基于信任机制下面部交并比的假脸视频检测方法及系统与流程
本发明涉及数字视频的篡改检测技术领域,具体涉及一种基于信任机制下面部交并比的假脸视频检测方法及系统。
背景技术:
在众多生物特征中,人脸是最具有代表性的特征之一,可辨识度较高。因此,随着人脸识别技术的突飞猛进,人脸篡改带来的安全威胁越来越大,特别是在手机高度流行和社交网络日益成熟的当代。深度换脸工具主要使用自编码器或对抗生成网络等深度神经网络生成虚假人脸后再对原视频的人脸进行替换,根据所使用的特征,现有假脸视频检测技术大致可分为三大类:基于传统手工特征、基于生物特征以及基于神经网络提取特征。上述方法在一定程度上能够识别出假脸视频,尤其在库内,测试中可达较高的准确率,然而,在跨库测试中准确率均急剧下降,即存在泛化能力不足问题。
技术实现要素:
为了克服现有技术存在的缺陷与不足,本发明提供一种基于信任机制下面部交并比的假脸视频检测方法及系统,本发明运用了像素级分类技巧和假脸篡改的先验知识,有效降低了跨库测试的平均错误率,使用图像分割进行确定待检测区域后再分类判决,有效地提高了泛化能力。
为了达到上述目的,本发明采用以下技术方案:
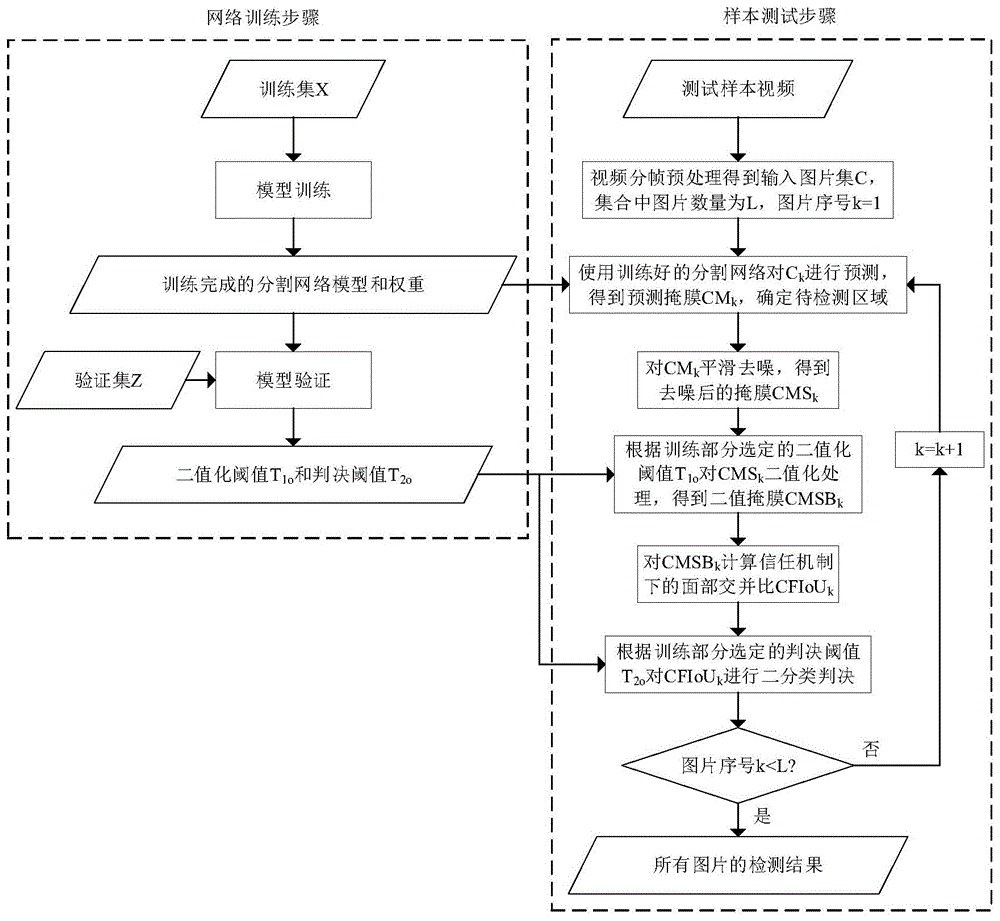
本发明提供一种基于信任机制下面部交并比的假脸视频检测方法,包括网络训练步骤和样本测试步骤,所述网络训练步骤包括模型训练步骤和模型验证步骤;
将数据集划分为源训练集、源验证集和源测试集;
所述模型训练步骤包括下述步骤:
对所述源训练集进行图像预处理后得到训练集图片x={x1,x2,...,xn},训练集正确掩膜y={y1,y2,...,yn},其中n为训练集图片总数;
输入训练集图片x和标签为训练集正确掩膜y进行分割网络训练,分割网络训练完成后保存分割网络模型和权重值;
所述模型验证步骤包括下述步骤:
对所述源验证集进行图像预处理后得到验证集图片z={z1,z2,...,zq},其中q为验证集图片总数;
对验证集第k张图片zk采用训练好的分割网络预测得到掩膜zmk,确定待检测区域;
对预测的掩膜zmk进行平滑处理得到去噪后的掩膜zmsk;
设置初始二值化阈值t1和初始判决阈值t2,采用网格搜索法进行网格搜索,并对验证集图片去噪后的掩膜进行二值化处理、面部交并比计算和二分类判决,得到虚警率和漏检率,记录相应的阈值对和等错误率,当判定等错误率最小时,选定二值化阈值t1o和判决阈值t2o;
所述样本测试步骤包括下述步骤:
对所述源测试集进行图像预处理后得到测试集图片c={c1,c2,...,cl},其中l为测试图片总数;
对测试集第k张图片ck采用训练好的分割网络预测得到掩膜cmk,确定待检测区域;
对预测的掩膜cmk进行平滑处理得到去噪后的掩膜cmsk;
采用网络训练步骤中选定的二值化阈值t1o对去噪后的掩膜cmsk进行二值化处理,得到二值掩膜cmsbk;
设置信任机制的惩罚因子p,对二值掩膜cmsbk计算信任机制下面部交并比cfiouk;
采用网络训练步骤选定的判决阈值t2o对面部交并比cfiouk进行二分类判决,逐帧判断测试集图片的真假,计算得到判断的准确率和平均错误率。
作为优选的技术方案,对所述源训练集进行图像预处理后得到训练集图片x,训练集正确掩膜y,具体步骤为:
对源训练集中的视频帧进行图像预处理,选取人脸框对人脸标志点进行检测记录,并矫正人脸框;
在源训练集的视频帧和对应的正确掩膜上,根据矫正后的人脸框位置裁剪出部分区域图片,并采集到同一分辨率,得到训练集图片x,训练集正确掩膜y;
对所述源验证集进行图像预处理后得到验证集图片z,具体步骤为:
对源验证集中的视频帧进行图像预处理,选取人脸框对人脸标志点进行检测记录,并矫正人脸框;
在源验证集的视频帧上,根据矫正后的人脸框位置裁剪出部分区域图片,并采集到同一分辨率,得到验证集图片z;
对所述源测试集进行图像预处理后得到测试集图片c,具体步骤为:
对源测试集中的视频帧进行图像预处理,选取人脸框对人脸标志点进行检测记录,并矫正人脸框;
在源测试集的视频帧上,根据矫正后的人脸框裁剪出部分区域图片,并采样到同一分辨率,得到测试集图片c。
作为优选的技术方案,所述模型训练的分割网络训练具体步骤包括:
构建分割网络,构建分割网络训练的损失函数,构建分割网络参数优化算法,所述分割网络参数优化算法采用adam算法;
输入训练集图片x和标签为训练集正确掩膜y进行分割网络训练,分割网络训练完成后保存分割网络模型和权重值;
所述分割网络训练的损失函数为:
其中,(i,j)表示掩膜上的坐标点位置,mk表示掩膜的长度,nk表示掩膜的宽度。
作为优选的技术方案,所述分割网络采用图像数据集imagenet上预训练的网络结构vgg-16为骨架的fcn-8s模型;
图片输入网络结构vgg-16,依次通过第一卷积模块、第二卷积模块、第三卷积模块、第四卷积模块和第五卷积模块;
第一卷积模块包括两个步长为1的64通道输入3×3卷积层和一个步长为2的2×2最大池化层;第二卷积模块包括两个步长为1的128通道输入3×3卷积层和一个步长为2的2×2最大池化层;第三卷积模块包括两个步长为1的256通道输入3×3卷积层和一个步长为2的2×2最大池化层;第四卷积模块包括两个步长为5的512通道输入3×3卷积层和一个步长为2的2×2最大池化层、第五卷积模块包括两个步长为5的512通道输入3×3卷积层和一个步长为2的2×2最大池化层,其中所有卷积层的激活函数为relu;
fcn-8s的输入为分辨率256×256,经过vgg-16骨架网络后,第五卷积模块的输出通过步长为1的4096通道输入7×7卷积层、relu激活函数、概率为0.5的随机失活层、步长为1的4096通道输入1×1卷积层、relu激活函数、概率为0.5的随机失活层、步长为1的2通道输入1×1卷积层、步长为2的2通道输入4×4反卷积层,与第四卷积模块的输出通过步长为1通道输入1×1卷积层后结果相加、步长为2的2通道输入4×4反卷积层,与第三卷积模块的输出通过步长为1通道输入1×1卷积层后结果相加、步长为8的2通道输入16×16反卷积层、softmax激活函数,输出为预测的掩膜。
作为优选的技术方案,所述选定二值化阈值t1o和判决阈值t2o具体步骤包括:
网格搜索:设置初始二值化阈值t1和初始判决阈值t2的值,进行步长值为s的网格搜索;
二值化处理:采用当前二值化阈值t1对第k张去噪后的掩膜zmsk进行二值化处理得到二值掩膜zmsbk;
面部交并比计算:设置信任机制的惩罚因子p,对二值掩膜zmsbk计算信任机制下面部交并比zfiouk:
zfiouk=(zs1k∩zs2k)/(zs1k∪zs2k+p×(zs1k∪zs2k-zs1k))
其中,zs1k为第k张图片zk中人脸区域,zs2k为二值掩膜zmsbk中待定篡改区域,p为信任机制的惩罚因子;
二分类判决:采用当前判决阈值t2对面部交并比zfiouk进行二分类判决,逐帧判断验证集中所有图片的真假,设q张图片中有q1张真脸图片和q2张假脸图片,其中q1张真脸图片内有q1a张被判断成真脸,有q1b张图片被判断成假脸,q2张假脸图片内有q2a张被判断成真脸,有q2b张被判断成假脸;
计算得到虚警率far和漏检率fnr分别为:
若满足虚警率等于漏检率,达到等错误率状态,记录当前阈值对{t1,t2}和等错误率eer;
设置第一阈值和第二阈值,根据网格搜索法改变t1和t2的值,重复执行所述网格搜索、二值化处理、面部交并比计算和二分类判决步骤,直至t1达到第一阈值并且t2达到第二阈值时,停止搜索,并记录相应的阈值对和等错误率,筛选出等错误率最小的阈值对{t1o,t2o},其中t1o和t2o分别表示选定的二值化阈值和判决阈值。
作为优选的技术方案,所述平滑处理采用核大小为3的高斯低通滤波器进行平滑处理。
作为优选的技术方案,所述对二值掩膜cmsbk计算信任机制下面部交并比cfiouk,具体计算方式为:
cfiouk=(cs1k∩cs2k)/(cs1k∪cs2k+p×(cs1k∪cs2k-cs1k))
其中,cs1k为第k张图片ck中人脸区域,cs2k为二值掩膜cmsbk中待定篡改区域,p为信任机制的惩罚因子。
作为优选的技术方案,所述计算得到判断的准确率和平均错误率具体步骤为:
在测试集中图片张数设为l,l张图片中包括l1张真脸图片和l2张假脸图片,设l1内l1a张被判断成真脸,l1b张被判断成假脸,l2内l2a张被判断成真脸,l2b张被判断成假脸;
准确率acc具体计算方式为:
平均错误率hter具体计算方式为:
其中,far表示虚警率,fnr表示漏检率。
本发明还提供一种基于信任机制下面部交并比的假脸视频检测系统,包括:
网络训练模块、样本测试模块和数据划分模块,所述网络训练模块包括模型训练子模块和模型验证子模块;
所述数据划分模块用于将数据集划分为源训练集、源验证集和源测试集;
所述模型训练子模块包括源训练集预处理单元和分割网络训练单元,所述源训练集预处理单元用于对所述源训练集进行图像预处理后得到训练集图片x,训练集正确掩膜y;
所述模型验证子模块包括源验证集预处理单元、验证集图片预测掩膜单元、第一去噪单元、二值化阈值和判决阈值选定单元,所述源验证集预处理单元用于对所述源验证集进行图像预处理后得到验证集图片,所述预测掩膜单元用于采用训练好的分割网络预测验证集图片的掩膜,确定待检测区域,所述第一去噪单元用于对验证集图片预测掩膜进行平滑处理得到去噪后的掩膜,所述二值化阈值和判决阈值选定单元用于采用网格搜索法进行搜索,并将验证集图片预测掩膜进行二值化处理、面部交并比计算和二分类判决后选定二值化阈值和判决阈值;
所述样本测试模块包括源测试集预处理单元、测试集图片预测掩膜单元、第二去噪单元、二值化单元、面部交并比计算单元和二分类判决单元,所述源测试集预处理单元用于对所述源测试集进行图像预处理后得到测试集图片,所述测试集图片预测掩膜单元用于采用训练好的分割网络预测测试集图片的掩膜,确定待检测区域,所述第二去噪单元用于对测试集图片预测掩膜进行平滑处理得到去噪后的掩膜,所述二值化单元用于采用所述选定二值化阈值对去噪后的掩膜进行二值化处理,得到二值掩膜;所述面部交并比计算单元用于设置信任机制的惩罚因子,对二值掩膜计算信任机制下面部交并比;所述二分类判决单元用于采用所述选定判决阈值对面部交并比进行二分类判决,逐帧判断测试集图片的真假,计算得到判断的准确率和平均错误率。
本发明与现有技术相比,具有如下优点和有益效果:
(1)本发明使用分割网络进行像素级的预测确定待检测篡改区域后再进行分类判决,为假脸视频检测提供了一种有效途径,达到了有效提高了泛化能力的效果。
(2)本发明根据假脸篡改的先验知识,定义了独特的面部交并比作为判决指标,达到了有效量化描述篡改区域的效果。观察分析得到大部分篡改区域都出现在人脸区域的先验知识,利用分割网络对背景区域的预测,对不信任的待定篡改区域进行惩罚,提出了信任机制,改进了面部交并比的计算公式,达到了降低潜在虚警的效果。
(3)本发明利用验证集数据对二值化阈值和判决阈值的取值进行学习计算,具体是使用网格搜索的方式,找到等错误率最小情况下的阈值对,保证了取值的合理性和在实际应用的适应性。
附图说明
图1为本实施例基于信任机制下面部交并比的假脸视频篡改检测方法流程示意图;
图2为本实施例网络训练步骤的模型训练流程示意图;
图3为本实施例训练集选取的视频帧示例图;
图4为本实施例训练集视频帧人脸框与鼻尖点位置示例图;
图5为本实施例训练集视频帧矫正后人脸框与鼻尖点示例图;
图6为本实施例训练集正确掩膜示例图;
图7为本实施例训练集裁剪出的输入图片示例图;
图8为本实施例训练集裁剪出的正确掩膜示例图;
图9为本实施例网络训练步骤的模型验证流程示意图;
图10为本实施例验证集选取的视频帧示例图;
图11为本实施例验证集裁剪出的输入图片示例图;
图12为本实施例验证集的预测掩膜示例图;
图13为本实施例验证集的去噪后掩膜示例图;
图14为本实施例验证集的二值掩膜示例图;
图15为本实施例验证集裁剪出的正确掩膜示例图;
图16为本实施例验证集假脸图片示意图;
图17为本实施例样本测试步骤的流程示意图;
图18(a)和图18(b)分别为假脸图片和真脸图片可视化检测结果示例图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
实施例
如图1所示,本实施例提供一种基于信任机制下面部交并比的假脸视频检测方法,包括网络训练步骤和样本测试步骤,其中网络训练步骤包括模型训练步骤和模型验证步骤;
本实施例以在faceforensics++(ff++)数据库上进行训练,在ff++数据库上进行库内测试以及timit数据库上进行跨库测试为例,详细介绍本实例实施过程,实验在ubuntu16.04系统上进行,使用3.6版本的python语言和2.2.4版本的keras人工神经网络库,keras的后端为1.12.0版本的tensorflow,cuda版本为9.0.0,cudnn版本为7.1.4。
首先对ff++数据库和timit数据进行划分,以7:2:1的比例分为训练集、验证集和测试集,并使用opencv将三个测试集中的视频分帧并分别保存。
如图2所示,网络训练步骤中的模型训练具体步骤如下:
s1:对训练集中的每一视频帧进行预处理,采用dlib库中的卷积神经网络选取人脸框,并且采用2dfan算法对人脸68个标志点进行检测记录,根据检测出的鼻尖点位置,水平平移,矫正人脸框,以保证鼻尖点位于人脸框的垂直中心线上,根据检测出的鼻尖点位置平移矫正人脸框,目的在于减少人脸框在视频序列中的剧烈抖动;
如图3所示,本实施例选取的某一视频帧,如图4所示,选取人脸框对人脸标志点进行检测记录,记人脸框左上角点坐标为(x1,y1),右下角点坐标为(x2,y2),检测出鼻尖点位置,记鼻尖点坐标为(xn,yn),水平平移人脸框,使左上角点坐标为
s2:在视频帧和所对应的正确掩膜上,根据矫正后的人脸框位置裁剪出部分区域图片,并采样到同一分辨率,得到训练集图片为x={x1,x2,...,xn},训练集正确掩膜为y={y1,y2,...,yn},其中n为训练集图片总数,正确的掩膜表示ground-truth的篡改区域;
在本实施例中,裁剪图片区域为1.3倍人脸,采样方法为三次插值,输入图片分辨率为256×256,如图6、图7、图8并结合图3所示,在选取的视频帧和对应正确掩膜上,裁剪出输入图片和正确掩膜;
s3:搭建分割网络,输入为训练集图片xk,标签为裁剪后对应的正确掩膜yk,输出为预测的掩膜xmk,其中k=1,2,...,n;
在本实施例中,采用imagenet上预训练的vgg-16为骨架的fcn-8s,vgg-16的输入分辨率为256×256,具有rgb三通道的彩色图片,接着依次通过第一卷积模块、第二卷积模块、第三卷积模块、第四卷积模块和第五卷积模块;
第一卷积模块包括两个步长为1的64通道输入3×3卷积层和一个步长为2的2×2最大池化层;第二卷积模块包括两个步长为1的128通道输入3×3卷积层和一个步长为2的2×2最大池化层;第三卷积模块包括两个步长为1的256通道输入3×3卷积层和一个步长为2的2×2最大池化层;第四卷积模块包括两个步长为5的512通道输入3×3卷积层和一个步长为2的2×2最大池化层、第五卷积模块包括两个步长为5的512通道输入3×3卷积层和一个步长为2的2×2最大池化层,其中所有卷积层的激活函数为relu;
fcn-8s的输入为分辨率256×256,经过vgg-16骨架网络后,第五卷积模块的输出通过步长为1的4096通道输入7×7卷积层、relu激活函数、概率为0.5的随机失活层、步长为1的4096通道输入1×1卷积层、relu激活函数、概率为0.5的随机失活层、步长为1的2通道输入1×1卷积层、步长为2的2通道输入4×4反卷积层,与第四卷积模块的输出通过步长为1通道输入1×1卷积层后结果相加、步长为2的2通道输入4×4反卷积层,与第三卷积模块的输出通过步长为1通道输入1×1卷积层后结果相加、步长为8的2通道输入16×16反卷积层、softmax激活函数,输出为预测的掩膜;
在本实施例中,分割网络也可以使用fcn-8s以外的分割网络;
s4:构建分割网络训练的损失函数:
其中,(i,j)为掩膜上的坐标点位置,mk为掩膜的长度,nk为掩膜的宽度;
s5:设置分割网络参数优化算法:
本实施例采用adam算法进行参数优化,设置学习率为1×10-4,一阶平滑参数β1=0.9,二阶平滑参数β2=0.999,防止分母为0的常数e=1×10-8;
s6:输入为训练集x和标签为正确掩膜y训练分割网络;
s7:训练完成后保存分割网络模型和权重值。
如图9所示,本实施例网络训练步骤中的模型验证具体步骤为:
s1:对验证集中的每一视频帧进行预处理,采用dlib库中的卷积神经网络选取人脸框,并且用2dfan算法对人脸68个标志点进行检测记录,根据检测出的鼻尖点位置,水平平移,矫正人脸框,以保证鼻尖点位于人脸框的垂直中心线上,处理过程与模型训练时的步骤s1相同;
s2:在视频帧上,根据矫正后的人脸框裁剪出部分区域图片,并采样到同一分辨率,得到验证集图片为z={z1,z2,...,zq},其中q为验证集图片总数;
本实施例裁剪图片区域为1.3倍人脸,采样方法为三次插值,输入图片分辨率为256×256;
s3:采用训练好的分割网络预测验证集第k张图片zk的掩膜zmk,确定待检测区域,其中k=1,2,...,q;
如图10、图11、图12所示,本实施例选取验证集某一视频帧进行裁剪,得到验证集裁剪出的输入图片和预测掩膜;
s4:对预测掩膜zmk进行平滑处理得到去噪后的掩膜zmsk;
如图13所示,本实施例采用核大小为3的高斯低通滤波器对预测掩膜zmk进行平滑处理,得到去噪后的掩膜zmsk;本实施例也可以使用其他的数字低通滤波器进行平滑处理;
s5:以0为二值化阈值t1和判决阈值t2的初始值,s为步长进行网格搜索,本实施例中s取0.001;
s6:如图14所示,采用当前t1对zmsk进行二值化处理得到二值掩膜zmsbk;
s7:对二值掩膜zmsbk计算信任机制下面部交并比;
对于如图10所示的序号为k的视频帧,图11表示人脸区域,图14中白色点为预测的待定篡改区域,图15中白色点为正确的篡改区域,将三个区域画入一张示意图中,如图16所示,图中实线包围区域zs1k为人脸检测网络选取的人脸区域;点状线包围区域zs2k为二值掩膜中的待定篡改区域;虚线包围区域zs3k为正确掩膜中的篡改区域;
传统分割问题中篡改区域交并比的计算公式为(zs3k∩zs2k)/(zs3k∪zs2k),无法在假脸视频篡改检测的问题上直接作为判决依据,原因有两点:一是在测试阶段没有正确的篡改区域,二是在未篡改区域中,对于任意的检测区域,交并比始终为0。因此本发明首先利用所有对象都存在的人脸区域得到面部交并比zfiouk=(zs1k∩zs2k)/(zs1k∪zs2k),再利用分割网络对背景区域的预测结果和背景区域中篡改内容较少的先验知识,对zs1k∪zs2k-zs1k区域产生一定的不信任,构建信任机制降低潜在的虚警,增加惩罚项改进面部交并比的计算公式。本实施里以p=1为惩罚因子,信任机制下的面部交并比计算公式为:
zfiouk=(zs1k∩zs2k)/(zs1k∪zs2k+p×(zs1k∪zs2k-zs1k))
其中,zs1k为第k张图片zk中人脸区域,zs2k为二值掩膜zmsbk中待定篡改区域,p为信任机制的惩罚因子;
s8:使用当前t2对面部交并比zfiouk进行二分类判决,判断验证集中所有q张图片的真假,设q张图片中有q1张真脸图片和q2张假脸图片,其中q1内q1a张被判断成真脸,q1b张被判断成假脸,q2内q2a张被判断成真脸,q2b张被判断成假脸,得到虚警率(falsealarmrate)
s9:根据网格搜索法改变t1和t2的值,重复上述步骤s6至步骤s8,直至t1=1且t2=1,停止搜索;
s10:在上述搜索过程所记录的阈值对和等错误率结果中,寻找等错误率值最小的阈值对{t1o,t2o},则t1o和t2o分别为选定的二值化阈值和判决阈值。
在本实施例中,选定的二值化阈值和判决阈值是在模型验证中通过网格搜索的方式计算得到的,是等错误率最小情况下的阈值,不需要人为设置,具有较强的适应性。
如图17所示,本实施例样本测试步骤中对ff++数据库的库内测试具体步骤为:
s1:对测试集中的每一视频帧进行预处理:采用dlib库中的卷积神经网络选取人脸框,并且用2dfan算法对人脸68个标志点进行检测记录,根据检测出的鼻尖点位置,水平平移,矫正人脸框,以保证鼻尖点位于人脸框的垂直中心线上,处理过程与模型训练时步骤s1相同;
s2:在视频帧上,根据矫正后的人脸框裁剪出部分区域图片,并采样到同一分辨率,得到测试图片集合为c={c1,c2,...,cl},其中l为测试图片总数;
本实施例中裁剪图片区域为1.3倍人脸,采样方法为三次插值,输入图片分辨率为256×256;
s3:采用训练好的分割网络预测测试集的第k张图片ck的掩膜cmk,确定待检测区域,其中k=1,2,...,l;
s4:对cmk进行平滑处理得到去噪后的掩膜cmsk;
本实施例采用核大小为3的高斯低通滤波器对预测掩膜cmk进行平滑处理,得到去噪后的掩膜cmsk;本实施例也可以使用其他的数字低通滤波器进行平滑处理;
s5:采用网络训练步骤选定的二值化阈值t1o对cmsk进行二值化处理得到二值掩膜cmsbk;
s6:对cmsbk计算信任机制下面部交并比:
cfiouk=(cs1k∩cs2k)/(cs1k∪cs2k+p×(cs1k∪cs2k-cs1k))
其中,cs1k为第k张图片ck中人脸区域,cs2k为二值掩膜cmsbk中待定篡改区域,p为信任机制的惩罚因子,本实施例的p取1;
s7:使用网络训练步骤选定的判决阈值t2o对cfiouk进行二分类判决,逐帧判断l张测试图片的真假,设l张图片中有l1张真脸图片和l2张假脸图片,其中l1内l1a张被判断成真脸,l1b张被判断成假脸,l2内l2a张被判断成真脸,l2b张被判断成假脸,给出准确率(accuracy)
在本实施例中,网络训练的模型训练步骤s2、模型验证步骤s2和样本测试步骤s2中,裁剪后的图片中除了人脸区域还包括部分背景区域,目的在于让网络获得更多背景信息,同时保证后续信任机制中惩罚项的有效计算;
在本实施例中,模型验证步骤s4和样本测试步骤s4中,进行平滑去噪的原因是因为分割网络进行像素级的预测时像素点之间的关联性较弱,易出现孤立噪声点,考虑到假脸视频中篡改区域在人脸中占比较大,并且本实施例旨在于进行二分类判决判断真假脸的存在性,因此使用低通滤波器去除这些噪声点,得到去噪后的掩膜;
在本实施例中,模型验证步骤s6和样本测试步骤s5中,对去噪后掩膜进行二值化的原因是因为目前得到的掩膜是0-1之间的概率图,无法直接进行二分类判决,因此根据阈值进行二值化处理,得到待定篡改区域的位置和面积信息;
在本实施例中,模型验证步骤s7和样本测试步骤s6中,提出的面部交并比有效利用了提前检测出的人脸区域,能够在网络训练和样本测试中有效使用,同样适用于实际场合下对一个未知视频的检测;
在本实施例中,模型验证步骤s7和样本测试步骤s6中,面部交并比引入了信任机制的原因是因为大部分假脸篡改区域都出现在人脸中,因此本实施例对人脸外的预测篡改区域进行惩罚,进而优化了面部交并比这一指标,提高了模型的泛化能力,惩罚因子p可选取大于0的数值,两个步骤的p取相同值;
在本实施例中,跨库测试对timit数据测试集进行相同的测试步骤,得到准确率和平均错误率,网络训练步骤得到二值化阈值t1o为0.439,判决阈值t2o为0.2347,库内测试中ff++验证集的等错误为2.12%,测试集的平均错误率为2.05%,准确率为97.91%;跨库测试中timit测试集的平均错误率为22.64%,准确率为79.54%。如图18(a)和图18(b)所示,检测可视化示例图包括原始视频帧、正确的未裁剪掩膜、正确的裁剪后掩膜、库内测试得到的二值掩膜、跨库测试得到的二值掩膜,可以看出,不论是在库内测试还是跨库测试中,本实施例能够有效得到假脸图片的篡改区域,并且能够将真脸图片的所有区域识别为未篡改区域。由此可知,与其他现有技术相比,本实施例的方法库内测试准确率较高,跨库测试的平均错误率较低,验证了有效性,本实施例利用神经网络分割待检测视频帧以后,计算信任机制下的面部交并比作为真假脸判决的准则,具有泛化能力强的特点。
本实施例还提供一种基于信任机制下面部交并比的假脸视频检测系统,包括:
网络训练模块、样本测试模块和数据划分模块,网络训练模块包括模型训练子模块和模型验证子模块;数据划分模块用于将数据集划分为源训练集、源验证集和源测试集;
在本实施例中,模型训练子模块包括源训练集预处理单元和分割网络训练单元,源训练集预处理单元用于对源训练集进行图像预处理后得到训练集图片x,训练集正确掩膜y;
在本实施例中,模型验证子模块包括源验证集预处理单元、验证集图片预测掩膜单元、第一去噪单元、二值化阈值和判决阈值选定单元,源验证集预处理单元用于对源验证集进行图像预处理后得到验证集图片,预测掩膜单元用于采用训练好的分割网络预测验证集图片的掩膜,确定待检测区域,第一去噪单元用于对验证集图片预测掩膜进行平滑处理得到去噪后的掩膜,二值化阈值和判决阈值选定单元用于采用网格搜索法进行搜索,并将验证集图片预测掩膜进行二值化处理、面部交并比计算和二分类判决后选定二值化阈值和判决阈值;
在本实施例中,样本测试模块包括源测试集预处理单元、测试集图片预测掩膜单元、第二去噪单元、二值化单元、面部交并比计算单元和二分类判决单元,源测试集预处理单元用于对源测试集进行图像预处理后得到测试集图片,测试集图片预测掩膜单元用于采用训练好的分割网络预测测试集图片的掩膜,确定待检测区域,第二去噪单元用于对测试集图片预测掩膜进行平滑处理得到去噪后的掩膜,二值化单元用于采用选定二值化阈值对去噪后的掩膜进行二值化处理,得到二值掩膜;面部交并比计算单元用于设置信任机制的惩罚因子,对二值掩膜计算信任机制下面部交并比;二分类判决单元用于采用选定判决阈值对面部交并比进行二分类判决,逐帧判断测试集图片的真假,计算得到判断的准确率和平均错误率。
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!