一种界面元素的自动分段截图方法及系统与流程
本申请涉及电子技术领域,尤其涉及一种界面元素的自动分段截图方法及系统。
背景技术:
目前随着人工智能的普及,图像识别技术的应用也越来越广泛。我们可以在图片中提取文字、识别车牌、识别非法内容等。但是目前ai识别技术的精准程度相对依赖图片源,比如说ocr文字识别就无法在整张截图中精准提取某一部分文字,而会把整屏的文字都识别出来,造成结果不可用的问题。同时整张图片识别必然会降低ai识别的精准程度。
目前,对图片进行切片分段的ai处理方法存在以下缺点:
1、对需要准确识别屏幕中一部分内容的需求,没有办法满足,整屏识别将造成结果混乱;
2、没有充分高效地利用ai识别,不对图片进行切片分段的识别,没有能够充分利用ai识别的优势,降低了ai识别的准确性;
3、消耗更多的ai识别资源以及时间,不对图片进行切片分段,会掺杂着大量无用的信息,增加ai识别服务的压力同时还需要消耗更多的时间来识别;
4、截图、对图片进行切片分段、识别这样的流程需要手工完成,时间成本高,效率低。
技术实现要素:
本发明提供了一种界面元素的自动分段截图方法及系统,用以解决现有技术中截图、对图片进行切片分段、识别这样的流程需要手工完成,时间成本高,效率低的问题。
其具体的技术方案如下:
一种界面元素的自动分段截图方法,所述方法包括:
在开启辅助服务时,获取至少一个控件的识别参数,并执行屏幕的截图分段,得到截图图片,所述识别参数为所述控件的标识信息;
获取所述屏幕中的所有控件的信息;
根据所述控件的识别参数,获取对应控件的快照信息;
根据所述截图图片,裁剪出控件范围的图像;
根据所述快照信息以及所述图像,得到分段后的结果集合,并将所述结果集合发送至调用方。
具体的,获取所述屏幕中的所有控件的信息,包括:
通过辅助服务中的定义方式遍历控件树,确定目标控件;
根据所述目标控件,确定所述目标控件在所述屏幕中的矩形顶点坐标;
保存各个控件对应的坐标以及标识,得到所述控件的信息。
具体的,获取所述屏幕中的所有控件的信息,包括:
加载源截图文件;
在所述快照信息中取出带分段的控件的位置信息;
在所述源截图文件中,按照所述控件的位置信息裁剪出矩形范围的图像。
具体的,所述方法还包括:
检测操作流程是否完成;
在检测到操作流程完成时,执行结束,并释放资源。
一种界面元素的自动分段截图系统,所述系统包括:
获取模块,用于在开启辅助服务时,获取至少一个控件的识别参数,并执行屏幕的截图分段,得到截图图片,所述识别参数为所述控件的标识信息;
处理模块,用于获取所述屏幕中的所有控件的信息;根据所述控件的识别参数,获取对应控件的快照信息;根据所述截图图片,裁剪出控件范围的图像;根据所述快照信息以及所述图像,得到分段后的结果集合,并将所述结果集合发送至调用方。
具体的,所述获取模块,具体用于通过辅助服务中的定义方式遍历控件树,确定目标控件;根据所述目标控件,确定所述目标控件在所述屏幕中的矩形顶点坐标;保存各个控件对应的坐标以及标识,得到所述控件的信息。
具体的,所述处理模块,具体用于加载源截图文件;在所述快照信息中取出带分段的控件的位置信息;在所述源截图文件中,按照所述控件的位置信息裁剪出矩形范围的图像。
具体的,所述处理模块,还用于检测操作流程是否完成;在检测到操作流程完成时,执行结束,并释放资源。
通过本发明所提供的方法至少具有如下技术效果:
1、通过本发明所提供的方法,将方案集成到手机端的rpa系统后,实现了手机端或者移动终端的自动化信息采集功能;
2、通过将本发明所提供的方法集成到企业内部运营系统中,实现了自动验收运营任务工单的功能,自动化截屏、分段、识别即可验证企业内员工是否完成运营任务的效果,节省了大量人力验证运营任务的工作量,提高了企业云运营效率;
3、通过使用截图分段识别方式对内容进行识别,比普通的识别准确率有质的提高,同时减少了脏数据的产生,并提高了ai系统中的识别效率,降低乐ai服务的资源消耗。
附图说明
图1为本发明实施例中一种界面元素的自动分段截图方法的流程图;
图2为本发明实施例中界面元素的自动分段截图原理执行流程图;
图3为本发明实施例中自动分段截图系统的系统架构示意图;
图4为本发明实施例中截图结果示意图之一;
图5为本发明实施例中截图结果示意图之二;
图6为本发明实施例中一种界面元素的自动分段截图系统的结构示意图。
具体实施方式
下面通过附图以及具体实施例对本发明技术方案做详细的说明,应当理解,本发明实施例以及实施例中的具体技术特征只是对本发明技术方案的说明,而不是限定,在不冲突的情况下,本发明实施例以及实施例中的具体技术特征可以相互组合。
首先来讲,在本发明实施例中,通过对安卓操作系统的“辅助服务”编程接口进行封装,使用安卓系统截屏接口进行截屏时,对屏幕中的控件进行快照,提供了按照控件信息进行分段切片,提供调用接口给外部系统如rpa、图像识别、图像处理等系统,外部系统调用本方法,即可取得分段好的图片的一体化方案,具体实现原理如下:
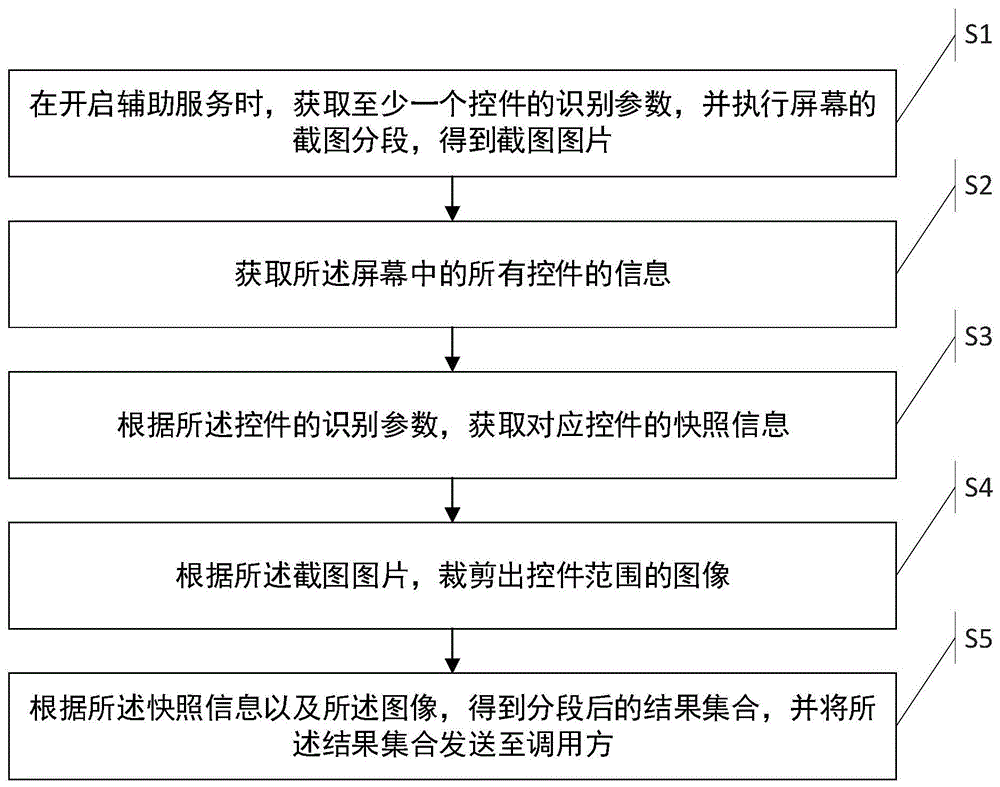
如图1所示为本发明实施例中一种界面元素的自动分段截图方法的流程图,该方法包括:
s1,在开启辅助服务时,获取至少一个控件的识别参数,并执行屏幕的截图分段,得到截图图片;
s2,获取所述屏幕中的所有控件的信息;
s3,根据所述控件的识别参数,获取对应控件的快照信息;
s4,根据所述截图图片,裁剪出控件范围的图像;
s5,根据所述快照信息以及所述图像,得到分段后的结果集合,并将所述结果集合发送至调用方。
首先来讲,本发明所提供的方法可以应用到一种安卓手机上按照界面元素自动分段截图的场景中,使用安卓操作系统提供的“辅助服务(accessibilityservice)”编程接口,封装了可供用户抓取屏幕控件快照信息的方法,并实现了使用安卓操作系统提供的截图编程接口对界面进行截屏的方法。本系统整合这两个方法,实现了自动化截屏、使用快照信息对图片进行分段切片处理。同时提供截屏、分段的api接口给外部系统如图像识别、图像处理、rpa等外部系统调用,在丰富的应用场景下都可对图像进行精准处理,在本系统中称为“截图分段api”,该方法的具体详细实现原理如图2所示,在图2中包含了信息采集、截图分段api、外部系统三个模块,基于该三个模块的具体实现原理如下:
步骤一:确定安卓手机中的accessibilityservice功能已经开启;
步骤二:api调用方调用调用截图分段api中的“开始截屏分段”方法,根据实际的使用场景,传入需要进行分段操作的单个或多个控件的识别参数,这里的识别参数可以但不限定是id、文字、控件类名,然后开始自动进行截图分段;
步骤三:截图分段api调用android操作系统的截屏功能进行截屏,截屏的同时,截图分段api会自动使用accessibilityservice编程接口中的方法,实现对屏幕中所有控件的信息获取,具体的原理如下:
1)、使用accessibilityservice中的findaccessibilitynodeinfosbyviewid或findaccessibilitynodeinfosbytext方法或自定义方法遍历控件树,取得目标控件;
2)、目标控件调用getboundsinscreen取得在屏幕中的矩形顶点坐标;
3)、保存各控件对应的坐标、id等信息生成快照。
步骤四:截图分段api根据传入的控件识别参数,取得该控件的快照信息,同时结合截图的图片,裁剪出该控件范围的图像,分段的原理如下:
1)、加载源截图文件;
2)、在快照中取出需要分段的控件的位置信息;
3)、在源截图文件中,再按照该控件的位置信息裁剪出该矩形范围的图像,保存为分段好的文件;
步骤五:截图分段api取得分段后的结果集;
步骤六:截图分段api把分段结果集返回到调用方。例如:手机端rpa系统、图像识别系统、图像处理系统等;
步骤七:调用方(rpa、图像识别、图像处理等系统)对分段后图像进行个性化处理;
步骤八:释放相关资源,完成单次api的调用操作。
下面通过具体的应用场景对本发明技术方案做进一步的说明:
示例1:
首先,如图3所示为实现本发明方法所对应的系统架构,基于该系统架构以及具体的实现方法,该示例1的具体实现原理如下:
步骤一:打开安卓手机中的accessibilityservice功能
步骤二:打开新浪微博,并任意打开一篇微博详情,ocr图像识别系统,调用截图分段api提供中的“开始截屏分段”方法,传入需要分段的控件id(新浪微博的内容id为:com.sina.weibo:id/tweet_message)。
步骤三:截图分段api开始自动截屏,同时使用accessibilityservice中的编程接口,保存微博详情界面上内容控件的快照信息。
步骤四:截图分段api根据上述传入内容控件的id,取得其快照信息,同时结合截图的图片,裁剪出该控件范围的图像。
步骤五:取得切片后的结果集,即:分段后图片的路径信息。
步骤六:截图分段api把分段结果集返回到ocr图像识别系统。
步骤七:ocr图像识别系统开始识别分段后的图像,并准确识别该范围的文本内容,具体截图结果如图4所示。
步骤八:截图分段api释放相关资源,完成本次api调用操作。
示例2:
步骤一:打开安卓手机中的accessibilityservice功能。
步骤二:rpa系统自动打开新浪微博,并自动打开需要验收运营任务的微博详情,同时自动调用截图分段api的“开始截屏分段”方法,传入新浪微博的评论用户昵称id(com.sina.weibo:id/tvitemcmtnickname)、评论内容id(com.sina.weibo:id/tvitemcmtcontent)。
步骤三:截图分段api开始自动截屏,同时使用accessibilityservice中的编程接口,保存微博详情界面上内容控件的快照信息。
步骤四:截图分段api根据上述传入内容控件的id,取得其快照信息,同时结合截图的图片,裁剪出该控件范围的图像。
步骤五:取得切片后的结果集(即分段后图片的路径信息)。
步骤六:截图分段api把分段结果集返回到rpa系统。
步骤七:rpa系统自动调用ocr图像识别系统开始识别分段后的图像,并准确识别该用户的昵称以及评论内容,实现验证某一用户是否在某一微博下评论的效果,实现自动化验收运营任务工单,具体截图结果如图5所示。
步骤八:截图分段api释放相关资源,完成本次api调用操作。
通过本发明所提供的方法,至少具有如下技术效果:
1、通过本发明所提供的方法,将方案集成到手机端的rpa系统后,实现了手机端或者移动终端的自动化信息采集功能;
2、通过将本发明所提供的方法集成到企业内部运营系统中,实现了自动验收运营任务工单的功能,自动化截屏、分段、识别即可验证企业内员工是否完成运营任务的效果,节省了大量人力验证运营任务的工作量,提高了企业云运营效率;
3、通过使用截图分段识别方式对内容进行识别,比普通的识别准确率有质的提高,同时减少了脏数据的产生,并提高了ai系统中的识别效率,降低乐ai服务的资源消耗。
对应本发明所提供的方法,本发明实施例中还提供了一种界面元素的自动分段截图系统,如图6所示为本发明实施例中一种界面元素的自动分段截图系统的结构示意图,该系统包括:
获取模块601,用于在开启辅助服务时,获取至少一个控件的识别参数,并执行屏幕的截图分段,得到截图图片,所述识别参数为所述控件的标识信息;
处理模块602,用于获取所述屏幕中的所有控件的信息;根据所述控件的识别参数,获取对应控件的快照信息;根据所述截图图片,裁剪出控件范围的图像;根据所述快照信息以及所述图像,得到分段后的结果集合,并将所述结果集合发送至调用方。
进一步,在本发明实施例中,所述获取模块601,具体用于通过辅助服务中的定义方式遍历控件树,确定目标控件;根据所述目标控件,确定所述目标控件在所述屏幕中的矩形顶点坐标;保存各个控件对应的坐标以及标识,得到所述控件的信息。
进一步,在本发明实施例中,所述处理模块602,具体用于加载源截图文件;在所述快照信息中取出带分段的控件的位置信息;在所述源截图文件中,按照所述控件的位置信息裁剪出矩形范围的图像。
进一步,在本发明实施例中,所述处理模块60,还用于检测操作流程是否完成;在检测到操作流程完成时,执行结束,并释放资源。
尽管已描述了本申请的优选实施例,但本领域内的普通技术人员一旦得知了基本创造性概念,则可对这些实施例作出另外的变更和修改。所以,所附权利要求意欲解释为包括优选实施例以及落入本申请范围的所有变更和修改,包括采用特定符号、标记确定顶点等变更方式。
显然,本领域的技术人员可以对本申请进行各种改动和变型而不脱离本申请的精神和范围。这样,倘若本申请的这些修改和变型属于本申请权利要求及其等同技术的范围之内,则本申请也意图包含这些改动和变型在内。
- 还没有人留言评论。精彩留言会获得点赞!