基于深度学习的词句级短文本分类方法与流程
本发明属于自然语言处理
技术领域:
,具体涉及一种基于深度学习的词句级短文本分类方法。
背景技术:
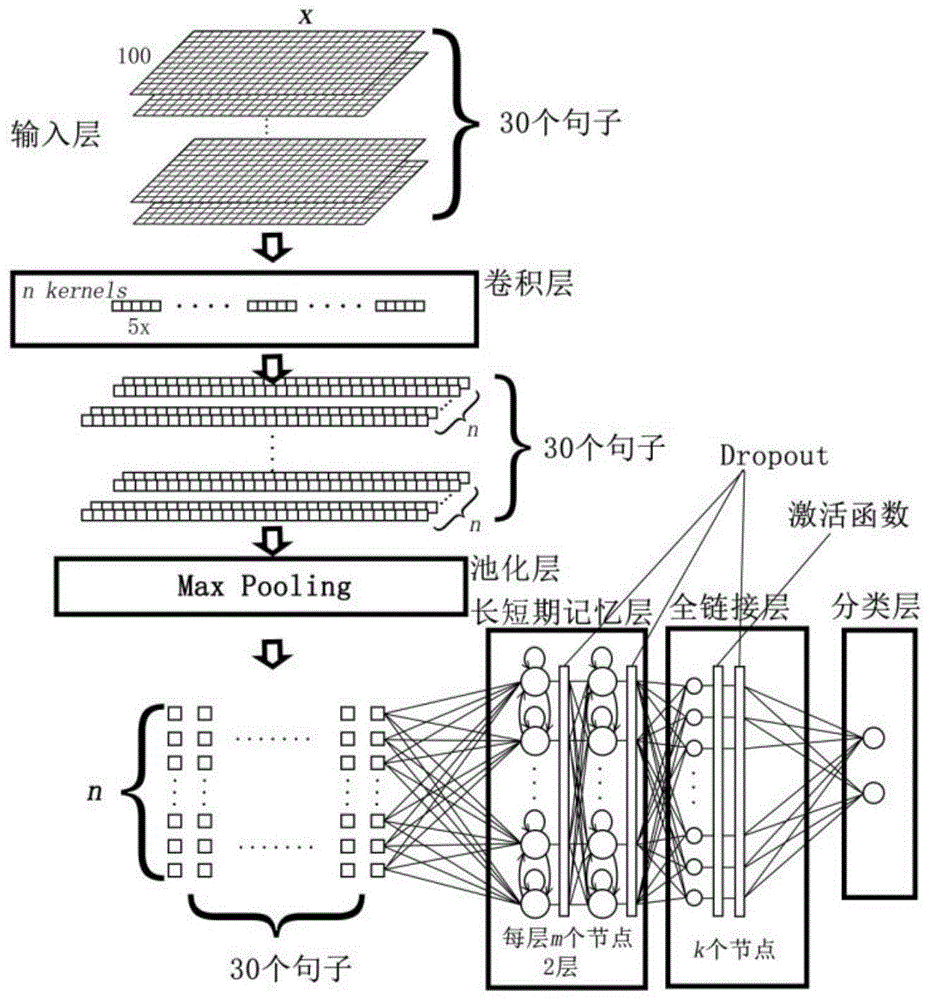
:随着计算机数据处理技术的发展,文本分类技术逐渐成熟并得到广泛的应用,其可应用的领域包括情感分析、主题分类、垃圾邮件检测等。而深度学习技术的发展,逐渐突出了卷积神经网络和循环神经网络两大重要的人工神经网络分支。于是,卷积神经网络利用其提取局部特征与有效降低权重参数的特性可较好的应用于计算机视觉的领域;循环神经网络对于前后输入的记忆与关联能力较强,善于处理序列及时间序列问题,因而常常应用于计算机认知科学的领域。考虑到文本内容的线性逻辑结构,学者们利用循环神经网络擅长处理时序数据的特点将其应用于文本分类中,进而衍生出矩阵向量循环神经网络(mv-rnn)、双向改进循环神经网络(bi-lstm)等结构。词向量的发现,使学者们尝试在文本分类中引入卷积神经网络,并提出了单层卷积神经网络(cnn-nostatic)、字符级的卷积神经网络(convnets)等结构。基于单层网络特征提取的局限性,有学者考虑利用复合网络模型完成深度特征的提取。因此,以aleksandrsboev等人为代表的c-rnn的研究者们,提出了一种结合cnn(卷积神经网络)、mlp(多层神经网络)和lstm(长短期记忆网络)的网络结构应用于文本分类领域。这种结构延伸出了一系列的研究,并实现了英文短文本分类、基于推特内容的交通事件检测模型与中文微博文本的情感分析等任务的处理。然而,目前的c-rnn研究更多倾向于改变卷积核或循环神经网络,尝试增加特征提取深度来获得更高的分类结果。实际上,很多研究都忽略了将句子层与词层结合研究,进行特征复合来进行复杂特征提取。因此,本发明提出了一种将词特征与句子特征结合的方法,基于词向量获得的词特征构建句子特征来表现短文本语义,进而实现文本的分类。技术实现要素:本发明的目的在于提供一种基于深度学习的词句级短文本分类方法,通过构建并训练所提出的词句级卷积循环神经网络模型实现。首先对输入的文本进行预处理操作,之后通过迭代卷积网络对输入文本每个句子中的词进行卷积池化计算提取句内词特征,然后将卷积网络输出的表达每个句子特征的向量依次输入长短期记忆网络进行全局关联,最后经过全连接层输出分类结果。本发明的目的是这样实现的:基于深度学习的词句级短文本分类方法,包括如下步骤:步骤一:获取待分类的文本数据及标签;步骤二:处理文本数据,通过word2vector训练获得词向量源表与检索词向量源表的词标签表;步骤三:通过识别尾缀符对文本数据进行分句处理,之后递归的对每个句子进行分词、去除停用词操作,最后通过词标签表检索词向量源表中的词向量来表示词,并根据句内词维数与句子要求进行padding操作;最终将文本转化为y×x×z的三维张量,其中y为句维数、x为句内词维数、z为词向量维数;步骤四:使用多卷积核对输入张量进行一维卷积计算,卷积后的特征图高度为h2=(h1-f+2p)/s+1,其中f表示卷积核维度的大小,p表示padding的尺寸,s表示卷积步长,通过n个卷积核的计算,每个句子最终获得n张一维卷积特征图;步骤五:使用一维最大池化maxpooling1d对卷积后的结果进行池化以提取句子的核心特征,池化后每个卷积核计算出的特征图将压缩为一个单一值,每个句子的特征由n个特征图池化后连接得到的n维向量表示,其将作为长短期记忆层某一时序下的输入;步骤六:通过卷积层与池化层递归的对每个句子进行计算,获得总时序y下长短期记忆层的输入;步骤七:将长短期记忆层的输出作为输入进入全连接层,用以平展网络的输出,全连接层输出维度为数据的类别数目并将softmax函数作为分类器,通过计算全连接层的输出实现分类,其计算式为其中,y(i)代表输出层第i个神经元的值,y(k)代表输出层中第k个神经元的值,exp代表以e为底的指数函数。所述步骤四中一维卷积计算式为其中mj表示某一卷积核输入值集合,与分别为卷积权重和偏置。所述步骤四中使用一维卷积层对输入进行卷积操作,卷积核大小设置为5,步长为1,数目256个。所述步骤五中一维最大池化计算式为ht=max(hj),其中ht表示长短期记忆层在t时刻的输入句向量连接式为ht=[ht(1);ht(2);...;ht(n)]。所述步骤六中长短期记忆网络在时序t时单一节点的递进计算公式为ft=σ(wf×[ht-1,ht]+bf),it=σ(wi×[ht-1,ht]+bi),ot=σ(wo×[ht-1,ht]+bo),h't=ot*tanh(ct),其中,ft表示遗忘门,σ表示sigmoid函数,wf表示遗忘门的权重矩阵,ht-1代表lstm网络上个时刻的输出,ht表示长短期记忆层在t时刻的输入,[ht-1,ht]表示把当前向量合并至前序向量中,bf为遗忘门的偏置值;it表示输入门,wi表示输入门的权重矩阵,bi表示输入门的偏置值;表示根据上一次的输出和当前的输入计算获得的当前输入的状态,wc表示当前输入状态的权重矩阵,bc表示当前输入状态的偏置值;ct表示由遗忘门ft乘上一时刻的单元状态ct-1加输入门it乘当前输入状态的和计算出的当前时刻状态,这样就把长短期记忆层长期的记忆ct-1与当前记忆结合在一起形成新的状态ct;ot表示输出门,wo代表输出门的权重,bo代表输出门的偏置值;h't表示长短期记忆层最终的输出。所述步骤六中在长短记忆层的每层门后加入dropout机制。所述步骤七中在全连接层后均加入dropout机制,全连接层节点后接入relu激活函数。本发明有益效果在于:(1)相比于当前诸如bi-lstm、cnn-nostatic等单层神经网络特征维度上的表现,本发明基于复合神经网络实现,其特征维度要高于前述单层神经网络;(2)相比于当前的种种c-rnn结构在提取特征深度上的突破,本发明在特征提取中保留了句子结构,通过cnn与rnn分别实现句内词间关系与句间关系的提取;(3)相比于当前的网络输入多数为二维矩阵的情况,本发明的网络输入结构为三维张量;(4)本发明由于以句子为单位限定了不同文本卷积池化迭代的次数需相同,由本方法进行分类,文本篇幅差距不宜过大,因此较为适用于短文本分类。附图说明图1为词句级卷积循环神经网络模型结构图。具体实施方式下面结合
发明内容,通过以下实施例阐述本发明的一种详细实施方案与效果。一种基于深度学习的词句级卷积循环神经网络短文本分类方法,用于处理短文本分类任务。本发明的核心在于基于词向量技术,通过连接卷积神经网络多个卷积核卷积池化句内词向量获得的多组特征图实现句向量,进而保留文本的句子层结构,完成句子内容的表达。句子是承载词汇的结构,因此句的本质仍然为词。由词向量构成的二维矩阵经过n个卷积核进行一维卷积并最大池化后,将得到一个由多个特征图组成的n维向量。这个n维向量体现了句内特征,反之最初的二维矩阵仅为词向量的顺位连接,没有产生内部关联性。因此,卷积后连接特征图产生的句向量更适合承载句子体。此外,文本、句、词是依次向后包含的关系,且语言是一种线性结构。因此语言的认知一般从文本由前到后并依次按照词、句、文的顺序理解。将循环神经网络置于卷积神经网络之后也恰好使复合结构先学习词特征再学习句特征,且从单句的处理角度看,识别句内词特征后就将该句与上文关联记忆,也符合这种一般的语言认知方式。步骤一:获取待分类的文本数据及标签。本实施例选取了两种不同的中文短文本数据集训练网络以检验本发明提出的词句级模型在不同短文本分类的表现效果。其中,第一类数据集为csdn提供的真实垃圾电子邮件数据集,共43916条。该数据集包括一般电子邮件16556封与垃圾电子邮件27360封,为二分类数据。本实施例在一般电子邮件与垃圾电子邮件中分别随机选取6500条数据共13000条数据作为神经网络训练的数据集。第二类数据集为新闻数据集thucnews,它是根据新浪新闻rss订阅频道2005-2011年间的历史数据筛选过滤生成,包含74万篇新闻文档,均为utf-8纯文本格式。本实施例在原始新浪新闻分类体系的基础上,重新整合划分出十个候选分类类别:体育、财经、房产、家居、教育、科技、时尚、时政、游戏、娱乐,并在每个类别中获取6500条数据共65000条数据作为神经网络训练数据集。具体的数据集信息如表1所示。表1文本分类数据集信息表数据集训练数据验证数据测试数据类别分类任务语言真实垃圾邮件数据集10000100020002邮件分类中文thucnews5000050001000010新闻分类中文步骤二:处理文本数据,通过word2vector训练获得词向量源表与检索词向量源表的词标签表。词向量完成了字符到值的数值转化。word2vector为google开发的开源词嵌入工具,通过语料训练获得词向量。分词即把句子拆分成若干单词或词组的过程,是处理中文文本的关键。去除停用词即降低无权重或低权重词汇的数量,提高保留词汇的价值,进而获得更好的文本分析结果。本例借助jieba分词包实现了分词操作,并利用哈尔滨工业大学停用词词库,实现去除停用词。将文本数据经分词与去除停用词处理后利用word2vector训练词向量。两个数据集最终获得的词向量表信息如表2所示。表2词向量信息表数据集词汇表大小词向量维数真实垃圾邮件数据集104674100thucnews412955100步骤三:数据预处理。通过识别尾缀符对文本数据进行分句处理,之后递归的对每个句子进行分词、去除停用词等操作,最后通过词标签表检索词向量源表中的词向量来表示词,并根据句内词维数与句子要求进行padding操作。最终将文本转化为y×x×z的三维张量,其中y为句维数(即限定的句子的个数)、x为句内词维数(即限定的一个句子内次的个数)、z为词向量维数。步骤四:构建复合神经网络模型。按照图1所示的词句级卷积循环神经网络模型结构构建网络,具体的网络结构参数(超参数)如表3所示。表3网络结构参数表参数名称参数值句内词维数50句维数30词向量维数100卷积核尺寸5卷积核个数64卷积步长1长短期记忆层层数2长短期记忆层单层节点个数64全链接层节点个数128dropout保留率0.5分类层节点个数2步骤五:网络训练与测试。词句级神经网络的工作原理包括:1)使用多卷积核对输入张量进行一维卷积计算,卷积后的特征图高度通过公式(1)计算。一维卷积计算公式见式(2)。通过n个卷积核的计算,每个句子最终将获得n张一维卷积特征图。h2=(h1-f+2p)/s+1(1)其中,f表示卷积核维度的大小,p表示padding的尺寸,s表示卷积步长,mj表示某一卷积核输入值集合,与分别为卷积权重和偏置。2)使用一维最大池化maxpooling1d对卷积后的结果进行池化以提取句子的核心特征,一维最大池化公式见式(3)。池化后每个卷积核计算出的特征图将会压缩为一个单一值,每个句子的特征由n个特征图池化后连接得到的n维向量表示,其将作为长短期记忆层某一时序下的输入。句向量连接公式见式(4)。ht=max(hj)(3)ht=[ht(1);ht(2);...;ht(n)](4)3)通过卷积层与池化层递归的对每个句子进行计算,可获得总时序y下长短期记忆层的输入。长短期记忆网络可以将前后文的句向量按序关联并把握全文语义,进而实现短文本分类。长短期记忆网络作为一种优化的循环神经网络结构,其在时序t时单一节点的递进计算式见式(5)到(10)。ft=σ(wf×[ht-1,ht]+bf)(5)it=σ(wi×[ht-1,ht]+bi)(6)ot=σ(wo×[ht-1,ht]+bo)(9)h't=ot*tanh(ct)(10)其中,ft表示遗忘门,σ表示sigmoid函数,wf表示遗忘门的权重矩阵,ht-1代表lstm网络上个时刻的输出,ht表示长短期记忆层在t时刻的输入,[ht-1,ht]表示把当前向量合并至前序向量中,bf为遗忘门的偏置值;it表示输入门,wi表示输入门的权重矩阵,bi表示输入门的偏置值;表示根据上一次的输出和当前的输入计算获得的当前输入的状态,wc表示当前输入状态的权重矩阵,bc表示当前输入状态的偏置值;ct表示由遗忘门ft乘上一时刻的单元状态ct-1加输入门it乘当前输入状态的和计算出的当前时刻状态,这样就把长短期记忆层长期的记忆ct-1与当前记忆结合在一起形成新的状态ct;ot表示输出门,wo代表输出门的权重,bo代表输出门的偏置值;h't表示长短期记忆层最终的输出。4)将长短期记忆层的输出作为输入进入全连接层,用以平展网络的输出。全连接层输出维度为数据的类别数目并将softmax函数作为分类器,通过计算全连接层的输出实现分类,其计算公式见式(11)。其中,y(i)代表输出层第i个神经元的值,y(k)代表输出层中第k个神经元的值,exp代表以e为底的指数函数。神经网络的训练参数如表4所示。表4训练参数表参数名称参数含义参数值batch_size批尺寸64epoch_size数据代次数10learning_rate学习率0.001learning_rate_decaty学习率衰减率0.9分别对两类数据集进行训练,并对测试数据测试所得结果进行对比分析,如表5所示。其中,训练垃圾电子邮件数据所得cnn-nostatic为本例还原的cnn-nostatic网络,在thucnews的结果中,cnn-nostatic与bi-lstm为gaussic的实验结果。表5文本分类实验结果表方法真实垃圾邮件数据集thucnewscnn-nostatic98.95%96.04%bi-lstm-94.22%word-sentence-rcnn99.35%95.87%此外,在步骤3)与步骤4)中,为了有效遏制深度学习训练中的过拟合问题,在长短期记忆层的每层门后以及全连接层后均加入了dropout机制。在步骤4)中,全连接层节点后接入了relu激活函数用以模拟生物神经元的兴奋与抑制态,relu激活函数见式(12)。如果没有激活函数的存在,神经网络仅为纯粹的矩阵叠加计算。relu(x)=max(0,x)(12)根据实验结果,本发明提出的词句级分类方法较为有效的解决了不同程度类别需求的短文本分类问题。在中文垃圾电子邮件分类中,word-sentence-rcnn的表现强于cnn-nostatic,而在新闻分类上,尽管cnn-nostatic的准确率最高,达到96.04%,但word-sentence-rcnn也比较接近于该值。由于以句子为单位限定了不同文本卷积池化迭代的次数需相同,由本方法进行分类,文本篇幅差距不宜过大,因此较为适用于短文本分类。由于句向量由句内词向量经卷积池化连接而来,因此称本发明的c-rnn结构为词句级结构,该方法亦称为词句级短文本分类方法。本发明的保护内容包括但不局限于以上实施例。在不背离发明构思的情况下,本领域技术人员设计出的与该技术方案相似的方法步骤及实施例或根据本发明做出的改进和替换,以所附的权利要求书为准,均属于本发明的保护范围。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1