一种基于商用WiFi的位置自适应动作识别方法与流程
本发明涉及一种动作识别技术,尤其涉及一种基于商用wifi的位置自适应的动作识别技术。
背景技术:
动作识别通常指对人们执行的动作进行监测和识别的过程。准确的识别动作在许多场合都有着重要意义。例如:通过室内日常动作识别,可以实现居家安全监控,对异常动作的发生及时做出判断和预警;通过对驾驶员的动作识别,可以监测驾驶员的行为操作是否安全合法,从而协助驾驶员安全驾驶,降低交通事故的发生概率;实时准确的动作识别还可以应用到体感游戏、人机智能交互等场景,提高人们的生活质量。
目前主流的动作识别技术通常基于视频监控或可穿戴设备。基于视频监控的方法能够高精度识别出人的动作。但是,视频监控非常依赖于环境中的光线条件,在光线条件很差或有障碍物遮挡的情况下无法进行识别。另外,视频监控存在隐私泄露问题,不适合部署在卫生间浴室等隐私场景。基于可穿戴设备的动作识别方法不存在隐私侵犯问题,也不需要光线条件,但是要求人时刻佩戴设备才能进行识别,对人的主观意愿有较强依赖性。
信道状态信息(channelstateinformation,csi)是wifi物理层信息,描述信号在每条传输路径上的衰弱因子,能够反映信号散射、环境衰弱、距离衰减等信息。利用csi可以感知环境中的细微变化,当人在覆盖wifi的房间内进行不同动作时,会对wifi信号的传播造成不同影响,使得采集到的csi幅值和相位发生不同变化,这使得采用csi来进行动作识别成为可能。采用基于商用wifi的方法进行人的动作识别,能够有效解决弱光、无光及遮挡情况下的动作识别,不存在隐私侵犯,也不需要人们穿戴任何设备,是一种低成本、普适性、无侵犯的动作识别方法。
但是,当人在不同位置进行动作时,不仅动作会导致csi变化,人所处的位置也会对csi产生影响,也就是说,csi的变化是位置和动作的叠加结果。如果只用单个位置的动作数据来训练识别模型,则在其它位置上的动作识别效果就会很差;而如果使用所有位置的动作数据来训练识别模型,对数据贴标基于人工介入会消耗大量资源,对于较大的监控环境不可行。
伪标签学习是一种半监督学习方法,先使用高成本的有标签数据训练分类模型,再将数据量大且低成本的无标签数据输入这个分类模型,模型输出的分类结果作为无标签数据的伪标签;之后,再使用有标签数据与伪标签数据重新训练分类模型,将完成训练后的分类模型作为最终的分类模型。伪标签学习使用少量有标签数据结合大量无标签数据,相对于仅使用少量有标签数据的学习方法,能提高决策边界的精确性与模型的稳健性。
技术实现要素:
本发明所要解决的技术问题是,提出一种在利用商用wifi设备的进行位置自适应的动作识别过程中,通过生成更精确的伪标签从而提升分类效果的方法。
本发明为解决上述技术问题所采用的技术方案是,一种基于商用wifi的位置自适应动作识别方法,包括以下步骤:
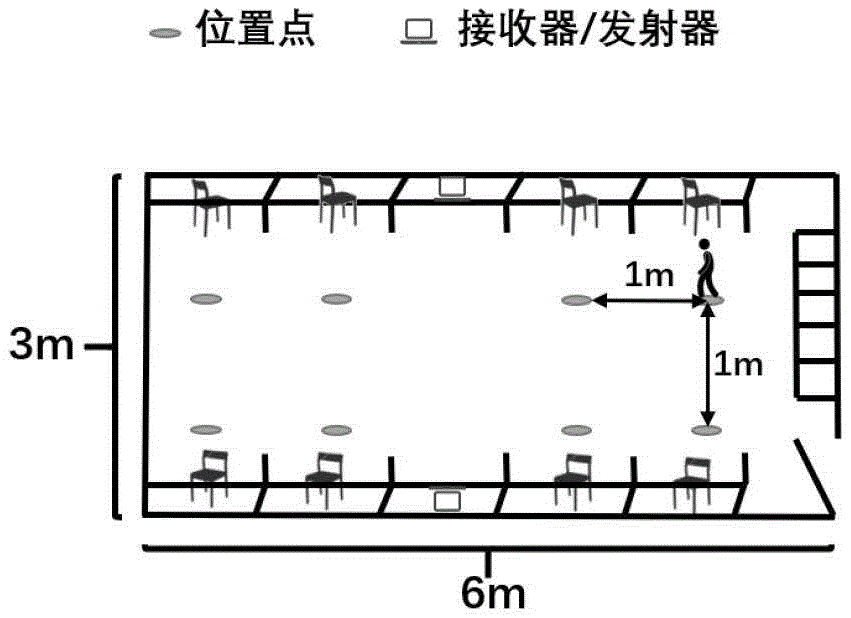
1)监测环境部署:将一对wifi发射器和接收器部署在房间两端;
2)在房间内选取若干个位置作为执行动作的位置,在每个位置上进行若干次动作,采集每个位置上每种动作的csi数据并提取csi幅值数据;
3)在执行动作的位置中选取部分位置作为源域,其余位置作为目标域;源域上的csi幅值数据带有动作标签,目标域上的csi幅值数据没有动作标签;理论上源域的位置选的越多,精度越高,但同时数据采集和训练模型的成本也越高。实际操作时,源域在可接受的精度上尽可能选少的位置。
4)对所有csi幅值数据进行奇异谱分析从而提取趋势分量成分作为趋势信号,源域上的带有动作标签的趋势信号为源域数据,目标域上的没有动作标签的趋势信号为目标域数据;
5)建立双评分多分类器集成学习模型作为标签模型,对目标域数据贴伪标签,包括以下步骤:
5-1)利用源域数据作为动作样本来训练标签模型,并对标签模型进行评分,将平均分类精度作为分类器评分sr,将每种动作的分类精度作为类别评分sc:
sr中每个元素
sc中每个元素
5-2)利用建立好的标签模型,将目标域数据输入到标签模型中,标签模型输出该目标域数据的各项分类概率pij;再将对应的分类器评分以及类别评分作为分类概率的加权项,计算出该目标域数据的在每个分类器处的评分sij:
pij为被第i个分类器分成第j个类别的概率;
最终计算出该目标域数据的总评分sj,取总评分最高的类别为目标域数据贴上伪标签label:
6)利用源域数据和带有伪标签的目标域数据共同作为动作样本来训练分类模型,源域数据和带有伪标签的目标域数据涵盖了房间内部分位置,训练出的分类模型能够泛化到房间中未采集数据的位置。
本发明根据人体动作对csi产生影响的原理,从csi数据中提取幅值信息,首先利用奇异谱分析的方法获得趋势分量成分,然后通过伪标签半监督学习将分类模型的动作识别能力泛化到所有位置上去,在进行半监督学习时采用双评分多分类器,双评分机制将分类器评分以及类别评分作为分类概率的加权项提高了评分精度,实现位置自适应的高精度动作识别。
进一步的,在标签模型以及分类模型的选择上,因为样本是时序数据,所以选择使用lstm来做基本的模型。分类器的双层结构比单层结构能够学习到更深层的信息,因此分类效果会比单层的好一些,但是训练的时间成本会更高,标签模型因为由多个分类器组成,学习的成本较高,所以用单层的lstm,比用双层结构降低了时间成本。当所有输入样本均有标签的情况下,无需使用多分类器结构,因此分类模型只有1个分类器,为了提升分类准确率,所以该分类器采用双层结构。
本发明的有益效果是,通过实验表明本发明能够达到针对所有位置约85%的动作识别正确率,比直接使用源域模型的精度提升了约40%,并且能够泛化到未采集动作数据的位置。
附图说明
图1为实验环境示意图;
图2为实施流程图;
图3为奇异谱分析信号分解图;
图4动作识别准确率。
具体实施方式
基于wifi的位置自适应动作识别方法要求在室内覆盖wifi信号。部署设备为一台wifi发射器和一台wifi接收器,均配置intelwirelesslink5300agn(iwl5300)无线网卡,发射器网卡和接收器网卡均配置3根天线,因此共包括9个天线对,每个天线对包含30条子载波。wifi发射器以100hz的发包率发射csi数据。实验环境示意图如图1所示。
本方法首先建立基于多分类器的集成学习标签模型,基分类器采用长短时记忆循环神经网络(longshort-termmemory,lstm),实施流程如图2所示,然后通过标签模型对无标签动作数据贴伪标签,最后用真实标签动作数据和伪标签动作数据共同训练得到位置无关动作识别模型。步骤如下:
步骤1:选取若干位置,在每个位置上执行动作并采集csi数据,每次动作采集10秒数据;
步骤2:在执行动作的位置中,选取部分位置作为源域,对源域中的动作数据设置对应的动作标签,其它位置作为目标域,对目标域中的动作数据不设置动作标签;
步骤3:对所有csi动作数据提取幅值信息,然后进行奇异谱分析,提取趋势分量成分,包含以下步骤:
步骤3-1:将每条csi子载波数据转化得到轨迹矩阵。假设x表示转化后的轨迹矩阵,xi表示数据包编号为i的csi幅值,n表示动作结束时刻所对应的数据包编号,l为选取的窗口长度,轨迹矩阵x如下:
步骤3-2:对轨迹矩阵x进行奇异值分解。令u表示l×l阶的酉矩阵,σ表示l×(n-l+1)阶半正定对角矩阵,v是(n-l+1)×(n-l+1)阶酉矩阵,vt是v的共轭转置矩阵,得到奇异值分解后的轨迹矩阵x′:
x′=uσvt
步骤3-3:将进行奇异值分解后的轨迹矩阵进行分组并重构,得到各组不同的分量成分,提取其中的趋势信号分量。假设
步骤4:训练基于多分类器集成学习标签模型,标签模型中的分类器基于双向lstm模型,具有6个分类器,每个分类器具有一层包含128个节点的隐藏层,包括以下步骤:
步骤4-1:将源域数据输入到标签模型中,提取动作数据时序特征:
f=lstm(x″;θ)
x″表示输入的源域数据,θ是循环神经网络参数,f为提取后的特征信息。
步骤4-2:利用softmax函数对提取特征后的动作数据进行分类,令p表示动作被分成各类的概率,wf和bf分别表示权重和偏置系数:
p=softmax(wf·f+bf)
步骤4-3:训练标签模型,获得多分类器评分
步骤4-4:训练标签模型,获得类别评分sc:
步骤5:利用训练好的标签模型为目标域中未带动作标签的动作数据贴上伪标签,包含以下步骤:
步骤5-1:将无标签动作数据输入到标签模型中,计算动作数据被第i个分类器分成第j个类别的得分sij,pij为被第i个分类器分成第j个类别的概率:
步骤5-2:计算该动作数据被分成各个类别的总得分sj,m表示分类器个数:
步骤5-3:具有最大得分的类别就是为该动作数据贴上的伪标签label:
步骤6:用带有真实动作标签的位置的数据和贴有伪标签的位置的数据共同训练动作分类模型,动作分类模型使用1个双层双向lstm分类器,该分类器的第一层隐藏节点数为128,第二层隐藏节点数为64,学习率为0.0001,得到最终的能够用于所有位置的动作识别模型,包括未采集动作数据的位置。
实施例的识别准确率如图4所示,表明本发明方法实施的两个场景,在会议室能够达到针对所有位置约82%的动作识别正确率,在大厅能够达到针对所有位置约85%的动作识别正确率,比直接使用源域模型的42%和40%,本发明方法的识别精度提升了约40%。
- 还没有人留言评论。精彩留言会获得点赞!