一种面向视频的非均匀风格迁移方法与流程
本发明属于计算机视频技术领域,涉及针对视频的风格迁移方法,具体为一种面向视频的非均匀风格迁移方法。
背景技术:
视频风格迁移是指参照给定图像的风格,对一个视频进行渲染,使得生成与给定图风格一致的风格化视频。其中,被风格化的视频称为内容视频,作为风格的图像称为风格图像,风格迁移生成的结果称为风格化视频。视频风格迁移可以帮助人们轻松的编辑视频,取得特定效果的编辑结果。
传统的视频风格迁移方法是对视频的每一帧单独进行风格化,再将所有帧的风格化结果合并成视频。这种做法效率通常不高,每个视频帧的处理通常需要几十秒;且由于各个视频帧的风格化是独立的,导致每帧的风格化结果一致性较差,生成的风格化视频会存在明显的闪烁(参考文献1、4)。针对风格化效率低下的问题,一些学者提出了近实时的视频风格化方法,极大地提升了风格化速度(参考文献3、5);针对风格化视频闪烁的问题,一些学者提出了光流约束的方法,可以保证相邻帧之间的相同区域有着相似的风格化结果(参考文献2、6)。
但是,视频风格迁移中的另一个关键问题却始终没有得到关注,即如何平衡视频内容保持程度和风格渲染程度。现在的视频风格化方法对全图均使用相同的参数设置进行风格化,易使结果过度风格化或者风格化不足,如图2所示,图2(a)为原视频的视频帧取样,图2(b)显示了过度风格化结果,图2(c)显示了风格化不足的结果,图2(d)为期待的风格化结果,即风格化结果中难以辨别原视频的内容或者难以感受到风格的影响。很多情况下,难以选择一个合适的全局参数实现风格化,都不可避免的会过度风格化或风格化不足。
本发明所涉及的面向视频的非均匀风格迁移方法,提供了一种针对过度风格化或者风格化不足问题的解决方案,实现了在视频中对不同区域采用不同的风格化程度,生成非均匀的风格迁移结果。
技术实现要素:
本发明要解决的问题是:解决视频风格迁移过程中可能产生的过度风格化或风格化不足的问题,目的是平衡风格化视频的内容保持程度和风格渲染程度。
本发明的技术方案为:一种面向视频的非均匀风格迁移方法,在视频中,对视频的不同区域采用不同的风格化,生成非均匀的风格迁移结果。
具体的,对视频帧的不同区域设定不同的风格化程度设定,对视频帧计算风格迁移中的内容损失和风格损失,并对相邻视频帧的风格化结果计算时间一致性损失,最小化总损失,对视频失生成非均匀的风格迁移结果。
作为优选方式,本发明包括以下步骤:
1)对于待风格化的视频,采用人工或者自动的方式,为所有视频帧上各个像素区域设定风格化程度;
2)对于视频的某个视频帧,将其表示为一层或多层特征图,同时采用相同的方法将风格图像表示为一层或多层特征图,计算对应层的特征图在风格迁移中的内容损失和风格损失;
3)对照相邻视频帧的风格化结果,计算时间一致性损失;
4)将内容损失、风格损失和时间一致性损失相融合,计算风格迁移中的总损失;
5)最小化风格迁移总损失函数,生成风格迁移结果。
本发明的有益效果是:提供了一种解决视频风格迁移中过度风格化或风格化不足问题的方案,同时保证对视频风格化的速度和稳定性,实现了在突出部分区域内容的同时强烈渲染其它区域的风格,在风格化的过程中更好的平衡风格化视频的内容保持程度和风格渲染程度。本发明方法具有良好的广泛性与实用性。
附图说明
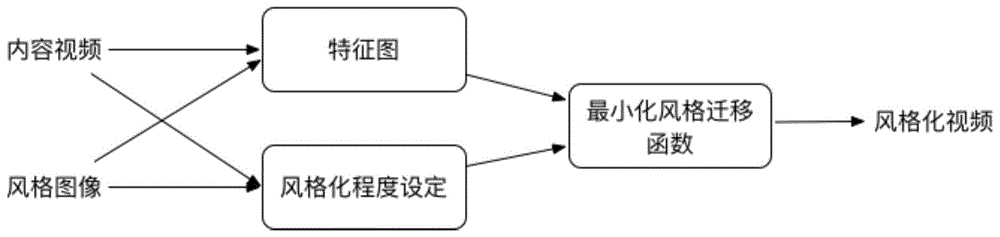
图1为本发明的实施流程。
图2为过度风格化和风格化不足效果展示。
图3为采用人工标注方式来设定风格化程度时,本发明结果与现有代表性方法结果的比较示例。
图4为采用自动检测显著性方式来设定风格化程度时,本发明结果与现有代表性方法结果的比较示例。
图5为采用自动检测运动区域方式来设定风格化程度时,本发明结果与现有代表性方法结果的比较示例。
具体实施方式
本发明提出了一种面向视频的实时非均匀风格迁移方法,对视频的不同区域采用不同的风格化,如图1所示,本发明对视频帧的不同区域设定不同的风格化程度设定,对视频帧计算风格迁移中的内容损失和风格损失,并对相邻视频帧的风格化结果计算时间一致性损失,最小化总损失,对视频失生成非均匀的风格迁移结果。
下面通过一个优选的具体实施方式来说明本发明的实施。
本发明实施例具体包括以下步骤:
1)对于输入的视频,采用人工或者自动的方式,为所有视频帧上各个像素设定风格化程度。本发明在具体实施中采用了以下3种代表性的风格化程度设定方法:
1.1)采用人工标注的方式:在输入视频中每隔30帧取出一张关键帧,人工标注这些视频帧中不同区域标注等级,等级取值为1到5,每个标注的区域内所有像素的等级取值与所属区域的等级取值相同;利用光流建立图像之间像素映射关系,生成其余视频帧中各个像素的等级取值;将第t帧中位置(i,j)的像素
1.2)采用自动求取显著区域的方式:自动求取各个像素的显著性,将第t帧上像素
1.3)采用自动求取运动区域的方式:自动检测视频中的运动区域,将第t帧的运动区域内的像素的初始风格化程度
2)对于输入的某个视频帧,将其表示为一层或多层特征图,同时采用相同的方法将风格图像表示为一层或多层特征图,计算风格迁移中的内容损失和风格损失:
2.1)将视频帧、风格图像和前一帧风格化结果分别作为卷积神经网络的输入,其中对于视频第一帧,使用随机生成的初始化图像作为风格化图像的初始值,得到其前一帧风格化结果。使用vgg-19神经网络中relu1_1,relu2_1,relu3_1,relu4_1四个卷积层提取特征图;
2.2)对设定的风格化程度,在卷积层relu1_1,relu2_1,relu3_1,relu4_1每层上分别调整其大小至内容视频帧在对应卷积层的特征图的宽高,形成四个新的二维矩阵。每层分别对四个二维矩阵进行复制,累叠,产生与内容视频帧图像在对应卷积层的特征图相同个数的同个数新矩阵,生成四组新矩阵,每组分别将该组新矩阵累叠合成三维显著区域矩阵,产生四个三维显著区域矩阵,分别对应着relu1_1,relu2_1,relu3_1,relu4_1。
2.3)计算风格迁移中的内容损失和风格损失如下:
其中,fl、al、xl分别是内容视频帧、风格图像、风格化视频帧的第l层特征图,ml×nl表示特征图在第l层的大小,ωl是由内容视频帧的各个像素的风格化程度组成的矩阵调整大小后在第l层上的结果,即前述的三维显著区域矩阵,所述调整指将风格化程度大小调整至第l层的特征图的宽高,g(·)表示基于grammatrix的特征相关性,
3)对照相邻视频帧的风格化结果,计算时间一致性损失如下:
其中,h表示输入的视频帧中既不属于非遮挡地区,也不属于运动边界的像素集合,非遮挡区域以及运动边界的识别可以参考文献2,pij表示h中的像素,xij表示pij的风格化结果,
4)将内容损失、风格损失和时间一致损失相融合,计算风格迁移中的总损失:
ltotal=αlcontent+βlstyle+rltemporal
其中,α,β,γ分别是对应内容损失、风格损失和一致性损失的权重,默认取值为1,5,20。
5)最小化风格迁移总损失函数,生成风格迁移结果。
本发明实施在从互联网搜集的视频集上,与现有代表性的方法进行了比较。本发明采用了几种代表性的风格化程度设定方法。图3所示为采用人工标注方式来设定风格化程度时,本发明结果与现有代表性方法结果的比较示例;图4所示为采用自动检测显著性方式来设定风格化程度时,本发明结果与现有代表性方法结果的比较示例;图5为采用自动检测运动区域方式来设定风格化程度时,本发明结果与现有代表性方法结果的比较示例。在图3-5中,(a)为风格图像,(b)为内容图像,(e)为本发明结果,(c)-(d)显示了参与比较的代表性方法的结果,包括:gatys方法(参考文献1),ruder方法(参考文献2)。实验结果表明,gatys方法生成的风格化视频会存在明显的闪烁,ruder方法存在过度风格化或者风格化不足的问题。本发明生成的风格化视频平衡了视频内容保存与风格样式呈现,例如图3-5的(d)可见本发明方法能够很好的保留视频中的主体内容,而只将环境因素进行风格化,帮助人们在享受图像风格化的同时理解图像内容;同时,本发明生成的风格化视频也具有较高的一致性,相邻帧之间的相同区域有着相似的风格化结果。
参考文献:
1.leona.gatys,alexanders.ecker,andmatthiasbethge.imagestyletransferusingconvolutionalneuralnetworks.ieeeinternationalconferenceoncomputervisionandpatternrecognition,2414–2423,2016.
2.manuelruder,alexeydosovitskiy,andthomasbrox.artisticstyletransferforvideos.germanconferenceonpatternrecognition,26–36,2016.
3.justinjohnson,alexandrealahi,andlifei-fei.perceptuallossesforreal-timestyletransferandsuper-resolution.europeanconferenceoncomputervision,2016.
4.xiaochangliu,mingmingcheng,yukunlai,andpaullrosin.depth-awareneuralstyletransfer.symposiumonnon-photorealisticanimationandrendering,2017.
5.dongdongchen,luyuan,jingliao,nenghaiyu,andganghua.stylebank:anexplicitrepresentationforneuralimagestyletransfer.ieeeinternationalconferenceoncomputervisionandpatternrecognition,2017
6.haozhihuang,haowang,wenhanluo,linma,wenhaojiang,xiaolongzhu,zhifengli,andweiliu.real-timeneuralstyletransferforvideos.ieeeinternationalconferenceoncomputervisionandpatternrecognition,2017.
- 还没有人留言评论。精彩留言会获得点赞!