用于短文本意图识别的网络层结构及短文本意图识别方法与流程
本发明涉及自然语言处理技术领域,特别涉及用于短文本意图识别的网络层结构及短文本意图识别方法。
背景技术:
近年来,ai计算迅猛发展,在很多方向上都有突破,特别是最近几年神经网络的崛起、google的深度学习框架tensorflow的飞速发展,给人工智能注入新的血液,同时传统机器学习方法在自然语言处理领域的应用也显得十分乏力,而深度学习在各种自然语言处理任务上显得十分得心应手,这使我们尝试使用深度学习来处理自然语言的任务,比如意图识别。
意图识别可以转化为文本分类问题,以前处理文本分类的问题主要用传统的机器学习方法,比如svm。但是目前文本分类有一些明显的特征:数据量大,训练数据几十万甚至上千万条、维度高,每行文本的维度可能高达200-800维、对于分类速度要求高,某些场景下需要分类速度在10ms以内。传统机器学习就不太适合处理这类分类任务,而神经网络可以很好地完成这类任务。
目前,大部分的意图识别方法采用多层神经网络、lstm等网络结构,为了提高速度减少多层网络的层数,导致数据欠拟合,识别度低,虽然采用复杂的lstm识别度高,但是速度较慢,不能满足使用需求。
技术实现要素:
本发明的目的是克服上述背景技术中不足,提供用于短文本意图识别的网络层结构及短文本意图识别方法,通过设计一种结合cnn与全连接的一种深度学习网络,实现一种意图分类的方法,试验证明可达到在10毫秒以内完成意图识别的目标,且准确度保证在98%以上。
为了达到上述的技术效果,本发明采取以下技术方案:
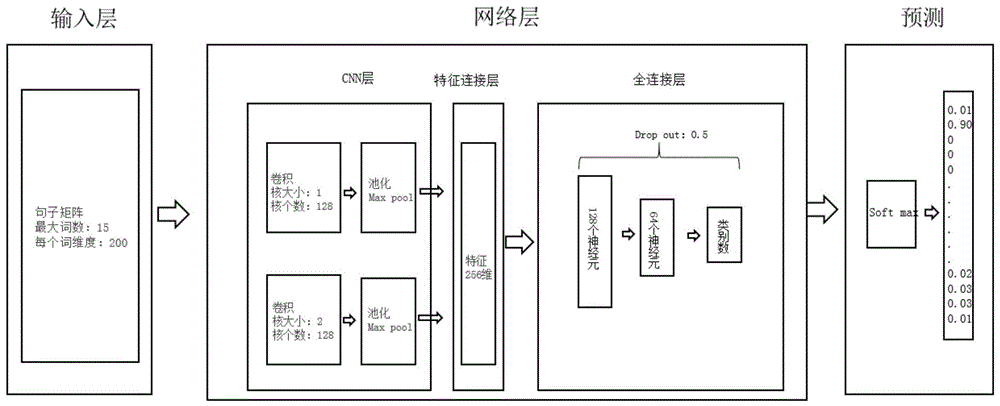
一种用于短文本意图识别的网络层结构,包括cnn层、特征连接层、全连接层,其中,所述cnn层用于对输入句矩阵通过包含n个卷积核的卷积窗口的卷积操作,然后使用最大池化操作,提取出n个特征;所述特征连接层用于在cnn层完成卷积操作后对得到的特征进行纵向叠加形成m维特征;所述全连接层采用每层神经元递减的方式搭建,使深层神经元能够代表更复杂的特征,且可减少计算量,提高计算速度,全连接层用于将特征连接层得到的m维特征的特征值作为输入,并进行计算最终输出计算结果。
进一步地,所述cnn层包括第一cnn层及第二cnn层,所述第一cnn层用于对输入句矩阵通过包含n个卷积核的卷积窗口的卷积操作,然后使用最大池化操作,提取出n个特征,所述第二cnn层用于对输入句矩阵通过包含n个卷积核的卷积窗口的卷积操作,然后使用最大池化操作,提取出n个特征。
进一步地,所述特征连接层用于在cnn层完成卷积操作后对得到两组特征进行纵向叠加形成m维特征,m=2n。
进一步地,所述全连接层包含一个输入层、一个输出层、二个隐藏层,其中,输入层维度为2n,输出层是n个分类的神经元节点,二个隐藏层分别为n个神经元和n/2个神经元。
进一步地,其特征在于,n=128。
进一步地,所述第一cnn层的卷积窗口大小为1,所述第二cnn层的卷积窗口大小为2。
同时,本发明还公开了一种短文本意图识别方法,基于上述的用于短文本意图识别的网络层结构及输入层、预测层实现,包括以下步骤:
a.输入层生成用户录入的文本的特征矩阵;
b.第一cnn层及第二cnn层分别对输入句矩阵通过包含n个卷积核的卷积窗口的卷积操作,提取出n个特征向量,然后使用最大池化操作,得到n个特征值;
c.特征连接层将各包含n个特征值的两组特征值进行纵向叠加形成1*2n个特征向量;
d.全连接层设置一个输入层、两层隐藏层、一个输出层,其中,输入层的神经元个数为2n,隐藏层神经元个数分别为n和n/2,输出层神经元个数x根据分类数确定;
e.将1*2n个特征向量作为全连接层的输入并进入两层隐藏层进行计算,两层隐藏层将计算结果输出给输出层,输出层输出x个数值;
f.预测层使用softmax函数归一化全连接层的x个输出值,得到x个对应每个分类的概率值,且所有概率值之和为1,其中,概率最大的值对应的分类即为预测分类。
进一步地,所述步骤a具体包括:
a1.通过分词工具把用户录入的句子切分为b个词;
a2.加载预训练的词向量模型得到a1中的b个词词向量,并得到b*y的特征矩阵,其中,y为每个词向量的维数。
进一步地,所述步骤a还包括步骤a3:若b小于15则在b*y的特征矩阵的基础上补充15-b行0向量,得到15*y的特征矩阵,若b大于15则截取前15行向量,得到15*y的特征矩阵。
进一步地,所述第一cnn层的卷积窗口大小为1,所述第二cnn层的卷积窗口大小为2,n=128。
本发明与现有技术相比,具有以下的有益效果:
本发明的用于短文本意图识别的网络层结构及短文本意图识别方法,相对现有技术解决了两个核心问题,即在满足分类速度的同时还提高了分类精度,其中,分类速度在长句子和短句子在分类速度上表现出了差异,虽然长句子要比短句子稍慢,但是通过验证证明总体上分类速度基本上在4-5毫秒左右,而分类准确率则通过在测试数据集上进行验证得到分类准确率高达98%以上。
附图说明
图1是本发明的一个实施例的短文本意图识别方法流程示意图。
图2是本发明的一个实施例中预测层进行训练和实际预测时的示意图。
具体实施方式
下面结合本发明的实施例对本发明作进一步的阐述和说明。
实施例:
实施例一:
一种用于短文本意图识别的网络层结构,具体分为三层:cnn层、特征连接层、全连接层。
具体的,本实施例中,cnn层又分为两个层次,分别为:第一cnn层及第二cnn层,第一cnn层用于对输入句矩阵通过包含128个卷积核的卷积窗口的卷积操作,然后使用最大池化操作,提取出128个特征,第二cnn层用于对输入句矩阵通过包含128个卷积核的卷积窗口的卷积操作,然后使用最大池化操作,提取出128个特征。
具体的,本实施例中,第一cnn层的卷积窗口大小为1,第二cnn层的卷积窗口大小为2。
特征连接层用于在第一cnn层及第二cnn层完成卷积操作后,对得到的两组特征(每组特征128个)进行纵向叠加形成256维特征并输出256各特征值。
全连接层采用每层神经元递减的方式搭建,使深层神经元能够代表更复杂的特征,且可减少计算量,提高计算速度,具体的本实施例中,全连接层包含一个输入层、一个输出层、二个隐藏层,其中,输入层维度为256(即特征连接层输出的特征值个数),输出层的神经元节点数具体根据分类数确定,如若有n个分类则输出层的神经元节点数即为n,二个隐藏层的神经元个数分别为128,64,同时,为了避免过拟合,设置dropdout为0.5。
本实施例的短文本意图识别的网络层结构在具体使用时作为意图识别系统的网络层,可结合意图识别系统的输入层及预测层一同实现意图识别。
实施例二
如图1所示,一种短文本意图识别方法,基于上述的用于短文本意图识别的网络层结构及输入层、预测层实现,包括以下步骤:
步骤1.输入层生成用户录入的文本的特征矩阵。
本实施例中,具体包括:
步骤1.1.通过分词工具把用户录入的句子切分为b个词。
如本实施例中,若用户输入的句子为“我想看刘x华的电影”,则通过分词工具对把句子切分即可具体分为四个词“我想看刘x华的电影”。
步骤1.2.加载预训练的词向量模型得到上一步的多个词的词向量,并得到b*y的特征矩阵,其中,y为每个词向量的维数。
如本实施例中,若词向量的维数是200维,则加载预训练的词向量模型即可得到4*200的特征矩阵:
我想看:[1.234,12.23,……,0.876]
刘x华:[3.124,1.332,……,2.987]
的:[1.237,5.398,……,8.566]
电影:[49.86,98.45,……,9.854]
由于上述特征矩阵不足15行,则需要再补11行0向量,得到15*200的特征矩阵如下:
我想看:[1.234,12.23,……,0.876]
刘德华:[3.124,1.332,……,2.987]
的:[1.237,5.398,……,8.566]
电影:[49.86,98.45,……,9.854]
[0,0,……,0]
……
[0,0,……,0]
步骤2.第一cnn层及第二cnn层分别对输入句矩阵通过包含n个卷积核的卷积窗口的卷积操作,提取出n个特征向量,然后使用最大池化操作,得到n个特征值,其中,第一cnn层的卷积窗口大小为1,第二cnn层的卷积窗口大小为2。
本实施例中具体为:
第一cnn层对输入句矩阵通过包含128个卷积核的卷积窗口的卷积操作,其中,每使用一种卷积核都会生成一个特征向量,因此可提取出128个特征向量,然后使用最大池化操作,得到128个特征值,第二cnn层对输入句矩阵通过包含128个卷积核的卷积窗口的卷积操作,其中,每使用一种卷积核都会生成一个特征向量,因此可提取出128个特征向量,然后使用最大池化操作,得到128个特征值。
步骤3.特征连接层将各包含128个特征值的两组特征值进行纵向叠加形成1*256个特征向量并输出至全连接层;
步骤4.全连接层设置一个输入层、两层隐藏层、一个输出层,其中,输入层的神经元个数为256,隐藏层神经元个数分别为128和64,输出层神经元个数x根据分类数确定,本实施例中共有40个分类,则输出层神经元个数为40。
具体的,输入层将特征连接层生成的1*256个特征向量作为全连接层的输入,并输入至两层隐藏层进行计算,然后将计算结果输入至输出层,输出层再输出40个数值,这40个数值作为预测层的输入。
步骤5.预测层使用softmax函数归一化全连接层的40个输出值,得到40个对应每个分类的概率值,且所有概率值之和为1,其中,概率最大的值对应的分类即为预测分类。
具体的,预测层在训练和预测的时候不同,训练的时候需要分类标签,预测的时候不需要,因此训练的时候输入样本的标签向量。由于是有监督学习,所以在训练时,需要给定一个40行的onehot标签向量,每行对应一个分类,(向量只有唯一行为1,其余行为0,比如,一个训练样本对应的分类为“视频”,“视频”分类对应的标签向量行位置为3,那么标签向量第三行的值为1,其余行均为0),训练时根据softmax函数输出的概率值与标签向量的值对比,计算误差,并反向传播误差,直到softmax函数输出的概率值与标签向量的值无限接近,就得到一个效果好预测模型。在预测时,不需要标签向量,则直接根据softmax函数输出的概率值得到分类结果,即softmax输出的概率向量的最大值所在行对应的分类即为分类结果,比如,“我想看刘x华的电影”,经过各个层的计算,最后softmax输出概率向量为[0.01,0.9,0.02……]t最大值为第二行0.9,并且我们预设第二行为“视频”,那么这次预测分类结果为“视频”,具体如2图所示。
可以理解的是,以上实施方式仅仅是为了说明本发明的原理而采用的示例性实施方式,然而本发明并不局限于此。对于本领域内的普通技术人员而言,在不脱离本发明的精神和实质的情况下,可以做出各种变型和改进,这些变型和改进也视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!