立体格局图产生方法与系统与流程
1.本发明关于一种立体格局图产生的技术,特别是指基于深度学习方法执行影像辨识与辨识空间型态而生成立体格局图的方法与系统。
背景技术:
2.随着影像辨识技术逐渐成熟,许多的影像应用因应而生,例如有拍摄全景图(panorama)的技术、取得360度空间图的技术等,形成立体影像的方式为依据影像的边界拼接多张影像,且一次仅能处理一个空间的影像。
3.对于较为复杂与多区域的全景图像处理,习知技术尚缺乏有效形成立体格局图的方法。
技术实现要素:
4.说明书揭示一种立体格局图产生方法与系统,其目的的一个是能根据拍摄的全景图(panorama)利用深度学习方法取得影像特征,辨识其中物件与空间的关系,进一步建模而产生立体格局图。
5.根据实施例的一个,所提出的立体格局图产生系统包括一主机,其中设有一或多个处理器与储存器,储存器储存由拍摄装置拍摄而取得涵盖一空间的一或多张影像,其中一或多张影像为对应此空间内的一或多个区域的全景图,由处理器执行实现影像辨识的人工智能的一或多个深度学习方法,以执行一立体格局图产生方法。
6.在立体格局图产生方法中,先取得涵盖一空间的一或多张影像,一或多张影像为对应空间内的一或多个区域的全景图,接着利用图像处理技术辨识并标记各区域全景图中的一或多个物件,并且分类各全景图中的一或多个物件,用以辨识各区域的空间型态,之后,能根据空间内的一或多个区域的空间型态得出各区域的尺寸与格局。
7.通过图像处理,还能于各全景图中定位空间中各区域的点与线,得出点与线在各区域的位置,之后通过结合空间的各全景图的一或多个物件,可依据各区域的点与线形成一立体格局图。
8.优选地,方法中用以辨识各影像中一或多个物件以及辨识各区域的空间型态的图像处理技术采用深度学习方法,可以根据辨识得出各区域的一或多个物件的属性来辨识出各区域的空间型态。
9.进一步地,所述空间包括有多个区域,各区域的全景图定位出的点与线形成多个区域之间的边界与相对关系,配合各区域中的一或多个物件与空间型态得出多个区域之间的连接关系,执行一立体空间建模,以结合多个区域以形成立体格局图。
10.优选地,在所述空间中,由各全景图辨识的各物件为室内区域内的门、窗、墙、家具与摆设的其中的一个,其中采用的深度学习方法的一个为双投射网络,其中采用等距长方全景视图与透视天花板视图,根据各区域的全景图预测各区域的一立体空间的格局。
11.更者,辨识各影像中物件以及辨识各区域的空间型态的深度学习方法还可包括一
深度残差网络,用于影像识别与分类,以快速地识别与分类各区域的格局。
12.所述深度学习方法的再一方法为一侦测网络的深度学习算法,能于分析各区域的全景图后,从影像中特征识别出各区域中一或多个物件,并执行定位。
附图说明
13.图1显示拍摄全景图的装置实施例示意图;
14.图2所示为描述立体格局图产生方法的实施例流程图之一;
15.图3所示为描述立体格局图产生方法的实施例流程图之二;
16.图4以图示方法描述立体格局图产生方法的实施例流程;
17.图5描述双投射网络的深度学习方法流程;
18.图6描述深度残差网络的深度学习方法流程;
19.图7a与7b显示侦测网络的深度学习成果的示意图;
20.图8显示利用深度学习识别场景的实施例示意图;
21.图9显示在二维平面图中定位区域的实施例示意图;
22.图10显示形成立体格局图前建立立体模型的实施例示意图。
具体实施方式
23.说明书公开一种立体格局图产生方法与系统,方法为基于取得的一或多张全景图,或者进一步地,先取得一个空间(包括多个区域)的多张全景图。所述全景图(panorama)是一种影像涵盖视野达到全景左右360度、上下180度的视野的广角图,其应用的一个可用于扩增实境(ar)或是虚拟现实(vr)场景,让使用者穿戴特定虚拟现实装置时,可以自由地在左右360度与上下180度的视野中浏览场景。
24.图1显示拍摄全景图的装置实施例示意图,在此实施例中,终端装置包括一拍摄影像的拍摄装置11,拍摄装置11实现一种全景摄影机(panoramic camera),较佳是配备有可以拍摄超广角影像的鱼眼镜头;可以为手机,其中照相机可能不具备鱼眼镜头的能力,但可以通过外挂镜头15的方式达成。
25.若为了要拍摄整个场景的全景图,需要涵盖左右360度与上下180度的视野,此例中,即将拍摄装置11安装于一可带动旋转拍摄整个场景的承载装置13,通过旋转机构135承载拍摄装置11,其中设有可以带动拍摄装置11旋转的马达,如步进马达。
26.承载装置13为可以程序化的装置,可以依照拍摄装置11的镜头15每次拍摄视场的涵盖范围决定拍摄每张影像的旋转角度。例如,当镜头15为可以涵盖上下左右180度视野的镜头,为了要拍摄涵盖左右360度与上下180度视野的全景图,至少需要在第一次拍摄后,旋转180度后进行第二次拍摄,如此才能得到涵盖左右360度与上下180度的全景图。或者,可以根据镜头15涵盖的视野,通过几次旋转后拍摄多次,每次拍摄的影像仅涵盖特定角度的视野,多张影像之间将包括重叠的特征,如边界或角落等区域,作为拼接影像的依据。
27.经拍摄装置11配合承载装置13完成全景图拍摄后,影像数据除了可以通过拍摄装置11内处理能力与相关软件程序达成拼接后形成全景图,还可以通过网络10或直接联机传送到主机14(另不排除可以传送到特定云端系统处理影像),由主机14执行图像处理,完成拼接而形成全景图。最后,可以将形成的全景图储存在主机14内,或是通过网络10传送到特
定云端系统,或是分享出去。
28.需要一提的是,图1所记载的实施例仅为拍摄全景影像的实施例的一个,并非用于限制揭露书所揭示的形成全景图的方法实施范围。
29.在揭露书提出的立体格局图产生系统,可以以上述主机14或是其他另外提供的主机执行立体格局图产生方法,主机设有一或多个处理器与储存器,储存器可储存由上述拍摄装置拍摄而取得涵盖空间的一或多张影像,一或多张影像为对应空间内的一或多个区域的全景图,一或多个处理器用以执行实现影像辨识的人工智能的一或多个深度学习方法,以执行立体格局图产生方法,在方法中,依据所取得一个空间的一或多张全景图产生立体格局图,可参考图2所示立体格局图产生方法的流程图。
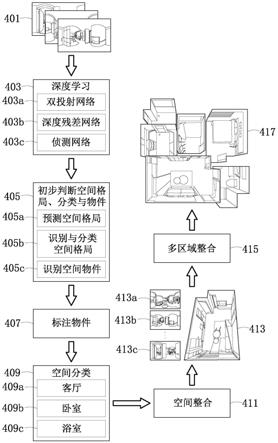
30.在此方法中,从特定数据库或是由上述实施例描述的拍摄装置取得涵盖一个空间的多张影像(步骤s201),这些影像为此空间内一或多个区域对应的全景图,特别以室内空间为例,接着是通过图像处理技术判断其中的格局,图像处理技术,如所提出立体格局图产生方法,采用了实现人工智能的深度学习方法,通过深度学习算法根据训练产生的模型(立体空间建模)辨识影像中的物件(步骤s203)。
31.接着,可通过软件程序进一步在影像中标记辨识得出的物件,例如可以文字或符号标示出全景图中辨识得到的桌子、椅子、门、窗、计算机、灯具等,且必要时进行人工校正(步骤s205),在深度学习的方法中,其中物件标记一旦经过人工或是特定方式校正后,将可用于修正人工智能中的影像识别参数,改善深度学习。
32.经辨识后的物件,通过数据库记载的查表可进一步分类物件(步骤s207),这是可以依据各种室内空间的属性分类物件,通过影像辨识技术以根据辨识物件,再根据每个区域中的物件属性辨识空间型态(type)(步骤s209)。举例来说,例如根据物件的型态判断此空间属于室内(有桌子、书本、计算机、窗子、门、墙、沙发等)或是室外(有树、花、草地、蓝天、阳光等);通过颜色、物件等辨识空间为书房(有书、计算机、台灯)、卧房(有床、没有计算机等)、客厅(有沙发、电视、音响等)、厨房(有锅子、水槽、瓦斯炉等)或是浴室(有浴缸、马桶等)。
33.之后,由于得出了各种物件的属性,表示也能因此估计出各物件的尺寸(dimension),使得通过图像处理技术可以判断出这些物件属性与物件在此区域内的空间关系估计出空间尺寸与格局(步骤s211),且进一步地,得出空间中的每个点,以对应到每张全景图的点,因此可以定位出这个点与线在空间的位置(步骤s213)。
34.如此,可以结合空间的各全景图的物件,依据各区域的点与线执行立体空间建模(modeling),形成一立体格局图(步骤s215)。
35.接着,以下描述图3显示的流程图,并配合图4以图示方法描述立体格局图产生方法的实施例流程。
36.一开始,系统取得输入影像(401,图4),例如从数据库或从全景摄影机拍摄取得一个空间内的多个区域的全景图(步骤s301),一个全景图对应一个区域,例如,一个房子内可能包括有客厅、一或多个卧室、一或多个浴室、厨房、餐厅等多个区域,每个区域依照装潢、摆设、家具等物件形成不同的型态(type)。其中用以辨识各影像中一或多个物件以及辨识各区域的空间型态的图像处理技术采用深度学习方法(403,图4),针对输入的影像进行特定演算过程(如卷积算法)取得影像特征,进而辨识各区域影像内各种物件(步骤s303)。
37.所述产生立体格局图的方法中的深度学习(deep learning)是机器学习的分支,是一种以人工神经网络为架构,对数据进行表征学习的算法,自动取得影像中足以代表影像特性的特征(feature),如图4显示,可以综合采用双投射网络(dula-net(dual-projection network))403a、深度残差网络(resnet(deep residual network))403b与侦测网络(detection network,detectnet)403c。
38.在双投射网络403a中,采用等距长方全景视图(equirectangular panorama view)与透视天花板视图(perspective ceiling view)等习知的立体影像展示技术,以能根据各区域的全景图预测各区域的一立体空间的格局。深度残差网络403b则是用于影像识别与分类,以快速地识别与分类各区域的格局。在侦测网络403c中,于分析各区域的全景图后,从影像中特征识别出各区域中该一或多个物件,并执行定位。
39.通过上述深度学习方法后,初步判断出空间格局、识别影像中物件,并分类物件(405,图4),深度学习得出的结果如图4所示,包括预测空间格局405a、识别与分类空间格局405b与识别空间物件405c。
40.之后,利用软件程序标记物件(步骤s305),根据上述物件辨识的结果在各区域的全景图中标记一或多个物件,在影像中形成标注物件(407,图4),若空间的其中的一个区域为一室内区域,由各全景图辨识的各物件可能为室内区域内的门、窗、墙、家具与摆设的其中的一个。之后,依照系统提出数据库事先的分类记载,可以根据各物件的属性分类物件(步骤s307),分类物件的目的的一个是用以辨识各区域的空间型态,也就是分别出多个区域(步骤s309),以及能够根据物件辨识各区域属性(步骤s311),其中采用的深度学习方法可根据辨识得出各区域的一或多个物件的属性辨识出各区域的空间型态。
41.同时,可以根据包括这些物件的空间进行分类(409,图4),依照图4显示的范例,经过深度学习所得出的物件属性还可继续将空间分类如客厅409a、卧室409b与厕所409c等,实际实施并不限于这些空间型态。当经过物件辨识而判断出各区域空间型态,还能进一步依照各种空间信息、物件属性而判断各区域尺寸、格局与型式(步骤s313)。
42.根据图4显示的流程,由于所提出的空间具有多个区域,各区域占有一定的空间比例,且依照各空间中物件关系可以判断多个区域之间连接关系(步骤s315),并以影像识别技术,依照各全景图的物件特性,如门、窗、天花板与墙壁,加上可辨识的角落、转角与物件,可以用以定位空间中各区域的点与线,得出点与线在各区域的位置,并可在影像上产生定位使用的点与线(步骤s317)。
43.其他定位技术还包括,可在各区域中设有一参考点,使得各区域内的点与此参考点之间具有一角度与一距离关系,使得各区域内多个点之间具有角度与距离的一相对关系,成为结合多个区域时的依据,也就是依据各区域内多个点的相对关系形成立体格局图。其中采用的即空间整合(411,图4)技术。
44.举例来说,空间整合技术如一种单一空间整合器(single room integrator),用于判断出空间中不同区域之间的连接关系,其中方法例如通过上述标注物件,如门(或窗),若有两个区域都标注有同一个门(或窗),加上各区域边界(boundary)的判断,可以判断出同一个门连结的两个邻接的房间,例如客厅、卧房与浴室以相同的门、窗连接。
45.上述得出各点之间相对关系的方式可采用一种图像映射技术(image correspondence),经设定参考点后,可得出每个点与空间中的参考点的相对位置,以得出
一个空间内每个点对应参考点的角度,之后经过识别出的边界、点,并配合每个区域的属性,拼接多张影像后得出整个空间的立体格局图(步骤s319,图4的413),如图4显示分别得出客厅格局413a、卧室格局413b以及厕所格局413c,执行多区域整合(415,图4),形成全局立体格局图(417,图4),也就是根据上述空间中多个区域之间的边界,以及配合各区域中的物件与空间型态得出多个区域之间的连接关系,加上各区域尺寸、格局,以及各全景图的一或多个物件,依据各区域的点与线形成一立体格局图(步骤s321)。
46.在执行多区域整合时,也就是拼接过程中,匹配空间中每个区域中有共同属性的物件,经排列组合外,判断出合理性(如可以根据这个空间的文化背景、种族、类型进行拼接出的结果的合理性判断),产生最合理的组合,形成一个全局的立体格局图。
47.当得出各区域的立体格局图,系统将这些影像信息储存在主机中,使得日后有使用者操作浏览时,可以这些立体格局图呈现内容,例如,当使用者选择了某个观察位置,系统即判断对应这个观察位置,得出在此观察位置的空间上的每个点与线形成的全景图,调入对应的全景图提供使用者在此观察位置的空间影像。
48.使用深度学习方法执行的立体格局图产生方法可以参考以下实施例的描述,其中采用的深度学习方法的个别算法为揭露书所揭示发明领域中已知技术,而为相关领域技术人员可理解而可据以实施的深度学习方法,然而,揭露书所提出的立体格局图的方法即利用这些已知方法达成原来各深度学习方法无法预期的技术目的。
49.图5描述双投射网络(dual-projection network,dula-net)的深度学习方法流程,其中并同时利用了图6描述的深度残差网络的深度学习方法。
50.双投射网络为一种深度学习架构(deep learning framework),用以根据单一全彩全景图(rgb panorama)预测一个立体空间的格局(3d room layout),其中,为了要得到更佳的预测准确性(prediction accuracy),可先得出两个预测结果,例如一为等距长方全景视图(equirectangular panorama-view),另一为透视天花板视图(perspective ceiling view),每个预测得出的全景视图分别包括空间格局(room layout)的不同线索,使得得到更为准确的预测空间格局。其结果还能在深度学习中用于训练预测平面图与格局的用途,若要学习更复杂的空间格局,还可引入其他包括有不同角落(corner)的空间格局的立体数据。
51.如图所示,在双投射网络的深度学习方法中,采用了两个图像处理技术,在等距长方全景视图的应用中,先输入一个空间内特定区域的全景图(501),通过特征撷取(503)得到等距长方全景视图,其中特征撷取(503)的步骤利用了深度残差网络的深度学习方法,用以识别与分类出影像中的空间格局,形成全景机率概图(505)。另一方面,在透视天花板视图的应用中,先取得所述区域的天花板视图(502),同样在特征撷取(504)可采用深度残差网络的深度学习方法,用以识别与分类出影像中的关于天花板的空间特征,形成平面机率概图(506)。之后,双投射网络的深度学习方法进一步结合全景机率概图(505)与平面机率概图(506),根据两个概图的影像信息,经过一个平面图的拟合过程(floor plan fitting),形成一个二维平面图(2d floor plan)(507),并经立体空间建模后预测区域的立体空间格局(508)。之后的流程即继续对空间内其他区域演算产生例体格局图,再通过如图4的流程得到各区域点、线、多个区域之间的连接关系,建立一全局的立体格局图。
52.图6描述深度残差网络(deep residual network,resnet)的深度学习方法流程。
53.深度残差网络的深度学习方法为一种用于影像识别与分类用的深度学习方法,特色在于可快速收敛深度学习的误差,也使得可以实现更深层的学习、提高准确度,使得有效而快速地识别(recognition)与分类(classification)空间格局。
54.如示意图所示,先取得空间内各区域的全景图601,图中示意表示有客厅、浴室与卧室的全景图,之后经过深度残差网络603的演算,包括图像处理631与识别与分类632等深度学习过程,利用深度学习从大数据建立描述各种空间型态的数据集(data set),例如,数据集分别记载了描述一个室内空间的浴室、卧室、餐厅、厨房与客厅等区域的数据,此例中,最后依照深度学习得到的数据集的数据判断出各区域为客厅605a、浴室605b与卧室605c等格局。
55.图7a与7b显示侦测网络(detection network,detectnet)的深度学习成果的示意图。
56.图7a显示一个在某一区域内单一视角的全景图,通过侦测网络的深度学习后,可得出区域内的各种物件,并可在全景图中标记出来,如
57.图7b所示的物件一701、物件二702、物件三703、物件四704、物件五705与物件六706等,例如分析单一全景图后,从影像中特征识别出空间中各种物件的轮廓与位置,如门、窗、隔墙、桌、椅等,并执行定位。
58.接着,可以继续输入相同区域内的另一视角的全景图,同样地,能够辨识而标记出其中的物件一701、物件二702、物件三703、物件四704、物件五705与物件六706,因此可以根据多个物件的标记判断出不同视角的全景图的相互关系,建立包括多个视角的立体格局图,使得系统可以根据使用者选择的视角提供对应的立体格局图,还包括涵盖多个空间、多个视角的全局的立体格局图。
59.图8显示利用深度学习识别场景的实施例示意图。
60.图中显示有一区域800,通过上述各深度学习方法得出各区域的立体格局图,识别与定位其中物件,加上形成相同区域内不同视角的多个立体格局图,形成图标中区域800可辨识的物件识别场景一801、物件识别场景二802与物件识别场景三803,通过空间整合(integration,411,图4),得出区域的立体格局图,例如得出客厅格局(413a,图4)、卧室格局(413b,图4)与浴室格局(413c,图4)等。
61.接着,如图9所示在二维平面图中定位区域的实施例示意图,其中显示有二维平面图转立体格局图的示意图91,即先于二维平面图上根据上述得出的各区域型态,依照于各全景图中定位空间中各区域的点与线,结合空间的各全景图的物件,经定位并标示后,结合各区域格局图,产生所述二维平面图转立体格局图的示意图91,示意图显示空间中多个区域如客厅92、浴室93与卧室94。
62.经过立体空间建模,其中持续依照上述多个空间的物件特征、标注物件与连接关系寻求一致性,结合多个区域的立体格局图,形成图10所示立体格局图前建立立体模型的实施例示意图,最终形成全局的立体格局图(417,图4)。
63.综上所述,根据上述实施例描述利用深度学习方法通过物件识别、定位、空间型态辨识、立体建模等技术,建立一个空间的各区域立体格局图,进而形成全局的立体格局图,以完成多视角的立体格局图,过程中持续通过校正与学习,不断地优化深度学习的能力。之后可应用于虚拟现实的观测应用,提供使用者在一个空间内走动,相关系统能够依据使用
者的视角提供对应的立体格局图。
64.以上所公开的内容仅为本发明的优选可行实施例,并非因此局限本发明的申请专利范围,所以凡是运用本发明说明书及图式内容所做的等效技术变化,均包含于本发明的申请专利范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1