基于生成式对抗网络模型书法字帖评价系统及方法与流程
本发明涉及图像处理技术领域,具体为一种基于生成式对抗网络模型书法字帖评价系统及方法。
背景技术:
汉字亦称中文字、中国字、国字,属于表意文字的词素音节文字,由汉人发明并改进,是世界上最古老的四大自源文字(两河流域的楔形文字、古埃及的圣书字、中国商朝甲骨文、玛雅文字)中唯一沿用至今的文字。
汉字是中国迄今为止连续使用时间最长的主要文字,中国历代皆以汉字为主要官方文字。隶变是汉字发展史上的一个里程碑,汉字发展至汉朝隶书时被取名为“汉字”。
书法,是中国及深受中国文化影响过的周边国家和地区特有的一种文字美的艺术表现形式。包括汉字书法、蒙古文书法、阿拉伯书法和英文书法等。其"中国书法",是中国汉字特有的一种传统艺术。
从广义讲,书法是指文字符号的书写法则。换言之,书法是指按照文字特点及其含义,以其书体笔法、结构和章法书写,使之成为富有美感的艺术作品。汉字书法为汉族独创的表现艺术,被誉为:无言的诗,无行的舞;无图的画,无声的乐等。
技术实现要素:
本发明的目的是:针对现有技术中因人工主观性的影响,导致对书写质量评价准确性低的问题,提出一种基于生成式对抗网络模型书法字帖评价系统及方法。
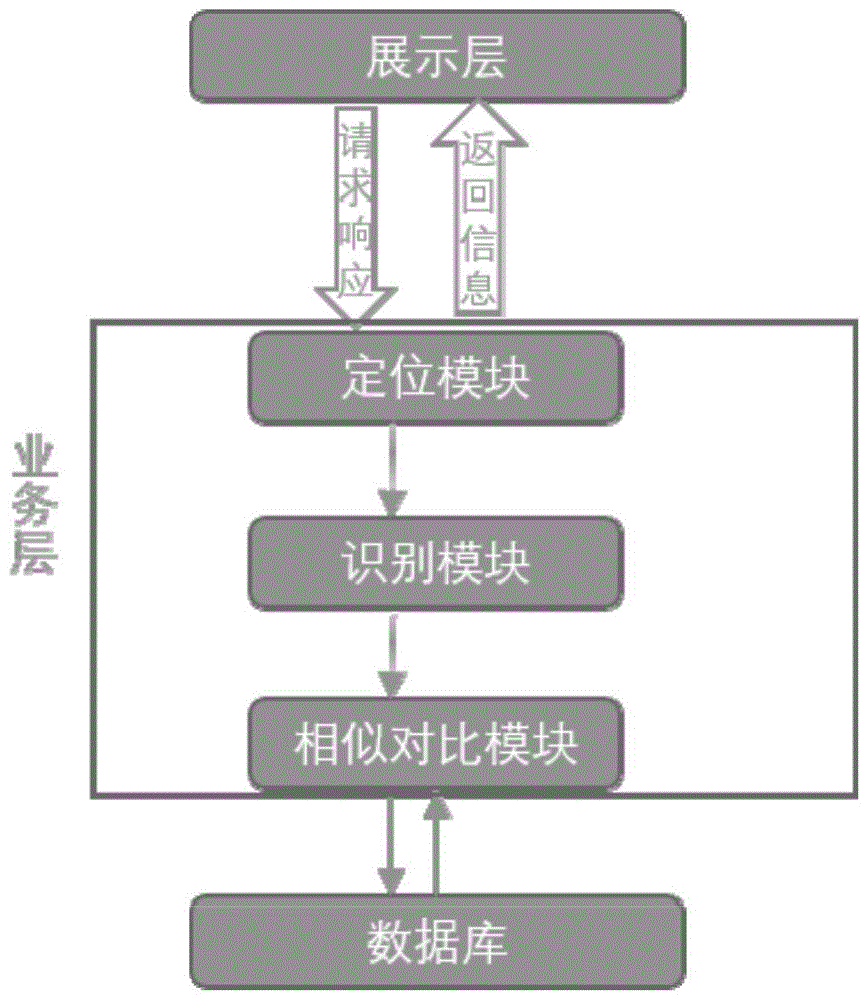
本发明为了解决上述技术问题采取的技术方案是:基于生成式对抗网络模型书法字帖评价系统,包括展示层、业务层和数据库,所述展示层用于用户交互;
所述业务层包括定位模块、识别模块和相似对比模块,所述定位模块根据用户所上传的字帖图像进行文本框定位,然后传给识别模块,所述识别模块利用定位模块所定位的文本框的位置并通过inception-v3网络框架进行文字识别,选择概率最大的文字输出文字的索引,所述相似对比模块依据识别模块输出的索引在数据库中找到相对应的文字进行相似对比;
所述数据库用于存放文字信息数据。
基于生成式对抗网络模型书法字帖评价方法,包括以下步骤:
步骤一:将图像进行预处理,得到固定大小的图片;
步骤二:利用darknet-53网络模型得到三种不同大小的特征图;
步骤三:选择和真实目标的具有最大交并比的anchorbox进行预测,得到预测坐标;
步骤四:利用inception-v3对字帖中目标定位后的文字进行识别;
步骤五:利用inception-v3的瓶颈层进行特征向量提取,并计算两个特征向量的距离损失,根据距离损失,并引入排名机制得到最终评价。
进一步的,所述步骤一中预处理包括去噪和裁剪。
进一步的,所述步骤三的详细步骤为:首先将每种特征图都划分为小网格,每种特征图对应三种不同大小的anchorbox,由物体中心对应的网格进行预测,选择和真实目标具有最大交并比的anchorbox进行预测,然后通过nms筛选重叠预测框,最后以张量形式得到整张图的文本框的预测坐标。
进一步的,所述步骤三中还包括使用yolo-v3网络的步骤。
进一步的,所述步骤四的具体步骤为:首先利用网络中的瓶颈层进行训练,并将最后的激活函数softmax的节点个数修改为文字的个数。
进一步的,所述步骤四的具体步骤为:首先利用网络中的瓶颈层进行训练,并将最后的激活函数softmax的节点个数修改为文字的个数。
进一步的,所述距离损失通过欧式距离计算。
本发明的有益效果是:本发明采用神经网络对书法字帖进行处理,从而对书写质量进行评价,本发明减少了人为的参与,提高了书写质量评价的准确性。
附图说明
图1为系统构架图。
图2为darknet-53网络框架图。
图3为darknet-53网络结构说明图。
图4为预测输出图。
图5为误差损失示意图。
图6为检测结果示意图。
图7为inception-v3网络架构图。
图8为inception-v3分支结构图。
图9为inception-v3模型示意图。
图10为具体实施例数据图。
具体实施方式
具体实施方式一:参照图具体说明本实施方式,本实施方式所述的基于生成式对抗网络模型书法字帖评价系统,包括展示层、业务层和数据库,所述展示层用于用户交互;
所述业务层包括定位模块、识别模块和相似对比模块,所述定位模块根据用户所上传的字帖图像进行文本框定位,然后传给识别模块,所述识别模块利用定位模块所定位的文本框的位置并通过inception-v3网络框架进行文字识别,选择概率最大的文字输出文字的索引,所述相似对比模块依据识别模块输出的索引在数据库中找到相对应的文字进行相似对比;
所述数据库用于存放文字信息数据。
展示层:系统前台,项目中的所用载体为微信小程序。其中包括的主要功能有评分功能、得分记录等。
业务层:业务层分为三个模块。定位模块根据用户所拍照上传的字帖照片进行文本框的定位,并传给识别模块进行调用;识别模块利用定位模块所定位的文本框的位置,通过inception-v3网络框架进行文字识别,选择概率最大的文字输出文字的索引;相似度对比模块主要依据识别模块所输出的索引号在数据库中找到相对应的文字进行相似性对比,从而进行评分。
数据库:最底层为数据库,存储着小学生所要掌握的标准文字以及各种结构表,结构表用于存放用户的各种信息。如图2所示。
目标定位是计算机视觉领域对于目标检测方向的实际应用。项目采用yolov3目标检测方法,yolov3目标检测方法是yolov1和yolov2方法的改进版,是目前计算机视觉目标检测领域时效性和准确性综合效率最高的目标检测方法。
文字定位采用yolov3方法,它采用了darknet-53网络框架,利用深度学习的卷积技术通过对大量的数据集的标注和训练实现对于字帖中每个文本框的坐标定位。如图2所示。
首先将图像进行预处理得到固定大小的图片,然后利用darknet-53网络模型得到三种不同大小的特征图。
在darknet-53网络结构中,利用残差网络技术来加速损失熵的收敛,防止出现梯度消失问题;利用batchnormalization(批次归一化)使得数据处于同一分布,避免出现过拟合问题;利用上采样技术使得顶层网络与上一层的网络进行连接,从而得到三种不同大小的特征图,使得能够更加精准的识别每一个文本框。如图3所示。
然后对三种不同的特征图进行预测处理。将每种特征图都划分为小网格,物体中心落在哪个网格就由哪个网格进行预测。最后通过nms(非极大值抑制,non-maximumsuppresion)筛选重叠预测框,最终以张量形式得到整张图的文本框的预测坐标。
为了避免出现模型的不稳定,模型预测的是边界框中心点相对于对应网格左上角位置的相对偏移值(tx,ty),以及tw,th。为了将边界框中心点约束在当前网格,使用sigmoid函数处理偏移值。若物体中心点所对应的网格左上角的顶点坐标为(cx,cy),anchorbox所对应的width为pw,high为ph,则所对应的最终预测结果bx,by,bw,bh如图4所示。
yolo-v3的损失函数采用平方和误差损失。通过对坐标损失(有目标)、类别损失、目标损失(有目标和没有目标)通过adam目标优化算法进行梯度更新,从而使梯度下降,达到目标精确的效果。如图5所示。
通过大量数据集的训练以及超参数的调试,检测结果如图6所示。
利用inception-v3网络架构,将最后一层的卷积层后面添加全连接层,训练过程中利用dropout技术,并将最后的激活函数softmax的节点个数修改为小学生文字的个数,实现对字帖中目标定位所得到的每个文字的识别。如图7所示。
inception-v3是对inception-v1网络结构和inception-v2网络结构的改进。利用n×1卷积后接1×n卷积来代替n×n卷积核,在不影响优化效果的前提下,节约了大量参数,从而加快运行速度并减轻过拟合。项目训练过程中,利用定位模块大量训练图片,并将训练好的模型进行冻结用于测试。应用过程中把定位模块输出的每个边界框的坐标作为输入,利用inception-v3网络框架进行特征处理并进行全局平均化,使得每个汉字最后通过softmax激活函数输出节点,每个节点对应着每个小学生文字的概率,选择最大概率的文字作为索要识别的文字,将其所对应的索引号进行输出。如图8所示。
相似性计算主要依据识别模块文字索引找到数据库中的标准文字进行相似性对比,从而进行打分。本算法可以将打分问题简化成传入的手写汉字数据与标准字数据的相似程度的量化。通多对欧氏距离、曼哈顿距离、余弦相似度等多种相似性计算方法对比,采用cnn网络框架提取特征特征向量,利用相似度距离算法进行距离计算,并引入打分机制进行相似度计算。如图9所示。
通过对欧氏距离、曼哈顿距离、切比雪夫距离等距离算法的试验比较,采用欧氏距离进行相似度计算,并引入排名机制,其优点是更加符合现实中人们的打分标准。
此算法通过将所要识别文字和数据库文字利用inceptionv3的瓶颈层进行特征向量提取,并利用欧式距离计算两个特征向量的距离损失,引入排名机制,每一个手写汉字加入到字库中所对应的文字列表中并进行重新排序,将图片的距离损失在所有该字上的距离的排名位置加上基础分数最终得到这个字的打分结果。一张字帖上包含多组手写汉字,最终字帖的得分就是所有手写汉字得分的平均值,最后将结果返回给用户。
需要注意的是,具体实施方式仅仅是对本发明技术方案的解释和说明,不能以此限定权利保护范围。凡根据本发明权利要求书和说明书所做的仅仅是局部改变的,仍应落入本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!