一种平衡共赢的数据资产定价机制的制作方法
本发明涉及数据资产交易与共享,尤其是从数据资产供应链的视角提出了一个平衡共赢定价机制等相关问题。
背景技术:
“数据资产”的概念最早出现在20世纪70年代,指的是个体“持有的政府债券、公司债券和实物债券等资产”。经过几十年信息技术和大数据技术的发展,数据成为资产,已经是行业共识。目前的数据资产主要指由个人或企业拥有或者控制的,能够带来经济利益或者具有服务潜力的数据资源。数据资产以物理或电子的方式记录,包括由数据组成的任何实体和信息化资源,如系统或应用程序的输出文件、文档、web页面、图片、电子数据等。
数据资产交易一般指数据资产所有权的转移,是传统的数据资产供给方式。数据资产共享一般保留数据资产的产权和管理权,一般包括有偿服务和免费开源两种数据资产供给方式。数据资产交易和共享都指的是数据资产在不同商业实体之间的流通和转换。定价是数据资产交易和共享的基础,因涉及利润分配和激励策略而严重影响数据资产交易市场的有序发展。此外,定价数据资产有利于提高人们对私有数据的保护意识和管理意识,这对网络数据安全的维护起到了很大的积极作用。
然而,数据资产作为一种虚拟资产,对其定价主要有以下五大难点:(1)数据质量。由于数据的类型多样、精度不一致以及人为干扰因素等问题,数据资产的数据质量难以保障。(2)时效。数据资产具有流动性和时间性。有些数据资产的价值会随时间推移而减少,甚至完全失去价值。(3)无后期成本。虽然数据的采集和加工是有成本的,但后期的交易成本几乎是零,比如软件的使用等。(4)权限(permissions)。数据资产是一种虚拟资产,权限是它的一种固有属性。数据资产的交易和共享涉及复杂的权限关系,这给数据资产定价带来了难题。(5)套利。数据资产的套利交易指的是买方通过多次购买低价值量的数据集去挖掘出高价值量的数据信息,以此赚取价格差。套利交易会侵犯数据所有者的隐私,损害卖方潜在收益。因此,定价数据资产一定要考虑数据资产交易市场的套利行为。
在遵循基本定价理论(主要包括劳动价值论、效用理论、套利与均衡理论)的前提下,学术界和商业界广泛讨论了数据资产的定价问题。已有关于数据资产定价的研究主要分为三类方法:(1)根据服务性质确定数据的价格,如订阅定价机制、按使用付费定价机制和免费定价策略。这种定价方法未考虑数据资源的固有价值,因此很难反应数据价值的差异化。(2)根据价值属性确定数据的价格。例如,细粒度的数据定价策略和基于噪音的查询应答的定价策略。细粒度的数据定价策略通过在粒度级别分析数据价值为数据价格设定提供指导性建议。基于噪音的查询应答的定价策略通过加噪的方式降低数据信息的隐私量,并根据数据的隐私损失确定数据的价格。根据价值属性确定数据价格的定价方法能体现数据的价值差异,并指明隐私损失、价值评估等数据价格影响因素与数据价格的关系。(3)根据盈亏平衡分析等数学模型确定数据的价格。例如,基于销售数据分析的定价策略和基于数据供应链利润绩效的定价机制。这种定价方法以数据收益为导向,缺乏细粒度的数据价值分析。
数据资产按照数据资产供应链可分为“源数据、数据集和数据产品/应用”三个生命周期阶段。本文从供应链的视角出发,针对数据资产不同生命周期阶段制定不同的定价机制:(1)源数据。源数据是一种多源异构的原始数据信息,包括数据所有者存储在组织中的所有属性和记录。本文通过五元组(数据元组id、数据质量、数据权威度、隐私损失、权限开放等级)对源数据进行计量计价。(2)数据集。数据集是对源数据的整合。对于数据集定价,我们首先需要确定数据产品的价格。然后按收益分成的方式确定数据集的价格,其中收益分成的比例根据数据集和数据产品的盈亏平衡确定。(3)数据产品。我们通过数学优化方法分析数据资产供应链的利润绩效,其中使供应链整体利润最大的数据产品价格将被我们采纳。我们发现:第一阶段的数据资产价格基于元组粒度级别上确定,并正向影响后面两个阶段的价格;在第二阶段,我们实现了数据集和数据产品的盈亏平衡;在第三阶段,我们实现了数据资产供应链整体利润的最优。
技术实现要素:
1)数据资产价格评估dataassetpriceassessment
古典经济学以及马克思主义经济学认为价格是价值的外在体现;现代市场经济学认为价格是由市场调节决定的。事实上,这两种说法辩证地存在,即价值和市场调节共同在影响价格的制定。本章重点介绍价值如何影响数据资产价格,而把关于市场调节的内容放到第三部分。为了可靠的计量数据资产的价格,我们先介绍一些关于价格评估的标准设定。
1.1标准设定standardsetting
标准是衡量事物优劣的基准,在不同的应用场景中被赋予了不同的涵义。所有的标准设定方法,尽管其很详尽、系统化,仍不能脱离人的主观判断。从这个意义上看,标准并不能完全客观的设定,只能一定程度反应客观事实。在本文,我们讨论了价值量、隐私损失等级和权限开放等级三类标准设定。隐私损失等级越大代表隐私损失越大;权限开放等级越大则表示权限损失越大。
隐私损失容忍度指的是数据所有者能接受的最大隐私损失量。注意,隐私损失容忍度不同于隐私损失。比如,john的隐私损失容忍度为0.3;数据需求方对数据的隐私损失要求为0.2(或者任意小于等于0.3的值);那么,系统在提供数据时将纳入john的数据,并按0.2对数据进行加噪。当然,隐私损失补偿也会按照0.2来计算,因为实际的隐私损失是0.2。反之,如果数据需求方对数据的隐私损失要求为0.4(或者任意大于0.3的值);那么,系统在提供数据时将不纳入john的数据,因为john不能接受比0.3大的隐私损失并且系统必须满足john的隐私保护需求。
1.2属性选择attributeselection
影响数据资产价格的因素有许多,比如成本、质量、时效、可信度、数量等。所以几乎不可能设计出一个覆盖所有价格相关因素的定价机制。为了通用地、合理地定价数据资产,我们研究了多种典型数据资产的定价策略。这包括数字媒体(图像、音频、视频)、知识产权和软件即服务产品的定价策略。在此基础上,我们选出了成本、数据质量、数据权威度、隐私损失和权限等级五个主要属性用于评估数据资产的价格。
(1)成本cost
成本是指卖方生产数据资产的各种成本,由固定成本和边际成本构成。固定成本指一个组织或企业收集、整合和加工数据,然后形成第一个中间数据产品或最终数据产品的成本。边际成本指每新增一个单位的数据产品所增加的成本。由于数据资产具有数量大的特性,其固定成本相对很小。因此在估计数据资产的成本时,常常指边际成本。
(2)数据质量dataquality
数据质量是保障数据分析结论有效和准确的基础。狭义的数据质量包括数据的准确性、及时性、完整性和一致性。数据的准确性指数据是否有错误;及时性指数据的最新程度;完整性指数据内容的完整程度;一致性指数据是否以相同的格式呈现。广义的数据质量还包括数据整体的有效性,例如,数据整体是否是可信的、数据的取样是否合理等。狭义的数据质量针对的是数据原生属性值的质量,而广义的数据质量更倾向于数据的信息质量。数据质量越好意味着数据可用性越高,因此数据资产价格和数据质量成正相关关系。
(3)数据权威度dataauthority
在《新现代汉语词典》中,对于权威的解释是:(1)使人信从的力量和威望;(2)是在某种范围里最有地位的人或事物。权威强调的是某个人、某种组织或某种思想体系被社会所认可、信任并自愿支持。数据权威度来源于微博用户权威度,指数据在数据市场中的影响力和社会对其信服的程度。
数据权威度由数据影响力和数据可信度两部分组成。数据影响力指数据对数据市场的作用程度及数据被传播的程度。关于数据影响力的定量评价方法有很多,如影响因子,h指数和自引率等。数据可信度指数据被公众信任和支持的程度。数据可信度与数据监管平台的可靠性、数据提供者的素质有关,比如权威机构或信用良好的用户提供的数据可信度一般较高。
数据权威度反映的是公众对于数据的评价和认可程度,对数据资产价格具有正向影响作用。
(4)隐私损失privacyloss
chaoli&rachananget等人指出分析数据信息会损害数据所有者的隐私,数据买方必须为此付费并且数据所有者应该因失去数据隐私而获得补偿。在本文中,数据所有者需要设置自己的隐私损失容忍度。买方选择需要的隐私损失,并根据系统检测的实际隐私损失支付相应的补偿价格。卖方和买方通过选择隐私损失等级可以控制自己的收益和支出。
数据资产交易中可能存在隐私的套利。比如,一个精明商家想获取“john是否有糖尿病”的数据信息(标记为info1)。假设他已经知道john是第100号糖药病检查者,那么他就可以通过同时购买数据信息“医院前99名糖药病检查者的患病人数”(标记为info2)和数据信息“前100名糖药病检查者的患病人数”(标记为info3)来得知答案。这个例子中,info2和info3的隐私含量极低,相应的价格也极低(价格分别为1美元和2美元)。但info1的隐私含量却极高,相应的该数据信息价格也极高(价格为100美元)。这样一来,这个精明商家应该花100美元才能搞定的事情现在用3美元就完成了。套利交易会侵犯数据所有者的隐私,损害卖方潜在收益。因此,合理的隐私补偿机制一定是无套利的。
我们从推测糖尿病患者的例子中发现,正是数据中的细小差异导致了潜在的隐私泄露和提供了隐私套利的条件。差分隐私(differentialprivacy)是一种安全计算方法,不仅可以保证对手无法从部分数据信息中了解到关于整个数据的有用信息,还可以确保对手对具体数据所有者一无所知。
definition1:(ε-differentialprivacy)arandomizedalgorithmm:d→rsatisfiesε-differentialprivacy(orε-dp)ifforeverypairofneighboringdatasetsx,y∈dwherexandydiffersbyonlyonerecord,andforanyset
pr(m(x)=o)≤eε×pr(m(y)=o)(1)
ε-dp要求对于输入不同数据集x和y,得到相同输出结果o的概率差(用eε表示)不大。概率差描述受差分隐私保护的输出数据信息与真实数据信息的接近度。概率差越小说明差分隐私保护力度越高,此时根据输出信息推断真实信息的难度越大。隐私预算参数ε表示隐私保护程度,ε∈0,1。本文用ε量化隐私损失等级。ε越小,隐私损失越小。
差分隐私意味着所有所有者或数据资产具有相同的隐私保护/损失等级ε。个性化差分隐私(personalizeddifferentialprivacy)指在差分隐私中每个数据资产或每个数据所有者都有自己的隐私损失容忍值ε′,ε′∈[0,1]。ε′-pdp保护有两种实现机制:(1)拉普拉斯机制(laplacemechanism),用于数值型结果的保护;(2)指数机制(exponentialmechanism),用于离散型结果的保护。本文在差分隐私的基础上引入个性化差分隐私既能避免由隐私泄露导致的隐私套利,又满足用户不同隐私级别的保护需求。
definition2:(personalizeddifferentialprivacy)regardingthetolerableprivacylossε′ofeachuser,arandomizedmechanismm:d→rsatisfiesε′-personalizeddifferentialprivacy(orε′-pdp)if,foreverypairofneighboringdatasetsx,y∈dwherexandydiffersbyonlyonerecord,andforanyset
pr(m(x)=o)≤emin(εx',εy')×pr(m(y)=o)(2)
其中εx'表示数据集x的隐私损失容忍值,εy'表示数据集y的隐私损失容忍值,而min(εx',εy')表示数据集x和y较小的那个隐私损失容忍值。概率差emin(εx',εy')越大,根据输出信息推断真实信息的难度越小。此时受差分隐私保护的数据信息与真实数据信息的接近度越高,数据资产价值较高。我们假设,对于一对相邻数据集,这种接近度用t(ε)表示,且t(ε)∝emin(εx',εy');对于多对相邻数据集,这种接近度用t(ε)表示,且t(ε)∝emin(ε1',ε2',…,εn'),n≥1。很容易理解数据资产价值∈(0,数据资产原始价值]。如果我们用数据资产原始价值×t(ε)表示数据资产价值,那么t(ε)∈(0,1]。到目前为止,我们归纳出函数t(ε)有两个充分条件:(1)t(ε)∝emin(ε1',ε2',…,εn');(2)t(ε)∈(0,1]。根据这两个充分条件,我们可以设计函数t(ε)为t(ε)=emin{εi}-1,εi表示数据所有者的实际隐私损失。当min{εi}=0时,t(ε)取最小值
总之,我们用εi量化数据所有者的个性化隐私损失,εi∈[0,1]。并且引入个性化差分隐私保护数据所有者的潜在隐私损失和避免隐私套利。
(5)权限等级permissionlevel
数据资产的供给方式根据权限开放程度的不同大致可以分为以下三种:
免费开放(openandfree):这是一种免费的数据资产供给方式。供应方把数据资产按照一定数据格式(主要是word、pdf、图片、excel等数据格式)免费提供给需求方,比如网页资源的免费浏览、下载和转载。这种供给方式一般不限定买方对象、需求量和用途(法律规定除外),一般保留数据资产的产权和管理权,类似开源软件方式(opensourcesoftware)、开源数据社区(opendatacommunity)。
有偿交易(paidtransaction):这是一种付费的数据资产供给方式。供应方把数据资产按照一定方式有偿提供给需求方,以此获得收益或者等价交换,可以参考实物商品的交易机制。数据资产作为一种无形商品,具有易复制、易传播、易加工等多种特性。这些特性使得数据资产交易附带产权界定、产权定价等多种复杂问题。
有偿服务(paidservice):这是一种付费的供给方式。供应方为需求方提供有偿的数据服务,以此获得收益,类似实物商品的租赁机制。paidservice与paidtransaction相似却不相同,体现在它尽量避免产权、管理权等问题,仅涉及使用权和安全访问控制等问题。这种供应方式可以大大降低成本,并且一定程度上避免了产权纠纷。文献引用、软件使用权购买是典型的案例。
本文引入了多级权限的数据供给方式,让每个数据所有者都可以根据个人需求设置数据资产的权限开放等级o,o∈[0,1]。o越小,权限保护水平越高。
2)理论模型theoreticalmodel
数据集:数据集是源数据的整合与封装,通常以表格的形式出现,比如报表、专有数据集。每一列代表一个特定属性。每一行是一个数据元组,对应于某一成员的数据信息。对应于行数,该数据集可能包括一个或多个成员。
数据产品:数据产品是指以数据为驱动、可以发挥数据价值去辅助用户更优的做决策甚至行动的一种产品形式。它在用户的决策和行动过程中,充当信息分析的展示者和价值的使能者。数据产品包括智力成果(即方案设计、智库策略等)、数字作品(即数字媒体及音像制品等)等数据资源。
数据所有者(也是数据供给方):数据所有者指的是拥有数据的个体、机构或企业,为数据资产供应链提供原始的数据。数据所有者既是数据应用的消费者,也是数据的生产者。
数据加工方:数据加工方一般是政府、机构或企业,也可以是个体。他们通过采集、存储和整合源数据信息输出高质量的、高可用的数据集。
应用供给方:应用供给方一般是公司、企业或机构,也可以是个体。他们依赖于对数据集的分析和运用来解锁数据价值,从而指导数据产品/应用的生产。
2.1数据资产供应链dataassetsupplychain
在介绍数据资产供应链之前,我们先简单介绍供应链的概念和流程框架。
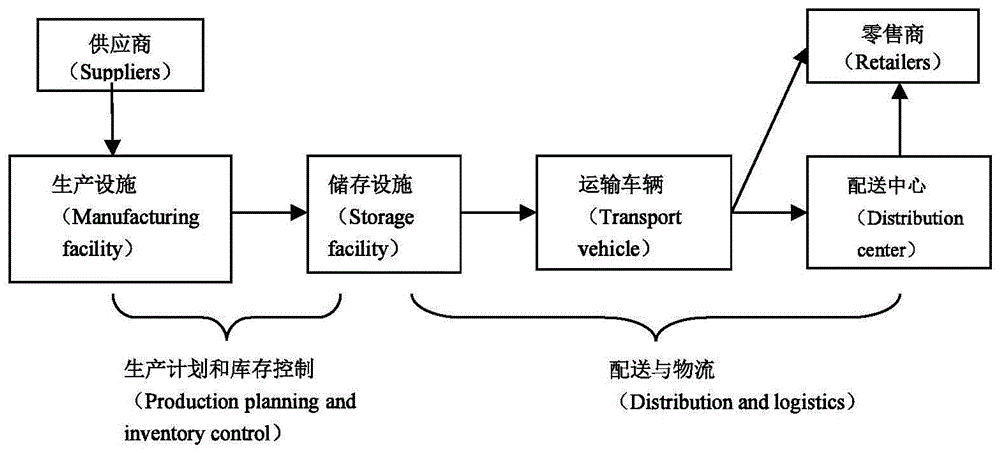
供应链(sc,supplychain)的概念最早出现在20世纪80年代,描述的是一种集成过程:通过许多不同的商业实体(即供应商、制造商、分销商和零售商)共同努力,将原材料转换成产品,然后交付给客户。图1描述了传统供应链的流程框架。供应链上的活动包括采购原材料,制成中间产品以及最终产品,最后由销售网络把产品送到消费者手中。
基于传统供应链的流程设计和管理,我们分析数据资产供应链的数据资产和资金的流动特征。
数据资产供应链是一个通过数据资产将不同商业实体连成一个整体的功能链结构。围绕数据供给方,数据加工方,应用供给方和最终用户四个核心商业实体,数据资产的生命周期可分为源数据、数据集和数据应用三个阶段。图2描述了数据资产供应链的流程框架:(1)数据供给方将源数据以一个五元组(数据元组id、数据质量、数据权威度、隐私损失、权限开放等级)为基本计量计价单位有偿提供给数据加工方;(2)数据加工方将源数据整合并封装形成高可用性的数据集,并售卖给应用供给方;(3)应用供给方通过数据加工、分析与使用将数据信息转换成最终数据产品,并由销售网把数据产品销售到终端用户手中;(4)终端用户在使用数据产品的过程中产生大量源数据,应用平台(数据加工方)沉淀这些源数据信息并以五元组为计量计价单位给予相应的数据价值补偿。
按照数据资产的流动方向,我们将数据资产供应链的商业实体分为上游、下游和终端。数据加工方为上游,应用供给方为下游,而终端用户为终端。见图2,上游负责数据资产的采集和整合,为下游输入数据以此获得合理的利润。下游的生产依赖于上游的数据供给。终端用户在使用数据应用的同时产生新的源数据。应用平台(上游)沉淀用户源数据并给出相应的补偿。通过如此循环往复,该数据资产供应链实现数据资产流动的闭环,用户是数据源源不断产生的根本。
2.2模型设置和假设meodelsetupandassumptions
为了明确数据资产不同生命周期的价格制定原理,我们建立了一个数据资产交易和共享架构,见图3。
数据所有者也是终端用户,为数据加工方贡献价值为vi的源数据,并获得金额为yi(vi)的补偿。yi(vi)是关于价值vi的价值补偿函数。需要注意的是,数据加工方接收到的总价值v应当等于所有数据所有者贡献的价值总和即v=∑vi。并且,数据加工方支付给所有者的总价值补偿y(v)应当等于所有所有者的价值补偿总和,即y(v)=∑yi(vi)。
数据加工方通过采集和整合数据所有者的源数据,为数据资产供应链输入高质量、大规模和可使用的数据集。单位数据集的价值量用小写字母v表示。
在数据资产交易和共享架构中,应用供给方也是数据集买方。应用供给方作为数据集买方提出数据查询请求bj(q,cmax,n),q表示查询语句,cmax表示最大预算,n表示预计购买量。数据加工方返回买方一个价格菜单供买方参考选择,如图9所示。图9中查询数据集的averagedeviation(e)可以用各种距离函数和相似度函数计算得到。比如数据类型的结果可以用欧几里得距离(euclideandistance)函数,而文本类型的则可以用余弦相似度(cosinesimilarity)函数。samplesize(n)表示查询数据集样本的容量大小,比如对于文本型的数据集,n表示文本数目;对于记录型数据集,n表示记录数目。买方根据个人偏好选择价格套餐menu(e,n)并按单位数据集的价格ρs付费,其中e表示数据集平均偏差,n表示购买量。然后数据加工方返回业务处理结果{a(q),ct,|rs|,e},其中a(q)表示购买的数据集,ct表示买方余额,|rs|表示该数据集的size,e表示该数据集的平均偏差。
应用供给方为终端用户提供价值量为r′v的数据应用并按单位应用价格s收费。r′是数据价值的转换率,表示数据集的数据信息转变成产品时价值的不确定性。为了建立一个简单和容易处理的模型,我们假设r′在r和1之间均匀分布。r表示数据价值的最低转换率。
终端用户既是数据应用的消费者,又是数据的生产者。我们将终端用户的人数标准化为单位1。图3中u(θ,s)的θ表示用户支付数据应用单位价值的意愿,反应用户对数据应用单位价值的满意程度。s表示单位数据应用的价格。
2.3定价机制研究researchonpricingmechanism
首先,我们需要明确源数据、数据集和数据应用的计量计价方式。根据数据资产交易和共享框架,数据所有者以五元组为计量计价的基本单位为数据加工方提供源数据和得到价值补偿。数据加工方整合源数据为一个数据集,并以一个集合为计量计价单位。最后应用供给方购买和应用该数据集信息生产数据应用,这里单份数据应用为一个计量计价单位。从中我们发现源数据、数据集和数据应用的计量计价单位存在对应关系,见图4。源数据和数据集的对应关系是n:1,因为一个数据集里包含了多条源数据信息;数据集和数据应用的对应关系是1:1。虽然一个数据集可以用于多个数据应用的生产,但在收益分成的计价方式中,数据应用的边际收益也是数据集的边际收益。因此,数据集和数据应用关于计量计价单位的对应关系是1:1。
其次,我们需要介绍源数据定价机制的特殊性。数据加工方(一般是企业、组织或机构)通常通过平台沉淀数据的方式采集和整合源数据。这种数据获取方式绑定了源数据的生产和出售;并且,这种数据获取方式不需要数据所有者花销额外的成本。因此,源数据的价格制定适合采用价值补偿的方式,即源数据的价格等价于源数据的价值。
我们用d表示应用的需求量。根据图4,d也表示数据集需求量。根据理论总利润=单位利润×需求量,传统分散定价机制(decentralizedpricingmechanism)的π1、π2和π可以表示为:
π1d=(k-τ-v)d(3)
π2d=(s-k-φ)d(4)
πd=π1d+π2d=(s-τ-v-φ)d(5)
我们的定价机制基于nash议价机制,这种机制按比例分配收入。具体点来说,基于数据加工方输出的数据集,应用供给方为终端用户提供应用,按单价s收费,其中ρs支付给数据加工方,ρ∈[0,1]。此时的数据加工方、应用供给方和数据资产供应链的利润函数如下:
π1n=(ρp-τ-v)d(6)
π2n=((1-ρ)p-φ)d(7)
πn=π1n+π2n=(p-τ-v-φ)d(8)
这种按比例分配收入的定价机制将数据加工方和应用供给方的利益绑定在一起。因此,只要将应用单价s和收入分配比例ρ设置为一个平衡值,那么就可以实现这二者利润的均衡。此外,数据资产供应链的整体利润同时受应用单价s和用户需求量d的制约。nash议价机制相比传统分散定价机制的优点由后面的章节具体分析。
我们假设数据加工方输出价值为v的数据集。应用供给方为终端用户提供价值为r′v的应用并按应用的单价s收费。显然单位支付意愿为θ的用户购买应用的期望效用为
基于数据资产不同生命周期阶段的价格制定原理,我们分析数据资产供应链的利润绩效:数据加工方利润、应用供给方利润、供应链整体利润和消费者盈余。
2.3.1分散定价机制decentralizedpricingmechanism
在传统的分散定价机制中,供应链的各个参与者都只考虑自己的利润而忽视整体的利润。我们将
求解这个式子的优化问题,我们得到一个局部最优价格
2.3.2nash议价机制nashbargainingmechanism
在nash议价机制中,供应链的各个参与者通过讨价还价寻求一个让大家都满意的价格,这种定价机制重视的是整体利润和利润分配的均衡性。我们将
求解这个式子的优化问题,我们得到一个平衡价格
比较两种机制下的利润绩效,我们发现π1d=π1n,π2d<π2n,πd<πn,并且csd<csn。这意味着nash议价机制比传统分散定价机制具有更大的供应链利润和消费者盈余。此外我们发现,πn=πmax且π1n=π2n,这意味着各个参与者等比例共享供应链的最优利润,实现了数据资产交易和共享过程中的双赢。
a基于价值定价源数据pricingsourcedatabasedonvalue
影响数据资产价值的因素有许多,所以几乎不可能设计出一个覆盖所有价值相关因素的定价机制。基于对多种典型数据资产的定价策略的分析,我们选出了数据质量、数据权威度、隐私损失和权限等级四个主要价值属性用于评估数据资产的价值。源数据的采集方式一般是平台沉淀而不需要数据所有者花销额外的成本。因此,源数据的价格制定仅依据价值评估而不考虑成本。
我们用q表示数据质量贡献的价格,用w表示数据权威度贡献的价格,εi表示个性化隐私损失,oi表示个性化权限开放等级。设α为数据质量权重,β为数据权威度权重,让它们满足以下约束:
α+β=1(11)
则源数据价格y可以表示为y(q,w,εi,oi)=(q×α+w×β)×t(εi)×oi。这里,t(εi)=emin{εi}-1表示隐私损失为εi时数据资产价值与其原始价值的接近度。
b基于nash均衡定价数据集pricingdatasetbasedonnashequilibrium
根据nash议价机制,应用供给方向终端用户按应用单价s收费,其中的ρs是单位数据集的价格,ρ∈[0,1]。则数据集单价为
c基于nash均衡定价数据产品/应用pricingdataproducts/applicationsbasedonnashequilibrium
根据nash议价机制,我们得到一个能使数据资产供应链的利润最大的数据应用单价,即
附图说明
图1描述了传统供应链的流程框架
图2描述了数据资产供应链的流程框架
图3描述了数据资产交易和共享架构
图4描述了不同阶段计量/计价单位的对应关系
图5描述了平衡共赢定价机制中数据价值的补偿
图6描述了平衡共赢定价机制的仿真
图7描述了nash议价机制与分散定价机制的比较
图8描述了注释摘要
图9描述了价格
图10描述了数据集示例
具体实施方式
下面结合实例对本发明作进一步的说明:
1)实验环境描述
为了验证本文关于价值评估、权限等级和隐私损失与数据资产价格关系的研究,证明平衡共赢定价机制的可行性和优越性,我们进行了如下实验:
(1)平衡共赢定价机制的模拟
a.源数据的价值补偿分析;
b.数据集和数据应用的价格分析;
(2)与分散定价机制的比较
c.对于相同数据偏差e,比较两种定价机制的数据资产价格;
d.对于相同数据集成本τ和数据应用成本φ,比较两种定价机制的利润绩效。
2)实验数据描述
这里我们使用一个具体的例子来进行实验。假设数据交易平台中有一个数据集,包含10个数据元组,分别对应10个数据所有者。这个数据集的原始数据价值被设置为100。数据集样本见图10。我们假设数据集的加工成本τ=5,依赖该数据集生产数据应用的成本φ=20,数据信息转变成产品时价值的转换率r=0.2。根据前文的推理
实验中我们应用拉普拉斯机制对数据集进行加噪。我们根据拉普拉斯分布的逆累积分布函数x=-λ×sgn(p-0.5)×ln(1-2×|p-0.5|),求解每个数值对应的噪声x。
3)实验图表描述
图1描述了传统供应链的流程框架
图2描述了数据资产供应链的流程框架
图3描述了数据资产交易和共享架构
图4描述了不同阶段计量/计价单位的对应关系
图5描述了平衡共赢定价机制中数据价值的补偿
图6描述了平衡共赢定价机制的仿真
图7描述了nash议价机制与分散定价机制的比较
图8描述了注释摘要
图9描述了价格
图10描述了数据集示例
4)实验结果分析
图5显示的是平衡共赢定价机制中数据价值的补偿。从图5(a)中我们看出源数据价格yi随隐私损失εi的增大而增大。当隐私损失εi为0时,yi>0。因为隐私价值只是数据资产价值属性的一类,比如脱敏后的数据资产仍然有价值。图5(b)说明了源数据价格yi随权限开放等级oi的增大而增大。权限开放等级越大,价格越高;但如果权限等级为0则意味着数据资产不对外开放和不对外提供价值,此时价格为0。图5(c)表明数据加工方支付给数据所有者的总价值补偿y(v)应当等于所有所有者的价值补偿总和,即当
图6显示的是平衡共赢定价机制的模拟结果。图6(a)显示数据集价格k、数据应用价格s与价值v呈正相关关系,这可以用价值正向影响价格的理论来解释。当价值为0时,k与s不等于0,因为除了价值,成本等其他因素也影响价格的制定。在图6(b)中,我们观察到用户最低支付意愿必须超过一定的值,数据集价格k、数据应用价格s才有效。这是因为虽然较低的数据集价格k和数据应用价格s能降低支付意愿阈值从而获得更多的消费者,但会导致入不敷出的结果。
图7(a)通过线性拟合的方法展示了源数据价格y、数据集价格k、数据应用价格s与数据偏差e的关系:(1)数据偏差e越大,源数据价格y、数据集价格k与数据应用价格s越低;(2)对于相同的数据偏差e,两种定价机制的源数据价格y相同;(3)对于相同的数据偏差e,分散定价机制的数据集价格、数据应用价格都分别对应地大于平衡共赢定价机制的数据集价格、数据应用价格。
此外,图7通过函数模拟的方法分析数据资产供应链的利润绩效,包括供应链上游(数据加工方)利润、供应链下游(应用供给方)利润、供应链整体利润和消费者盈余。注意价值v必须大于0。因为当价值为0时,用户购买应用的期望效用u<0,
图7(b)显示消费者盈余cs随价值v的增加而增加。基于nash议价机制的消费者盈余csn等于供应链最大消费者盈余csmax,并且大于基于分散定价机制的消费者盈余csd。图7(c)显示供应链整体利润π随价值v的增加而增加。基于nash议价机制的供应链整体利润πn等于供应链最大整体利润πmax,并且大于基于分散定价机制的供应链整体利润πd。图7(d)显示,基于nash议价机制的供应链上游利润π1和供应链下游利润π2相等,而基于分散定价机制的供应链上游利润π1大于供应链下游利润π2。
上述实验结果表明,nash议价机制明显优于分散定价机制:对于相同的数据误差e,(1)纳什议价机制与分散定价机制具有相同金额的补偿y;(2)纳什议价机制具有更便宜的数据集价格和数据应用价格;(3)纳什议价机制具有更大的利润绩效。我们通过采用nash议价机制,实现了数据资产供应链的整体利润最优和各个参与者公平的共享供应链最优利润。这达到了共赢的研究目的。此外,我们通过支持个性化隐私保护和多级权限设置,能够保证用户完全控制自己的收益和支出。这达到了平衡金钱与数据价值的研究目的。
一个动态的、标准化的定价机制将彻底改变现有的数据资产交易和共享市场,促进交易和共享的透明性,提高效率。由于数据资产的定价依赖于大量的变量,如数据质量权重和权威度权重,因此该模型需要时间去开发、测试和培训。
- 还没有人留言评论。精彩留言会获得点赞!