一种基于自注意力机制的从人眼生成人脸的方法
本发明设计了一种基于自注意力机制的从人眼生成人脸的方法,涉及计算机视觉、深度学习和公共安全技术领域。
背景技术:
随着人脸识别技术的进步,其应用越来越广泛,目前人脸识别技术在一些在公开人脸库celeba和lfw上已经超过98%的识别率。但是在实际的应用环境中,场景不同识别效果也差异比较大,在一些近距离能够清晰摄取到完整人脸的场所识别效果也很好,如火车站、机场、考场、移动支付等;而受距离、光照、背景、遮挡等因素干扰的场所,识别效果还不尽如人意,如公共安全领域,犯罪破坏分子通常都是蒙着面,能获取到的人脸只有其眼睛信息可见这给识别带来了挑战。
随着公共监控的发展,在公共场所基本都普及和安装了监控摄像头,能够实时摄取到违法犯罪和恐怖分子的头像,但是他们通常是将脸部信息遮住只将两只眼睛的信息暴露出来,执法人员对这些蒙面人的身份很难进行辨认,在执法过程中对犯罪分子的搜索和锁定难度较大。目前主流的人脸识别技术都是针对完整人脸进行识别的,只根据眼睛信息进行人脸识别的识别率较低,为此开展根据人的眼睛进行人脸识别的研究非常有必要,也具有重要意义。
现在的人脸识别方法主要分为传统机器学习和深度学习两大类:传统机器学习在人脸识别领域的应用研究已经取得了众多的突破,其中典型的方法有:(1)基于模板匹配法的分类方法;(2)基于提取人脸几何特征的识别方法;(3)基于数理统计的识别方法,主要方法包括:奇异值分解(singularvaluedecomposition,svd)分类法、kl(karhunen-loeve)算法识别、隐马尔可夫(hiddenmarkovmodel,hmm)算法等这些算法,以上算法都取得了较高的识别率。随着深度学习技术的发展,基于深度学习的人脸识别方法的研究也成为发展趋势,识别率较传统方法有了很大的提升,甚至基于深度学习的最新方法在公开人脸数据集celeba和lfw上目前已经超过了人类的识别率。其中典型的卷积神经网络(convolutionalneuralnetwork,cnn)利用梯度下降和反向传播机制,能够自适应地学习卷积核的参数并提取人脸特征进行对比识别,这种方式比起传统机器学习方法中人工设计的特征提取方式更为科学,实践也证明了更有效;同时对抗生成网络(generativeadversarialnetworks,gans)技术也在图像生成和计算机视觉领域取得了突破性的进展。
技术实现要素:
本发明为解决上述问题提拱了一种基于自注意力机制的从人眼生成人脸的方法。在公共安全领域,犯罪分子通常是将其大部分人脸信息遮住只露出双眼,为了对他们进行有效识别,本发明设计了先根据人眼生成对应的人脸,然后再对人脸进行识别的流程和方法,通过基于自注意力机制对抗生成网络挖掘人眼和人脸之间的内部映射关系,根据人眼生成逼真的人脸,并用典型的人脸识别网络facenet对生成人脸进行识别,识别率达可到94%以上,生成人脸整体效果较好,识别率可达94%以上,可为相关部门提供技术支撑。
本发明通过以下技术方案来实现上述目的:
1.本发明提供的深度神经网路模型需要在专用的数据集上进行训练,目前尚未有人眼到人脸(eyes-to-face)生成的公开数据集,为此第一步需要自己构建数据集,其步骤及要求如下:
(1)通过公开的人脸识别数据集celeba和lfw、网络资源等获取人脸原始图像,并将其归一化到统一大小256×256;
(2)通过自编软件工具提取出步骤(1)中所得人脸的眼睛部分图像,并将人脸其余部分的图像信息擦除;
(3)将步骤(2)所得的人眼图像归一化到统一大小256×256;
(4)将步骤(1)中原始人脸图像与步骤(3)所得与之对应的人眼图像组成数据对,并组合成大小为512×256的单幅图像作为一个训练数据对,最终组成从人眼到人脸生成(eyes-to-face)的数据集,本发明构建的数据集取名叫scu-eyes。
2.本发明提供的一种基于自注意力机制的从人眼生成人脸的方法,其中具体的网络模型结构及原理如下所述:
(1)本发明提供的基于自注意力机制对抗生成网络,其网络结构为:由两个生成器(generator)和两个鉴别器(discriminator)组成的循环对抗生成网络,其中生成器中的编解码器(encoder-decoder)是用的卷积神经网络u-net,在生成器中加入自注意力机制(self-attentionmechanism)去引导生成器的训练,生成器的损失函数包括gans损失,人脸特征损失,l1、l2损失,kl损失的加权和用于引导生成器的训练,整个训练过程是生成器和鉴别器不断循环博弈的结果,该模型的总损失函数如下所示:
其中l1gan(g,d)和l2gan(g,d,e)为gan的损失函数,l1(g,e)和l1(g,e)是图像像素分布损失函数,fl(epr)为特征损失函数,lkl(e)为条件噪声分布损失函数。
(2)本发明在模型训练过程中用预训练好的人脸特征提取网络resnet去提取生成的人脸和原始人脸的特征,并计算有条件的噪声损失和人脸特征损失,反馈到网络中引导模型的训练训练,让生成的人脸更接近本人,其特征损失函数如下所示:
其中epr()表示预训练好的resnet网络,
(3)本发明加入自注意力机制(self-attentionmechanism)去引导模型中生成器的训练,能够让模型更好地学习到人眼与人脸的内部映射关系,生成更加逼真的人脸。将注意力模型嵌入到生成器的编解码器中的两个卷积层之间,将编解码器中上一卷积层输出的特征向量x输入到注意力模型中进行计算,计算后注意力模型输出的值oj与x进行加权求和后作为编解码器下一卷积层的输入,其原理及公式如下所示:
其中,f(x)=wfx,g(x)=wgx,h(x)=whx;x是自注意力模型的输入;f(x)、g(x)、h(x)是图像的三路1×1conv卷积特征向量;wf、wg、wh为权重。
yi=γoi+xi
其中oj表示自注意力模型的输出,yi作为编解码器下一卷积层的输入。
(4)本发明提出的深度神经网络模型经过实验验证,当训练到300~400epochs时达到最佳收敛效果,此时模型训练完成,该模型将用于下一步进行人眼图像生成人脸图像。
(5)生成的人脸图形用一个预训练的深度卷积神经网络进行识别,进而对判别出所识别人脸的身份。
本发明针对只有人眼信息的人脸识别提出了一个解决方案,设计的从人眼生成人脸的深度神经网络能够生成与原始人脸更接近的人脸,有效地提升了识别率,在公共安全和涉恐等领域都有较大的应用前景。
附图说明
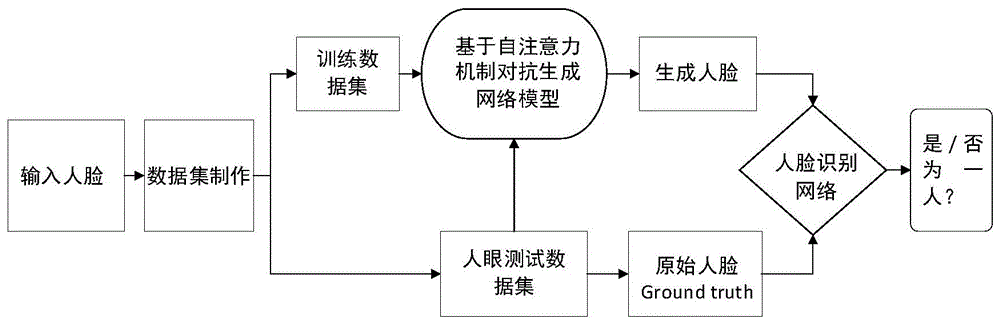
图1是本发明提出的方案流程图
图2是本发明提出的从人眼生成人脸训练数据集的样例
图3是本发明设计的基于人眼生成人脸的算法结构图
图4是本发明在生成器中嵌入自注意力机制示意图
具体实施方式
下面结合附图对本发明作进一步说明:
如图1所示,一种基于自注意力机制的从人眼生成人脸的方法,有如下工作步骤:
步骤一:数据集制作,基于公开人脸数据集中的人脸图像构建从人眼生成人脸的数据集;
步骤二:网络模型训练,将基于注意力机制对抗生成网络(self-attentionmechanismgenerativeadversarialnetworks,gans)在步骤一构建的数据集上进行训练,并通过多轮参数调整完成模型训练;
步骤三:人眼图像预处理,即按照要求将人脸图像中的人眼部分提取出来,并且对其进行归一化处理;
步骤四:从人眼生成人脸,将步骤三预处理后的人眼图像输入到步骤二已训练好的神经网络网络模型中完成人脸图像的生成;
步骤五:人脸识别,即将合成的人脸与原人脸(groundtruth)在人脸识别网络中进行身份识别验证。
图2是自构建数据集中的数据对样本,每个样本是一副512×256大小的图像,左半部分图像是右半部分人脸所对应的眼睛。
图3是基于自注意力机制对抗生成网络设计实现的一个端到端的从人眼生成人脸的网络。
具体设计如下:
由两个生成器(generator)和两个鉴别器(discriminator)组成的循环对抗生成网络,其中生成器中的编解码器(encoder-decoder)是用的卷积神经网络u-net,在生成器中加入自注意力机制(self-attentionmechanism)去引导生成器的训练,生成器的损失函数包括gans损失,人脸特征损失,l1、l2损失,kl损失的加权和用于引导生成器的训练,整个训练过程是生成器和鉴别器不断循环博弈,直到生成的人脸与原始人脸(groundtruth)让鉴别器无法区分为止。
图4是本发明引入的自注意力机制示意图,加入自注意力机制(self-attentionmechanism)去引导模型生成器的训练,能够让模型更好的学习到人眼与人脸的内部映射关系,生成更加真实的人脸。
- 还没有人留言评论。精彩留言会获得点赞!