但实际上,特征之间是可能有隐含关联的。举例说明,一般来说,女性用户看化妆品之类的商品比较多,而男性更容易点击各种鞋类商品。那么可以推断出,性别为女性这个特征与化妆品类商品有很大的关联性,男性这个特征与鞋类商品的关联性更为密切。如果能将这些有关联的特征找出来,对于提升推荐效果很有意义。而因子分解机可以解决数据稀疏的情况下,特征组合的问题,因此,步骤s3构建的模型包括因子分解机,通过因子分解机的模型增加特征组合显得很有必要。但随之而来的是,因子分解机在处理高阶特征时计算量急剧增大,因子分解机只用来提取一阶特征xi和二阶特征xi,xj;所以步骤s3构建的模型还包括深度神经网络,更高阶特征由深度神经网络来提取。该深度神经网络是若干层全连接的神经网络,具体原理图见附图3所示。本实施例中,通过对因子分解机算法进行改进,将原始因子分解机模型中特征之间的交互强度的权重度量不再利用内积,而是利用平方欧氏距离,既传承了因子分解机本身具有的优点,又具有了提取序列特征的优势。另外,将改进后的因子分解机模型与深度神经网络结合,克服了因子分解机提取二阶以上关联特征计算量巨大的缺点,因子分解机模型负责提取低阶特征(即一阶及二阶特征)之间的关联特征及用户行为的序列特征,深度神经网络负责提取更高阶的特征,从而更加准确高效的进行推荐。最后,作为端到端模型,与其它神经网络模型相比,不需要特征工程的操作,更加方便。以上所述之实施例子只为本发明之较佳实施例,并非以此限制本发明的实施范围,故凡依本发明之形状、原理所作的变化,均应涵盖在本发明的保护范围内。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1