一种基于强化学习的导航滤波器参数优化方法与流程
本发明涉及一种基于强化学习的导航滤波器参数优化方法,属于卫星自主导航技术领域。
背景技术:
基于卡尔曼滤波理论设计的传统导航滤波器在卫星自主导航技术领域得到广泛应用。众所周知,传统导航滤波器的设计依赖已知的系统噪声方差和测量噪声方差。但是,在解决实际工程问题的过程中,往往会遇到噪声方差存在不确定性的情况。举例来说,在基于星间相对测量的星座卫星自主导航系统中,导航敏感器在轨测量误差特性会受到观测平台姿态抖动、太阳光照条件和空间热环境等因素的影响,考虑在地面试验室模拟空间应用环境的局限性,导航敏感器在实际应用环境中的测量误差特性可能不同于试验室测试的情况。对于系统噪声和测量噪声统计特性的不确定性,基于卡尔曼滤波理论设计的传统导航滤波器不具备自适应能力。在实际噪声方差偏离其标称值的情况下,会导致滤波器性能下降。因此,需要有针对性地改进滤波器的设计,以提升导航系统的性能。
针对噪声统计特性不确定性的影响,以往研究中已给出多种策略,主要目的是增强滤波器的自适应能力,其中,具有噪声方差在线估计能力的自适应滤波器得到广泛重视。针对带有系统噪声或测量噪声统计特性不确定性的系统,已提出自适应卡尔曼滤波器(adaptivekalmanfilter/akf)等多种算法。自适应滤波器的问题在于,对于噪声方差存在不确定性的情况,受噪声方差估计与滤波估计误差的耦合影响,使得滤波器的整体性能得不到保证。举例来说,对于所研究的星座卫星自主导航系统,在同时估计噪声方差和卫星位置、速度时,往往会出现自适应卡尔曼滤波器估计精度不及传统卡尔曼滤波器的情况。
技术实现要素:
本发明的技术解决问题是:针对模型中的噪声方差不确定性导致滤波器估计误差增大的问题,提出一种基于强化学习的导航滤波器参数优化方法。该方法能够根据基准滤波器和搜索滤波器的测量残差识别导航敏感器测量误差增大的情况,与实际应用环境进行交互并作出调整,通过学习得到导航滤波器中噪声方差阵的取值,从而实现对不同导航敏感器测量信息的优化处理,增强星座卫星自主导航系统应对噪声方差不确定性影响的能力。
本发明的技术解决方案是:
一种基于强化学习的导航滤波器参数优化方法,步骤如下:
(1)对基准滤波器、搜索滤波器和导航滤波器进行初始化,为每个滤波器分配初始滤波估计值及相应的估计误差方差阵,根据先验知识设置基准滤波器中的系统噪声方差
(2)基于不同的系统噪声方差和测量噪声方差组合,对强化学习中的状态集s和相应的动作集a进行初始化;
(3)对于状态集s和动作集a中的各个元素,设置状态动作值函数、状态值函数和奖赏初始值,随机选择状态s∈s,作为状态的初始值;
(4)基于强化学习中的∈贪心策略,根据状态动作值函数选择动作a∈a,相应地,状态由s转移到s′,对应搜索滤波器中系统噪声方差
(5)根据步骤(1)得到的
(6)根据步骤(4)得到的
(7)根据步骤(5)得到的基准滤波器的测量残差和步骤(6)得到的搜索滤波器的测量残差计算奖赏;
(8)根据步骤(4)得到的
(9)根据步骤(7)得到的奖赏,利用强化学习中的时序差分方法更新状态动作值函数,对状态值函数和奖赏进行重置;
(10)利用步骤(5)得到的基准滤波器的滤波估计值和估计误差方差阵,对搜索滤波器的滤波估计值和估计误差方差阵进行重置;
(11)将步骤(4)到步骤(10)进行重复迭代,获得作为导航滤波器设计参数的系统噪声方差
进一步的,所述步骤(1)中,对基准滤波器、搜索滤波器和导航滤波器进行初始化的方法为:
其中,
进一步的,所述步骤(2)中,对强化学习中的状态集s和相应的动作集a进行初始化的方法为:状态集s中的各个元素为不同系统噪声方差和测量噪声方差的组合,动作集中a的各个元素为状态转移的动作,即从选择某一组系统噪声方差和测量噪声方差转向选择另外一组系统噪声方差和测量噪声方差。
进一步的,所述步骤(3)中,设置状态动作值函数、状态值函数和奖赏初始值的方法为:对于任何状态s∈s和动作a∈a,设置
q(s,a)←0,v(s)←0,r←0
其中,q(s,a)表示状态动作值函数,v(s)表示状态值函数,r表示奖赏。
进一步的,所述步骤(4)中,根据状态动作值函数选择动作的方法为:
a←greedy(a,q(s,a),s,∈)
其中,函数greedy(a,q(s,a),s,∈)表示∈贪心策略,即以∈的概率随机选择在动作集a中选择动作,以1-∈的概率选择使状态动作值函数q(s,a)最大的动作,∈∈(0,1)为事先设定的随机动作选择概率。
进一步的,所述步骤(5)中,通过基准滤波器进行递推解算的方法为:
其中,
进一步的,所述步骤(6)中,通过搜索滤波器进行递推解算的方法为:
其中,
进一步的,所述步骤(7)中,根据测量残差计算奖赏的方法为:
进一步的,所述步骤(8)中,通过导航滤波器进行递推解算的方法为:
其中,
进一步的,所述步骤(9)中,利用时序差分方法更新状态动作值函数的方法为:
q(s,a)←q(s,a)+α[r+γv(s′)-q(s,a)]
其中,α∈(0,1)为事先设定的学习速率,γ∈(0,1)为事先设定的折扣因子,对状态值函数和奖赏进行重置的方法为:
v(s)←maxaq(s,a)
s←s′
r←0
其中,符号maxaq(s,a)表示对于给定的状态s,状态动作值函数q(s,a)的最大值。
进一步的,所述步骤(10)中,对搜索滤波器的滤波估计值和估计误差方差阵进行重置的方法为:
本发明与现有技术相比的有益效果是:
本发明提出一种基于强化学习的导航滤波器参数优化方法,在模型中的系统噪声方差和测量噪声方差存在不确定性的情况下,将强化学习方法用于导航滤波器的优化设计,通过与应用环境的交互更新状态动作值函数,根据状态动作值函数自适应地调整导航滤波器中的系统噪声方差和测量噪声方差,从而提升导航系统对应用环境的适应性,改善导航滤波器的性能。
附图说明
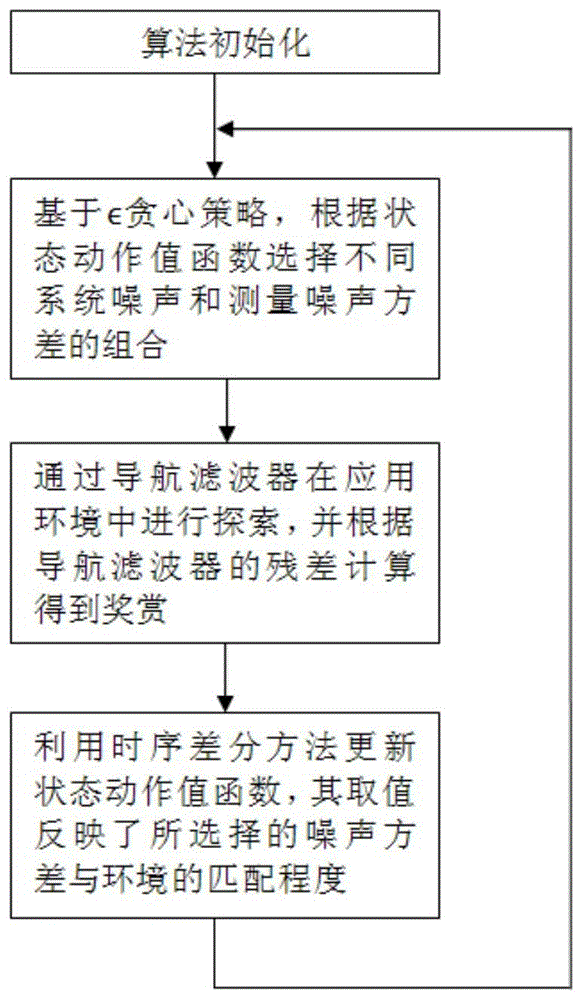
图1为本发明流程图;
图2为用于表述不同系统噪声方差和测量噪声方差组合的状态集示意图;
图3为星座卫星自主导航系统示意图;
图4为本发明所提方法(rlkf)与传统卡尔曼滤波(kf)和自适应卡尔曼滤波(akf)的仿真精度对比曲线示意图。
具体实施方式
下面结合附图对本发明的具体实施方式进行进一步的详细描述。
在作为导航滤波器参数的系统噪声方差和测量噪声方差存在不确定性的情况下,会导致基于传统卡尔曼滤波理论设计的导航滤波器性能下降;针对上述问题,充分发挥强化学习方法在未知环境探索和复杂问题决策方面的优势,提出一种基于强化学习的导航滤波器参数优化方法,首先,基于∈贪心策略,根据状态动作值函数选择不同系统噪声和测量噪声方差的组合;同时,通过导航滤波器在应用环境中进行探索,并根据导航滤波器的测量残差计算得到奖赏;进而,根据计算得到的奖赏,利用时序差分方法更新状态动作值函数,其取值反映了所选择的噪声方差与实际应用环境的匹配程度;随着导航滤波过程的进行,通过迭代计算,能够以较大的概率选择与实际应用环境相匹配的噪声方差,从而实现自适应地调整导航滤波器中系统噪声方差和测量噪声方差的目的。所提方法能够增强导航滤波器克服系统噪声和测量噪声方差不确定性影响的能力,改善卫星自主导航精度。
如图1所示,本发明提出一种基于强化学习的导航滤波器参数优化方法,步骤如下:
(1)对基准滤波器、搜索滤波器和导航滤波器进行初始化,为每个滤波器分配初始滤波估计值及相应的估计误差方差阵,根据先验知识设置基准滤波器系统噪声方差
其中,
(2)基于不同的系统噪声方差和测量噪声方差组合,对强化学习中的状态集s和相应的动作集a进行初始化;对强化学习中的状态集s和相应的动作集a进行初始化的方法为:状态集s中的各个元素为不同系统噪声方差和测量噪声方差的组合(实际上包含基准滤波器、搜索滤波器和导航滤波器三种滤波器各自的系统噪声方差和测量噪声方差),动作集中a的各个元素为状态转移的动作,即从选择某一组系统噪声方差和测量噪声方差转向选择另外一组系统噪声方差和测量噪声方差。用于表述不同系统噪声方差和测量噪声方差组合的状态集示意图如图2所示,图中各个网格表示状态集中的各个元素,共包含m×n个元素,在不同网格中系统噪声方差和测量噪声方差的取值不同,网格中的箭头表示状态转移的方向,即可选择的动作。
(3)对于状态集s和动作集a中的各个元素,设置状态动作值函数、状态值函数和奖赏初始值,随机选择状态s∈s,作为状态的初始值;设置状态动作值函数、状态值函数和奖赏初始值的方法为:对于任何状态s∈s和动作a∈a,设置
q(s,a)←0,v(s)←0,r←0
其中,q(s,a)表示状态动作值函数,v(s)表示状态值函数,r表示奖赏。
(4)基于强化学习中的∈贪心策略,根据状态动作值函数选择动作a∈a,相应地,状态由s转移到s′,对应搜索滤波器中系统噪声方差
a←greedy(a,q(s,a),s,∈)
其中,函数greedy(a,q(s,a),s,∈)表示∈贪心策略,即以∈的概率随机选择在动作集a中选择动作,以1∈的概率选择使状态动作值函数q(s,a)最大的动作,∈∈(0,1)为事先设定的随机动作选择概率。
(5)根据步骤(1)得到的
其中,
(6)根据步骤(4)得到的
其中,
(7)根据步骤(5)得到的基准滤波器的测量残差和步骤(6)得到的搜索滤波器的测量残差计算奖赏;根据测量残差计算奖赏的方法为:
(8)根据步骤(4)得到的
其中,
(9)根据步骤(7)得到的奖赏,利用强化学习中的时序差分方法更新状态动作值函数,对状态值函数和奖赏进行重置;利用时序差分方法更新状态动作值函数的方法为:
q(s,a)←q(s,a)+α[r+γv(s′)-q(s,a)]
其中,α∈(0,1)为事先设定的学习速率,γ∈(0,1)为事先设定的折扣因子,对状态值函数和奖赏进行重置的方法为:
v(s)←maxaq(s,a)
s←s′
r←0
其中,符号maxaq(s,a)表示对于给定的状态s,状态动作值函数q(s,a)的最大值。
(10)利用步骤(5)得到的基准滤波器的滤波估计值和估计误差方差阵,对搜索滤波器的滤波估计值和估计误差方差阵进行重置;对搜索滤波器的滤波估计值和估计误差方差阵进行重置的方法为:
(11)将步骤(4)到步骤(10)进行重复迭代,获得的
本发明给出如下实施例:
以在地球轨道上飞行的3颗星座卫星自主导航为例,通过仿真实例验证本发明所述方法的有效性。星座卫星自主导航系统示意图如图3所示,通过导航敏感器测量得到星座卫星之间的相对位置矢量,通过导航滤波器处理导航敏感器测量信息,对星座中三颗卫星的位置和速度进行估计。
设3颗星座卫星的轨道半长轴为27900km,轨道倾角为55°,升交点赤经分别为0°、120°和240°。假设用于星间相对位置测量的导航敏感器测量精度标称值为50m,数据更新率为0.1hz。导航敏感器信号受到干扰的情况下,会导致测量误差方差增大。在传统卡尔曼滤波器中,系统噪声方差和测量噪声方差设为
其中,
相对于传统卡尔曼滤波(kf)算法,本发明所提方法的主要优势体现在对不同应用环境的自适应能力,有助于解决滤波器性能受噪声统计特性不确定性影响的问题;相对于自适应卡尔曼滤波(akf)等算法,所提方法的主要优势是能够避免传统akf算法同时对噪声方差和卫星位置进行估计造成的误差耦合问题。针对星座卫星自主导航系统开展仿真研究,在测量噪声方差不同的情况下,统计导航滤波器的位置估计误差均方根。本发明所提方法(rlkf)与传统卡尔曼滤波(kf)和自适应卡尔曼滤波(akf)的仿真精度对比曲线如图4所示。
图4中横坐标表示相对于标称值,测量噪声标准差放大的倍数,其数值越大,则表示实际系统与滤波模型之间的差异越大,纵坐标表示星座中第1颗卫星位置估计误差的均方根统计值,单位为m,图中符号kf、akf和rlkf分别表示卡尔曼滤波器、自适应卡尔曼滤波器和本发明提出的强化学习卡尔曼滤波器。
从图4中可以明显看出,采用本发明所提方法进行星座卫星自主导航,能够获得优于传统kf和akf的定位精度,测量噪声方差的标称值与实际值之间的差异越大,则本发明所提方法的优势越明显。
显然,相对传统方法而言,采用本发明所述方法得到的星座卫星自主导航精度有了较大程度的提升。因此,本发明提出的基于强化学习的导航滤波器参数优化方法是有效的。
本发明的主要技术内容可用于星座卫星自主导航系统方案设计,实现我国新一代北斗卫星导航系统自主导航,也可推广用于其它地球轨道航天器和深空探测器自主导航,具有广阔的应用前景。
本发明说明书中未作详细描述的内容属于本领域专业技术人员的公知技术。
- 还没有人留言评论。精彩留言会获得点赞!