一种自下而上配电网多尺度时空负荷预测方法及系统与流程
本发明属于大数据背景下的配电网空间负荷预测领域,具体地说是一种多维数据驱动的自下而上配电网多尺度时空负荷预测方法及系统。
背景技术:
中低压配电网规划的基础是空间负荷预测,空间负荷预测结果的精确性对配电网规划方案的适用性具有关键性影响。当前应用最广泛的负荷密度指标空间负荷预测方法适用性较低,该方法实际应用时面临两个困难。
困难1为负荷密度指标的确定。在实际配电网规划中,通常以《城市电力规划规范(gb/t50293-2014)》为基础,但由于各地气候、经济发展水平、产业类型等的差异性,统一的负荷密度指标体系适用性有限,需根据当地特点针对性选取空间负荷密度指标,目前缺乏具有指导性的负荷密度差异化指标确定方法。
困难2为同时率的选取。不同负荷具有不同的峰谷时间分布,负荷密度指标法对不同性质的地块进行叠加时不能简单考虑最大负荷量,而需要考虑一定比例,称为同时率。显然不同类型用地之间具有不同的同时率,但现有规划标准没有给出同时率选取标准,规划人员大多数情况下只能通过经验进行设定,主观性太强。
现有技术的缺陷总结如下:负荷密度指标没有考虑各地在发展水平、气候等方面的差异性,地块叠加时无法科学选取同时率,导致预测结果误差较大。
技术实现要素:
针对上述现有技术存在的不足,本发明提供一种多维数据驱动的自下而上配电网多尺度时空负荷预测方法及系统,其采用数据挖掘的方法给出具有指导性的负荷密度指标体系和典型负荷曲线,再基于负荷曲线进行自下而上负荷叠加预测,以避免同时率选取的难题,提升空间负荷预测结果准确性,有利于科学指导变电站选址定容、出线安排及用户接入。
为此,本发明采用的技术方案如下:一种自下而上配电网多尺度时空负荷预测方法,其包括:
1)通过非参数核密度估计方法得到各类型地块的典型负荷密度上、下界和高中低区段典型值,提升负荷密度指标科学性;
2)采用基于db指标的自适应k-means聚类方法,从用电信息采集系统中提取各类用户典型负荷曲线,精确表征其用电特性;
3)采用自下而上地负荷叠加方法,逐级得到“地块-网格-供电区”的负荷增长时空全景图,避免同时率的选取。
本发明基于大量样本地块的负荷密度数据和典型负荷曲线,具有大数据鲁棒性优势,所述的多尺度指“地块-网格-供电区”等不同大小的空间尺度。
进一步地,所预测的区域为已开展控制性详细规划区域,土地利用性质已知。
进一步地,通过非参数核密度估计方法统计空间负荷密度典型指标,具体内容为:
基于大量的成熟地块的统计数据,建立空间负荷密度概率模型,设x1,x2,…,xn是某用地类型的n个样本的负荷密度值,负荷密度的概率密度函数为f(x),则该概率密度函数的核估计为:
式中,n为样本容量;h是带宽,充当光滑系数;k()是核函数;选取标准高斯函数为核函数,设带宽为0.5,则负荷密度的核密度估计如下所示:
得到负荷密度值的核密度估计曲线之后,为去除样本中极值数据的影响,首先从极小和极大的负荷密度数据中各剔除5%,然后将剩余范围等分处理,再从各段区间中选取极点作为该段负荷密度的典型值。
极点表示该段负荷密度在该值邻域分布最集中,因而该负荷密度最具有代表性。通过多个典型值相配合可相对全面地刻画该用地类型的空间负荷密度分布规律。
进一步地,采用db指标度量负荷曲线聚类效果,具体内容为:
通过用电信息采集系统获取大量该用地类型的用户日负荷曲线,对其进行聚类,将各类型的中心线作为该用地类型的典型负荷曲线,采用db指标确定合适的聚类类型数:
式中,ci表示第i个类型,zj是ci中的向量,ai为的聚类中心ci,p表示取zj与ai的p-范数,根据上式最终计算得到db指标。
显然si度量了ci类型内的一致程度;||ai-aj||p度量了类型ci和cj的差异程度。可见,db指标同时考虑了同类的一致性和异类的差异性,是聚类有效性的综合度量。对负荷曲线进行聚类的目的是搜索最小的db值,实现聚类效果最佳,这种搜索可以通过迭代算法进行。
进一步地,采用基于db指标的自适应聚类算法提取各类用地典型负荷曲线,具体内容为:
采用基于db指标迭代搜索k-means算法最佳聚类数,其流程包括9步:
第1步:设定k=2,输入待聚类的负荷曲线集合;
第2步:运行k-means算法;
第3步:计算当前聚类方案的db指标大小,记为db(k);
第4步:更新k=k+1;
第5步:判断是否达到最大允许聚类数目,即是否k>kmax,若是跳转至第9步,若否,进入第6步;
第6步:运行k-means算法;
第7步:计算当前聚类方案的db指标大小,记为db(k);
第8步:基于db指标判断聚类效果是否更好,即是否db(k)<db(k-1),若是回转至第4步,若否,进入第9步;
第9步:终止迭代,输出最佳聚类数k。
本发明通过聚类负荷曲线为地块峰值负荷的叠加提供参考信息,因此样本库中的负荷曲线应在区域最大负荷月中选取。考虑到当样本曲线足够多时,大数据自身会有很好的容错性。因此,没有必要指定负荷曲线选取的具体日期。
进一步地,本发明的自下而上配电网多尺度时空负荷预测方法,具体内容如下:
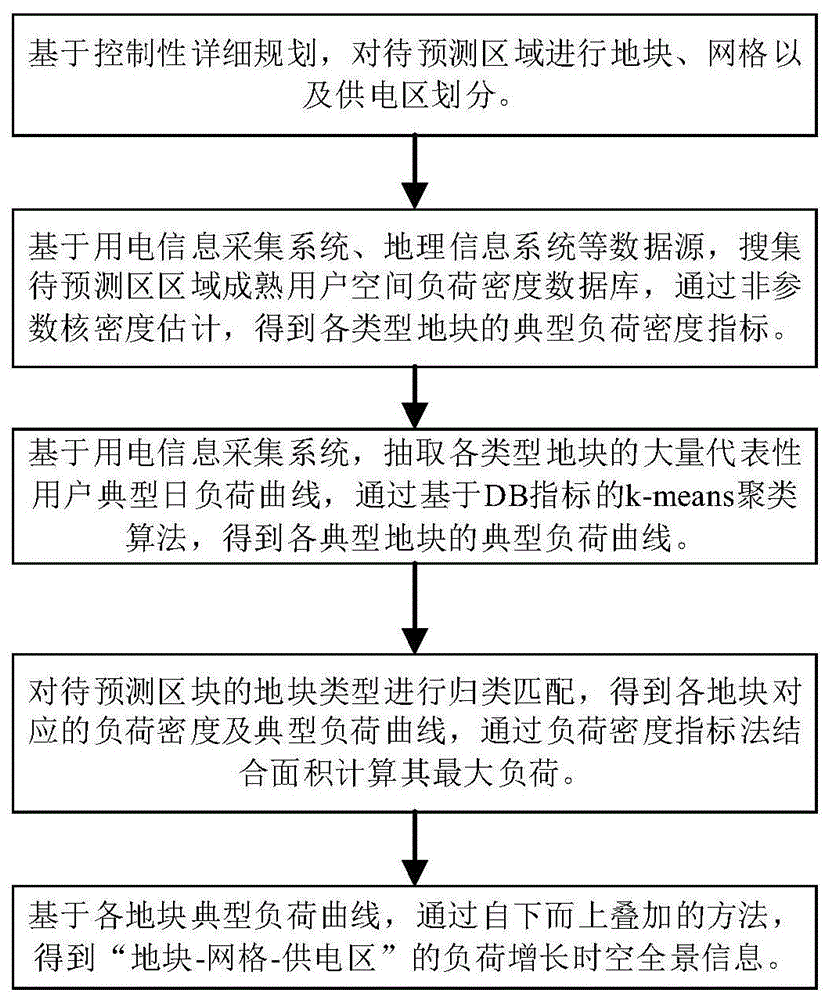
第1步:基于待预测区域控制性详细规划,以及河流和交通干道为边界,对待预测区域进行地块、网格以及供电区划分;
第2步:基于用电信息采集系统和地理信息系统,并通过互联网查询,搜集待预侧区块所在地区各类成熟用户空间负荷密度数据库,通过非参数核密度估计,得到各类型地块的典型负荷密度指标;
第3步:基于用电信息采集系统,抽取各类型地块的大量代表性用户典型日负荷曲线,通过基于db指标的k-means聚类算法,得到各典型地块的典型负荷曲线;
第4步:对待预测区块的地块类型进行归类匹配,得到各地块对应的负荷密度及典型负荷曲线,通过负荷密度指标法结合面积计算其最大负荷;
第5步:基于各地块典型负荷曲线,通过自下而上叠加的方法,得到“地块-网格-供电区”的负荷增长时空全景图。
进一步地,待预测区域的最大负荷值由以下公式计算:
式中,max为求最大值符号,n为待预测区块的功能地块数目,各地块的典型日负荷曲线包含m维负荷点,其中pij为地块i第j个负荷点的值,pi是地块i的最大负荷,由以下负荷密度指标法计算:
pi=siρi,
式中,si和ρi分别为地块i的面积和负荷密度典型值。
进一步地,所采用的k-means聚类算法基于负荷曲线距离测度,采用如下流程:
第1步:在待聚类负荷曲线数据集中任选k个初始聚类中心z1(l),z2(l)…zk(l);
第2步:计算每个负荷曲线样本到k个聚类中心曲线的距离,并按最近规则归类;若||x-zj(l)||<||x-zi(l)||,则x∈gj(l),i=1,2,…k,i≠j,其中:gj(l)为聚类中心zj(l)的样本聚类;在第l次迭代,分配所有样本x到k个聚类中心;
第3步:从第2步的计算结果计算新的聚类中心;
新的聚类中心应使准则函数的jj值达到最小:
其中:gj是第j个负荷曲线类;nj为第j个类的负荷曲线样本数;zj为第j个样本的负荷曲线聚类中心;
第4步:若新的聚类中心与前一个聚类中心相等,即:
zj(l+1)=zj(l),j=1,2,…,k;
则算法收敛,聚类结束;否则,转入第2步。
进一步地,所述的日负荷曲线全部预先经过归一化处理,具体内容为:
假设典型日负荷曲线为m维数组,则第i条负荷曲线表示为xi=(xi,1,xi,2,…,xi,m),其第j维负荷值的归一化结果为:
式中,min和max分别为取最小值和最大值运算符号。
本发明采用的另一种技术方案为:一种自下而上配电网多尺度时空负荷预测系统,其包括:
待预测区域划分单元:基于待预测区域控制性详细规划,以及河流和交通干道为边界,对待预测区域进行地块、网格以及供电区划分;
典型负荷密度指标获取单元:基于用电信息采集系统和地理信息系统,并通过互联网查询,搜集待预侧区块所在地区各类成熟用户空间负荷密度数据库,通过非参数核密度估计,得到各类型地块的典型负荷密度指标;
典型负荷曲线计算单元:基于用电信息采集系统,抽取各类型地块的大量代表性用户典型日负荷曲线,通过基于db指标的k-means聚类算法,得到各典型地块的典型负荷曲线;
最大负荷计算单元:对待预测区块的地块类型进行归类匹配,得到各地块对应的负荷密度及典型负荷曲线,通过负荷密度指标法结合面积计算其最大负荷;
负荷增长时空全景图获取单元:基于各地块典型负荷曲线,通过自下而上叠加的方法,得到“地块-网格-供电区”的负荷增长时空全景图。
本发明通过和密度估计方法给出的负荷密度指标包括上下界以及高、中、低三个典型值,有明确物理意义,其中密度上、下界给出了该区域负荷密度的可能范围,可用于负荷预测结果的判断以及校验;而低段密度典型值、中段密度典型值、高段密度典型值三项分布特征是大量统计得出的最可能负荷密度值,可直接用于配电网规划负荷标准。
本发明基于配电网网格化体系,所述的“地块-网格-供电区”空间尺度为目前我国配电网规划和管理的常用单位。其中,地块是网格化规划体系中规划强度赋值的基本单位,范围与土地利用规划、控制性详细规划中功能地块相对应,一般来说,地块在负荷量级上对应配电变压器,进行地块负荷预测,有助于确定配变容量和台数,确定开关站布点、制定用户接入方案。用电网格在负荷量级上对应中压线路级别,对应中压网架结构,进行用电网格负荷预测,有助于指导线路电力平衡,明确中压线路廊道、路径,开闭所所址位置。供电区一般在负荷量上达到高压配电网主供电源点,对应变电站电力平衡,进行供电区负荷预测有助于确定规划分区中变电站的总需求,包括变电站容量、数量,确定110kv变电站的供区范围,优化变电站站址。
本发明进行“地块-网格-供电区”体系下的自下而上空间负荷预测有助于提升配电网规划和市政规划的衔接性。
本发明具有的有益效果是:
本发明应用核密度估计方法给出了体现区域特征的负荷密度指标体系,采用基于负荷曲线的自下而上负荷叠加方法,避免了同时率选取的难题,提升了空间负荷预测结果的精度,提高了配电网规划方案的适用性。
附图说明
图1是本发明实施例2的流程图;
图2是本发明应用例中基于非参数核密度估计的负荷密度典型值提取过程示意图;
图3是本发明应用例中基于db指标的负荷曲线自适应聚类算法流程图;
图4是本发明应用例中区域典型负荷曲线提取效果图;
图5是本发明应用例中区域采用本发明基于负荷曲线自下而上叠加所得预测负荷曲线图。
具体实施方式
下面结合说明书附图和实施例对本发明作进一步说明。
实施例1
本实施例提供一种多维数据驱动的自下而上配电网多尺度时空负荷预测方法,其步骤如下:
1)首先,通过非参数核密度估计方法得到各类型地块的典型负荷密度上下界和高中低区段典型值,提升负荷密度指标科学性;
2)然后,提出基于db指标的自适应k-means聚类方法,从用电信息采集系统中提取各类用户典型负荷曲线,精确表征其用电特性;
3)最后,提出自下而上地负荷叠加方法,逐级得到“地块-网格-供电区”的负荷增长时空全景图,从而避免了同时率的选取。
所预测的区域为已开展控制性详细规划区域,土地利用性质已知。
通过非参数核密度估计方法统计空间负荷密度典型指标,具体内容为:
基于大量成熟地块的统计数据,建立空间负荷密度概率模型,设x1,x2,…,xn是某用地类型的n个样本的负荷密度值,负荷密度的概率密度函数为f(x),则该概率密度函数的核估计为:
式中,n为样本容量;h是带宽,充当光滑系数;k()是核函数;选取标准高斯函数为核函数,设带宽为0.5,则负荷密度的核密度估计如下所示:
得到负荷密度值的核密度估计曲线之后,为去除样本中极值数据的影响,首先从极小和极大的负荷密度数据中各剔除5%,然后将剩余范围等分处理,再从各段区间中选取极点作为该段负荷密度的典型值。
采用db指标度量负荷曲线聚类效果,具体内容为:
通过用电信息采集系统获取大量该用地类型的用户日负荷曲线,对其进行聚类,将各类型的中心线作为该用地类型的典型负荷曲线,采用db指标确定合适的聚类类型数:
式中,ci表示第i个类型,zj是ci中的向量,ai为的聚类中心ci,p表示取zj与ai的p-范数,根据上式最终计算得到db指标。
采用基于db指标的自适应聚类算法提取各类用地典型负荷曲线,具体内容为:
采用基于db指标迭代搜索k-means算法最佳聚类数,其流程包括9步:
第1步:设定k=2,输入待聚类的负荷曲线集合;
第2步:运行k-means算法;
第3步:计算当前聚类方案的db指标大小,记为db(k);
第4步:更新k=k+1;
第5步:判断是否达到最大允许聚类数目,即是否k>kmax,若是跳转至第9步,若否,进入第6步;
第6步:运行k-means算法;
第7步:计算当前聚类方案的db指标大小,记为db(k);
第8步:基于db指标判断聚类效果是否更好,即是否db(k)<db(k-1),若是回转至第4步,若否,进入第9步;
第9步:终止迭代,输出最佳聚类数k。
所采用的k-means聚类算法基于负荷曲线距离测度,采用如下流程:
第1步:在待聚类负荷曲线数据集中任选k个初始聚类中心z1(l),z2(l)…zk(l);
第2步:计算每个负荷曲线样本到k个聚类中心曲线的距离,并按最近规则归类;若||x-zj(l)||<||x-zi(l)||,则x∈gj(l),i=1,2,…k,i≠j,其中:gj(l)为聚类中心zj(l)的样本聚类;在第l次迭代,分配所有样本x到k个聚类中心;
第3步:从第2步的计算结果计算新的聚类中心;
新的聚类中心应使准则函数的jj值达到最小:
其中:gj是第j个负荷曲线类;nj为第j个类的负荷曲线样本数;zj为第j个样本的负荷曲线聚类中心;
第4步:若新的聚类中心与前一个聚类中心相等,即:
zj(l+1)=zj(l),j=1,2,…,k;
则算法收敛,聚类结束;否则,转入第2步。
实施例2
本实施例提供一种多维数据驱动的自下而上配电网多尺度时空负荷预测方法,如图1所示,其步骤如下:
第1步:基于待预测区域控制性详细规划,以及河流和交通干道为边界,对待预测区域进行地块、网格以及供电区划分;
第2步:基于用电信息采集系统和地理信息系统,并通过互联网查询,搜集待预侧区块所在地区各类成熟用户空间负荷密度数据库,通过非参数核密度估计,得到各类型地块的典型负荷密度指标;
第3步:基于用电信息采集系统,抽取各类型地块的大量代表性用户典型日负荷曲线,通过基于db指标的k-means聚类算法,得到各典型地块的典型负荷曲线;
第4步:对待预测区块的地块类型进行归类匹配,得到各地块对应的负荷密度及典型负荷曲线,通过负荷密度指标法结合面积计算其最大负荷;
第5步:基于各地块典型负荷曲线,通过自下而上叠加的方法,得到“地块-网格-供电区”的负荷增长时空全景图。
所预测的区域为已开展控制性详细规划区域,土地利用性质已知。
通过非参数核密度估计方法统计空间负荷密度典型指标,具体内容为:
基于大量成熟地块的统计数据,建立空间负荷密度概率模型,设x1,x2,…,xn是某用地类型的n个样本的负荷密度值,负荷密度的概率密度函数为f(x),则该概率密度函数的核估计为:
式中,n为样本容量;h是带宽,充当光滑系数;k()是核函数;选取标准高斯函数为核函数,设带宽为0.5,则负荷密度的核密度估计如下所示:
得到负荷密度值的核密度估计曲线之后,为去除样本中极值数据的影响,首先从极小和极大的负荷密度数据中各剔除5%,然后将剩余范围等分处理,再从各段区间中选取极点作为该段负荷密度的典型值。
采用db指标度量负荷曲线聚类效果,具体内容为:
通过用电信息采集系统获取大量该用地类型的用户日负荷曲线,对其进行聚类,将各类型的中心线作为该用地类型的典型负荷曲线,采用db指标确定合适的聚类类型数:
式中,ci表示第i个类型,zj是ci中的向量,ai为的聚类中心ci,p表示取zj与ai的p-范数,根据上式最终计算得到db指标。
采用基于db指标的自适应聚类算法提取各类用地典型负荷曲线,具体内容为:
采用基于db指标迭代搜索k-means算法最佳聚类数,其流程包括9步:
第1步:设定k=2,输入待聚类的负荷曲线集合;
第2步:运行k-means算法;
第3步:计算当前聚类方案的db指标大小,记为db(k);
第4步:更新k=k+1;
第5步:判断是否达到最大允许聚类数目,即是否k>kmax,若是跳转至第9步,若否,进入第6步;
第6步:运行k-means算法;
第7步:计算当前聚类方案的db指标大小,记为db(k);
第8步:基于db指标判断聚类效果是否更好,即是否db(k)<db(k-1),若是回转至第4步,若否,进入第9步;
第9步:终止迭代,输出最佳聚类数k。
待预测区域的最大负荷值由以下公式计算:
式中,max为求最大值符号,n为待预测区块的功能地块数目,各地块的典型日负荷曲线包含m维负荷点,其中pij为地块i第j个负荷点的值,pi是地块i的最大负荷,由以下负荷密度指标法计算:
pi=siρi,
式中,si和ρi分别为地块i的面积和负荷密度典型值。
所采用的k-means聚类算法基于负荷曲线距离测度,采用如下流程:
第1步:在待聚类负荷曲线数据集中任选k个初始聚类中心z1(l),z2(l)…zk(l);
第2步:计算每个负荷曲线样本到k个聚类中心曲线的距离,并按最近规则归类;若||x-zj(l)||<||x-zi(l)||,则x∈gj(l),i=1,2,…k,i≠j,其中:gj(l)为聚类中心zj(l)的样本聚类;在第l次迭代,分配所有样本x到k个聚类中心;
第3步:从第2步的计算结果计算新的聚类中心;
新的聚类中心应使准则函数的jj值达到最小:
其中:gj是第j个负荷曲线类;nj为第j个类的负荷曲线样本数;zj为第j个样本的负荷曲线聚类中心;
第4步:若新的聚类中心与前一个聚类中心相等,即:
zj(l+1)=zj(l),j=1,2,…,k;
则算法收敛,聚类结束;否则,转入第2步。
所述的日负荷曲线全部预先经过归一化处理,具体内容为:
假设典型日负荷曲线为m维数组,则第i条负荷曲线表示为xi=(xi,1,xi,2,…,xi,m),其第j维负荷值的归一化结果为:
式中,min和max分别为取最小值和最大值运算符号。
实施例3
本实施例提供一种自下而上配电网多尺度时空负荷预测系统,其包括:
待预测区域划分单元:基于待预测区域控制性详细规划,以及河流和交通干道为边界,对待预测区域进行地块、网格以及供电区划分;
典型负荷密度指标获取单元:基于用电信息采集系统和地理信息系统,并通过互联网查询,搜集待预侧区块所在地区各类成熟用户空间负荷密度数据库,通过非参数核密度估计,得到各类型地块的典型负荷密度指标;
典型负荷曲线计算单元:基于用电信息采集系统,抽取各类型地块的大量代表性用户典型日负荷曲线,通过基于db指标的k-means聚类算法,得到各典型地块的典型负荷曲线;
最大负荷计算单元:对待预测区块的地块类型进行归类匹配,得到各地块对应的负荷密度及典型负荷曲线,通过负荷密度指标法结合面积计算其最大负荷;
负荷增长时空全景图获取单元:基于各地块典型负荷曲线,通过自下而上叠加的方法,得到“地块-网格-供电区”的负荷增长时空全景图。
所预测的区域为已开展控制性详细规划区域,土地利用性质已知。
通过非参数核密度估计方法统计空间负荷密度典型指标,具体内容为:
基于大量成熟地块的统计数据,建立空间负荷密度概率模型,设x1,x2,…,xn是某用地类型的n个样本的负荷密度值,负荷密度的概率密度函数为f(x),则该概率密度函数的核估计为:
式中,n为样本容量;h是带宽,充当光滑系数;k()是核函数;选取标准高斯函数为核函数,设带宽为0.5,则负荷密度的核密度估计如下所示:
得到负荷密度值的核密度估计曲线之后,为去除样本中极值数据的影响,首先从极小和极大的负荷密度数据中各剔除5%,然后将剩余范围等分处理,再从各段区间中选取极点作为该段负荷密度的典型值。
采用db指标度量负荷曲线聚类效果,具体内容为:
通过用电信息采集系统获取大量该用地类型的用户日负荷曲线,对其进行聚类,将各类型的中心线作为该用地类型的典型负荷曲线,采用db指标确定合适的聚类类型数:
式中,ci表示第i个类型,zj是ci中的向量,ai为的聚类中心ci,p表示取zj与ai的p-范数,根据上式最终计算得到db指标。
采用基于db指标的自适应聚类算法提取各类用地典型负荷曲线,具体内容为:
采用基于db指标迭代搜索k-means算法最佳聚类数,其流程包括9步:
第1步:设定k=2,输入待聚类的负荷曲线集合;
第2步:运行k-means算法;
第3步:计算当前聚类方案的db指标大小,记为db(k);
第4步:更新k=k+1;
第5步:判断是否达到最大允许聚类数目,即是否k>kmax,若是跳转至第9步,若否,进入第6步;
第6步:运行k-means算法;
第7步:计算当前聚类方案的db指标大小,记为db(k);
第8步:基于db指标判断聚类效果是否更好,即是否db(k)<db(k-1),若是回转至第4步,若否,进入第9步;
第9步:终止迭代,输出最佳聚类数k。
待预测区域的最大负荷值由以下公式计算:
式中,max为求最大值符号,n为待预测区块的功能地块数目,各地块的典型日负荷曲线包含m维负荷点,其中pij为地块i第j个负荷点的值,pi是地块i的最大负荷,由以下负荷密度指标法计算:
pi=siρi,
式中,si和ρi分别为地块i的面积和负荷密度典型值。
所采用的k-means聚类算法基于负荷曲线距离测度,采用如下流程:
第1步:在待聚类负荷曲线数据集中任选k个初始聚类中心z1(l),z2(l)…zk(l);
第2步:计算每个负荷曲线样本到k个聚类中心曲线的距离,并按最近规则归类;若||x-zj(l)||<||x-zi(l)||,则x∈gj(l),i=1,2,…k,i≠j,其中:gj(l)为聚类中心zj(l)的样本聚类;在第l次迭代,分配所有样本x到k个聚类中心;
第3步:从第2步的计算结果计算新的聚类中心;
新的聚类中心应使准则函数的jj值达到最小:
其中:gj是第j个负荷曲线类;nj为第j个类的负荷曲线样本数;zj为第j个样本的负荷曲线聚类中心;
第4步:若新的聚类中心与前一个聚类中心相等,即:
zj(l+1)=zj(l),j=1,2,…,k;
则算法收敛,聚类结束;否则,转入第2步。
所述的日负荷曲线全部预先经过归一化处理,具体内容为:
假设典型日负荷曲线为m维数组,则第i条负荷曲线表示为xi=(xi,1,xi,2,…,xi,m),其第j维负荷值的归一化结果为:
式中,min和max分别为取最小值和最大值运算符号。
应用例
按照本发明实施例2的具体实施方案,以具有控制性详细规划的区块作为对象,选取浙江海宁地区经编产业园区为例进行本发明方法验证,其实施过程如下:
1)首先,通过图2所示的非参数核密度估计方法得到各类型地块的典型负荷密度上下界和高中低区段典型值,结果如表1所示。
表1海宁各类用地负荷密度典型分布特征提取结果
2)然后,采用图3所示基于db指标的自适应k-means聚类方法,从用电信息采集系统中提取各类用户典型负荷曲线,精确表征其用电特性,结果如图4所示;
得到待预测区域地块的负荷密度典型指标以及典型负荷曲线之后,采用基于负荷曲线的自下而上叠加方法,得到整个预测园区的负荷值为161.89mw,叠加所得的园区负荷曲线如图5所示。
最后,还需要说明的是,对所公开的实施例的上述说明,使本领域技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
- 还没有人留言评论。精彩留言会获得点赞!