基于固定基正则化的神经网络参数稀疏化方法
本发明属于人工智能领域,涉及深度学习和机器学习算法领域,具体涉及一种基于固定基正则化的神经网络参数稀疏化方法,尤其涉及一种基于固定基正则化的卷积神经网络参数稀疏化的方法。
背景技术:
深度神经网络尤其是卷积神经网络广泛应用于人工智能领域,包括图像分类、目标识别、语音及自然语言处理。随着应用领域的扩大,基于图像识别与分类的卷积神经网络规模逐渐增大,大量的神经网络结构参数的存储和计算使得网络的训练时间和功耗量急速上升。在保证精确度的前提下进行神经网络参数的稀疏化(sparsify)和网络模型的压缩变得极为重要。
卷积神经网络主要包含卷积层和全连接层两个计算结构。在基于图像识别和分类的应用中,卷积层负责将输入图像数据和权重矩阵进行卷积计算处理,将输入原始数据映射到隐层特征空间;全连接层负责将卷积层输出结果映射到标记分类空间,输出分类结果。卷积神经网络中的参数主要集中在卷积层和全连接层两个计算结构内。
卷积神经网络中的参数主要表示为多维矩阵的计算形式,经过多次训练后,大规模深度神经网络中的权重参数矩阵均会变成稠密的,即矩阵中包含大量非零元素,稠密矩阵的存储和计算需要消耗大量的存储空间和计算资源。因此,通过稀疏化的方法将稠密矩阵转换为稀疏矩阵,即包含大量零元的矩阵,可以大大降低计算复杂度,提高神经网络训练效率并有助于网络模型的存储压缩。
传统剪枝(pruning)算法,通过将绝对值小于一定阈值的矩阵元素直接置为零的方法进行参数稀疏化,再通过重训练(fine-tune)补偿精度损失。在一定程度上可以实现网络结构的稀疏,但是对大规模参数矩阵的剪枝操作也引入了额外的计算消耗。另外重训练在补偿精确度的同时也会降低一定的稀疏度,两者之间的调和(trade-off)也是一个问题。另外还有一些基于定制化硬件平台实现的神经网络稀疏化和模型压缩算法,由于局限于特定的实现平台,在可移植性和可扩展性上存在欠缺,对于当今大规模多样性的卷积神经网络应用具有限制。因此,现已提出的神经网络稀疏化和模型压缩算法在满足应用需求方面仍不能发挥较好的作用。
与本发明有关的参考文献:
[1]songhan,huizimao,andwilliamjdallly,“deepcompression:compressingdeepneuralnetworkswithpruning,trainedquantizationandhuffmancoding,”arxivpreprintarxiv:1510.00149,2015.
[2]jiecaoyu,andrewlukefahr,davidpalframan,ganeshdasika,reetuparnadas,andscottmahlke,“scalpel:customizingdnnpruningtotheunderlyinghardwareparallelism”inacmsigarchcomputerarchitecturenews,volume45,pages548-560.acm,2017.
[3]weiwen,chunpengwu,yandanwang,yiranchen,andhaili,“learningstructuredsparsityindeepneuralnetworks,”inadvancesinneuralinformationprocessingsystems,pages2074-2082,2016.
[4]weiwen,congxu,chunpengwu,yandanwangyiranchen,andhaili,“coordinatingfiltersforfasterdeepneuralnetworks,”intheieeeinternationalconferenceoncomputervision(iccv),2017.
[5]bopeng,wenmingtan,zheyangli,shunzhangm,dixie,andshiliangpu,“extremenetworkcompressionviafiltergroupapproximation,”arxivpreprintarxiv:1807.11254,2018.
[6]liu,zhuangandli,jianguoandshen,zhiqiangandhuang,gaoandyan,shoumengandzhang,changshui,“learningefficientconvolutionalnetworksthroughnetworkslimming,”theieeeinternationalconferenceoncomputervision(iccv),pages2755—2763,ieee,2017。
技术实现要素:
本发明的目的是提供一种基于固定基正则化的神经网络参数稀疏化方法,所述方法是一种基于固定基正则化的卷积神经网络参数稀疏化的方法,该方法通过将大量的权重参数分解表示为低秩的固定基形式,固定基的大小及低秩均参数可进行调节,对全局共享卷积核的固定基还可以进行折叠操作,再对固定基进行部分正则化和剪枝处理,进行卷积神经网络的稀疏化训练;所述方法可克服传统神经网络稀疏化算法的障碍,在达到更高的稀疏度和精确度的同时,降低算法计算量和计算复杂度,大大减少权重参数的存储空间,提高卷积神经网络的训练成本和效率;此外,所述固定基的运用是一种便于硬件实现的方法,且本发明不局限于任何定制硬件平台实现,具有更高的应用和实现的灵活性。
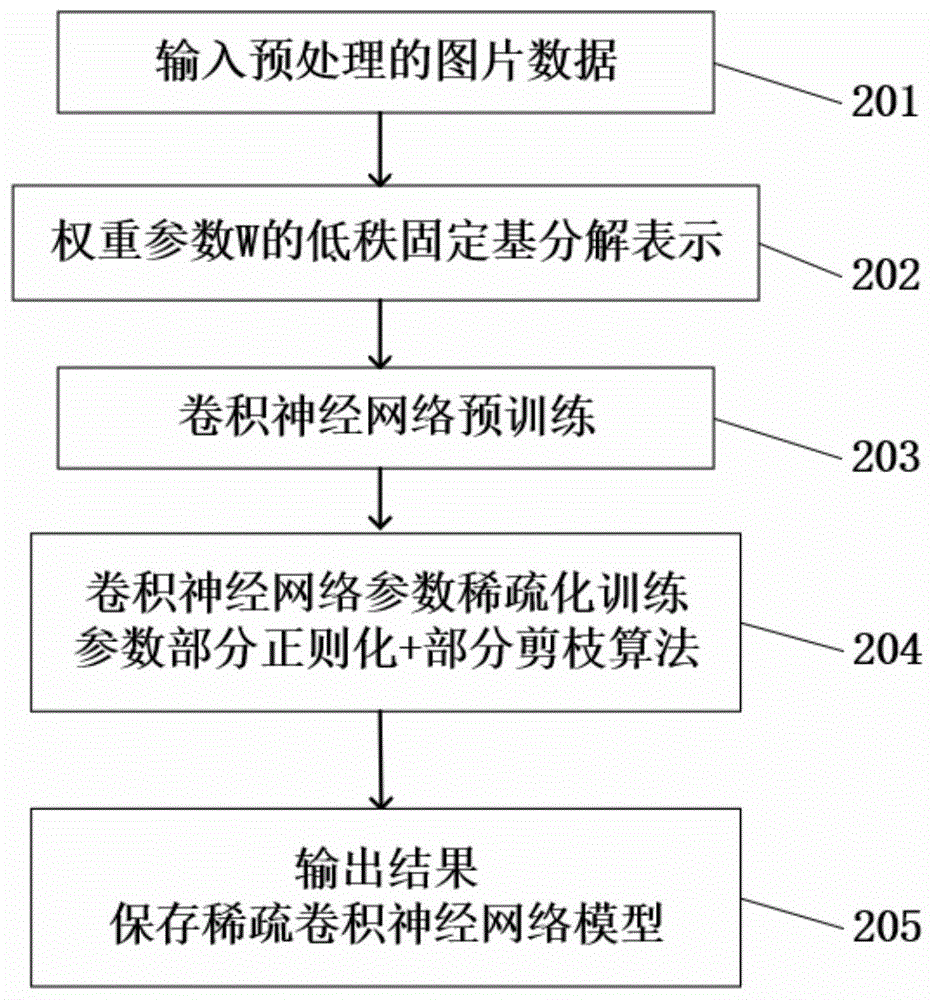
为了达到上述目的,本发明的技术内容是:一种基于固定基正则化的神经网络参数稀疏化方法,主要在图像识别和分类应用中进行卷积神经网络的模型优化,其步骤如下(如图1所示):
步骤201:读入原始图片,进行大小、格式等归一化处理,并增加随机噪声、翻转等图片预处理过程,生成输入的图片数据;
步骤202:卷积神经网络卷积层的卷积核和全连接层的权重参数均可进行稀疏化处理,将两类参数统一称为权重参数并以卷积核形式为例,一般用多维矩阵来表示;权重参数的固定基低秩分解表示可以分为逐层权重参数固定基分解和可折叠的固定基分解两种情况,处理过程略有不同,表示为两个分步骤21和22:
分步骤21:逐层进行的权重参数固定基低秩分解,对于第l层权重参数,原始卷积核
wl=tl*al*sl
其中
分步骤22:可折叠的权重参数固定基分解,该情况主要适用于包含多层相同或相似卷积层结构的卷积神经网络模型,通过建立全局共享的权重并进行可折叠的固定基分解,为稀疏化训练模型进行参数准备;
为进行对比,以单层卷积核可折叠固定基分解为例,对于第l层权重参数,将原始四维张量的卷积核改写为相同元素数目的
类似地选取低秩参数
其中
步骤203:进行无稀疏化处理的常规卷积神经网络预训练,不对任何参数进行剪枝或者正则化处理,使用adam梯度优化器进行重复训练。
预训练的过程是使卷积神经网络进行前期的学习,在没有引入稀疏化处理之前,通过不断调整稀疏化操作之外的其他超参数,促使经过低秩固定基分解卷积核和权重参数后的卷积神经网络可最大程度适应,并在精度上得到最优性能,从而实现初期的优化网络结构的目标;
由于所述稀疏化的操作在一定程度上消除部分卷积核和权重的参数,削剪去部分神经元之间的关联,对于神经网络初期的学习功能有极大的损害。多次实验的结果表明,选择对卷积神经网络进行初期预训练后再开展稀疏化参数训练相比于直接开始进行稀疏化训练神经网络能够得到更好的精确度和网络结构;此外,神经网络预训练模型可以保存下来,对于只调节稀疏化操作参数的网络结构优化过程,直接使用保存的预训练模型可大大提高稀疏化参数调节和训练效率,对于得到优化的稀疏卷积神经网络结构十分有利。
步骤204:卷积神经网络的稀疏化训练;对于展开成固定基形式的卷积核w或
其中,e0(w)表示没有稀疏化操作的原始训练损失函数;r1(·)表示参数l1正则化约束。
类似地,在卷积神经网络训练后期的步骤中,加入卷积核权重参数的剪枝操作;传统剪枝操作是针对所有可训练的参数设置一个较小的阈值,将所有绝对值在阈值内的矩阵中的元素置为零,在神经网络训练的每一次迭代中,进行阈值判断和置零操作;在基于低秩固定基正则化的本发明中,改进了传统剪枝算法,仅在后期1%~2%的训练步骤中加入剪枝操作,并只对低秩固定基分解表示卷积核中的部分参数
卷积神经网络的稀疏化训练是在预训练结束后,结合对低秩固定基分解表示的卷积核和权重参数部分l1正则化和部分剪枝操作,在整体神经网络训练后期开展的稀疏化训练;
步骤205:输出稀疏化卷积神经网络训练后得到图片识别分类判断结果。
本发明针对应用卷积神经网络的图片识别和分类应用具有如下优点:
1.相比现已提出的卷积神经网络稀疏化算法,在相同的图片识别分类实例中的应用中,达到相同水平的分类结果精确度,可以达到更高的网络参数稀疏度;
2.稀疏化算法的操作,包括低秩固定基分解和参数的部分l1正则化和部分剪枝操作,相比于原始l1正则化和剪枝对于卷积核和权重参数整体矩阵元素的约束操作,复杂度为o(mlnl*clfl),分解后的部分稀疏化约束将复杂度降为
3.固定基的分解有利于稀疏神经网络的参数硬件实现和存储。对于稀疏化的参数矩阵,使用少数固定图样的基的组合表示卷积核和权重参数,固定基表示稀疏的形式是固定的,因此更有利于本发明在硬件平台上的实现和加速。
附图说明
图1是本发明基于固定基正则化的神经网络参数稀疏化方法的流程图;
图2是低秩固定基分解示意图;
图3是折叠的固定基分解(b=t*a)示意图;
图4是基于mnist的稀疏lenet5分类结果对比;
图5是基于cifar10的稀疏resnet32分类结果对比;
图6是基于cifar100的稀疏resnet32和vgg19分类结果对比。
具体实施方式
本发明是一种基于低秩固定基正则化的卷积神经网络稀疏化的方法。本发明应用的所有实施例均在仅有一个geforcegtx1080tigpu的服务器上运行试验。
下面结合附图,通过几个图像识别分类应用中的实施例进一步描述本发明,但不以任何形式限制本发明的适用范围和应用领域。
实施例1
基于改进lenet卷积神经网络在mnist数据集上实现;本实施例进行稀疏化训练的是一个具有两层卷积层和两层全连接层的改进版lenet网络,mnist是具有60000张训练图片和10000张测试图片的手写字图片数据集,每张黑白图片为28x28像素规格,每张图片对应一个0~9表示分类的标签,第一个实施例就是基于mnist数据集手写字图片识别分类训练的稀疏卷积神经网络。
本实施例网络中采用的是adam后向训练算法,由于最后一层全连接层参数量很少,仅对卷积神经网络中的两层卷积层和第一层全连接层的参数进行稀疏化处理;首先,本实例中没有对mnist数据集进行预处理,直接读入图片像素数据后,对两层卷积层(conv1和conv2)的卷积核和全连接层(fc1)的权重参数进行低秩固定基分解,选取三组低秩参数αi进行以三组低秩固定基展开的矩阵表达,在本实施例中不采取固定基折叠的形式;其次,对参数固定基展开后的卷积神经网络进行预训练,同时调整优化其他超参数。
稀疏化lenet的训练主要针对于固定基对应的
实施例2
本实施例基于32层标准残差神经网络(resnet32)在cifar10数据集上实现;resnet32是包含31层卷积层和1层全连接层的卷积神经网络结构,cifar10是具有50000张训练图片和10000张测试图片的彩色图片数据集,每张彩色图片为32x32像素规格,每张图片对应一个0~9表示分类的标签,第一个实施例就是基于cifar10数据集图片识别分类训练的稀疏残差神经网络。
由于resnet32只包含最后一层全连接层,在本实施例中仅对除去第一层卷积层和最后一层全连接层余下的30层卷积层进行稀疏化操作处理;首先,对于cifar10图片数据进行裁剪和翻转的预处理,基本不改变原始数据形貌;基于选取的30层卷积层的卷积核大小一致,在本实施例2中采取逐层卷积核固定基分解和全局共享卷积核折叠固定基分解两种分解方式进行两组实验。对于前者逐层方式采取3组低秩参数αi进行固定基分解,后者将所有形状大小一致的卷积核合并在同一个全局共享卷积核中,在执行卷积操作时再随机从全局共享的卷积核中抽取所需的卷积核以满足每层的卷积操作。对于全局共享卷积核,以β=2进行固定基折叠后,选取6组低秩参数αi进行固定基分解。再类似地进行神经网络的预训练,在adam梯度后向传播训练算法下,调整其他超参数优化预训练网络。然后,针对固定基对应的
实施例3
基于resnet32和vgg16两种卷积神经网络在cifar100数据集上实现;vgg16是包含5组共13层卷积层的卷积神经网络。cifar100是和实施例2中cifar10大小一致的彩色图片数据集,包含50000张训练图片和10000张测试图片,分类标签共有0~99总计100个类别。
在resnet32网络中分别采取了sgd和momentum两种梯度优化算法进行对比。类似实施例1和2中的步骤,对cifar100数据集采用和cifar10相同的预处理,进行网络无稀疏化预训练。对于resnet32采取卷积层逐层固定基分解,对于vgg16采取β=2折叠的全局共享卷积核固定基分解,对其中的13层卷积层进行稀疏化处理,两组网络各选取6组低秩参数进行基于固定基的展开。结合部分参数l2正则化和部分参数剪枝,得到与其他提出稀疏化算法在cifar100数据集上的结果对比如图6所示,其中filtergroup和slimming分别是文章[5]和[6]中提出的算法。以vgg16结果为例,在获得低至24.71%的分类错误率的同时可以达到78.17%的卷积层网络稀疏度,具有明显的优势。
本发明适用于所有采用标准后向传播的训练算法包括随机梯度下降训练算法(sgd)、自适应次梯度训练算法(adagrad)、亚当算法(adam)以及动量梯度下降算法(momentum)等,以及所有标准后向传播的卷积神经网络模型包含标准卷积神经网络(cnn)、残差神经网络(rnn)、vgg16、vgg19、alexnet及其各种变形等。
此外,本发明不局限于公布实施例内容所包含的应用和使用范围,相关领域的技术人员可以理解:在不脱离本发明及所附权利要求的精神和范围内,适当的替换、扩展和修改是可能的。本发明要求的保护范围以权利要求书界定的范围为准。
- 还没有人留言评论。精彩留言会获得点赞!