一种利用基于图论的多重交互网络机制解决视频问答问题的方法与流程
本发明涉及视频问答答案生成,尤其涉及一种利用基于图论的多重交互网络机制解决视频问答问题的方法。
背景技术:
视频问答问题是视频信息检索领域中的一个重要问题,该问题的目标是针对于相关的视频及对应的问题,自动生成答案。
现有的技术主要解决的是关于静态图像相关的问答问题。虽然目前的技术针对于静态图像问答,可以取得很好的表现结果,但是这样的方法缺少对于视频中的时间动态信息的建模,所以不能很好地拓展到视频问答任务上面。
针对于视频中经常包含对象物品的外形及其移动信息,并且与问题相关的视频信息是分散在视频的某些目标帧之中的情况,本方法将使用基于图论的多重交互机制来聚焦于视频与所问问题相关的目标帧,并且学习与问题相关的有效的视频表达。同时,使用分段级别的视频特征提取机制提取关于视频帧之中的物体外形及移动信息。
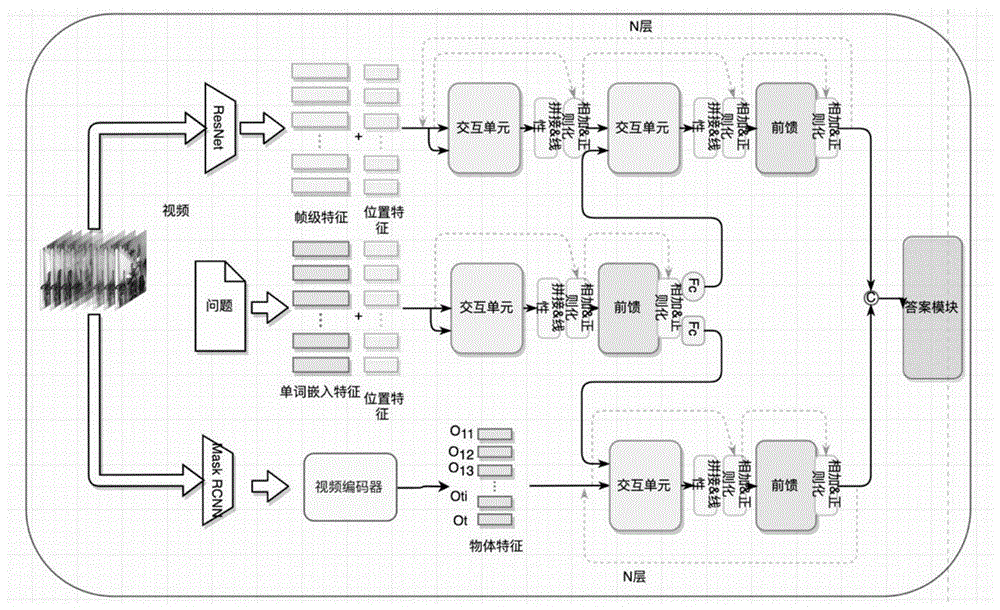
本方法将利用残差神经网络得到视频帧级别的表达,同时针对这组视频,用maskr-cnn神经网络得到物体存在和物体位置的特征表达。另外,用glove神经网络得到问题单词级别的特征信息。之后利用图神经网络对这组视频进行构图,并引入消息传输机制迭代更新图的特征表达。之后利用多重交互网络分三个通道分别学习到与问题相关的视频帧级别和段级别的表达以及与问题相关的物体的运动信息。最后利用学习到的这些特征信息,结合不同类型问题的特点,用不同的回归函学习出答案来解决视频问答问题。
技术实现要素:
本发明的目的在于解决现有技术中的问题,为了克服现有技术中缺少对于视频中的时间动态信息的建模的问题,且针对于视频中经常包含对象物品的外形及其移动信息,并且与问题相关的视频信息是分散在视频的某些目标帧之中的情况,本发明提供一种利用基于图论的多重交互网络机制解决视频问答问题的方法,本发明所采用的具体技术方案是:
1)对于输入的视频及自然语言问题语句,训练出图神经网络和多重交互网络来获取问题相关的物体存在特征表达、物体间动态联系的特征表达、以及与问题相关的帧级和片段级视频表达,得到针对不同问题的预测答案;
1.1)针对一段视频,采用残差神经网络提取视频的帧级表达;
1.2)采用maskr-cnn神经网络,提取视频中物体存在特征表达和物体空间位置特征表达;
1.3)针对自然语言问题语句,采用预训练的glove神经网络得到自然语言问题语句的单词级别的嵌入表达;
1.4)利用步骤1.2)得到的物体存在特征表达和物体空间位置特征表达,通过图神经网络进行建图,并引入消息传输机制,对图进行迭代更新,获得最终的物体存在特征表达;
1.5)利用步骤1.1)获得的视频的帧级表达、步骤1.2)获得的物体空间位置特征表达、步骤1.3)获得的自然语言问题语句的单词级别的嵌入表达和步骤1.4)获得的最终的物体存在特征表达,引入多重交互网络,利用预训练的交互网络和前馈神经网络,分三个通道得到与问题相关的物体存在特征表达、物体间动态联系的特征表达以及与问题相关的视频帧级和片段级视频表达;
1.6)针对不同的问题形式,采用不同的回归函数和损失函数,得到针对问题的预测答案;
2)将步骤1)获得的针对不同问题的预测答案与真实的答案进行比较,更新图神经网络和多重交互网络的参数,得到最终的图神经网络和多层注意力网络;
3)对于要预测答案的视频和问题,根据生成的最终的图神经网络和多层注意力网络,得到所预测的答案。
进一步的,所述的步骤1.1)具体为:
对于一段视频,将视频输入到预训练的残差神经网络,输出视频的帧级表达φ={ii},i=1,2,3,…,,其中ii表示视频第i帧的特征表达,t表示视频的帧数。
进一步的,所述的步骤1.2)具体为:
对于一段视频,将视频输入到预训练的maskr-cnn卷积神经网络,输出视频中的物体存在特征表达
进一步的,所述的步骤1.3)具体为:
对于自然语言问题语句,采用预训练的glove神经网络得到自然语言问题语句的单词级别的嵌入表达q={q1,q2,…,q|q|};其中qi表示自言语言问题语句中的第i个单词的嵌入特征表达,|q|表示自然语言问题语句中的单词的数量。
进一步的,所述的步骤1.4)具体为:
1.4.1)对于步骤1.2)获得的视频中物体存在特征表达
其中
将不同帧中被检测到的所有物体重新进行排序,不同帧中的同一物体算不同物体,只使用下角标i表示不同帧中被检测到的第i个物体,简称视频中第i个物体;
进一步得到视频中物体的隐藏状态表达hv,
hv={hv}v∈v={h1,…,hi,…h|v|}
其中,hi表示视频中第i个物体的隐藏状态表达,v表示被检测到的所有物体的个数;
1.4.2)对于步骤1.2)获得的视频中物体空间位置特征表达,计算两两物体之间的相对位置向量:定义任意视频中两个物体的空间位置特征表达lm和ln,根据如下公式得到四个维度上的物体相对位置向量(xmn,ymn,wmn,hmn)t:
对于上述四个维度相对位置向量(xmn,ymn,wmn,hmn)t,利用位置编码,将(xmn,ymn,wmn,hmn)t通过不同频率的正弦、余弦函数嵌入到高维,然后再将四个高维向量拼接成单个向量,得到视频中第m个物体和第n个物体之间的特征向量lrmn;
计算视频中第m个物体和第n个物体的空间位置联系lrmn:
lrmn=max{0,wr·lrmn}
其中,wr为参数矩阵,运用线性整流函数作为神经元的激活函数;
视频中所有物体之间的空间位置联系两两对应,得到视频中物体空间位置的隐藏状态表达he:
其中
1.4.3)步骤1.4.1)和步骤1.4.2)得到的hv、he对应初始化的图,将hv和he输入到图神经网络中,分两步采用消息传输机制对图点和边的隐藏状态进行多次迭代更新:
第一步,只考虑连接同一帧图像中物体的交互型边;按照如下公式,计算视频中第i个物体和第j个物体的连接分数:
其中ws,wt,wst分别是第i个物体,第j个物体,ij之间交互型边的学习权重,vo是学习向量,σ是一个非线性函数,
其中,
对于上述标准值
根据如下公式更新图的隐藏状态向量:
其中,
第二步,考虑轨迹型边;按照如下公式,计算没有注意力机制下,从第i个物体到第j个物体的轨迹型边上的传输信息
其中w′s、w′st是学习权重;
根据如下公式更新图的隐藏状态向量:
其中λij是一个二进制标量,当且仅当第i个物体和第j个物体之间存在轨迹型边时取1,否则取0;
经过l次循环更新,得到更新图的隐藏状态向量
最终的物体存在特征表达h表示为:
进一步的,步骤1.5)所述的多重交互网络具体如下,假定多头线性层的头数为1:
第一步,对两个输入序列做线性映射,得到两个输入矩阵q=(q1,q2,…,qi)和v=(v1,v2,…,vj),其中q是lq×dk维的实矩阵,v是lv×dk维的实矩阵。
第二步,构建张量k来表示两个输入矩阵的每列之间的相互作用,张量k的每列kij计算方式如下:
其中kij是一个dk维的实列向量,qi和vj也是dk维的实列向量,
第三步,对张量k利用一个卷积核窗面积为sq×sv的卷积层,此时,张量k被分为不同的子张量k′,这些子张量是sq×sv×dk维的实矩阵,表示段问题和段视频之间的按元素交互特征,随着卷积核窗的移动,得到不同的按段交互的表达,构成张量p;
第四步,用一个去卷积层将张量p恢复成原始lq×lv×dk维的张量m,其中张量m包含了按段交互的信息;
第五步,将张量k和张量m压缩到dk维,分别得到lq×lv维的按元素的权重矩阵we和lq×lv维的按段的权重矩阵ws;
第六步,利用softmax函数得到按元素和按段的交互信息,即多重注意力机制的最终输出:
o=softmax(we+ws)vor
o=softmax((we+ws)⊙wr)v
其中,o是一个lq×dk维的实矩阵,wr是可选的外部矩阵;
此外,步骤1.5)中提到的多重交互网络三个通道的q和v分别为视频的帧级表达和物体空间位置特征表达,自然语言问题单词级别的嵌入表达和物体空间位置特征表达,最终的物体存在特征表达和通道2输出的特征矩阵;通道1第一个交互单元输出的特征矩阵与通道2输出的特征矩阵作为通道1第二个交互单元的输入。
进一步的,所述的步骤1.6)具体为:
针对多选类型的问题,使用线性回归函数,将视频编码器的输出fvo作为其输入,并输出每个选项的分数:
其中ws是训练权重;使用正确答案的分数sp和错误答案的分数sn之间的合页损失函数max{0,1+sn-sp}来优化模型;
针对开放性数字题,利用下列公式得到输出的答案:
其中,wn是训练权重,b是偏置,round是取整函数,同时利用正确数字和预测数字之间的
针对开放单词题,利用线性层将输出维度转换成答案词汇维度,利用softmax函数计算出答案分布:
其中,wn是训练权重,b是偏置,同时利用正确单词和预测单词之间的交叉熵损失函数来优化模型。
本发明具备的有益效果是:
1)本发明提出了一种全新的视频问答模型——基于图论的多重交互网络,相较于传统gnn神经网络边的权重是预先设定的,本发明的模型可以根据视频的前后连续性动态地调整边权,因此本发明的模型能抓取更深层次的有连贯性的语义信息;
2)本发明设计了一种全新的注意力机制——多重交互网络。有一些问题的答案往往包含在多帧图片中,因此在设定注意力的时候本发明不是仅仅选取单帧,还选取了多帧的视频段。因此,本发明的模型在回答一些需要观察物体前后变化等此类问题时效果较传统模型更优;
3)本发明在更新图的时候用到了消息传输机制。两种类型的边——交互边和轨迹边协同合作,不仅可以获取物体间空间关系还可以获取他们之间相互的语义关系,从而抓取更多重要的细节信息;
4)本发明的答案模块,会根据不同的问题形式,采用不同的策略来得到效果最优的答案。
附图说明
图1是本发明所使用的对于视频问答问题的基于图论的多重交互网络的整体示意图;
图2是视频编码器的结构;
图3是消息传输机制对图进行迭代更新的示意图;
图4是多重交互机制的示意图。
具体实施方式
下面结合附图和具体实施方式对本发明做进一步阐述和说明。
如图1所示,本发明的一种利用基于图论的多重交互网络机制解决视频问答问题的方法包括如下步骤:
步骤一、对于输入的视频及自然语言问题语句,训练出图神经网络和多重交互网络来获取问题相关的物体存在特征表达、物体间动态联系的特征表达、以及与问题相关的帧级和片段级视频表达,得到针对不同问题的预测答案;
1、对于一段视频,将视频输入到预训练的残差神经网络,输出视频的帧级表达φ={ii},i=1,2,3,…,,其中ii表示视频第i帧的特征表达,t表示视频的帧数。
2、对于一段视频,将视频输入到预训练的maskr-cnn卷积神经网络,输出视频中的物体存在特征表达
3、对于自然语言问题语句,采用预训练的glove神经网络得到自然语言问题语句的单词级别的嵌入表达q={q1,q2,…,q|q|};其中qi表示自言语言问题语句中的第i个单词的嵌入特征表达,|q|表示自然语言问题语句中的单词的数量。
4、按照如下公式获得视频中第t帧第i个物体的隐藏状态表达:
其中
将不同帧中被检测到的所有物体重新进行排序,不同帧中的同一物体算不同物体,只使用下角标i表示不同帧中被检测到的第i个物体,简称视频中第i个物体;
作为本发明的优选实施方式,选择名为图神经网络并引入消息传输机制来学习物体级别的动态信息。该网络的点隐藏状态初始化hv(视频中物体的隐藏状态表达)为:
hv={hv}v∈v={h1,…,hi,…h|v|}
其中,hi表示视频中第i个物体的隐藏状态表达,v表示被检测到的所有物体的个数;
计算两两物体之间的相对位置向量:定义任意视频中两个物体的空间位置特征表达lm和ln,根据如下公式得到四个维度上的物体相对位置向量(xmn,ymn,wmn,hmn)t,即得到网络的边隐藏状态初始化为:
对于上述四个维度相对位置向量(xmn,ymn,wmn,hmn)t,利用位置编码,将(xmn,ymn,wmn,hmn)t通过不同频率的正弦、余弦函数嵌入到高维,然后再将四个高维向量拼接成单个向量,得到视频中第m个物体和第n个物体之间的特征向量lrmn;
计算视频中第m个物体和第n个物体的空间位置联系lrmn:
lrmn=max{0,wr·lrmn}
其中,wr为参数矩阵,运用线性整流函数作为神经元的激活函数;
视频中所有物体之间的空间位置联系两两对应,得到视频中物体空间位置的隐藏状态表达he:
其中
将hv和he输入到图神经网络中,分两步采用消息传输机制对图点和边的隐藏状态进行多次迭代更新,对该图的点边隐藏状态更新流程如图3所示:
第一步,只考虑连接同一帧图像中物体的交互型边;按照如下公式,计算视频中第i个物体和第j个物体的连接分数:
其中ws,wt,wst分别是第i个物体,第j个物体,ij之间交互型边的学习权重,vo是学习向量,σ是一个非线性函数,
其中,
对于上述标准值
根据如下公式更新图的隐藏状态向量:
其中,
第二步,考虑轨迹型边;按照如下公式,计算没有注意力机制下,从第i个物体到第j个物体的轨迹型边上的传输信息
其中w′s、w′st是学习权重;
根据如下公式更新图的隐藏状态向量:
其中λij是一个二进制标量,当且仅当第i个物体和第j个物体之间存在轨迹型边时取1,否则取0;
经过l次循环更新,得到更新图的隐藏状态向量
最终的物体存在特征表达h表示为:
5、引入多重注意力机制,训练的交互网络和前馈神经网络。
作为本发明的优选实施方式,多重注意力机制具体步骤如图2所示,为了方便假定多头线性层的头数为1:
对两个输入序列做线性映射,得到两个输入矩阵q=(q1,q2,…,qi)和v=(v1,v2,…,vj)。其中q是lq×dk维的实矩阵,v是lv×dk维的实矩阵。
根据以下公式构建一个张量:
其中kij是一个dk维的实列向量,qi和vj也是dk维的实列向量,
对上面得到的张量k,将它压缩到dk维,得到一个lq×lv维的权重矩阵we。
针对上述权重矩阵we和输入矩阵v,利用softmax函数得到最终的输出:
o=softmax(we)v
其中o是一个lq×dk维的实矩阵。
考虑本专利提到的多重交互网络机制。与上述多头注意力网络相比,引入了两个额外的步骤来抓取按段的交互信息。
第一步,对张量k利用一个卷积核窗面积为sq×sv的卷积层。此时,张量k被分为不同的子张量k′。这些子张量是sq×sv×dk维的实矩阵,并且可以被看作是段问题和段视频之间的按元素交互特征。随着卷积核窗的移动,就可以得到不同的按段交互的表达,这些表达构成了张量p。
第二步,用一个去卷积层将张量p恢复成原始lq×lv×dk维的张量m,其中张量m就包含了按段交互的信息。对张量k和m进行前面提到的压缩,就可以得到按元素的权重矩阵we和按段的权重矩阵ws。对这两个权重矩阵利用softmax函数得到按元素和按段的交互信息:
o=softmax(we+ws)vor
o=softmax((we+ws)⊙wr)v
其中,o是一个lq×dk维的实矩阵,wr是可选的外部矩阵;
如图4所示,三个通道的q和v分别为视频的帧级表达和物体空间位置特征表达,自然语言问题单词级别的嵌入表达和物体空间位置特征表达,最终的物体存在特征表达和通道2输出的特征矩阵;通道1第一个交互单元输出的特征矩阵与通道2输出的特征矩阵作为通道1第二个交互单元的输入。
6、针对多选类型的问题,使用线性回归函数,将视频编码器的输出fvo作为其输入,并输出每个选项的分数:
其中ws是训练权重;使用正确答案的分数sp和错误答案的分数sn之间的合页损失函数max{0,1+sn-sp}来优化模型;
针对开放性数字题,利用下列公式得到输出的答案:
其中,wn是训练权重,b是偏置,round是取整函数,同时利用正确数字和预测数字之间的
针对开放单词题,利用线性层将输出维度转换成答案词汇维度,利用softmax函数计算出答案分布:
其中,wn是训练权重,b是偏置,同时利用正确单词和预测单词之间的交叉熵损失函数来优化模型。
步骤二、针对不同问题的预测答案与真实的答案进行比较,更新图神经网络和多重交互网络的参数,得到最终的图神经网络和多层注意力网络。
步骤三、下面将上述方法应用于下列实施例中,以体现本发明的技术效果,实施例中具体步骤不再赘述。
实施例
本发明在著名的数据集tgif-qa、msvd-qa和msrvtt-qa上面进行实验验证,表1-表3是本实施例在三个数据集上训练和测试的结果。
表1:tgif-qa数据集中样本的统计数据
表2:msvd-qa数据集中样本的统计数据
表3:msrvtt-qa数据集中样本的统计数据
为了客观地评价本发明的算法的性能,本发明对不同类型的问题采用不同的评估机制。对于状态转换,重复行为,单帧图像问答,采用分类精确率(acc)来衡量准确度;对于重复计数,采用正确答案和预测答案之间的平均平方误差(mse)表示。
最终所得的实验结果如表4-表6所示:
表4:在tgif-qa数据集与其他优秀算法的对比
表5:在msvd-qa数据集与其他优秀算法的对比
表6:在msrvtt-qa数据集与其他优秀算法的对比
- 还没有人留言评论。精彩留言会获得点赞!