一种档案合并方法、装置、电子设备及存储介质与流程
本发明涉及档案管理技术领域,尤其涉及一种档案合并方法、装置、电子设备及存储介质。
背景技术:
随着社会的进步,人员流通更加普遍,这样就加大了城市级大规模人员管理的难度。目前有一些部门或者系统可以为每个人员建立人员档案,以方便对人员的管理。目前均是通过摄像头拍摄人员图像并基于该摄像头下拍摄到的图像建立人员档案。为了更有效的管理人员,一般将每个摄像头拍摄到的不同的人分别建立对应的人员档案,若某个人员再次被同一摄像头拍摄,则将当前拍摄到的图像归入已经建立的人员档案中。当部门或系统中均设置有多个摄像头,如果多个摄像头分别拍摄到同一个人时,也会分别基于每个摄像头下的图像分别建档。在处理城市级大规模个人档案时,档案数量过于庞大,如百亿级的数量,因此,很容易发生同一个人存在多个档案的情况,从而造成多个人有多个档案,使得个人档案的数据量增加,不便于城市级大规模档案管理,从而导致档案管理效率较差。可见,现有人员档案的管理中存在管理效率低的问题。
技术实现要素:
本发明实施例提供一种档案合并方法、装置、电子设备及存储介质,能够提高档案管理效率。
第一方面,本发明实施例提供一种档案合并方法,包括以下步骤:
检测多个待合并档案中每两个待合并档案的相似度,所述待合并档案包括档案id以及用于计算相似度的档案特征;
当检测到所述多个待合并档案中存在两个待合并档案之间的相似度达到预设相似度阈值时,以两个相似待合并档案分别为节点进行连接,得到多个节点对,所述节点包含对应的待合并档案的档案id;
基于所述多个节点对构建得到目标档案树,每棵所述目标档案树包括至少一个节点对;
基于每棵所述目标档案树进行档案合并,得到对应的目标档案。
可选的,所述检测多个待合并档案中每两个待合并档案的相似度包括:
提取每个待合并档案的档案特征;
计算每两个档案特征之间的相似度;
基于所述每两个档案特征之间的相似度,得到多个待合并档案中每两个待合并档案的相似度。
可选的,所述基于所述多个节点对构建得到目标档案树的步骤包括:
对所述多个节点对进行去重,得到多个去重节点对;
任意选取一个去重节点对作为基础档案树;
在剩余的去重节点对中选取与所述基础档案树有共同节点的去重节点对与所述基础档案树进行结合,每次与所述基础档案树结合后,更新一次所述基础档案树,直到所述剩余的去重节点对不包含与更新后的基础档案树中存在相同节点的去重节点对,以得到目标档案树。
可选的,所述基于所述多个节点对构建得到目标档案树的步骤还包括:
判断所述剩余的去重节点中是否存在与所述基础档案树没有共同节点的去重节点对;
若所述剩余的去重节点中存在与所述基础档案没有共同节点对的去重节点对,则在所述与所述基础档案树没有共同节点的去重节点对中任意选取一个去重节点对作为新的基础档案树;
基于所述新的基础档案树,得到新的目标档案树。
可选的,所述基于每棵所述目标档案树进行档案合并,得到目标档案的步骤包括:
将每棵所述目标档案树中的子节点合并到根节点上,得到目标档案。
将每棵所述目标档案树中的任意一个节点的档案id作为所述目标档案的档案id。
第二方面,本发明实施例提供一种档案合并装置,包括:
相似度检测模块,用于检测多个待合并档案中每两个待合并档案的相似度,所述待合并档案包括档案id以及用于计算相似度的档案特征;
节点对获取模块,用于当检测到所述多个待合并档案中存在两个待合并档案之间的相似度达到预设相似度阈值时,以两个相似待合并档案分别为节点进行连接,得到多个节点对,所述节点包含对应的待合并档案的档案id;
档案树构建模块,用于基于所述多个节点对构建得到目标档案树,每棵所述目标档案树包括至少一个节点对;
档案合并模块,用于基于每棵所述目标档案树进行档案合并,得到对应的目标档案。
可选的,所述相似度检测模块包括:
档案特征提取单元,用于提取每个待合并档案的档案特征;
相似度计算单元,用于计算每两个档案特征之间的相似度;
相似度确定单元,用于基于所述每两个档案特征之间的相似度,得到多个待合并档案中每两个待合并档案的相似度。
可选的,所述档案树构建模块包括:
节点去重单元,用于对所述多个节点对进行去重,得到多个去重节点对;
基础档案树确定单元,用于任意选取一个去重节点对作为基础档案树;
目标档案树构建单元,用于在剩余的去重节点对中选取与所述基础档案树有共同节点的去重节点对与所述基础档案树进行结合,每次与所述基础档案树结合后,更新一次所述基础档案树,直到所述剩余的去重节点对不包含与更新后的基础档案树中存在相同节点的去重节点对,以得到目标档案树。
第三方面,本发明实施例提供一种电子设备,包括:存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现上述实施例提供的档案合并方法中的步骤。
第四方面,一种计算机可读存储介质,所述计算机可读存储介质上存储有计算机程序,所述计算机程序被处理器执行时实现上述实施例提供的档案合并方法中的步骤。
本发明实施例中,通过检测多个待合并档案中每两个待合并档案的相似度,所述待合并档案包括档案id以及用于计算相似度的档案特征;当检测到所述多个待合并档案中存在两个待合并档案之间的相似度达到预设相似度阈值时,以两个相似待合并档案分别为节点进行连接,得到多个节点对,所述节点包含对应的待合并档案的档案id;基于所述多个节点对构建得到目标档案树,每棵所述目标档案树包括至少一个节点对;基于每棵所述目标档案树进行档案合并,得到目标档案。这样,可以将多个待合并档案中同一个人的档案进行合并,使得每个人有且只有唯一一个档案,从而减少个人档案数量,便于档案管理,进而提高档案的管理效率。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是本发明实施例提供的一种档案合并方法的流程图;
图2是图1实施例中步骤103提供的一种方法的流程图;
图3是图1实施中步骤103提供的另一种方法的流程图;
图4是本发明实施例提供的一种档案树的构建示意图;
图5是本发明实施例提供的另一种档案树的构建示意图;
图6是图1实施例中步骤101提供的一种方法流程图;
图7是图1实施例中步骤104提供的一种方法的流程图;
图8是本发明实施例提供的一种档案合并装置的结构示意图;
图9是图8实施例中相似度检测模块提供的一种结构示意图;
图10是图8实施例中档案树构建模块提供的一种结构示意图;
图11是图8实施例中档案树构建模块提供的另一种结构示意图;
图12是图8中档案合并模块提供的一种结构示意图;
图13是本发明实施例提供的一种电子设备的结构示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
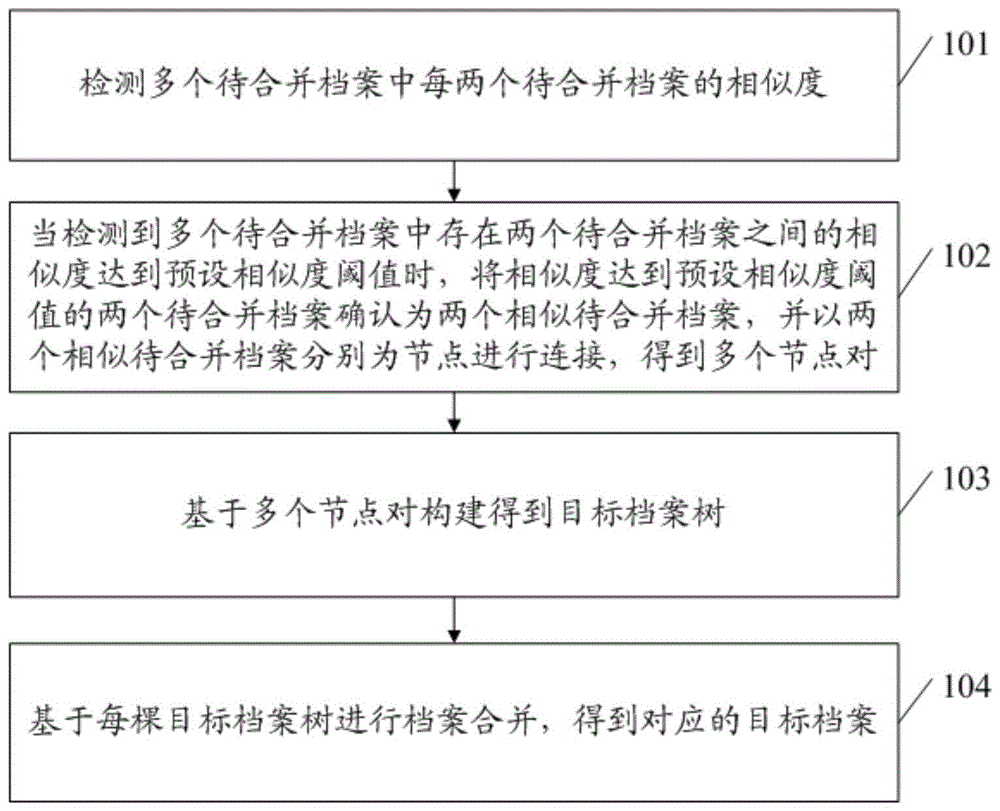
如图1所示,图1是本发明实施例提供的一种档案合并方法的流程图,该档案合并方法包括以下步骤:
步骤101、检测多个待合并档案中每两个待合并档案的相似度。
其中,上述多个待合并档案可以是用来进行档案合并的多个档案。该档案可以是图像档案,也可以是属性档案或者其他形式的档案。上述多个待合并档案中可以包括多个人的档案,并且每个人可能会有一个或多个档案。每个档案都会包含有一个唯一的档案id,且每个档案都会有一个档案特征,每个档案还可以包含有已经归档的档案内容。档案id可以代表档案的身份,档案id可以是单个数字或多个数字的组合形成,也还可以由其他字符组合得到。上述待合并档案还包含有一个档案名,也可以称为档案标识符,比如,档案a、档案a1、档案a2等,也可以表示为档案b、档案b1、档案b2等。
上述档案特征可以是图片档案中的档案封面,也可以是属性档案中的档案属性。上述已经归档的档案内容可以是图像档案中的已经归档的图像,或属性档案中已经归档的属性。属性可以是某个人的指纹、dna等,还可以是身高、体重、体型等。上述档案封面可以包含有人员对应的人脸图像。档案属性可以包含有人员对应的指纹属性。
上述每两个待合并档案的相似度可以是通过每两个待合并档案的档案特征进行计算得到。也可以说,每两个档案的相似度是通过每两个档案的档案特征进行计算得到。所以每个待合并档案至少包括档案id以及用于计算相似度的档案特征。
具体的,检测多个待合并档案中每两个待合并档案的相似度可以是计算多个待合并档案中每两个待合并档案的相似度。
需要说明的是,多个待合并档案可以存储在档案数据库中,且每个待合并档案可以是由不同系统或不同部门建档得到的,例如,在某小区管理系统中的摄像头拍摄到某人员的人脸图像,该系统基于拍摄到的人脸图像建立该人员的档案,并存储在对应的档案数据库中;而在另一小区管理系统中的摄像头也拍摄到该人员的人脸图像,也对该人员建立对应的档案,也存储在对应的档案数据库。此时,该人员在两个小区管理系统的档案数据库中都存有档案,也就是说该人员同时有两个档案,但这两个档案均是同一个人员的。当需要对多个小区管理系统的人员档案进行管理时,需要将多个小区管理系统中的档案数据库中的档案拿出来进行管理,这样就会存在同一个人有多个档案的情况。并且每个小区管理系统都会建立多个人员的档案,那么管理多个小区管理系统的档案时,就会存在多个人对应多个档案的情况。为此,上述多个待合并档案可以相当于本例子中,多个小区管理系统中提供的多个档案,这多个档案可以是多个小区管理系统提供的部分档案数据或者全部档案数据。每个待合并档案还可以是相同系统或相同部门的不同建档终端建档得到的。
步骤102、当检测到多个待合并档案中存在两个待合并档案之间的相似度达到预设相似度阈值时,将相似度达到预设相似度阈值的两个待合并档案确认为两个相似待合并档案,并以两个相似待合并档案分别为节点进行连接,得到多个节点对。
其中,上述预设相似度阈值可以是预先设置的相似度门限值。该预设相似度阈值用于判断两个待合并档案之间是否相似的标准,该预设相似度阈值可以根据需要设置。比如,设置相似度门限值为0.90,如果两个待合并档案之间的相似度为0.90,则认为这两个待合并档案为相似待合并档案。上述节点相当于待合并档案,一个节点相当于一个待合并档案,一个待合并档案也相当于一个节点。每个节点包含对应待合并档案的档案id。上述节点对可以是两个具有连接关系的节点连接组成,也可以说是两个相似待合并档案连接起来的档案对。上述以两个相似待合并档案分别为节点进行连接可以是,将两个相似待合并档案分别作为节点,并将这两个节点进行连接。
具体的,当检测到多个待合并档案中每两个待合并档案之间的相似度后,将检测到的每个相似度与预设相似度阈值进行比较判断,即将多个相似度中的每个相似度与预设相似度阈值进行比较,并判断每个相似度是否满足预设相似度阈值。若每个相似度大于预设相似度阈值,说明该相似度满足预设相似度阈值,也即说明该相似度对应的两个待合并档案为相似待合并档案,则将这两个待合并档案对应的相似度保留下来,并且将这两个相似待合并档案分别作为节点连接起来得到对应的节点对。由于待合并档案的数量为多个,将多个待合并档案中的两两进行相似度计算,所以会得到多组相似待合并档案,也即得到多组节点对,并且得到对应的多个相似度。若每两个待合并档案之间的相似度小于等于预设相似度阈值,说明该相似度不满足预设相似度阈值,也即说明该相似度对应的两个待合并档案不是相似待合并档案,则不保留这两个待合并档案对应的相似度,也不将这两个待合并档案作为节点进行连接。
步骤103、基于多个节点对构建得到目标档案树。
其中,上述目标档案树包括至少一个节点对。上述目标档案树的数量可以是一棵或者多个棵,当多个待合并档案中包括多个人的多个档案时,就可以构建得到多棵不同的目标档案树,每棵目标档案树代表一个人的档案,每颗树中的每个节点相当于每个人的每个不同档案。当构建得到多颗目标档案树时,也即构建得到档案森林。
具体的,参见图2,步骤103包括以下步骤:
步骤201、对多个节点对进行去重,得到多个去重节点对。
具体实施时,在执行步骤102后得到多个节点对,但由于得到的多个节点对是计算多个待合并档案中每两个待合并档案的相似度而得到的,所以会存在重复计算两个待合并档案之间的相似度的情况,使得一对相似待合并档案计算两次相似度,若两次计算得到的相似度均满足预设相似度阈值的话,两个相似均被保留下来,所以会存在两组一样的相似待合并档案,也即得到两对一样的节点对。为此,需要将重复的节点对进行去重处理,进而保证每个节点对均是唯一的。在本实施例中,经过去重处理得到的节点对被称为去重节点对,每个去重节点对均是唯一的。去重节点的数量为多个,且多个去重节点对中可以是同一个人的节点对,也可以是不同人的节点对。
步骤202、任意选取一个去重节点对作为基础档案树。
具体实施时,在得到多个去重节点对后,可选择任意一个去重节点对作为最初的基础档案树(相当于树干),基于该基础档案树建立目标档案树。
步骤203、在剩余的去重节点对中选取与基础档案树有共同节点的去重节点对与基础档案树进行结合,每次与基础档案树结合后,更新一次基础档案树,直到剩余的去重节点对不包含与更新后的基础档案树中存在相同节点的去重节点对,以得到目标档案树。
具体实施时,当确定最初的基础档案树之后,将剩余的去重节点对中的任意一个去重节点对中的每个节点分别与基础档案树中的每个节点对应的档案id进行对比,并判断该去重节点对与基础档案树是否存在档案id相同的节点,若该去重节点对与基础档案树有档案id相同的节点,则将档案id相同的节点作为该去重节点对与基础档案树的共同节点。则基于该共同节点将该去重节点对与基础档案树进行合并,进而得到新的基础档案树(相当于更新基础档案树)。若该去重节点对与基础档案树不存在共同节点,则不将该去重节点对与基础档案树进行结合,那么该去重节点对还是保留在剩余去重节点对中。
当然,一旦在剩余的去重节点对中有去重节点对与基础档案树进行合并,则在合并后,更新基础档案树(新的基础档案树)。然后又从剩余的去重节点对中的任意一个去重节点与新的基础档案树进行共同节点判断,若剩余的去重节点对中还是存在与新的基础档案树有共同节点的去重节点,还是将具有共同节点的去重节点对与新的基础档案树再次合并,又再次得到新的基础档案树。这样重复比较合并直到剩余的去重节点对中没有与新的基础档案树有共同节点的去重节点,则停止比较合并操作。而得到的最后一个新的基础档案树即为某个人的目标档案树。
需要说明的是,基础档案树在与去重节点对进行合并后,新的基础档案树的深度或度数都是在不断增加的,而剩余的去重节点对中,若有去重节点对与基础节点对进行结合后,剩余的去重节点对是不断的在减少的。
更具体的,参见图3,步骤103还包括以下步骤:
步骤301、判断剩余的去重节点中是否存在与基础档案树没有共同节点的去重节点对。
步骤302、若剩余的去重节点中存在与基础档案没有共同节点对的去重节点对,则在与基础档案树没有共同节点的去重节点对中任意选取一个去重节点对作为新的基础档案树。
步骤303、基于新的基础档案树,得到新的目标档案树。
具体实施时,若在进行一个人的目标档案树构建完成后,若还有多个剩余去重节点对未构建目标档案树,则就目标档案树的相同构建方法对剩余的去重节点对构建新的目标档案树,进而得到另一个目标档案树。这样可以实现多个人的目标档案树的构建。
为了便于说明本发明基于多个节点对构建得到目标档案树的过程,示例性的,请参见图4,图4是本发明实施例提供的一种档案树的构建示意图。
经过步骤201进行去重后得到八组节点对如下:
节点对(b、b1)包括档案b以及档案b1,其中,档案b的档案id为1,档案b1的档案id为2。
节点对(b、b2)包括档案b以及档案b2,其中,档案b的档案id为1,档案b2的档案id为3。
节点对(b3、b4)包括档案b3以及档案b4,其中,档案b3的档案id为4,档案b4的档案id为5。
节点对(b2、b4)包括档案b2以及档案b4,其中,档案b2的档案id为3,档案b4的档案id为5。
节点对(c、c1)包括档案c以及档案c1,其中,档案c的档案id为11,档案c1的档案id为12。
节点对(c1、c2)包括档案c1以及档案c2,其中,档案c1的档案id为12,档案c2的档案id为13。
节点对(c2、c3)包括档案c2以及档案c3,其中,档案c2的档案id为13,档案c3的档案id为14。
节点对(c、c4)包括档案c以及档案c4,其中,档案c的档案id为11,档案c4的档案id为15。
基于上述提供的八组去重节点对执行步骤202-步骤203构建档目标案树,具体为:
第一步:将节点对(b、b1)作为基础档案树(b、b1),剩余去重节点则为:对去重节点对(b、b2)、(b3、b4)、(b2、b4)、(c、c1)、(c1、c2)、(c2、c3)、(c、c4)。
第二步:将剩余去重节点对(b、b2)中的档案b以及档案b2分别与基础档案树(b、b1)中的档案b以及档案b1进行共同节点判定。根据上述提供的各组去重节点对中的档案id说明,以及将去重节点对(b、b2)中的各个节点与基础档案树(b、b1)中的各个节点进行一一对比可知,去重节点对(b、b2)中的档案b的档案id与基础档案树(b、b1)中的档案b的档案id相同,均为1。去重节点对(b、b2)中的档案b2的档案id与基础档案树(b、b1)中的档案b1的档案id互不相同,分别为3和2。去重节点对(b、b2)中的档案b2与基础档案树(b、b1)中的档案b的档案id也互不相同,分别为3和1。所以,去重节点对(b、b2)与基础档案树(b、b1)存在一个共同节点(档案b)。所以基于共同节点(档案b)将去重节点对(b、b2)与基础档案树(b、b1)进行合并得到新的基础档案树(b、b1、b2)。
第三步:再得到新的基础档案树(b、b1、b2)后,剩余的去重节点对则变为:(b3、b4)、(b2、b4)、(c、c1)、(c1、c2)、(c2、c3)、(c、c4)。那么再将剩余的去重节点对中的去重节点对(b3、b4)与基础档案树(b、b1、b2)进行共同节点判定。也是根据上述提供的各组去重节点对中的档案id说明,以及将去重节点对(b3、b4)中的各个节点与基础档案树(b、b1、b2)中的各个节点进行一一对比可知,去重节点对(b3、b4)与基础档案树(b、b1、b2)没有共同节点。为此,不将去重节点对(b3、b4)与基础档案树(b、b1、b2)进行合并。
第四步:由于基础档案树(b、b1、b2)没有合并新的去重节点对,所以继续从剩余的去重节点对中选取新的去重节点对(b2、b4)与基础档案树(b、b1、b2)进行共同节点判定。经过共同节点判定之后发现,去重节点对(b2、b4)与基础档案树(b、b1、b2)存在共同节点(档案b2),于是基于该共同节点(档案b2),将去重节点对(b2、b4)与基础档案树(b、b1、b2)进行合并得到新的基础档案树(b、b1、b2、b4)。由此,基本档案树从基础档案树(b、b1、b2)更新为基础档案树(b、b1、b2、b4)。
第五步:得到新的基础档案树(b、b1、b2、b4)后,剩余的去重节点对则变为:(b3、b4)、(c、c1)、(c1、c2)、(c2、c3)、(c、c4)。由于去重节点对(b3、b4)在第三步的共同点判定中,不能够被合并,而经过新一轮的共同节点判定后,基础档案树被更新为基础档案树(b、b1、b2、b4),所以再次将去重节点对(b3、b4)归为剩余的去重节点对中。而且去重节点对(b3、b4)与基础档案树(b、b1、b2、b4)有共同节点(档案b4),为此将去重节点对(b3、b4)合并到基础档案树(b、b1、b2、b4)中,得到基础档案树(b、b1、b2、b4、b3)。
第六步:在经过多个次的共同节点的判定后发现,剩余的去重节点(c、c1)、(c1、c2)、(c2、c3)、(c、c4)中均与基础档案树(b、b1、b2、b4、b3)没有共同节点,所以剩余的去重节点(c、c1)、(c1、c2)、(c2、c3)、(c、c4)均不能与基础档案树(b、b1、b2、b4、b3)进行合并。而剩余的去重节点对中不存在与基础档案树(b、b1、b2、b4、b3)有共同节点的去重节点了,所以最后得到的基础档案树(b、b1、b2、b4、b3)。也即,确定基础档案树(b、b1、b2、b4、b3)为一个目标档案树(b、b1、b2、b4、b3)。
具体实施时,还是基于图4中的例子进行说明。由第一步至第六步得到一个目标档案树后,剩余的去重节点对包括:去重节点对(c、c1)、(c1、c2)、(c2、c3)、(c、c4),且确定剩余的去重节点对(c、c1)、(c1、c2)、(c2、c3)、(c、c4)均不能与得到的目标档案树(b、b1、b2、b4、b3)进行合并。为此,参见图5,还需要对剩余的去重节点对(c、c1)、(c1、c2)、(c2、c3)、(c、c4)构建新的目标档案树。可选的,构建新的目标档案树的方法可以与图4中的构建目标树的方法相同。不同的是去重节点对不同以及对应的档案id不同。所以经过图4中的构建目标档案树的方法得到新的目标档案树为目标档案树(c、c1、c2、c3、c4)。
需要说明的是,在图4中,构建目标档案树的过程与图5中的过程相同,为了避免重复,在此不在赘述。而且在图5中得到的新的目标档案树(c、c1、c2、c3、c4)与图4中得到的目标档案树(b、b1、b2、b4、b3)不同。目标档案树(c、c1、c2、c3、c4)以及目标档案树(b、b1、b2、b4、b3)分别代表不同人的目标档案树,也可以说目标档案树(c、c1、c2、c3、c4)以及目标档案树(b、b1、b2、b4、b3)为两个人对应的目标档案树。每个目标档案树代表一个人的档案。
需要说明的是,为了便于说明本发明的构建目标档案树的过程,图4中举例的去重节点对的数量仅是示例性的,而且得到的目标档案树的数量也是示例性的,本发明不对去重节点对、目标档案树的数量进行限定。再一个,得到的各个目标档案树的形状可以是相同的,也可以是不相同的,在此不对目标档案树的形状进行限定,只需要保证去重节点对不同,对应的档案id不同即可。
当需要处理大量的待合并档案时,也就相应的得到大量的去重节点对,同时也会得到大量的目标档案树,这样就可以将每个人员对应的多个档案构建成一棵目标档案树。有多个人员即得到多个目标档案树。
步骤104、基于每棵目标档案树进行档案合并,得到对应的目标档案。
上述目标档案可以是每个人的多个档案进行合并之后得到的唯一的档案。上述基于每棵目标档案树进行档案合并,得到对应的目标档案可以是,将目标档案树中的各节点对应的档案进行合并,得到一个唯一的档案。
具体的,当多个待合并档案中存在多个人的多个档案时,执行步骤101-103后,得到多个人对应的目标档案树,也即得到多个目标档案树,再执行步骤104分别将每个目标档案树中的档案合并,进而得到对应的目标档案,最后得到多个人的目标档案,也即得到多个目标档案。这样就可以将同一个人的多个档案合并为一个档案,每个人有且只有唯一一个档案,从而减少个人档案数量,便于档案管理,进而提高档案管理效率。
本发明实施例中,通过检测多个待合并档案中每两个待合并档案的相似度,待合并档案包括档案id以及用于计算相似度的档案特征;当检测到多个待合并档案中存在两个待合并档案之间的相似度达到预设相似度阈值时,以两个相似待合并档案分别为节点进行连接,得到多个节点对,节点包含对应的待合并档案的档案id;基于多个节点对构建得到目标档案树,每棵目标档案树包括至少一个节点对;基于每棵目标档案树进行档案合并,得到目标档案。这样,可以将多个待合并档案中同一个人的档案进行合并,使得每个人有且只有唯一一个档案,从而减少个人档案数量,便于档案管理,进而提高档案的管理效率。
如图6所示,图6是图1实施例中步骤101提供的一种方法流程图,步骤101包括:
步骤201、提取每个待合并档案的档案特征。
步骤202、计算每两个档案特征之间的相似度。
步骤203、基于每两个档案特征之间的相似度,得到多个待合并档案中每两个待合并档案的相似度。
上述档案特征可以是能够代表该档案的特征,比如,一个图像档案设置有特定的档案封面,那么这个档案封面可以是这个档案的档案特征。
具体的,首先提取多个待合并档案中,每个待合并档案的档案特征。然后再分别计算多个待合并档案中每两个待合并档案对应的档案特征之间的相似度。
进一步的,可以先对每个待合并档案的档案特征进行向量化,得到特征向量,基于每个待合并档案对应档案特征的特征向量计算每两个档案特征的相似度。例如,每个待合并档案均是以人脸图像作为档案的档案封面,则需要对每个待合并档案的档案封面进行人脸检测,并提取人脸对应的人脸特征。得到每个档案封面对应的人脸特征后,计算每两个档案封面对应的人脸特征之间的相似度。
两特征向量之间的相似度可以是通过欧氏距离、曼哈顿距离、或夹角余弦等计算公式来计算得到。
需要说明的是,得到每两个档案封面对应的人脸特征之间的相似度后,即可得到每两个档案封面之间的相似度,进一步得到每两个待合并档案之间的相似度。
多个待合并档案中每两个待合并档案的相似度计算完毕后,得到多组待合并档案的相似度,也即得到多个相似度。
在本发明实施例中,通过计算多个待合并档案中每两个待合并档案中的档案特征之间的相似度,进而得到多个待合并档案中每两个待合并档案的相似度。再对计算得到的多个相似度进行判断,进而能够判断出多个待合并档案中的相似档案。这样便于对多个待合并档案中的相似档案进行合并。这样,可以对多个待合并档案中同一人的多个档案以构建档案树的形式进行合并,使得每个人有且只有唯一一个档案,从而减少个人档案数量,便于档案管理,进而提高档案的管理效率。
可选的,参见图7,图7是图1实施例中步骤104提供的一种方法的流程图,步骤104包括:
步骤501、将每棵目标档案树中的子节点合并到根节点上,得到目标档案。
步骤502、将每棵目标档案树中的任意一个节点的档案id作为目标档案的档案id。
其中,上述目标档案树中的每个子节点所对应的档案均是属于同一人的其中一个重复的档案。
上述将每棵目标档案树中的子节点合并到根节点上,得到目标档案。可以是,将得到的每棵目标档案树的子节点都合并到根节点上,进而将子节点对应的档案均合并为一个档案以得到目标档案。这样合并后的根节点所对应的档案即为目标档案。且该目标档案是每个人唯一的档案。
上述将每棵目标档案树中的任意一个节点的档案id作为目标档案的档案id可以是,在目标档案树中的子节点都合并到根节点后,将目标档案树中任意一个子节点对应的档案id作为根节点对应的档案的档案id。这样根节点有且只有一个档案id,目标档案树也有且只有唯一个档案id,也即,每个人的多个档案均合并为一个档案,目标档案树的子节点对应的档案的档案id统一为一个档案id。使得每个人员有且只有一个档案。
在本发明实施例中,将每个人的多个档案合并为一个档案,且将多个档案的档案id也统一为一个档案id,这样可以得到每个人有且只有一个唯一的档案,也有且只有唯一个档案id。这样,进一步实现对多个待合并档案中同一个人存在多个档案时,以构建档案树的形式进行合并,使得每个人有且只有唯一一个档案,从而减少个人档案数量,便于档案管理,进而提高档案的管理效率。
如图8所示,图8是本发明实施例提供的一种档案合并装置的结构示意图,该档案合装置1包括:
相似度检测模块11,用于检测多个待合并档案中每两个待合并档案的相似度,待合并档案包括档案id以及用于计算相似度的档案特征。
节点对获取模块12,用于当检测到多个待合并档案中存在两个待合并档案之间的相似度达到预设相似度阈值时,以两个相似待合并档案分别为节点进行连接,得到多个节点对,节点包含对应的待合并档案的档案id。
档案树构建模块13,用于基于多个节点对构建得到目标档案树,每棵目标档案树包括至少一个节点对。
档案合并模块14,用于基于每棵目标档案树进行档案合并,得到对应的目标档案。
如图9所示,图9是图8中相似度检测模块提供的一种结构示意图,相似度检测模块11包括:
档案特征提取单元111,用于提取每个待合并档案的档案特征。
相似度计算单元112,用于计算每两个档案特征之间的相似度。
相似度判断单元113,用于基于每两个档案特征之间的相似度,得到多个待合并档案中每两个待合并档案的相似度。
可选的,参见图10,档案树构建模块13包括:
节点去重单元131,用于对多个节点对进行去重,得到多个去重节点对。
基础档案树确定单元132,用于任意选取一个去重节点对作为基础档案树。
目标档案树构建单元133,用于在剩余的去重节点对中选取与基础档案树有共同节点的去重节点对与基础档案树进行结合,每次与基础档案树结合后,更新一次基础档案树,直到剩余的去重节点对不包含与更新后的基础档案树中存在相同节点的去重节点对,得到目标档案树。
可选的,参见图11,档案树构建模块13还包括:
判断单元134,用于判断剩余的去重节点中是否存在与基础档案树没有共同节点的去重节点对。
新基础档案树确定单元135,用于若剩余的去重节点中存在与基础档案没有共同节点对的去重节点对,则在与基础档案树没有共同节点的去重节点对中任意选取一个去重节点对作为新的基础档案树。
新目标档案树构建单元136,用于基于新的基础档案树,得到新的目标档案树。
可选的,参见图12,图12是图8中档案合并模块提供的一种结构示意图,档案合并模块14包括:
档案合并单元141,用于将每棵目标档案树中的子节点合并到根节点上,得到目标档案。
档案id确定单元142,用于将每棵目标档案树中的任意一个节点的档案id作为目标档案的档案id。
在本发明实施例中,该档案合并装置能够实现上述实施例提供的档案合并方法的各个步骤,并能够达到相同的效果,为避免重复,在此不再赘述。
如图13所示,图13是本发明实施例提供的一种电子设备的结构示意图,该电子设备2包括:存储器22、处理器21及存储在存储器22上并可在处理器21上运行的计算机程序,处理器21执行计算机程序时实现上述实施例提供的档案合并方法中的步骤。处理器21执行以下步骤:
检测多个待合并档案中每两个待合并档案的相似度,待合并档案包括档案id以及用于计算相似度的档案特征;
当检测到多个待合并档案中存在两个待合并档案之间的相似度达到预设相似度阈值时,以两个相似待合并档案分别为节点进行连接,得到多个节点对,节点包含对应的待合并档案的档案id。
基于多个节点对构建得到目标档案树,每棵目标档案树包括至少一个节点对。
基于每棵目标档案树进行档案合并,得到对应的目标档案。
可选的,处理器21执行的检测多个待合并档案中每两个待合并档案的相似度的步骤包括:
提取每个待合并档案的档案特征。
计算每两个档案特征之间的相似度。
基于每两个档案特征之间的相似度,得到多个待合并档案中每两个待合并档案的相似度。
可选的,处理器21执行的基于多个节点对构建得到目标档案树的步骤包括:
对多个节点对进行去重,得到多个去重节点对。
任意选取一个去重节点对作为基础档案树。
在剩余的去重节点对中选取与基础档案树有共同节点的去重节点对与基础档案树进行结合,每次与基础档案树结合后,更新一次基础档案树,直到剩余的去重节点对不包含与更新后的基础档案树中存在相同节点的去重节点对,得到目标档案树。
可选的,处理器21执行的基于多个节点对构建得到目标档案树的步骤还包括:
判断剩余的去重节点中是否存在与基础档案树没有共同节点的去重节点对。
若剩余的去重节点中存在与基础档案没有共同节点对的去重节点对,则在与基础档案树没有共同节点的去重节点对中任意选取一个去重节点对作为新的基础档案树。
基于新的基础档案树,得到新的目标档案树。
可选的,处理器21执行的基于每棵目标档案树进行档案合并,得到对应的目标档案的步骤包括:
将每棵目标档案树中的子节点合并到根节点上,得到目标档案。
将每棵目标档案树中的任意一个节点的档案id作为目标档案的档案id。
本发明实施例还提供一种计算机可读存储介质,计算机可读存储介质上存储有计算机程序,计算机程序被处理器21执行时实现上述实施例提供的档案合并方法中的步骤。
本领域普通技术人员可以理解实现上述实施例方法中的全部或部分流程,是可以通过计算机程序来指令相关的硬件来完成,的程序可存储于一计算机可读取存储介质中,该程序在执行时,可包括如上述各方法的实施例的流程。其中,的存储介质可为磁碟、光盘、只读存储记忆体(read-onlymemory,rom)或随机存取存储器22(randomaccessmemory,简称ram)等。
以上所揭露的仅为本发明较佳实施例而已,当然不能以此来限定本发明之权利范围,因此依本发明权利要求所作的等同变化,仍属本发明所涵盖的范围。
- 还没有人留言评论。精彩留言会获得点赞!