一种基于联合熵尺度加权和正则块对角的鲁棒多核子空间聚类算法
1.本发明设计数据挖掘领域,特别是基于非线性核子空间聚类的高精度和鲁棒性的一种基于联合熵尺度加权和正则块对角的鲁棒多核子空间聚类算法。
背景技术:
2.随着大数据智能化时代来临,大规模高维数据在社会、经济、工程等领域越来越普遍。大规模高维数据不仅增加了数据存储的需求,也使得数据分析更加复杂,以此引发了一系列相关学科与技术的高速发展。
3.子空间学习是行业中极具挑战和热门的方向,在数据挖掘和机器学习中起着至关重要的作用,特别是多个潜在子空间之间有相交性的情形。目前行业内研究子空间学习问题比较常见的且有效的是自表达方法,这类方法基本上将每个样本向量表示为其他向量的线性组合,因为子空间的属性特点,表示向量之间具有比较明显的子空间属性,再将谱聚类方法用于由自表达矩阵对称非负化得到的关系矩阵,就可以得到具有一定的子空间属性的聚类方式,进而由聚类得到样本点,估计相应的子空间。子空间聚类的关键点就是求解表达系数矩阵z,而其不足是z与图谱聚类的拉普拉斯矩阵l是两个分开的过程,相互之间不能联系。
4.近年来,基于非线性核的子空间聚类方法通过揭示样本的非线性结构来提高聚类性能,得到了广泛的关注,很多子空间聚类方法得以提出。但是,现有的内核子空间聚类存在以下三个缺点:一是聚类性能高度依赖所选择的核函数,二是对非高斯噪声不具备鲁棒性,三是得到的亲和矩阵不满足聚类必须的块对角属性。因此,急需一种具有更佳精度和鲁棒性的子空间聚类算法。
技术实现要素:
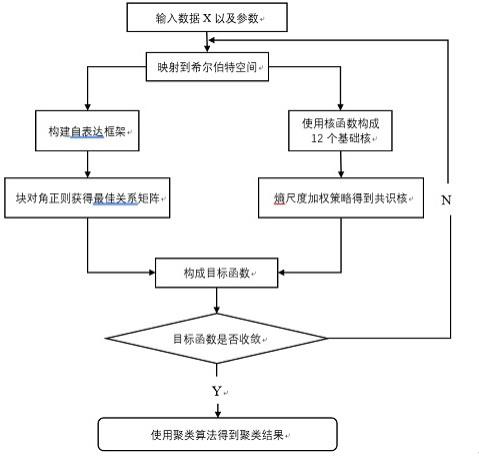
5.有鉴于此,本发明的目的在于克服现有技术的不足,提供一种提高计算结果精度和鲁棒性的一种基于联合熵尺度加权和正则块对角的鲁棒多核子空间聚类算法,所述方法包括以下步骤:1、一种基于联合熵尺度加权和块对角正则的鲁棒多核子空间聚类算法,其特征在于:所述方法包括以下步骤:s100、预处理图像,得到输入矩阵x。
6.s200、根据先验知识,输入目标函数的权衡参数α、β、γ,阈值,同时输入已知类数值k。
7.s300、引用12种核函数对输入矩阵进行映射到希尔伯特空间,得到多个核矩阵h
i
,构成核池。
8.s400、初始化:初始化矩阵s1=0,a1=0,z1=0,h1、w1,令迭代统计变量t=1,最大迭代次数t
max
=1000。
9.s500、利用下式,更新z: 。
10.s600、利用下式,更新s:引入的度矩阵为最优。其中,d是具有对角元素{
jj
}的对角矩阵。
11.s700、利用下式,更新a:其中,,。
12.s800、利用下式,更新h: 。
13.s900、利用下式,更新w:。
14.s1000、获得z、s、a、h、w获得目标函数。
15.s1100、判断目标函数是否收敛,若不收敛,则跳转到s500,若收敛,则进行到下一步,判断收敛算法如下式:其中是第次迭代的目标函数的值,是停止阈值。
16.s1200、使用谱聚类算法,输出聚类结果。
17.本发明的有益效果是:1、由于本发明提出了一种用于子空间聚类的鲁棒多核方法。该方法从预定义的核池中自适应地学习最优的共识核来解决寻找合适的单核难题,优化处理非线性结构的数据,与现有的单核和多核方法相比,获得了更可靠的聚类结果;2、由于本发明引入bdr,使得到的再生核希尔伯特征空间中的数据点具有自表达性,得到的关系矩阵具有最优的块对角结构;3、本发明利用熵尺度加权的方法从12个基核中学习得到一个共识核,提高算法对非高斯噪声的鲁棒性。
18.附图说明
19.图1是本发明的一个实施例流程框图。
20.图2和图3是是本公开发明的实际案例结果评估数据。
具体实施方式
21.为使本发明的目的、技术方案和优点更加清楚,下面将对本发明的技术方案进行详细的描述。显然,所描述的实施例仅仅是本发明一部分实施例,而不是全面的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动的前提下所得到的所有其它实施方式,都属于本发明所保护的范围。
22.在一个实施例中,结合附图1,本发明揭示了一种基于联合熵尺度加权和块对角正则的鲁棒多核子空间聚类算法,其特征在于:所述方法包括以下步骤:s100、预处理图像,得到输入矩阵x;s200、根据先验知识,输入目标函数的权衡参数α、β、γ,阈值,同时输入已知类数值k;s300、引用12种核函数对输入矩阵进行映射到希尔伯特空间,得到多个核矩阵h
i
,构成核池;s400、初始化:初始化矩阵s1=0,a1=0,z1=0,h1、w1,令迭代统计变量t=1,设置最大迭代次数t
max
;s500、利用下式,更新z:;s600、利用下式,更新s:引入的度矩阵为最优。其中,d是具有对角元素{
jj
}的对角矩阵;s700、利用下式,更新a:其中,,;s800、利用下式,更新h:;s900、利用下式,更新w:;s1000、获得z、s、a、h、w获得目标函数;s1100、判断目标函数是否收敛,若不收敛,则跳转到s500,若收敛,则进行到下一步,判断收敛算法如下式:其中是第次迭代的目标函数的值,是停止阈值;s1200、使用谱聚类算法,输出聚类结果。
23.在一个实施例中,所述步骤s100具体包括以下步骤:s1001、输入n张图片;s1002、针对每张图片进行roi处理,提取特征,得到n张h
×
w数据;s1003、对每张图片向量化,构成(h
×
w)
×
1列向量;s1004、将n张图片按列向量顺序排列,得到(h
×
w)
×
n输入矩阵x。
24.在一个实施例中,所述步骤s300具体包括以下步骤:s3001、引入常见的12种核函数,包含7种高斯函数,4种线性函数,1种多项式函数;s3002、引入“核技巧”,利用直接得到任意两个数据点的相似性,构成相应核函数的核矩阵h;s3003、12种核函数得到12个基础核,构成核池。
25.在一个实施例中,所述步骤s500具体包括以下步骤:s5001、引入联合多核子空间聚类方法(jmksc)模型的目标函数,如下式:其中,α、β、γ为已知权衡参数,z为亲和矩阵,a为关系矩阵,h为共识核矩阵,w为基核权重;s5002、引入交替最小策略,固定其他变量同时更新z,因此定义一个目标函数如下:;s5003、得到的求解式如下:对上式求关于z的偏导,得到z的更新解。
26.在一个实施例中,所述步骤s700具体包括以下步骤:s7001、引入联合多核子空间聚类方法(jmksc)模型的目标函数,如下式:其中,α、β、γ为已知权衡参数,z为亲和矩阵,a为关系矩阵,h为共识核矩阵,w为基核权重;s7002、引入交替最小策略,固定其他变量同时更新z,因此定义一个目标函数如下:其中,和,因此的拉普拉斯矩阵由给出,其中是具有对角元素{jj}的对角矩阵,根据
–
块对角正则的定义,有
;s7003、利用ky fan定理[4],上式可以改写为:;s7004、得到的求解式如下:更新s后,可得到a的更新式子如下:令和得到a的闭合解。
[0027]
在一个实施例中,所述步骤s800具体包括以下步骤:s8001、引入联合多核子空间聚类方法(jmksc)模型的目标函数,如下式:其中,α、β、γ为已知权衡参数,z为亲和矩阵,a为关系矩阵,h为共识核矩阵,w为基核权重;s8002、引入交替最小策略,固定其他变量同时更新h,因此定义一个目标函数如下:对上式求关于h的偏导,得到h的更新解。
[0028]
在一个实施例中,所述步骤s900具体包括以下步骤:s9001、引入联合多核子空间聚类方法(jmksc)模型的目标函数,如下式:其中,α、β、γ为已知权衡参数,z为亲和矩阵,a为关系矩阵,h为共识核矩阵,w为基核权重;s9002、扩展相关熵(cim)的概念,用于任何两个平方矩阵或者核矩阵之间的一般相似度量,定义为下式:
其中是具有相同维数的两个任意矩阵,是数据点的数量和给定矩阵的维数,σ是内核大小,是内核大小为的高斯内核。内核大小取平均距离偏差,具体如下式:,接近期望的共识核的基核被赋予较大的权重,反之亦然。
[0029]
下面结合具体数据集聚类结果做进一步说明。
[0030]
1、实验条件:实验平台是mac mini 2018,配备intel core i7(3.2 ghz)cpu和16 gb ram,操作系统为macos mojave,仿真软件为matlab 2016b。
[0031]
2、实验内容:选取9个不同的公共数据集进行实验,包括6个图像数据集(yale,jaffe,orl,ar,coil20和binary alphadigits)和3个文本数据集(tr11,tr41和tr45),实验结果如图2、图3所示。其中单核方法包括kkm,sc和rkkm,以及它们对应的ew,avg和best版本,多核方法包括mkkm,aasc,rmkkm,smkl,scmk和lkgr。在所有实验中,通过3种流行的评估指标对所有方法的聚类性能进行评估,包括聚类准确度(acc),归一化互信息(nmi)和纯度。指标值越高表示聚类性能越好。
[0032]
3、实验结果与分析所有数据集的实验结果显示在图2(对于单核方法)和图3 (对于多核方法)中,报告了通过acc,nmi和平均纯度评估结果。对于每个数据集有3行,分别对应于acc,nmi和纯度的平均值。图2和图3显示,本发明在大多数情况下均获得最高性能。具体地,与第二最佳方法scmk相比,本发明分别对acc,nmi和纯度实现了约8.5,10.8和5.7的改进。此外,本发明方法的acc,nmi和纯度的平均最小标准偏差分别为1.2,0.8和1.1。
[0033]
在对结果进行深入分析之后,注意到以下结果:(1)在所有实验中,基于自表达的方法比单核方法获得更好的结果。事实证明,mkkm,aasc,rmkkm,smkl,scmk,lkgr和本发明的表现远远优于kkm,sc和rkkm,这表明,自表达框架可以弥补单核方法在不同数据集上较差的适应性。
[0034]
(2)
“-
best”方法(即kkm-best,sc-best,rkkm-best)的性能优于
“-
avg”方法(即kkm-avg,sc-avg,rkkm)-avg),这表明了预定义合适内核的重要性。
[0035]
(3)如图所示,kkm-ew,sc-ew和rkkm-ew分别比kkm-avg,sc-avg和rkkm-avg提高了聚类性能,也就是使用同等加权内核的单核方法(即
“-
ew”方法)比
“-
avg”方法更优,这证明了本发明采用内核加权策略的重要性。
[0036]
(4)本发明在所有情况下优于smkl,这证明bdr和尺度熵加权策略的有效性。本发明引入了基于熵尺度的加权策略,而不是使用简单的欧几里德距离度量,同时,本发明通过引入bdr来学习具有最佳k块对角结构的所需关系矩阵。
[0037]
(5)在mkl方法中,本发明具有最小的标准偏差,这意味着本发明具有良好的稳定性。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1