面向口令猜测的语料乘积规则的描述、生成与检测方法与流程
本发明涉及口令猜测
技术领域:
,具体涉及一种面向口令猜测的语料乘积规则的描述、生成与检测方法。
背景技术:
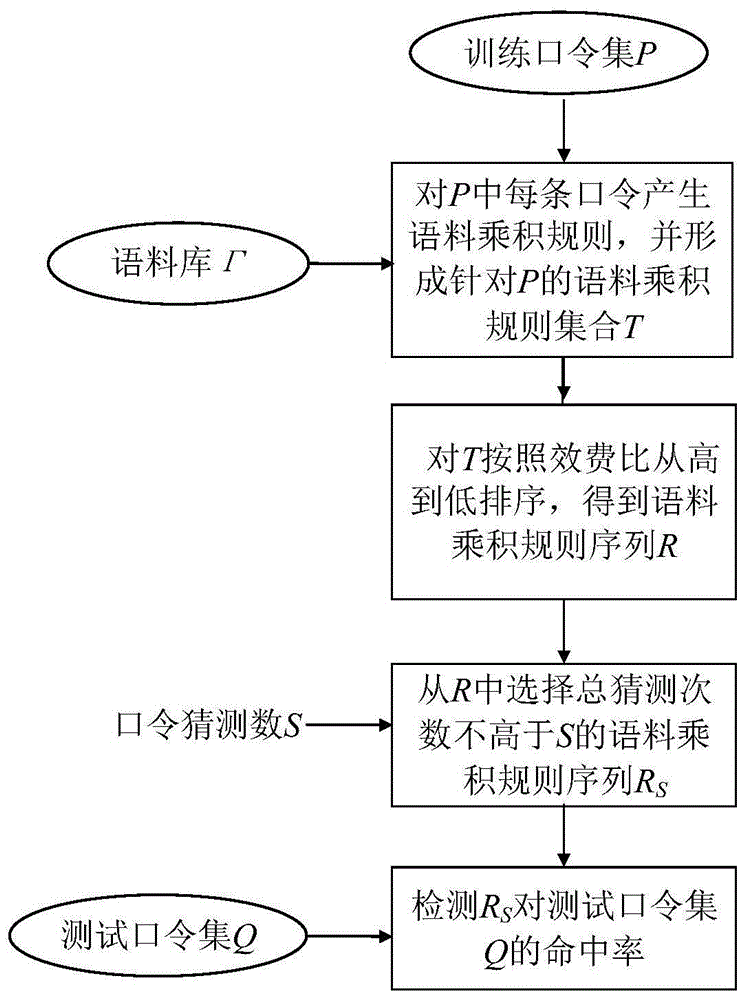
:口令猜测的基本方法是不断尝试用户可能使用的口令,直至发现正确口令,或者达到预定猜测次数而放弃猜测。因此,要提高猜测的效率需要优先猜测用户使用可能性更高的口令。现有的口令猜测方法主要包括:暴力、碾压、markov过程、概率上下文无关文法(pcfg)、语义模式等五种类型。暴力方式是最为传统的口令猜测方法,其主要缺陷是能猜测的口令长度较短。由于总猜测次数的限制,全键盘字符的暴力猜测长度往往不超过9个字符,仅仅包含小写字母和数字的暴力猜测长度往往不超过11个字符。碾压方法([tat15]eminislamtath,"crackingmorepasswordshasheswithpatterns",ieeetrans.oninformationforensicsandsecurity,vol.10,no.8,pp.1656-1665,2015)是指根据口令变形规则(例如olchashcat中的rockyou-30000规则库)将源口令集变形成为待猜测的口令。这种口令猜测方法在实践中非常常用,但是它的有效性依赖于源口令集,对源口令集合中未出现的口令将无法完成有效猜测。markov过程方法([ma14]jerryma,weiningyang,minluo,ninghuili,"astudyofprobabilisticpasswordmodels",inproc.ieeesymposiumonsecurityandprivacy,pp.689-704,2014;[dur15]markusdurmuth,fabianangelstorf,claudecastelluccia,danieleperito,abdelberichaabane,"omen:fasterpasswordguessingusinganorderedmarkovenumerator",inproc.the7thsymposiumonessos,pp.119-132,2015)是建立训练口令集中字母之间的转移概率矩阵,并据此预测某个口令的概率。该方法的最大特点是不依赖于语料集,可以自主发现口令内常见的词汇,而且可以有效处理词汇中常见的变形形式。但是其缺点是需要高阶markov过程以“记忆”较长的词汇内容,而且语义不甚明确。pcfg方法([wei09]mattweir,sudhiraffarwal,brenodemedeiros,billglodek,"passwordcrackingusingprobabilisticcontext-freegrammars",inproc.30thieeesymposiumonsecurityandprivacy,2009,pp.391-405)的核心是将口令按照字符类型分段,并产生两级概率:第一级为不同字符类型分段的结构概率,第二级是语料库中每个单词的概率,并由此可以推测出特定结构和语料构成口令的概率。改进的pcfg方法([hou15]shivahoushmand,sudhiraggarwal,randyflood,"nextgenpcfgpasswordcracking",ieeetrans.oninformationforensicsandsecurity,vol.10,no.8,pp.1776-1791,2015)是进一步加入了键盘串集合,并对语料库的词汇频率进行了laplace平滑。前者在一定程度上弥补了原有pcfg方法按照字符类型分词的局限性,后者则可以进一步丰富语料库的内容,从而部分解决无法描述训练口令集中未出现词汇的问题。但是pcfg方法有两个重要缺陷:1)它按照口令的字符类型分段,对于包含多种字符类型的语料词汇难以提供统一的处理模式;2)它需要计算每个待猜测口令出现的概率,并按照各个口令的概率从高到低依次猜测,在口令猜测过程中引入了较大的计算开销,难以满足在线口令猜测过程的口令生成速度要求。语义模式([ver14]rafaelveras,christophercollins,juliethorpe,"onthesemanticpatternsofpasswordsandtheirsecurityimpact",inproc.networkanddistributedsystemsecuritysymposium(ndss),2014,pp.1-16)将根据语料库中语义明确的词汇对训练口令进行结构划分。在划分方法上,采用了词汇最大覆盖率作为分词依据,而且采用了不定长的语料和结构描述。与此同时,保持了pcfg方法中对语料库的每个词汇进行频率统计,并由此计算出每条口令概率的方法。该方法有两个主要问题:1)采用词汇最大覆盖率作为分词依据,有可能会导致口令分词不恰当;2)和pcfg方法相同,该方法需要预测每条待猜测口令的概率,并根据概率从高到底依次尝试,也将在口令猜测过程中产生较大的开销。技术实现要素:为了解决已有口令猜测方法中存在这些不足之处,本发明提供了一种面向口令猜测的语料乘积规则的描述、生成与检测方法,即通过穷举每条训练口令可能的基于语料的描述方法,并根据各种描述方法的猜测次数和复杂度来选择合理的语料乘积规则;其次,累计训练口令集合中各种类型规则在训练口令集合中的出现频度;然后,使用效费比指标对上述规则集合进行排序,并根据口令猜测数形成最终的语料乘积规则序列;最后,评价语料乘积规则序列对测试口令集的命中率。本发明的目的至少通过如下技术方案之一实现。面向口令猜测的语料乘积规则的描述、生成与检测方法,包括以下步骤:s1、定义语料库的约束条件;s2、描述语料乘积规则;s3、针对训练口令集p中的每条训练口令p产生单条口令对应的语料乘积规则,并形成训练口令集p对应的语料乘积规则及其出现频度的集合t;t中的元素为二元组(r,f),其中r为规则,f为规则r出现的频度;s4、使用效费比指标对规则集合t进行排序,得到语料乘积规则序列r;s5、根据外部输入的口令猜测次数s,从r中选择语料乘积规则,形成总猜测次数小于s的口令猜测规则序列rs;s6、检测总猜测次数小于s的口令猜测规则序列rs针对测试口令集q的命中率。进一步地,步骤s1中,所述语料库的约束条件包括:1.1)、语料库γ由若干语料集合构成;1.2)、每个语料集合的词汇具有相同的属性和长度,数量不超过m条(m可以设置为6000或其他合理的预先固定值),且词汇的字符类型不受约束;1.3)、两个语料集合之间没有相同的词汇;1.4)、语料库中包括小写字母语料集合[az]、大写字母语料集合[az]、数字语料集合[09]和特殊符号语料集合[sp],分别对应ascii码中的小写字母、大写字母、数字和不包含上述类型的其他可打印字符。语料库γ包含了n个语料集合,使用ci表示第i个语料集合,其中i=1…n。同一个语料集合包含了同一类型的词汇。语料集合的词汇类型包括但不限于英语常见姓名、地名、常见键盘字符序列、常见日期格式、汉语拼音、中国大陆手机号码等。对于第i个语料集合ci,|ci|定义为其词汇的数量,l(ci)定义为其词汇的长度。进一步地,步骤s2中,所述语料乘积规则包括:2.1)、语料乘积规则由若干语料集合组成;基于语料库γ,语料乘积规则r可以描述为n个语料集合的组合:r=c1…cn,其中ci∈γ,i=1,…,n,n≥1。2.2)、语料乘积规则所对应的猜测口令集合为此规则中所有语料集合的笛卡尔乘积,此规则的猜测次数为上述笛卡尔乘积集合的元素数量;语料乘积规则r对应的猜测口令集合为c1×c2×…×cn,其中×表示集合的笛卡尔乘积。语料乘积规则r的猜测口令数记为|r|,等于猜测口令集合的数量,即2.3)、一条语料乘积规则所对应的猜测口令集合中所有口令的长度相同。语料乘积规则r的段数为n。语料乘积规则r对应的猜测口令集合中所有的口令长度均为进一步地,所述步骤s3包括以下步骤:s3.1、对训练口令集p中的一条训练口令p,穷举基于语料库γ所有能够产生p的语料乘积规则,然后在这些语料乘积规则中,选择猜测次数不大于这些语料乘积规则中最小猜测次数10倍的语料乘积规则中段数最小的语料乘积规则,作为单条训练口令p对应的语料乘积规则r;s3.2、将单条训练口令p对应的语料乘积规则r加入到口令训练集p对应的语料乘积规则与出现频度的集合t中;如果该语料乘积规则已经出现,则将其出现频度加1;否则,将此规则加入到集合t中,并设置其出现频度为1;s3.3、对训练口令集p中的每条训练口令p重复步骤s3.1和s3.2,得到最终的集合t。具体地,给定语料库γ和训练口令集合p,将根据下述算法产生语料乘积规则与其出现频度的集合t。算法运行前输入训练口令集合p以及语料库γ,算法运行流程如下:1.2.对训练口令集合p中的每条训练口令p,进行以下循环:2.1.训练口令p为一个长度为m的字符串,记为p=c1,…,cm;2.2.对于口令p=c1,…,cm,创建一个有向无环图g=<v,e>,图g的顶点集合v初始化为m+1个顶点,记为v={v1,…,vn,vm+1}。2.3.i从1到m,进行以下循环:2.3.1.e=e∪{<(vi,vi+1),li>},li为ci所属的字符集合;2.4.对c1…cn中的任意子串ci…cj进行以下循环,其中1≤i<j≤n;2.4.1.如果语料库γ中存在语料集合c满足ci…cj∈c,则e增加一条边<(vi,vj+1),c>,即e=e∪{<(vi,vj+1),c>};否则,无操作;2.5.临时备选规则集合2.6.对从v1到vm+1的所有路径path,进行以下循环:2.6.1.path所经历的k条边依次为:<(w1,w2).c1>,<(w2,w3).c2>,…,<(wk,wk+1).ck>,其中w1,w2,…,wk,wk+1均为图g的顶点,w1=v1,wk+1=vm+1;ci为对应边的语料集合,i=1,…,k;2.6.2.rtemp=rtemp∪{<c1…ck>};2.7.求rtemp中所有猜测规则的最小猜测口令数gmin,即gmin=min{|r||r∈rtemp};2.8.求rtemp中所有猜测口令数小于10gmin的规则集合r1,即r1={r|r∈rtenp,|r|<10gmin};2.9.从r1中选择段数最小的一个规则r作为口令p对应的语料乘积规则;2.10.若t中存在一个元素(r0,f),满足r0=r,则f=f+1,否则t=t∪{(r,1)};3.输出集合t。其中,有向无环图g=<v,e>,其中v为顶点集合,e为边集合。边集合中的元素为<(vi,vj),w>,标识了从vi到vj的一条边,w为该边对应的语料集合;rtemp和r1为临时规则集合。该算法的核心是从单条训练口令p得到语料乘积规则r,即上述算法中的2.1步到2.9步。在算法的2.1到2.4步中,对单条训练口令p构造基于语料库γ的有向无环图g=<v,e>。在算法的2.5步到2.6步中,产生g中从起点到终点的所有路径,以及每条路径对应的一种语料乘积规则。在算法的2.7步到2.9步,将得到所有可能语料乘积规则的最小猜测口令数,并以其为基准,选取其10倍以内猜测次数的语料乘积规则集合中段数最小的规则为该条口令对应的语料乘积规则。这种选择猜测规则的方法兼顾了语料乘积规则的猜测次数及段数。一方面训练口令对应的语料乘积规则的猜测次数越小越好,以节省计算资源。但是,现实的语料集合规模差异较大,存在着段数较多却有着较小猜测次数的可能性,因此也不能够完全根据猜测次数来决定此口令对应的语料乘积规则。另一方面,简单的语料乘积规则可能会更贴近用户设计口令时的真实用意,因此应该尽可能选择段数较少的语料乘积规则。经过大量尝试,确定了上述猜测次数和段数度之间进行折中的方法。算法的2.10步是将单条训练口令对应的语料乘积规则加入到口令训练集p对应的语料乘积规则与其出现频度的集合t中。如果该类型规则已经出现,则将其出现频度加1;否则,将此规则加入到集合t中,并设置其出现频度为1。进一步地,所述步骤s4包括以下步骤:s4.1、将语料乘积规则的效费比定义为该语料乘积规则在训练口令集合p训练过程中出现的频度除以该语料乘积规则的猜测次数;s4.2、将训练口令集合p所生成的集合t中的语料乘积规则按照效费比从高到低进行排序,形成语料乘积规则序列r。对于从训练口令集合p得到的规则集合t中的每个元素(r,f),其效费比定义为f/|r|,其中|r|为语料乘积规则r的猜测次数,f为规则r出现的频度。规则集合t中的语料乘积规则根据语料乘积规则的效费比从大到小排序,可以得到语料乘积规则序列r。进一步地,所述步骤s5包括以下步骤:s5.1、输入的口令猜测次数s;s5.2、对于按照效费比从大到小排序的语料乘积规则序列r,从序列起始处取语料乘积规则,直至所有选取的语料乘积规则的猜测次数之和不小于口令猜测次数s;s5.3、所有选取的语料乘积规则形成总猜测次数小于s的口令猜测规则序列rs。在口令破解过程中,受猜测时间和计算规模的约束,口令猜测次数s是有限的。对于外界给定的口令猜测次数s,需要从语料乘积规则序列r的起始规则开始选择,直至所选择到的规则总猜测次数达到s为止。即对于语料乘积规则序列r=<r1,...,rn>,找到小于等于n的整数m满足,且则rs=<r1,...,rm>。|ri|为语料乘积规则序列r中第i个语料乘积规则ri的猜测次数。所述步骤s6包括以下步骤:s6.1、将外部输入的测试口令集q的每条测试口令q转换为规则rq;s6.2、判断规则rq是否在口令猜测规则序列rs中,如果rq在rs中,则认为该测试口令q被命中,反之,则认为该测试口令q没有被命中;s6.3、累计测试口令集q中所有测试口令的命中数量;s6.4、口令猜测规则序列rs针对测试口令集q的命中率等于口令猜测规则序列rs中命中的测试口令数除以测试口令集q的测试口令总数。相比现有技术,本发明的有益效果如下:(1)在总猜测次数固定的情况下,口令猜测的命中率较现有技术更高。(2)由于本发明可以根据口令猜测数s,直接产生了口令猜测规则序列rs,避免了pcfg、markov过程、语义模式等方法在口令尝试过程中要计算每条口令的出现概率问题,大幅度减少了后续口令猜测过程的附加开销。(3)本发明具有很强的通用性,不同的语料库可以实现不同类型的口令猜测方法。(4)使用不同地域的训练口令集合p,本发明可以得到针对不同地域的口令猜测规则。(5)检测测试口令集命中率时不需要产生真实的猜测口令集合,本发明只需要计算测试口令集中口令对应的规则,可以快速检测大规模猜测口令集合的命中率,而不受到存储容量的限制。附图说明图1是本发明面向口令猜测的语料乘积规则的描述、生成与检测方法的总体流程图。图2是根据训练口令集产生语料乘积规则序列r的流程图。图3是根据口令猜测次数s,从语料乘积规则序列r中选择口令猜测规则序列rs的流程图。图4是针对测试口令集q,检测总猜测次数小于s的语料猜测规则序列rs命中率的流程图。图5是针对口令“loverain”所产生的有向无环图。图6是训练集为rockyou,测试集为phpbb时,猜测次数与命中率之间的关系图。具体实施方式以下结合附图和实施例对本发明的具体实施作进一步说明,但本发明的实施和保护不限于此。面向口令猜测的语料乘积规则的描述、生成与检测方法,如图1所示,包括以下步骤:s1、定义语料库的约束条件;s2、描述语料乘积规则;s3、针对训练口令集p中的每条训练口令p产生单条口令对应的语料乘积规则,并形成训练口令集p对应的语料乘积规则及其出现频度的集合t;t中的元素为二元组(r,f),其中r为规则,f为规则r出现的频度;s4、使用效费比指标对规则集合t进行排序,得到语料乘积规则序列r;s5、根据外部输入的口令猜测数s,从r中选择语料乘积规则,形成总猜测次数小于s的口令猜测规则序列rs;s6、检测总猜测次数小于s的口令猜测规则序列rs针对测试口令集q的命中率。进一步地,步骤s1中,所述语料库的约束条件包括:1.1)、语料库γ由若干语料集合构成;1.2)、每个语料集合的词汇具有相同的属性和长度,数量不超过m条,且词汇的字符类型不受约束;1.3)、两个语料集合之间没有相同的词汇;1.4)、语料库中包括小写字母语料集合[az]、大写字母语料集合[az]、数字语料集合[09]和特殊符号语料集合[sp],分别对应ascii码中的小写字母、大写字母、数字和不包含上述类型的其他可打印字符。进一步地,步骤s2中,所述语料乘积规则包括:2.1)、语料乘积规则由若干语料集合组成;2.2)、语料乘积规则所对应的猜测口令集合为此规则中所有语料集合的笛卡尔乘积,此规则的猜测次数为上述笛卡尔乘积集合的元素数量;2.3)、一条语料乘积规则所对应的猜测口令集合中所有口令的长度相同。进一步地,如图2所示,所述步骤s3包括以下步骤:s3.1、对训练口令集p中的一条训练口令p,穷举基于语料库γ所有能够产生p的语料乘积规则,然后在这些语料乘积规则中,选择猜测次数不大于这些语料乘积规则中最小猜测次数10倍的语料乘积规则中段数最小的语料乘积规则,作为单条训练口令p对应的语料乘积规则r;s3.2、将单条训练口令p对应的语料乘积规则r加入到口令训练集p对应的语料乘积规则与出现频度的集合t中;如果该语料乘积规则已经出现,则将其出现频度加1;否则,将此规则加入到集合t中,并设置其出现频度为1;s3.3、对训练口令集p中的每条训练口令p重复步骤s3.1和s3.2,得到最终的集合t。进一步地,所述步骤s4包括以下步骤:s4.1、将语料乘积规则的效费比定义为该语料乘积规则在训练口令集合p训练过程中出现的频度除以该语料乘积规则的猜测次数;s4.2、将训练口令集合p所生成的集合t中的语料乘积规则按照效费比从高到低进行排序,形成语料乘积规则序列r。进一步地,如图3所示,所述步骤s5包括以下步骤:s5.1、输入的口令猜测次数s;s5.2、对于按照效费比从大到小排序的语料乘积规则序列r,从序列起始处取语料乘积规则r,直至所有选取的语料乘积规则的猜测次数|r|之和不小于口令猜测次数s;s5.3、所有选取的语料乘积规则形成口令猜测规则序列rs。进一步地,如图4所示,所述步骤s6包括以下步骤:s6.1、将外部输入的测试口令集q的每条测试口令q转换为规则rq;s6.2、判断规则rq是否在总猜测次数小于s的口令猜测规则序列rs中,如果rq在rs中,则认为该测试口令q被命中,反之,则认为该测试口令q没有被命中;s6.3、累计测试口令集q中所有测试口令的命中数量;s6.4、口令猜测规则序列rs针对测试口令集q的命中率等于口令猜测规则序列rs中命中的测试口令数h除以测试口令集q的测试口令总数|q|。对于从训练口令集合p得到的规则集合t中的每个元素(r,f),其效费比定义为f/|r|,其中|r|为语料乘积规则r的猜测次数,f为规则r出现的频度。规则集合t中的语料乘积规则根据语料乘积规则的效费比从大到小排序,可以得到语料乘积规则序列r。本发明的实施需要由数据和软件两个部分组成。其中所需数据包括语料库γ,训练口令集合p,测试口令集q。所需软件包括规则生成和频度统计软件(makeregv1.0)、口令猜测规则生成软件(regav1.0)、命中率检测软件(testregv1.0)等三个部分。具体实施步骤如下:1、基于语料库γ,对训练口令集合p,通过规则生成和频度统计软件完成步骤s3和s4,将生成语料乘积规则序列r,并存储于文件f中;2、输入待口令猜测次数s和文件f到口令猜测规则生成软件中,完成步骤s5,生成最终的口令猜测规则序列rs,并存储于文件rf中;3、输入文件rf和测试口令集q到命中率检测软件中,完成步骤s6,检测q在猜测次数为s时的命中率。实施例1:口令“loverain”中包含了多个词汇,包括“love”,“lover”,“over”,“in”等。基于这些词汇,可以构成“loverain”的有向无环图,如图5所示。口令“loverain”的有向无环图中每条路径都带有权值,而每条路径的权值等于对应语料集合中词汇的数量。其中,“in”所在语料集合en0_2的词汇数量为255,“love”、“over”、“rain”所在语料集合en0_4的词汇数量为5620,“lover”所在的语料集合en0_5的词汇数量为2977,小写字母路语料集合的词汇数量为26。遍历有向无环图,得到从起点到终点的所有可能路径。每一条路径对应一条规则,由此可以得到对应路径和规则的猜测次数和段数。口令“loverain”有以下8条路径,如表1所示:表1如表1所示,猜测次数最小的路径为路径3,其猜测次数为19,737,510。猜测次数在路径3猜测次数的10倍以内的候选路径包括路径2、路径3、路径4。其中段数最低的是路径4,其段数为2,所以路4径为最佳路径。此路径为口令“loverain”的最佳分词,其对应规则[en0_4]{2}为口令“loverain”最终转化成的规则。实施例2:本实施例中,以口令集合rockyou作为训练集,以口令集合phpbb作为测试集,在猜测次数变化时,本发明对测试集的命中率如表2所示,猜测次数与命中率之间的关系如图6所示。表2猜测次数108109101010111012101310141015命中率38%52%63%72%80%86%90%94%表3给出了本发明与相关论文中的口令猜测方法比较的猜测命中率。在大多数情况下,本发明口令的命中率大部分情况都明显优于已有的实验结果,仅仅只有一个例外,即在猜测总数较小时,本发明稍弱于5阶markov过程,这是由于本发明产生的猜测空间较markov过程更大,而且覆盖了训练集中未曾出现的语料元素。表3表-3中的参考文献如下:[ur15]b.ur,s.m.segreti,l.bauer,n.christin,l.f.cranor,s.komanduri,d.kurilova,m.l.mazurek,w.melicher,andr.shay,“measuringrealworldaccuraciesandbiasesinmodelingpasswordguessability,”in24thusenixsecuritysymposium(usenixsecurity15).washington,d.c.:usenixassociation,2015,pp.463–481.;[ji17]x.h.w.h.z.l.r.b.shoulingji,shukunyang,“zero-sumpasswordcrackinggame:alarge-scaleempiricalstudyonthecrackability,correlation,andsecurityofpasswords,”ieeetransactionsondependableandsecurecomputing,vol.14,no.5,pp.550–564,oct.2017.。实施例3:设置语料库γ仅仅包含大写字母、小写、字母和数字等四种类型的语料集合,则本发明所述方法可以产生暴力猜测规则序列。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1