一种水电数据库自动建表分表的方法与流程
本发明涉及用于水利和发电专业大数据存储等科学研究中的大规模测量数据存储和访问,尤其涉及一种水电数据库自动建表分表的方法。
背景技术:
如今随着智能化水电厂的发展,数据的量级也是呈指数的增长,从gb到tb到pb。对数据的各种操作也是愈加的困难,传统的关系性数据库已经无法满足快速查询与插入数据的需求。而水电业务的使用场景是绝对要有事务与安全指标的。这个时候nosql肯定是无法满足的,所以还是需要使用关系性数据库。
目前水电系统所使用的商用数据库或者开源数据库一般都不支持大规模自动建表扩展,单表上面存在着性能瓶颈。一般的数据库单表超过1000w~2000w条记录时,性能就会有比较明显的下降。为了提升性能以及可以存储数据的量,需要针对工程特点、水电各专业特点等进行分表。
对于数据量很大的表(千万级以上),关系型数据库性能会有很大下降,因此尽量控制在每张表的大小在百万级别。对于数据量很大的一张表,可以考虑将这些记录按照一定的规则通过分片放到不同的数据表里面。这样每个数据表的数据量不是太大,性能也不会有太大损失。
数据库分片指:通过某种特定的条件,将存放在一个数据库表中的数据分散存放在不同的多个数据表中,这样来达到分散单表的容积,当数据库表分片后,数据由一个数据表分散到多个数据表中。此时系统要查询时需要切换不同的数据表进行查询,那么系统如何知道要查询的数据在哪个数据表中,当添加一条记录时要向哪个数据表中插入呢。
技术实现要素:
本发明的目的是展示利用虚拟数据库技术实现一个低成本高效率可以无限扩展的水电行业自动建表分表的方法。虚拟数据库技术就是构建一个逻辑数据库,它利用标准的数据库通讯协议对外提供无差别的数据库访问服务。所有的水电业务组件和模块的数据访问层统一访问逻辑库,由这个虚拟逻辑库去统一管理数据子表的访问和路由。
该方法能够根据水电业务提交的各种数据库请求进行解析,精确为所有请求路由至不同的子表进行真实数据库访问,对访问的结果按照请求类型进行合并和排序反馈回水电业务端,水电业务端完全不需了解底层数据库的细节。
本发明的技术方案:
一种水电数据库自动建表分表的方法,包括以下步骤:
1)虚拟数据库前端按照mysql数据库标准底层通讯协议建立数据库服务侦听,后端按照真实的数据库连接信息、用户名和密码建立物理数据库连接线程池,水电业务系统按照真实的mysql的链接信息连接到虚拟数据库;
2)水电业务系统的数据访问层向虚拟数据库提交sql请求,虚拟数据库侦听到sql请求语句,将sql请求语句进行解析,比对预设的分表表名和分表算法,查看该条sql请求语句是否需要进行分表处理;如果该条语句无需进行分表处理,直接将该请求提交至后端物理数据库;
3)对于需要进行分表处理的sql请求语句,解析语句查询条件,根据预设的分表算法计算出该条语句涉及的子表名称,按语句类型、排序和分组进行类别归类;
4)根据子表名称查询子表缓存,查看子表在物理数据库是否存在,如果不存在,在物理数据库创建相应的子表,如果存在该子表,表示该子表已经被创建,则进入步骤5),对该子表进行请求提交;
5)对提交的sql请求语句进行修正,将其拆分成多个子表请求,将所有请求异步提交给物理数据库执行,将每个子表请求的返回结果放置缓存于结果集;等待所有子表请求完成,进入步骤6)进行结果集合并;
6)所有的子查询结果集按照步骤3)整理的类别进行归并处理,将归并的结果集按照标准的mysql协议返回给水电业务系统。
进一步地,步骤2)中,分表处理的方法为:通过sql语法分析器,将输入sql请求语句的查找条件、子查找条件和分表字段值处理进行缓存分析,循环计算分表范围,确定所有的分片节点以后,对所有分片并行进行子表语句执行。
进一步地,分表处理的内容包括定义表的分片规则来实现分片,每个表格捆绑一个分片规则,每个分片规则指定一个分片字段并绑定一个函数,来实现动态分片算法。
进一步地,当用来进行分表的逻辑库收到一个sql请求语句时,先解析这个sql请求语句,查找涉及到的表,然后查看此表的定义,如果有分片规则,则获取到sql请求语句里分片字段的值,并匹配分片函数,得到该sql请求语句对应的分片列表,然后将sql请求语句发往这些分片去执行,最后收集和处理所有分片返回的结果数据,并输出到客户端。
进一步地,步骤4)中,子表创建的步骤为:预先设置子表创建脚本模板,当子表不存在时,子表结构直接模仿主表进行复制创建。
进一步地,将主表的约束和主表触发器复制给子表,相关的约束和触发器按照模板进行自动创建。
进一步地,步骤6)中的归并处理包括再排序和分组。
进一步地,在所述虚拟数据库定义线程池,与真实的物理数据库建立连接,当多条sql请求语句请求处理时,并发构建多个会话和物理数据库进行通讯。
进一步地,所述虚拟数据库中的分表配置中心构建有分表算法注册中心,直接参与分表的表名、字段名以及指定分表算法的实现类路径。
本发明的优点:
对比以往的数据库分库分表方法,本方法主要在以下方面取得了改进:
一、提供基于标准数据库通讯协议的数据库服务,对客户端屏蔽数据库分表的细节,实现数据库分表与应用业务数据访问的解耦,大大减少应用程序数据访问的复杂性。
二、基于预先定义的库表构建脚本模板,实现了库表以及库表相关的约束、触发器的自动生成,理论上可实现库表自动无限扩充。
三、充分利用了异步现场sql提交,极大地提高了数据查询的速度。
四、通过代理拦截,将分表算法独立于数据访问逻辑,分表策略可根据工程现状进行二次开发,充分满足个性化的分表需求,降低了开发成本。
附图说明
图1为本发明的分表示意图;
图2为本发明的分片规则示意图;
图3为本发明的框架组件图;
图4为本发明的工作流程图。
具体实施方式
本发明的利用虚拟数据库技术实现水电数据库自动建表分表的方法,如图4所示,其过程是包括以下步骤:
1)虚拟数据库程序前端按照mysql数据库标准底层通讯协议建立数据库服务侦听,后端按照真实的数据库连接信息、用户名和密码等建立物理数据库连接线程池,水电业务系统按照真实的mysql的链接信息连接到虚拟数据库。
2)水电业务系统数据访问层向虚拟库提交数据库的sql请求,虚拟库侦听到sql请求,将sql语句进行解析,比对预先设定的分表表名和分表算法,查看该条sql语句是否需要进行路由和分片。如果该条语句无需进行分表处理,直接将该请求提交至后端物理数据库。
3)对于需要进行分表的sql语句,解析语句查询条件,根据该工程的分表算法计算出该条语句涉及的子表名称,对语句类型、排序、分组等进行类别归类
4)查询子表缓存,查看子表在物理数据库是否存在,如果不存在,在物理库构建相应的子表,将主表的约束和主表触发器复制给子表并重新命名。如果存在该子表,表示该子表已经被创建,则进入第5步,对该子表进行请求提交。
5)对原来提交的sql请求进行修正,将其拆分成多个子表请求,将所有请求异步提交给物理库进行出来,将每个子表请求的返回结果放置缓存结果集。等待所有子表请求完成,进入第6步进行结果集合并。
6)所有的子查询结果集按照第三步整理的操作类别进行归并处理,包括再排序和分组等等,将归并的结果集按照标准的mysql协议返回给水电业务系统调用方。
水情水调系统数据库分表的原理是通过拦截客户端应用发送过来的sql语句,首先对sql语句做了一些特定的分析:如分片分析、路由分析、读写分离分析、缓存分析等,然后将此sql发往后端的真实数据库,并将返回的结果做适当的处理,最终再返回给用户。
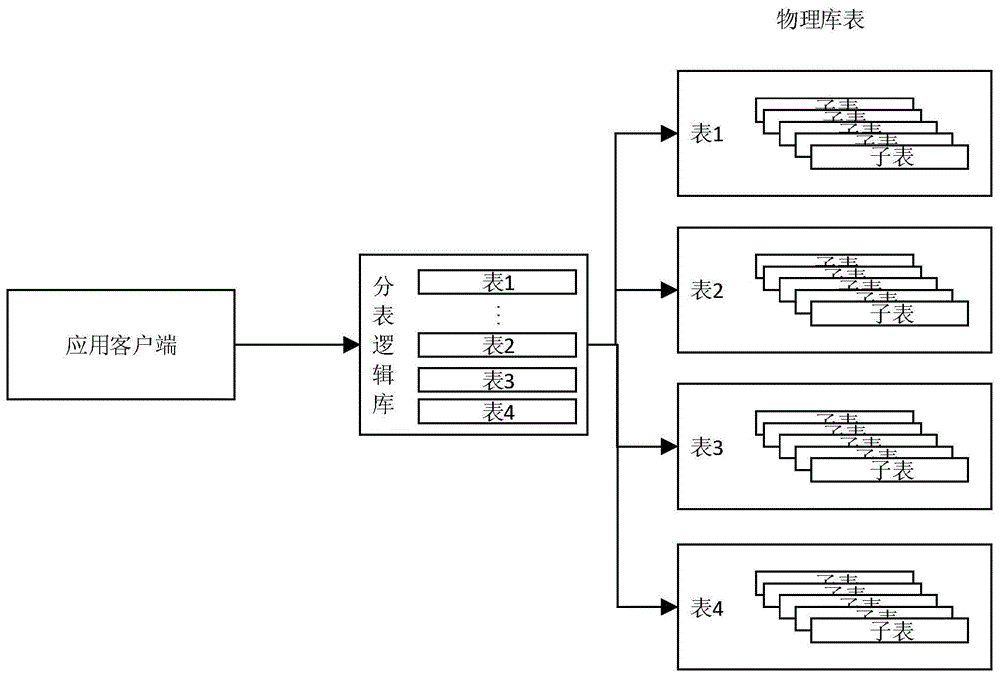
系统用来进行分表的逻辑库,是一个实现了mysql协议的server,前端用户可以把它看作是一个数据库代理,用mysql客户端工具和命令行访问,而其后端可以也可以用jdbc协议与大多数主流数据库服务器通信。其核心功能是分表,即将一个大表水平分割为n个小表,存储在后端物理数据库里,如图1所示。
水情系统数据库分表的核心内容是通过定义表的分片规则来实现分片,每个表格可以捆绑一个分片规则,每个分片规则指定一个分片字段并绑定一个函数,来实现动态分片算法,如图2所示。当逻辑库服务收到一个sql时,会先解析这个sql,查找涉及到的表,然后看此表的定义,如果有分片规则,则获取到sql里分片字段的值,并匹配分片函数,得到该sql对应的分片列表,然后将sql发往这些分片去执行,最后收集和处理所有分片返回的结果数据,并输出到客户端。
数据库分表做到应用无侵入性:
目前市面上很多开源的分表方案通过在做一些轻量级的框架包由客户端引用。与框架的动态配置中心结合,实现动态数据源与动态分片规则。分表框架通过分析sql请求和查询配置中心,告诉这个应用应该去访问哪个数据库以及分片规则是什么。最终由应用自己去访问数据库,并作分片和合并结果。
这样做虽然将实现分片和结果聚合的压力分摊给了每一个应用,降低分表路由和结果归并的难度,但是它对业务应用系统代码有侵入性,将业务开发与后台数据库分库分表管理耦合,使得应用程序变得很重,一旦出现问题,应用端难以定位哪里出了问题,不利于开发管理。
在应用层与数据库层添加数据库路由中间件(相当于代理),将自己伪装成一个mysql数据库,实现mysql协议栈,自己后台管理所有mysql实例。应用无感知,只当后台只是一个mysql实例。这个代理mysql实例,实现分库分表,结果合并等功能。统一管理后台数据库,能及时定位问题,对应用没有侵入性,压力打在中间件上。
基于堆栈缓存的sql条件分析:
水情水调系统的数据具备时效性,且各种类型测量数据采集频率不均,因此按照时间类型进行分表是最常用的分表方式。所有按照时间进行条件查询的sql请求异常复杂,如何针对条件进行分表路由分析成为了一个难题。目前开源的分表语法分析,如tddl不能按照时间进行分表,仅限于对特定类型的分表字段进行路由分析查找,而mycat对于时间字段只进行between单操作分析。
本方法采用druidsql解析器对sql请求进行分析生成range集合,同时针对每一个子查询建立and和or两个缓存条件堆栈,每一个子查询解析的分表条件按照类型分别置于两个堆栈中,置于and堆栈的range集合取交集range,置于or堆栈的range集合取并集range,所有子查询按照合并规则最终生成一个结果range集合。
range集合作为分表算法的输入,进行分表路由计算,最终形成路由节点集合,后台物理端多线程对每个节点提交sql请求,完成数据库查询。
自动建表机制:
随着水情数据管理水平的提高,系统对于数据存储能力要求也越来越高。目前最新施工的小浪底调度系统要求按照秒级数据入库,这样数据库扩展更加不能按照传统预定义的分表个数进行定义。举个例子,通常将数据库分表预定义为n个。如果将n设置成足够大,那么每次路由计算循环进行遍历的范围也会很大,严重影响计算效率。如果设置得太小,那么当分表用完后,后期维护将会变得非常复杂。只有设置成自动子表扩展模式,才能一劳永逸解决这个问题。
虚拟数据库分析拦截获取的sql请求,依据指定的分表算法计算得到即将用到的目标子表,如果子表号大于数据库已有的子表个数,按照主表的结构复制生成一个新的子表,按照工程现场定制的子表约束和触发器模板,为新生成的子表建立关系约束和构建触发器,保证子表完全具备主表的功能。
多线程sql请求:
虽然工程设计的分表算法会尽量让大部分查询集中到某一到两个分表中,但仍不可避免会产生跨多个分表的组合查询。通常在这种情况下,一条sql语句请求会被拆分成多条语句,如果串行等待所有语句执行,效率将会变得非常低下。
本发明在虚拟数据库层定义线程池与真实的物理数据库建立连接,当多条分表语句请求处理时,并发构建多个会话和物理数据库进行通讯。将每个线程进行查询的结果最终在虚拟库进行归并,将处理结果集返回给应用客户端。
支持分表算法二次开发:
由于水电行业各个工程管理的差异性,那么对数据存储的方式和采集特点也是各有不同,这就要求能随时根据工程现场的情况,快速定制个性化的分表方法。比如a水电站采集的数据频率固定,但是站点类型繁多,需要按照测点进行分表;b水电站采集装置类型固定,但是各种采集装置的采集频率各有不同,要求按照时间进行分表,这样显然不能在虚拟库中间层直接定义分表算法。
本发明通过在虚拟库分表配置中心构建一个分表算法注册中心,在算法配置中,可以直接参与分表的表名、字段名以及指定分表算法的实现类路径。通常可以默认实现几种常用的分表算法以供选择,当出现个性化的分表需求时,只需按照特定接口开发对应的算法,便可以将该算法注册到分表配置中心,实现个性化的分表方法。
本发明的整个方法在建立的虚拟数据库平台上进行。在这个平台上,应用端可以按照传统关系型数据库的访问方式开发自己的应用业务,提交的sql请求只需要知道虚拟的主表名即可,然后该平台就可以自动地为应用端进行分表路由,并将重塑的sql请求发送给后台真实的数据库进行处理。
该平台可以充分地解析从应用端提交过来的sql语句,分析语句中的表名、字段名以及查询条件等,根据配置中心指定的分表算法,自动创建子表并进行路由查找,最终将处理结果进行归并处理返回给应用端。
整个虚拟库平台分为三个处理层:前端协议层、解析路由层和后端访问层。整个结构如图3所示:
前端的协议层实现专门的通信层,负责向应用端提供标准数据库协议的数据库服务,它负责构建连接池,将应用端提交的sql请求经过初步处理和优化后,交给解析路由层进行分析处理。
解析路由层将协议层提交的sql语句进行语法分析,同时根据查询条件对语句进行优化,将处理表对象、查询条件等按照预定义的路由分表算法进行路由计算,向计算得出的子表节点进行验证,如不存在相应的子表,提交创建子表请求后再对子表节点各自提交已经拆分的多条子表查询语句,语句被送到后端访问层进行真实数据库查询。解析路由层对每条子查询结果进行归并处理,主要涉及聚合、排序等等。
后端的数据访问层建立数据库连接池并发执行真实的数据库查询,查询得到的结果都将送往解析路由层进行处理。该层采用标准的jdbc连接屏蔽底层的各类物理数据库。
本发明根据预先定义的分表策略算法进行指定数据库表的切分和路由,利用后台真实的物理数据库链接进行实际的数据库访问和库表动态创建,极大地提高了大数据单表的读写速度,简化了业务系统的数据访问逻辑,而且成本低廉。同以往的数据库管理系统自带的分库分区方法不同,该方法可以根据现场的工程环境按照指定的表字段定制各种策略的分表算法,动态地将业务系统的单表请求自动转换成多表请求,避免数据库单表数据过大带来的性能下降。通过利用水电数据的点号规则或者时效性特点更加缩小待处理有用数据的范围,为高效存取水电数据提供了平台基础。业务系统可以根据每个工程的实际情况,按照数据量大小选择连接虚拟库还是直接连接物理库,而不会干扰业务系统的业务开发。
- 还没有人留言评论。精彩留言会获得点赞!