基于置信分数的无参考图像质量评价方法与流程
本发明涉及图像质量评价领域,特别涉及一种基于置信分数的无参考图像质量评价方法。
背景技术:
数字图像在其采集、压缩及传输等过程中通常会受到不同程度的失真降质。图像质量评价旨在度量失真对图像视觉感知质量的影响。高效准确的图像质量评价在诸多实际应用中发挥着关键作用,是保证用户视觉感知体验的重要基础。近年来,客观图像质量评价方法印其可实现自动高效的质量预测获得了研究人员的关注。因为参考图像在大多数实际场景中无法采集或获取代价较大,而无参考图像质量评价方法能够在参考图像信息不可用的情况下,直接对失真图像进行质量评价,因此开发有效的无参考图像质量评价方法具有十分重要的研究意义和应用价值。近年来出现的算法主要解决无参考图像质量评价出现的两个问题:
(1)采用数据增广策略时无法获取图像块真实标签的问题,针对该问题,目前有些算法认为裁剪图像块的真实标签可由全参考方法生成的局部客观质量分数来代替。但是该类方法存在应用场景受限的问题,因为其在训练时需要必要的参考图像信息。
(2)数据量限制的问题,针对该问题,目前同样有一些算法,比如在imagenet数据库进行预训练,然后在图像质量评价数据库上精调网络的方式来处理无参考图像质量评价问题或者是基于成对排序学习提出一种新的数据增广方法,利用两幅图像之间的相对感知质量来训练网络。具体地,通过对原始图像用不同的失真方法结合不同的失真强度进行失真,得到大量失真图像,然后两两组合构建包含相同失真图像对的数据集,并将这些图像对传入siamese网络进行预训练,预训练结束后取siamese网络的一支来进行微调等等。
这些方法从不同的角度来解决将卷积神经网络应用到无参考图像质量评价领域时出现的一系列问题,但是其最终采用的还是一元回归框架。直接将mos或者dmos值作为一元回归标签的策略,在一定程度上忽略了在进行主观评分时带来的个体主观差异。
技术实现要素:
本发明的目的在于提供一种无需参考图像信息,且具有评价结果准确、泛化性良好等特点的图像质量评价方法。
实现本发明目的的技术解决方案为:一种基于置信分数的无参考图像质量评价方法,包括以下步骤:
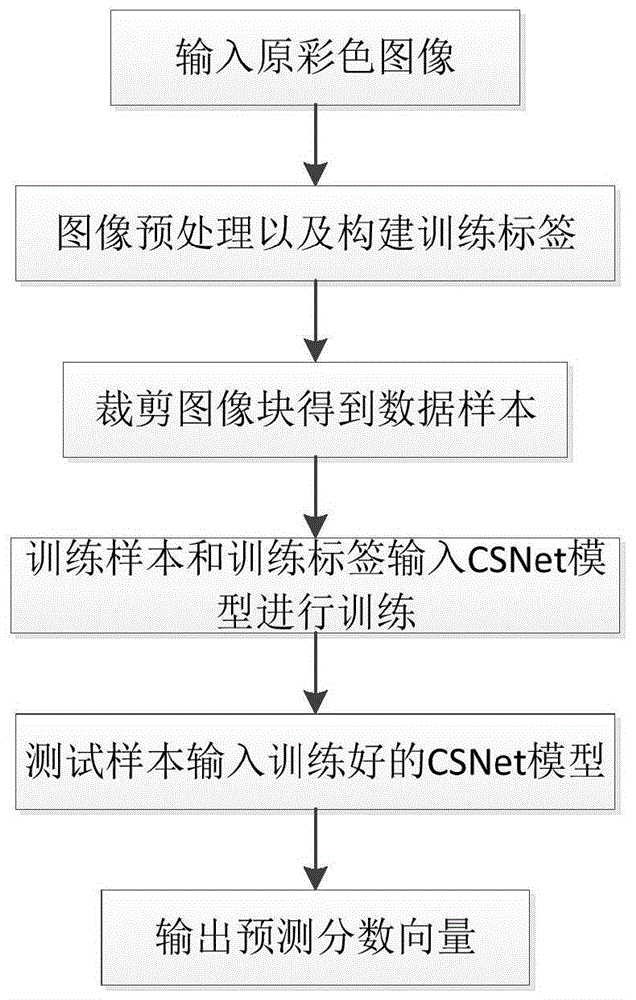
步骤1、从图像质量评价数据库中采集若干图像;
步骤2、对采集的图像进行预处理,并构建训练标签;
步骤3、将预处理后的图像划分为训练集和测试集,然后对训练集和测试集进行裁剪获得相应的数据样本;
步骤4、构建基于置信分数的网络模型csnet;
步骤5、将训练集中的训练样本和对应的训练标签输入构建的csnet模型进行训练;
步骤6、将测试集中的测试样本输入训练好的csnet模型获得预测分数向量;
步骤7、对来自于同一原图像的所有测试样本的预测分数向量取平均值获得该图像的质量分数。
进一步地,步骤2所述构建训练标签具体为:
根据原图像对应的质量分数s以及标准差分数δ构建一个二元置信分数向量即训练标签为:
[s-3δ,s+3δ]。
进一步地,步骤4所述构建基于置信分数的网络模型csnet,具体为:
构建的csnet模型共包括8个卷积层,每个卷积层都为“conv-bn-relu”结构,即卷积层-batchnorm层-relu激活层;卷积核的大小均为3×3,通道数分别32,32,64,64,96,96,128,128;卷积层的步长为1,补零设置为1;
在第二、第四、第六和第八个卷积层后都连接一个最大池化层,窗口大小设置为3×3,步长为2;最后一个池化层后连接四个全连接层,前三个全连接层的通道数分别为1000,500,100,最后一个全连接层输出为2,且只在第一个全连接层后接一个relu激活层。
本发明与现有技术相比,其显著优点为:1)从统计学和个体主观评分差异的角度出发,利用图像质量评价数据库提供的质量分数以及标准差分数,构建二元置信分数向量来表征裁剪训练样本的训练标签,相对于一元分数更加准确;2)构建的卷积神经网络模型csnet更改传统的一元回归框架为二元回归框架,将训练样本和对应的训练标签输入构建卷积神经网络模型进行训练,利用测试集进行测试;与其他方法进行对比,本发明具有很强的竞争力,在多个数据库上都取得了最佳效果,并具有良好的泛化能力;3)采用裁剪较大图像块的做法在一定程度上可以减少样本与原图像的分数误差;4)将训练样本的真实分数用二元置信分数向量隐式表征,考虑了个体主观差异带来的影响并且不需要利用参考图像信息去获得训练样本的真实标签;5)同时仍然可以采用裁剪图像块的数据增广策略,可以直接在实验数据库上进行训练测试,不需要在别的数据库(如imagenet)上进行预训练然后在实验数据库上进行训练。
下面结合附图对本发明作进一步详细描述。
附图说明
图1为本发明基于置信分数的无参考图像质量评价方法的流程图。
图2为本发明中csnet模型架构图。
具体实施方式
结合图1,本发明一种基于置信分数的无参考图像质量评价方法,包括以下步骤:
步骤1、从图像质量评价数据库中采集若干图像;
步骤2、对采集的图像进行预处理,并构建训练标签;
步骤3、将预处理后的图像划分为训练集和测试集,然后对训练集和测试集进行裁剪获得相应的数据样本;
步骤4、构建基于置信分数的网络模型csnet;
步骤5、将训练集中的训练样本和对应的训练标签输入构建的csnet模型进行训练;
步骤6、将测试集中的测试样本输入训练好的csnet模型获得预测分数向量;
步骤7、对来自于同一原图像的所有测试样本的预测分数向量取平均值获得该图像的质量分数。
进一步优选地,步骤2中对采集的图像进行预处理,并构建训练标签,具体为:
步骤2-1、对图像进行灰度化处理;
步骤2-2、对灰度图像进行归一化处理;
步骤2-3、根据原图像对应的质量分数s以及标准差分数δ构建一个二元置信分数向量即训练标签为:
[s-3δ,s+3δ]。
进一步优选地,步骤3中对训练集和测试集进行裁剪获得相应的数据样本,具体为:在预处理后的图像上以步长为δl裁剪l×l大小的图像块作为相应的数据样本,其中步长为δl表示从图像左上角开始每隔δl个像素裁剪一个l×l大小的图像块;δl≥32,l≥32。
示例性优选地,上述δl=50,l×l=100×100。
进一步优选地,结合图2,步骤4中构建基于置信分数的网络模型csnet,具体为:
构建的csnet模型共包括8个卷积层,每个卷积层都为“conv-bn-relu”结构,即卷积层-batchnorm层-relu激活层;卷积核的大小均为3×3,通道数分别32,32,64,64,96,96,128,128;卷积层的步长为1,补零设置为1;
在第二、第四、第六和第八个卷积层后都连接一个最大池化层,窗口大小设置为3×3,步长为2;最后一个池化层后连接四个全连接层,前三个全连接层的通道数分别为1000,500,100,最后一个全连接层输出为2,且只在第一个全连接层后接一个relu激活层。
进一步优选地,步骤5中将训练样本和对应的训练标签输入构建的csnet模型进行训练,具体为:
训练过程中采用的损失函数为欧式损失函数即l2损失函数,其公式为:
式中,yi为真实分数,即训练标签,
进一步优选地,上述构建的csnet模型采用自适应矩估计算法进行优化。
进一步地,步骤7中对来自于同一原图像的所有预测分数向量取平均值得到该图像的质量分数,所用公式为:
式中,[si1,si2]为对应原图像的第i个测试样本的预测分数向量,n为原图像裁剪后得到的所有测试样本的个数,s为原图像的预测质量分数。
下面结合实施例对本发明作进一步详细的描述。
实施例
本发明所用图像质量评价数据库的基本信息如下表1所示。
表1本发明所用图像质量评价数据库的基本信息
本实施例中将针对表1中的所有数据库中的图像对本发明的方法进行验证。
首先是针对单重失真数据库的实验,在四个经典单重失真数据库上进行,包括:live、csiq、tid2008和tid2013。针对每一个数据库,将库中的图像根据参考图像按照8:2的比例分为训练集和测试集。对训练集中的图像进行灰度化以及归一化处理之后,根据数据库提供的质量分数以及标准差分数得到对应训练图像的二元置信分数向量训练标签。对预处理后的图像进行步长为50像素的裁剪,得到多个100×100尺寸大小的图像块,将图像块与对应的训练标签输入构建的csnet模型进行训练。损失函数选用欧式距离函数,并采用adam算法来优化,学习率设置为0.01,每次训练的batchsize设置为64。每迭代11个epoch将学习率下降10倍,总共训练66个epoch。对测试集中的图像同样进行灰度化以及归一化处理,然后裁剪预处理后的图像得到测试图像块,将测试图像块输入训练好的csnet模型得到图像块的预测分数向量。将来自于同一原图像的所有图像块的预测分数向量取均值得到对应源图像的预测质量分数。然后利用图像质量评价的评价指标srocc(预测单调性的斯皮尔曼排序相关系数)和lcc(衡量预测线性相关性的皮尔逊系数)进行算法性能对比,对比算法的结果如下表2和表3所示:
表2在live、csiq、tid2008数据库上的性能对比
表3在tid2013数据库上的性能对比
由表2可以看出,本发明提出的基于置信分数的无参考图像质量评价方法在三个数据库上均取得了良好的性能,并且与全参考方法fsim的结果相当。由表3可以看出,在更具挑战性的tid2013数据库上,本发明取得了无参考方法中最好的性能结果和仅次于全参考方法fsim的性能结果。
其次是针对多重失真数据库的实验,与单重失真不同的是,采用在livemd整体数据库上训练,在mdid2013整体数据库上进行测试的方案。训练样本和测试样本的获取、测试结果的获取、优化算法的参数设置均与单重失真实验一致。同样采用评价指标srocc和lcc来进行算法性能对比,对比算法结果如表4所示:
表4在多重失真数据库上的性能对比
从表4可以看出本发明取得了良好的结果,与目前在mdid2013数据库上表现最佳的无参考方法sisblim相比,本发明分别提高了1.8%和3.5%。与全参考方法相比,本发明也表现得很有竞争力,取得了仅次于psim的结果,但明显优于ssim和vsi。
一般来说,一个优秀的基于训练的无参考图像质量评价算法,其性能应当于数据库图像无关,也就是说算法得到模型能够适用于不同数据库不同图像语义不同失真类型并且能够取得良好的结果。因此本发明在四个数据库:live、csiq、tid2013、ivc上进行验证。为了公平进行对比,采取在live整体数据库上进行训练,在其他三个数据库上进行测试的实验方案。因为用于测试的三个数据库包含许多live数据库没有的失真类型,测试过程中,仅选取与live数据库共有的失真类型来进行测试,具体地,csiq和tid2013的测试数据包含白噪声失真、高斯模糊失真、jp2k压缩失真、jpeg压缩失真。ivc的测试数据包含jpeg压缩失真、jp2k压缩失真、高斯模糊失真。训练样本和测试样本的获取、测试结果的获取、优化算法的参数设置均与单重失真实验一致。同样采用评价指标srocc和lcc来进行算法性能对比,对比算法结果如下表5所示:
表5在csiq、tid2013、ivc数据库上的跨库测试结果
由表5可知,本发明在三个数据库上的跨库实验都取得了令人满意的结果。其中在csiq和ivc上都取得了最优性能,在tid2013上也取得了相对较好的性能。三个数据库上的对比实验表明本发明具有良好的泛化能力,对于不同数据库不同图像语义具有较好的鲁棒性。
最后需要验证本发明提出的二元置信分数向量确实取得比传统的一元回归更好的结果。该部分验证是在前面的基础上进一步验证的,将之前的置信分数向量回归改为一元回归,所有的实验设定,如训练-测试实验划分,训练测试样本的获取、训练策略、参数的选择等,均与前面的实验相同。具体地,在三个单重失真数据库(csiq、tid2008、tid2013)上的对比实验和在多重失真数据(livemd、mdid2013)上的对比实验。其中多重失真数据库上的实验为在livemd整体数据库上训练,在mdid2013整体数据库上测试,对比结果如下表6所示:
表6二元置信分数向量回归与一元回归的对比实验
由表6可以看出,二元置信分数向量取得了比一元回归更好的结果,这也证明了本发明的有效性。
根据表2、3、4、5和6中的结果,证明本发明提出的方法具有良好的有效性以及鲁棒性,对各类型失真图像质量预测都取得了优良结果。同时证明了用二元置信分数向量表征图像质量分数相对于单一分数更加准确。
- 还没有人留言评论。精彩留言会获得点赞!