一种基于动态种群鲸鱼优化算法的社区检测方法与流程
本发明涉及数据挖掘领域,尤指划分网络中的非重叠社区结构。
背景技术:
现实世界中的许多复杂的问题或系统,例如电力系统、交通网络、计算机网络、生态系统等,直接研究这些问题或系统都是十分困难的。网络是一种能够帮助我们研究问题的有效工具,网络具有小世界特性、无标度特性、高群聚特性等都能够帮助我们研究复杂问题或系统,因此将复杂的问题或系统抽象为网络并加以研究成为近年来的研究热点。社区检测技术能够帮助我们分析网络中的局部特性,并进一步挖掘网络更深层次的结构关系。社区检测技术有许多方法,与已有的社区检测算法相比基于群体智能优化的社区检测方法表现出显著的优势。
群体智能优化算法是一种较为新颖的优化算法,它不依赖于梯度,因此能够应用于社区检测这类离散空间问题。目前已有一些基于群体智能的社区发现方法,例如1)q.liu,b.zhou,s.d.li,a.p.li,p.zouandy.jia,“communitydetectionutilizinganovelmulti-swarmfruitflyoptimizationalgorithmwithhill-climbingstrategy,”arabianjournalforscienceandengineering,vol.41,pp.807-828,2016.2)r.h.shang,j.bai,l.c.jiaoandc.jin,“communitydetectionbasedonmodularityandanimprovedgeneticalgorithm,”physicaa:statisticalmechanicsanditsapplicationsvol.392,pp.1215-1231,2013.3)q.cai,m.g.gong,l.j.ma,s.s.ruan,f.y.yuanandl.c.jiao,“greedydiscreteparticleswarmoptimizationforlarge-scalesocialnetworkclustering,”informationsciences316:503-516,2015.但这些已有的基于群体智能优化算法的社区方法普遍存在容易陷入局部最优和时间复杂度过高等问题。例如1)是基于果蝇优化的社区检测方法,在该方法中作者采用了多种群策略来提升算法的搜索能力,但这也使得算法需要消耗大量的时间。2)是基于基因算法的社区检测算法,该方法以寻找最大模块度作为划分目标,因此这导致该方法划分社区结果的准确率不高。3)是基于粒子群优化的社区检测方法,该方法采用了一种贪婪思想,这使得该算法更有可能得到较好的结果,但同时也使得该算法更容易陷入局部优化问题。已有的这些方法存在局部最优和时间复杂度较高的问题,为了解决这些问题,本方法将一种新颖且稳健的鲸鱼优化算法应用于社区发现。但鲸鱼优化算法适用连续数值问题,并不能很好的应用于社区发现这种符号空间搜索问题。因此,本方法对鲸鱼算法进行改进使鲸鱼算法能很好的应用于社区发现,同时本方法也加入了多种策略来提高算法性能,最终提出了一种基于动态种群鲸鱼优化算法的社区检测方法。
技术实现要素:
鉴于现有技术的以上不足,本发明的目的是提出一种更加稳定高效的基于群体智能优化的社区检测方法。其手段如下:
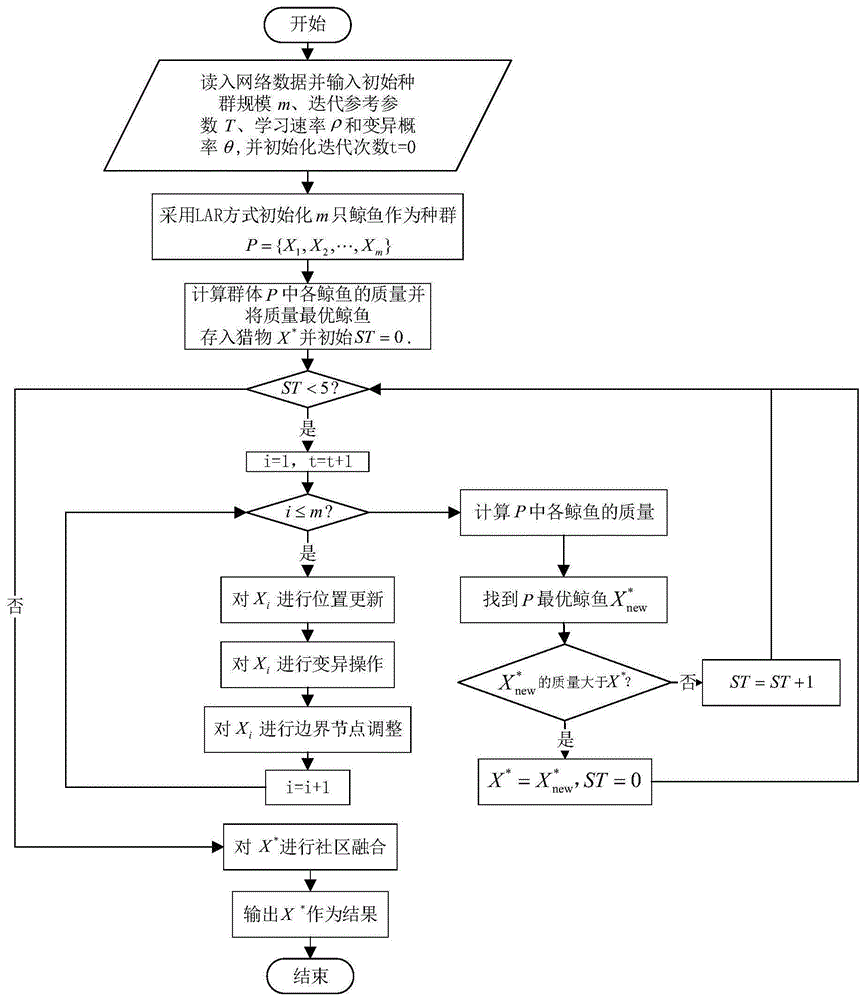
一种基于动态种群鲸鱼优化算法的社区检测方法,首先输入网络数据g=(v,e)并给定鲸鱼群体规模m=200、变异概率θ=0.3以及自适应迭代结束参数st=0;然后使用lar方式初始化m只鲸鱼作为鲸鱼群体p={x1,x2,…,xm};再计算群体中每只鲸鱼的质量f={f1,f2,…,fm},质量最高的鲸鱼个体作为猎物x*;在算法的每一次迭代中都需要对群体p中每一只鲸鱼进行位置更新、变异以及边界节点调整操作并得到更新后的鲸鱼群体p={x1,x2,…,xm};计算p={x1,x2,…,xm}中每只鲸鱼的质量f={f1,f2,…,fm};如果p={x1,x2,…,xm}中的质量最高的鲸鱼
步骤1:输入网络
步骤2:采用lar方式初始化m只鲸鱼作为鲸鱼种群p={x1,x2,…,xm},并计算群体p中每一只鲸鱼的质量f={f1,f2,…,fm},且质量最高的鲸鱼作为猎物x*;在lar方式初始化中,每只鲸鱼xi都是一个染色体xi={g1,g2,…,gn},染色体中的每一个基因都对应网络中的一个节点,因此n是网络中节点的个数;
步骤3:当前迭代次数t=t+1,并分别对鲸鱼种群p={x1,x2,…,xm}中的每一只鲸鱼xi进行更新操作(i={1,2,…,m},更新操作包括三个步骤依次为:位置更新、变异、边界节点调整;这三个步骤的详细介绍如下:
3.1位置更新
当对鲸鱼个体进行位置更新时,随机选择三种方式1)游向猎物、2)搜寻猎物、3)环绕猎物之一来进行位置更新;随机初始化两个参数a和b作为位置更新选择参数;a和b是随机生成数且a,b∈[0,1];当a<0.5且b<0.5时,xi选择“游向猎物”;当a<0.5且b≥0.5时,xi选择“搜寻猎物”;当a≥0.5时,xi选择“环绕猎物”;
所述三种位置更新方式描述如下:
“游向猎物”
xi为当前要更新位置的鲸鱼个体,x*为猎物;“游向猎物”是xi向x*学习的过程,本方法将学习过程定义为基因的学习过程;基因学习是指用x*中δ个基因来替代xi中对应的基因;δ的计算公式如下:
其中,ρ是学习速率,一般ρ∈(0,1],本发明采用ρ=0.2;t为当前迭代次数,t为参考迭代次数且采用t=10;计算得到xi的δ后,从x*的基因集合{g1,g2,…,gn}中有放回的抽样得到δ个基因来代替xi中对应位置的基因,这样便实现了xi游向x*;
“搜寻猎物”
通过鲸鱼xi的随机游走的方式来寻找质量高于x*的猎物;即鲸鱼xi向n个鲸鱼pn={x1,x2,…,xn}学习的过程,其中n=5且pn中的鲸鱼是从集合p={x1,x2,…,xm}中无放回抽样得到的;xi分别向pn中的每一只鲸鱼进行基因学习,这里的基因学习与“游向猎物”相同,但学习基因个数δ′=δ/5;
“环绕猎物”
xi环绕x*表示xi中的每个基因都有一定概率被x*中的对应基因替代,通过螺旋曲线函数来拟合xi向x*基因替代概率,螺旋曲线函数被定义如下:
其中,r∈[0,1]表示每个基因替代概率;b是一个常数,本方法令b=1;l是一个随机数且l∈[0,1],当xi环绕x*时初始化一个随机数l,并将l带入上式求得xi的基因被x*替换的概率r;遍历xi={g1,g2,…,gn}中的基因,并对于每一个基因gj都需要初始化一个随机数wj∈[0,1],当wj≤r时,xi中的基因gj被x*中的对应基因代替;
3.2变异操作
对xi进行位置更新后,需要对其进行变异;变异分为两种方式:单基因变异和联合基因变异;当对鲸鱼xi进行变异时,需要对xi={g1,g2,…,gn}中的每个基因进行变异操作,当对基因gj进行变异操作时,首先产生一个随机数d∈[0,1],当d>θ;θ为变异概率;不需要对gj进行变异操作;否则,产生一个随机数e∈[0,1],当e<0.5时,gj选择单基因变异,否则gj选择联合基因变异;
单基因变异表示gj自身变为一个新的值gj←max{g1,g2,…,gn}+1;gj对应网络中的一个节点,表示该节点自己组成一个新的社区;
联合基因变异表示gj自身及其邻居节点neib(gj)对应的基因一起变为一个新的值gj∪neib(gj)←max{g1,g2,…,gn}+1;经过联合基因变异后,gj对应的节点以及它的邻居节点一起组成一个新的社区;
为了保证变异操作能够使的xi的质量fi提高,只有质量提升的变异操作被保留,如果一个变异操作后鲸鱼的质量降低了,那么该鲸鱼会回退到变异前状态;
3.3边界节点调整
对xi进行变异后,对鲸鱼xi中的边界节点进行调整提升鲸鱼的质量;对鲸鱼xi进行边界节点调整流程定义如下:首先,检测出xi中所有的边界节点,并将这些边界节点对应的基因存入一个新的集合vb={g1,g2,…,gq}中(表示xi中存在q个边界节点);然后,依次对vb中的每一个节点进行基因调整;当对节点gj进行基因调整时,首先将gj的邻居节点neib(gj)中出现的所有基因种类存储到一个新的集合l=gj∪neib(gj)中,然后从l中取出能够使得xi具有最高质量的基因并赋予给当前边界节点
步骤4:鲸鱼群体p={x1,x2,…,xm}经过步骤3后得到更新后的鲸鱼群体p={x1,x2,…,xm},计算群体p中各鲸鱼的质量f={f1,f2,…,fm};找到群体p中质量最高的鲸鱼
步骤5:当st<5时,对种群p进行动态调整,并执行步骤3;否则执行步骤6;种群动态调整的步骤如下:首先,计算当前p的规模m,如果m≤10,则无需对p进行动态调整;否则对p执行如下操作:首先,依据鲸鱼的质量的大小对p进行降序排列,对于p中的每一个鲸鱼个体xi,当
上述公式仅用来计算普通鲸鱼被剔除的概率;其中,si是鲸鱼xi在普通鲸鱼群体中的排名,me是普通鲸鱼的个数;计算得到所以普通鲸鱼的剔除概率后,对于普通鲸鱼进行剔除操作;为每一只普通鲸鱼xi初始化一个随机数cri(cri∈[0,1]),当cri≤cuti时,xi被剔除,最后将剩余的普通鲸鱼与精英鲸鱼一起重新组成鲸鱼群体p;
步骤6:x*是算法迭代过程中找到的质量最高的鲸鱼,x*中包含了若干社区c={c1,c2,…,cs};为消除x*中的异常小社区而进一步提升结果质量,对x*进行社区融合,融合步骤如下所示:
step-1.对x*中的社区c={c1,c2,…,cs}按照社区大小进行降序排列c={c′1,c′2,…,c′s},其中ci.size()≥cj.sice()i<j;
step-2.初始化x←1,y←c.size();
step-3.如果x<y,则执行step-4,否则结束;
step-4.如果融合社区cx和cy使得鲸鱼质量提升,则cx←cx∪cy并从c中移除cy,执行step-2;否则x=x+1并执行step-3;
经过上述步骤后,将x*输出即为所求结果。
与现有技术相比,本发明的积极效果是:
一、区别于已有的基于群体智能优化的社区检测方法,本发明是基于近年来被提出来的一种新颖的鲸鱼优化算法,鲸鱼优化算法中“游向猎物”保证了算法的收敛性,“搜寻猎物”能够避免算法陷入局部最优问题,“环绕猎物”使得算法具有更加细致的搜索能力。本发明使用的鲸鱼优化算法具有更优的性能,同时本发明对鲸鱼算法的三种行为进行改进使得该算法能够更好的应用于社区检测。
二、区别于已有的基于群体智能优化的社区检测方法,本发明加入了新的变异操作来增加鲸鱼群体的多样性,新的变异操作分为:单基因变异和联合基因变异。单基因变异属于小力度变异操作,该操作能够对个体进行一个微小的调整以寻找更优解。而联合基因操作力度更大,能够快速推进种群多样性的发展,防止算法陷入局部最优问题。
三、区别于已有的基于群体智能优化的社区检测方法,本发明采用了自适应迭代结束条件,因此无需人为给定算法的迭代次数,算法能够根据运行情况来选择是否停止迭代。同时本方法还采用了动态种群策略,及种群规模并不是固定不变的,而是随着迭代的进行不断减少,该方式能够有效提升算法效率。
附图说明
图1是本发明方法的步骤流程示意图。
图2是本发明方法中位置更新流程示意图。
图3是本发明方法中变异流程示意图。
图4是本发明方法中边界节点调整流程示意图。
图5是对本发明中变异概率θ进行调整图。
图6是本发明在真实网络的试验结果。
图7是本发明在人工网络的试验结果。
具体实施方式
本发明方法的步骤流程示意如图1所示:
步骤1:输入网络
步骤2:采用lar方式初始化m只鲸鱼作为鲸鱼种群p={x1,x2,…,xm},并计算群体p中每一只鲸鱼的质量f={f1,f2,…,fm},且质量最高的鲸鱼作为猎物x*。在lar方式初始化中,每只鲸鱼xi都是一个染色体xi={g1,g2,…,gn},染色体中的每一个基因都对应网络中的一个节点,因此n是网络中节点的个数。lar方式在基于群体智能优化的社区发现算法中一种常用的方法。
步骤3:当前迭代次数t=t+1,并分别对鲸鱼种群p={x1,x2,…,xm}中的每一只鲸鱼xi进行更新操作(i={1,2,…,m},这表示该步骤需要对群体p中的每一只鲸鱼都进行更新操作),更新操作包括三个步骤依次为:位置更新、变异、边界节点调整。这三个步骤的详细介绍如下:
一、位置更新,如示意图2所示:
位置更新方式有三种,分别为:1)游向猎物、2)搜寻猎物、3)环绕猎物。当对鲸鱼个体xi进行位置更新时,xi会随机选择一种方式来进行位置更新,因此当每次对xi进行位置更新操作前,需要随机初始化两个参数a和b作为位置更新选择参数(a和b是随机生成数且a,b∈[0,1])。当a<0.5且b<0.5时,xi选择“游向猎物”;当a<0.5且b≥0.5时,xi选择“搜寻猎物”;当a≥0.5时,xi选择“环绕猎物”。三种位置更新方式描述如下:
1)游向猎物
xi为当前要更新位置的鲸鱼个体,x*为猎物。“游向猎物”是xi向x*学习的过程,本方法将学习过程定义为基因的学习过程(基因学习是指用x*中δ个基因来替代xi中对应的基因)。δ的计算公式如下:
其中,ρ是学习速率,一般ρ∈(0,1],本发明采用ρ=0.2;t为当前迭代次数,t为参考迭代次数且采用t=10。计算得到xi的δ后,从x*的基因集合{g1,g2,…,gn}中有放回的抽样得到δ个基因来代替xi中对应位置的基因,这样便实现了xi游向x*。
2)搜寻猎物
xi为当前要更新位置的鲸鱼个体,x*为猎物。“搜寻猎物”的目的是通过鲸鱼xi的随机游走的方式来寻找质量高于x*的猎物。本方法定义“搜寻猎物”方式为鲸鱼xi向n个鲸鱼pn={x1,x2,…,xn}学习的过程,其中n=5且pn中的鲸鱼是从集合p={x1,x2,…,xm}中无放回抽样得到的(从p中无放回抽取n个鲸鱼后,需要将p恢复到抽样前状态p=p∪pn,也就是说
3)环绕猎物
xi为当前要更新位置的鲸鱼个体,x*为猎物。xi环绕x*表示xi中的每个基因都有一定概率被x*中的对应基因替代。本方法通过会通过一个螺旋曲线函数来拟合xi向x*基因替代概率。螺旋曲线函数被定义如下:
其中,r∈[0,1]表示每个基因替代概率,r越大xi向x*学习程度越大;b是一个常数,本方法令b=1;l是一个随机数且l∈[0,1],当xi环绕x*时初始化一个随机数l,并将l带入上式求得xi的基因被x*替换的概率r。遍历xi={g1,g2,…,gn}中的基因,并对于每一个基因gj都需要初始化一个随机数wj∈[0,1],当wj≤r时,xi中的基因gj被x*中的对应基因代替。
二、变异操作
对xi进行位置更新后,需要对其进行变异操作,变异操作如流程图3所示。本方法中变异分为两种方式:单基因变异和联合基因变异。当对鲸鱼xi进行变异时,需要对xi={g1,g2,…,gn}中的每个基因进行变异操作,当对基因gi进行变异操作时,首先产生一个随机数d∈[0,1],当d>θ(θ为变异概率),不需要对gi进行变异操作;否则,产生一个随机数e∈[0,1],当e<0.5时,gi选择单基因变异,否则gi选择联合基因变异。单基因变异表示gi自身变为一个新的值(gi对应网络中的一个节点,表示该节点自己组成一个新的社区);联合基因变异表示gi自身及其邻居节点对应的基因一起变为一个新的值(gi对应的节点以及它的邻居节点一起组成一个新的社区)。为了保证变异操作能够使的鲸鱼质量提高,本方法要求只有质量提升的变异操作被保留,如果一个变异操作后鲸鱼的质量降低了,那么该鲸鱼会回退到变异前状态。
三、边界节点调整
对xi进行变异后,需要对其进行边界节点调整,边界节点调整流程如图4所示。边界节点指的是社区边界节点(邻居节点中存在不同社区节点),边界节点决定了社区的结构,因此也决定了社区的质量。本方法中定义的边界节点调整是为了在每次迭代过程中,对鲸鱼中的边界节点进行调整,从而提升鲸鱼的质量。对鲸鱼xi进行边界节点调整流程定义如下:首先,检测出xi中所有的边界节点,并将这些边界节点存入一个新的集合vb中;然后,依次对vb中的每一个节点进行社区标签调整。当对节点vi进行标签调整时,首先将vi的邻居节点中出现的所以标签种类存储到一个新的集合l中,然后从l中取出能够使得xi具有最高质量的标签并赋予给vi。因此,边界节点调整就是从邻居节点中找到最适合(使鲸鱼质量最大)自己的社区标签。
步骤4:鲸鱼群体p={x1,x2,…,xm}经过步骤3后得到更新后的鲸鱼群体p={x1,x2,…,xm},计算群体p中各鲸鱼的质量f={f1,f2,…,fm}。找到群体p中质量最高的鲸鱼
步骤5:当st<5时,对种群p进行动态调整,并执行步骤3;否则执行步骤6。种群动态调整的步骤如下:首先,计算当前p的规模m,如果m≤10,则无需对p进行动态调整;否则对p执行如下操作:首先,依据鲸鱼的质量的大小对p进行降序排列,对于p中的每一个鲸鱼个体xi,当
上述公式仅用来计算普通鲸鱼被剔除的概率。其中,si是鲸鱼xi在普通鲸鱼群体中的排名,me是普通鲸鱼的个数。上述公式表明,当鲸鱼xi为普通鲸鱼并且质量越小时,xi则被剔除的概率cuti就越高。计算得到所以普通鲸鱼的剔除概率后,对于普通鲸鱼进行剔除操作。为每一只普通鲸鱼xi初始化一个随机数cri(cri∈[0,1]),当cri≤cuti时,xi被剔除。最后将剩余的普通鲸鱼与精英鲸鱼一起重新组成鲸鱼群体p。
步骤6:x*是算法迭代过程中找到的质量最高的鲸鱼,x*中包含了若干社区c={c1,c2,…,cs}。本方法提出了社区融合策略来消除x*中的异常小社区,从而进一步提升结果质量。对x*进行社区融合,融合步骤如下所示:
step-1.对x*中的社区c={c1,c2,…,cs}按照社区大小进行降序排列c={c′1,c′2,…,c′s},其中ci.size()≥cj.sice()i<j;
step-2.初始化x←1,y←c.size();
step-3.如果x<y,则执行step-4,否则结束;
step-4.如果融合社区cx和cy使得鲸鱼质量提升,则cx←cx∪cy并从c中移除cy,执行step-2;否则x=x+1并执行step-3。
经过上述步骤后,将x*输出作为本方法的结果。
为了验证本发明的有效性,本发明使用公共网络数据集和lfr人工网络作为本发明的验证数据,并分别使用q和nmi作为本发明的评估度量(鲸鱼质量评价函数),其计算公式如下所示:
其中,s是划分的社区数量;m是网络中边的总数;lk是社区k中边的个数;dk是社区k中节点度的总和。a表示网络的真实社区结构,b表示算法划分的社区结构;ci表示社区i中节点个数,cij表示同时在社区i和j中节点个数;n为网络中节点总数。
参数设置说明
本方法中提供可调的参数包括:初始化种群规模m、迭代参考参数t、学习速率ρ以及变异概率θ。在本方法的试验中设定m=200,当然也可以根据实际的网络规模做适当的调整,网络规模小可适当减小m,反之可适当增大m。本方法设定迭代参考参数t=10以及学习速率ρ=0.2,t和ρ觉得了算法的收敛速度;t越小且ρ越大时算法收敛的越快,算法会更快的结束,但也可能来不及找到最优解。反之t越大且ρ越小时算法收敛的越慢,算法可能会迭代更多次,此时更有可能找到更好的结果,但同时也会消耗大量的时间。因此,t和ρ可根据具体对结果质量以及算法运行时间的要求进行适当调整。本方法设定变异概率θ=0.3,θ与其他参数不同,它对于算法结果有较大影响,因此本方法对θ的不同取值进行了测试,测试结果如附图5所示。可以看出θ≥0.3时算法趋于稳定,为了保证算法的执行效率同时也保证结果质量,本方法采用θ=0.3。
本发明方法在真实社交网络中的有效性评价试验
为了验证本发明的方法在真实社交网络中是否有效,在karate,dolphin,football,polbooks,lesmis,netscience,polblogs数据集上对本发明进行测试,并与cdmfoa,miga和gdpso进行对比(本发明被记作our),并采用q和nmi作为评价函数,由于优化算法存在一定随机性,为了更好的对本方法性能进行测试和对比,分别记录各算法的q的最大值和均值以及nmi的最大值和均值并进行对比,对比结果如附图6所示。真实网络实验结果表明本发明提出的方法不仅能够划分得到具有最高q和nmi的社区结构,同时本发明的方法也是最稳定的。
本发明方法划分网络的准确率评价试验
为了进一步验证本发明的方法划分网络的准确率,本发明在lfr生成带有真实社区标签的网络数据集上进行测试,其试验结果如图7所示。μ是lfr的一个重要参数,随着μ增大所生成的人工网络的真实社区结构就越复杂,且μ∈[0,1]。本发明采用0.1作为步长,使μ从0逐渐增长。对于社区结果采用nmi作为评价函数,其实验结果如附图7所示(本发明被记作our)。实验结果表明本发明能够检测到更接近于真实社区结构的结果,且效果较为显著。
- 还没有人留言评论。精彩留言会获得点赞!