一种基于隐喻主题挖掘的景区评价知识库构建方法与流程
本发明涉及大数据分析技术领域,特别是涉及一种基于隐喻主题挖掘的景区评价知识库构建方法。
背景技术:
随着旅游互联网的蓬勃发展,越来越多的游客会在旅行的过程中使用社交媒体平台记录旅途行程中的游览经历,真实的记录了自己在旅游过程中的所见所闻所感,这些信息多数以文本或图片形式存在于互联网的各旅游网站或者社交平台上,这些信息能够实时的反映出景区在不同主题指标上的变化,能够为游客的旅游路线及偏好提供大数据分析支持,也能够为景区的管理者在提升景区服务方面提供帮助。
目前国内外研究者针对旅游在线评论的研究多集中关注酒店业,对其他研究对象关注较少。有些学者关注了景区评论但分析的粒度较粗,仅从浅层关注了游客的满意度而没有细粒度的针对大量的评论数据逐条分析研究,无法细粒度的反映出景区的每项主题指标随时间的变化,无法及时向旅游管理者提供知识支撑。
从互联网旅游网站的海量评论信息中抽取细粒度的主题情感信息,通常这些信息具有口语性强、语义信息破碎度高等特征且在一个文本中会出现多个主题。基于传统的监督学习的方法需要大量的人工手工标注工作,而基于传统的基于规则的方法,目前的研究中还没有针对旅游领域的语料做出通用的规则,其他领域的规则无法移植到旅游领域。
技术实现要素:
本发明的目的是提供一种基于隐喻主题挖掘的景区评价知识库构建方法,以解决上述现有技术存在的问题,能够对细粒度主题的感情倾向进行快速准确识别。
为实现上述目的,本发明提供了如下方案:本发明提供一种基于隐喻主题挖掘的景区评价知识库构建方法,包括如下步骤:
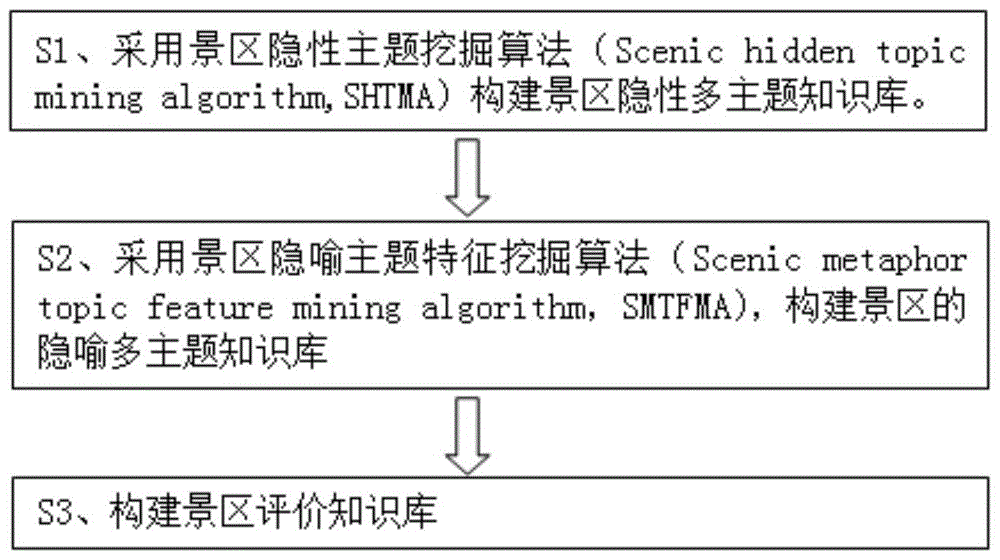
s1、采用景区隐性主题挖掘算法(scenichiddentopicminingalgorithm,shtma)构建景区隐性多主题知识库:根据显性主题词从景区评论语料中挖掘隐性主题词,构建景区隐性多主题知识库;其中,显性主题词与隐性主题词共同构成了基础多主题知识库;
s2、采用景区隐喻主题特征挖掘算法(scenicmetaphortopicfeatureminingalgorithm,smtfma)构建景区的隐喻多主题知识库:所述隐喻多主题知识库由隐喻主题词及隐喻主题特征两部分组成,根据步骤s1中得到的基础多主题知识库,从景区评论语料中挖掘隐喻主题词及隐喻主题特征,构建景区的隐喻多主题知识库;将隐喻主题词与基础多主题知识库进行整合,得到景区多主题知识库,将隐喻主题特征与情感词库整合得到景区情感词知识库;
s3、构建景区评价知识库:基于景区语料库的语义搭配计算模型来计算景区主题词与情感词之间的搭配关系,并对主题词与情感词构成的搭配进行优化,使景区主题词与情感词形成一对多的搭配,以知识树的形式进行存放,构建景区评价知识库;并基于景区评价知识库对游客评论数据所属的主题及在该主题下对应的情感倾向进行识别。
优选地,所述步骤s1景区隐性多主题知识库的构建方法具体包括:
首先构建景区显性多主题知识库,其次采用shtma,把基于各主题的显性主题词作为种子词,从景区评论语料中挖掘提取语料中包含的隐性主题词,构建隐性多主题知识库。
优选地,所述shtma的具体流程包括:
首先,对游客评论语料进行预处理,获取隐性主题词候选词库;其次,通过shtma词向量模型计算显性主题词与隐性主题词候选词库中词语的相似度,根据相似度挖掘隐性主题词,挖掘出的隐性主题词构成隐性多主题知识库,具体包括:先使用评论语料训练词向量模型,再将显性主题词输入训练好的词向量模型,经过词向量模型的计算,得到隐性主题词候选词库中词与输入的显性主题词的语义特征相似度,根据语义特征相似度挖掘隐性主题词,并组成候选的隐性主题词。
优选地,所述步骤s2中隐喻主题词及隐喻主题特征的挖掘方法具体包括:
首先,从语料库中筛选出针对各主题的景区评论语料,景区评论语料包括基础主题词、隐喻主题词、隐喻主题特征,将语料中的句子按照标点符号分成短句;其次,基于smtfma,使用处理后的语料训练分类器模型,并使用训练后的分类器模型从景区评论语料中识别并挖掘隐喻主题词及隐喻主题特征,构建隐喻多主题知识库。
优选地,所述smtfma的具体流程包括:
首先,基于基础多主题知识库,对基于显性主题、隐性主题及隐喻主题特征的语料进行人工标注;其次,通过人工标注的景区评论语料的隐喻特征对smtfma条件随机场分类器进行训练,根据训练后的条件随机场分类器计算未经标注语料在特定特征词出现的情况下,待计算特征词出现的概率,根据特征词出现的概率识别指定词的隐喻主题词及隐喻主题特征。
优选地,所述步骤s3构建景区评价知识库的具体方法包括:
首先,构建旅游情感词典知识库;其次,基于景区多主题知识库及旅游情感词典知识库,采用景区语料库的语义搭配计算模型进行情感词与主题词的搭配,形成主题词与情感词之间一对多的搭配形式,并以sql形式存放在数据库之中,构建景区评价知识库。
优选地,所述采用景区语料库的语义搭配计算模型进行情感词与主题词的搭配的具体方法包括:
首先,计算主题词与情感词的共现度,如式1所示;
其中,t表示主题词,e表示情感词,f(t,e)表示主题词与情感词在语料中出现在同一语句的句子个数,f(t)表示主题词在语料中单独出现的句子个数,f(e)表示情感词在语料中单独出现的句子个数,w(t,e)表示主题词与情感词的共现度;
其次,对主题词与情感词构成的搭配进行优化:主题词与情感词共现度的阈值为h,0<h<1,当主题词与情感词在旅游领域语料库的共现度大于阈值h时,视为该主题词与该情感词能构成搭配,小于阈值h时,视为不能构成搭配并将其删除,完成主题词与情感词搭配的优化,构建与主题词对应的情感词词库。
本发明公开了以下技术效果:
本发明采用景区隐性主题挖掘算法(scenichiddentopicminingalgorithm,shtma)、景区隐喻主题特征挖掘算法(scenicmetaphortopicfeatureminingalgorithm,smtfma)及景区语料库的语义搭配计算模型辅助构建景区评价知识库,通过构建的顾及隐喻信息的景区评价知识库能够较为精确的判断互联网旅游网站中每条评论的细粒度主题及对应主题的情感倾向信息,通过结合时间和空间维度综合做出分析,能够详细的统计出各景区在每个主题的表现情况,用于向游客提供数据支撑,辅助游客做出符合自己偏好性的决策,还能够辅助景区管理者提高景区服务,提升景区网络口碑。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1为本发明景区评价知识库构建方法流程图;
图2为本发明隐性多主题的挖掘算法流程图;
图3为本发明隐喻主题语料标注示例图;
图4为本发明隐喻主题挖掘算法流程图;
图5为本实施例中景区评价知识库结构示意图;
图6为本实施例中使用现有词典对蜈支洲岛与大东海景区的评论进行情感倾向识别的结果;其中,图6(a)为蜈支洲岛情感倾向识别结果,图6(b)为大东海情感倾向识别结果;
图7为本实施例中使用本发明景区评价知识库对蜈支洲岛与大东海景区的评论进行情感倾向识别的结果;其中图7(a)为2016年蜈支洲岛与大东海正负面情感倾向识别结果,图7(b)为2017年蜈支洲岛与大东海正负面情感倾向识别结果,图7(c)为2018年蜈支洲岛与大东海正负面情感倾向识别结果,图7(d)为2016-2018年蜈支洲岛与大东海正负面情感倾向识别结果。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本发明作进一步详细的说明。
参照图1-7所示,本实施例以蜈支洲岛及大东海景区为例提供一种基于隐喻主题挖掘的景区评价知识库构建方法,基于互联网多平台获取多个旅游网站的景区评论数据构建景区评价知识库,并对2016-2018年携程旅游网站上蜈支洲岛及大东海景区的游客评论进行情感倾向识别,为景区质量的评价提供数据支持,并且能够向游客推荐符合个人偏好的旅游景点,包括如下步骤:
s1、采用景区隐性主题挖掘算法(scenichiddentopicminingalgorithm,shtma)构建景区隐性多主题知识库:根据显性主题词从景区评论语料中挖掘隐性主题词,构建景区隐性多主题知识库;其中,显性主题词与隐性主题词共同构成了基础多主题知识库。具体流程如如图2所示,包括如下步骤:
s11、构建景区显性多主题知识库;
s12、采用shtma,把基于各主题的显性主题词作为种子词,从景区评论语料中挖掘提取语料中包含的隐性主题词,构建隐性多主题知识库,将显性主题词与隐性主题词共同构建为基础多主题知识库;具体包括如下步骤:
s121、首先对游客评论语料进行预处理,包括:分词、去停用词、词性标注、词频统计,预处理后,将词频大于20且词性标注为名词的词语列入隐性主题词候选词库之中;
s122、shtma集成了词向量模型,词向量模型通过训练把对文本内容的处理简化为k维向量运算,能够把向量空间上的相似度采用文本语义的形式表达。shtma以景区游客评论语料作为模型训练的基础,通过计算显性主题词与步骤s121中得到的隐性主题词候选词库的词语相似度挖掘隐性主题词,挖掘出的隐性主题词构成了隐性多主题知识库,该过程使用词向量模型,旨在通过计算输入词的上下文特征来获取与该词具有相似语境信息的特征词作为候选的隐性主题词。
s2、采用景区隐喻主题特征挖掘算法(scenicmetaphortopicfeatureminingalgorithm,smtfma),构建景区的隐喻多主题知识库:所述隐喻多主题知识库由隐喻主题词及隐喻主题特征两部分组成,根据步骤s1中得到的基础多主题知识库,从景区评论语料中挖掘隐喻主题词及隐喻主题特征,构建景区的隐喻多主题知识库;将隐喻主题词与基础多主题知识库进行整合,得到景区多主题知识库,将隐喻主题特征与情感词库整合得到景区情感词知识库,具体如图4所示。
隐喻主题词及隐喻主题特征的挖掘,包括如下步骤:
s21、从语料库中筛选出针对各主题的景区评论语料,景区评论语料包括基础主题词、隐喻主题词、隐喻主题特征,将语料中的句子按照标点符号分成短句。
s22、基于smtfma,使用步骤s21处理后的语料训练分类器模型,并使用训练后的分类器模型从景区评论语料中识别并挖掘隐喻主题词及隐喻主题特征,构建隐喻多主题知识库。具体包括如下步骤:
s221、基于基础多主题知识库作为抽取依据,利用统计手段对基于显性主题、隐性主题及隐喻主题特征的语料进行人工标注,如例句“沙滩踩上去像踩上了松软、舒适的地毯。”例句中标注“沙滩”属于基础多主题知识库(basicmulti-themeknowledgebase,b)中的词语,而“地毯”属于隐喻主题词(metaphoricaltheme,mt),“松软”、“舒适”属于隐喻特征(metaphoricalfeature,mf),如图3所示。
s222、smtfma集成了条件随机场分类器,根据步骤s221中人工标注的景区评论语料的隐喻特征,计算不同特征之间出现的条件概率,得到分类器模型中的优化参数,并根据训练后的条件随机场分类器模型计算未经标注语料在特定特征词出现的情况下,待计算特征词出现的概率,根据特征词出现的概率识别指定词的隐喻主题词及隐喻主题特征。
s3、构建景区评价知识库:基于景区语料库的语义搭配计算模型来计算景区主题词与情感词之间的搭配关系,并对主题词与情感词构成的搭配进行优化,使景区主题词与情感词形成一对多的搭配,以知识树的形式进行存放,构建景区评价知识库,并基于景区评价知识库对游客评论数据所属的主题及在该主题下对应的情感倾向进行识别。
具体包括如下步骤:
s31、构建旅游情感词典知识库;
s32、基于步骤s2中得到的景区多主题知识库及s31中得到的旅游情感词典知识库,基于景区语料库的语义搭配计算模型进行情感词与主题词的搭配,形成主题词与情感词之间一对多的搭配形式,以sql形式存放在数据库之中。
所述步骤s32利用基于景区语料库的语义搭配计算模型,基于景区多主题知识库及旅游情感词典知识库,从现有的情感词典知识库中挖掘与主题词能够构成搭配的情感词作为补充词,具体包括:
首先,计算主题词与情感词的共现度,如公式(1)所示;
其中,t表示主题词,e表示情感词,f(t,e)表示主题词与情感词在语料中出现在同一语句的句子个数,f(t)表示主题词在语料中单独出现的句子个数,f(e)表示情感词在语料中单独出现的句子个数,w(t,e)表示主题词与情感词的共现度。
其次,对主题词与情感词构成的搭配进行优化:主题词与情感词共现度的阈值为h,本实施例中h取0.75,当主题词与情感词在旅游领域语料库的共现度大于阈值h时,视为该主题词与该情感词能构成搭配,小于阈值h时,视为不能构成搭配并将其删除,完成主题词与情感词搭配的优化,构建与主题词对应的情感词词库。多主题知识库作为树状结构第三层,情感词词库作为树状结构第四层,共同构建了旅游多主题情感知识库。
本实施例中景区评价知识库结构示意图如图5所示,其结构表示为一颗高度为4的树,第二层包括对景区进行细粒度分析的多主题类别,第三层包括显性多主题知识库、隐性多主题知识库、隐喻多主题知识库,第四层包括景区情感词知识库,景区情感词知识库包括正面情感词库、中性情感词库、负面情感词库,第三层多主题知识库与第四层景区情感词知识库为一对多的对应关系。
本实施例多主题类别共分为9个大类,每个大类包括2-3个子类,如表1所示。
表1
本实施例情感类别分为3类,每一类对应多个含有感情情绪的情感词,如表2所示,设置景区评价知识库中公众情感倾向对应的各情感词的分值为:各正面情感倾向词的分值为score(positive)=1,中性情感倾向词的分值为score(neutral)=0,负面情感词对应的各情感词对应的分值为score(negative)=-1。
表2
s33、基于步骤s32构建的景区评价知识库,对游客评论数据所属的主题及在该主题下对应的情感倾向进行识别,包括如下步骤:
s331、数据预处理:将游客评论的语料按照标点断句形成短句集合{c1,c2,c3,….ci,i>=1},其中ci表示待处理文本断句后形成的短句,并对各短句分别进行分词、去停用词处理;
s332、将ci短句中预处理后的词分别与景区多主题知识库中各主题节点下的主题词相匹配,当ci短句满足某一主题类别的主题特征词时,将ci标记为该主题该下的候选句;
s333、将步骤s332中得到的候选句与景区情感词知识库中的各类情感特征词相匹配,当该候选句满足某情感满意度倾向时,得到该候选句在该主题下的情感类别;
s334、判断该候选句中的其他词是否能够与步骤s333中得到的情感类别的否定词进行搭配,若能够搭配,则将该主题情感倾向改为相反的情感倾向。
使用目前市面上通用的情感词典对2016-2018年携程旅游网站上关于蜈支洲岛与大东海的游客评论数据进行情感识别,识别结果如图6所示,可见,目前市面上通用的情感词典不涉及主题,只分正面情感、中性情感、负面情感。根据图6(a)显示,蜈支洲岛从2016-2018年正面、中性、负面评论的评论数量都趋于稳定,表现良好,而根据图6(b)显示,大东海正面评论数量随着时间的增加急速减少,中性评论与负面评论数量也在逐渐减少,但负面评论占总体评论占比越来越高,说明大东海景区的网络口碑下滑比较严重。但使用目前现有的研究方法无法得到随时间变化的细粒度主题情感变化,也就无法分析大东海游客数量急速下降的原因。
而使用本发明景区评价知识库对2016-2018年携程旅游网站上关于蜈支洲岛与大东海的游客评论数据进行情感识别,识别结果如图7所示。根据图7能够明显看出,蜈支洲岛在饮食口味、饮食价格、特色、景色、住宿、娱乐趣味性、项目价格、服务质量、商业氛围及物价主题得到了游客的广泛关注,随着年份增加蜈支洲岛特色、购票、景色主题的正面评论数量在稳步地增加,饮食价格主题的负面评论在逐步减少,说明景区发展状况良好,景区的吸引力在逐步的增加,但需要注意的是蜈支洲岛在娱乐趣味性主题的正面评论随着年份的增加在缓慢减少,但项目价格、商业氛围主题的负面评论逐步增加,说明景区在娱乐方面有待改善。大东海在饮食口味、交通、景色、住宿、娱乐趣味、商业氛围受到了游客的广泛关注,但随着年份的增加在各主题的评论数量迅速减少,对比蜈支洲岛可以看出大东海缺乏特色及娱乐主题的关注度,缺少景区独特的吸引力,使得大东海很难吸引游客前往,故大东海景区的游客关注度迅速降低。可见,根据本发明所构建的景区评价知识库,游客能够结合自己的兴趣爱好选择相对应的景区,有效提升了游客游览的旅行效率,也能够为景区管理者有针对性的提升网络口碑提供数据支持。
基于本发明所构建的景区评价知识库,本发明还提供一种基于java语言的智能化识别游客评论主题及情感满意度的程序,集成了包括词向量模型、语义相似度计算、条件随机场分类器、条件概率计算分类器、基于景区语料库的语义搭配计算模型,能够智能化的挖掘潜藏在语料中隐性主题词、隐喻主题词、隐喻主题特征、针对各主题的情感词,以知识树的形式构建了景区评价知识库,克服了短文本上下文特征稀疏,细粒度景区主题识别分类困难等缺点,能够精确的识别旅游评论中每条评论对应的主题及情感倾向性,通过对游客的评论语句逐条分析,能够根据分析结果快速准确地推理出该景区在哪些主题具有突出的优势或劣势,从而为景区管理者及游客提供数据支持。
在本发明的描述中,需要理解的是,术语“纵向”、“横向”、“上”、“下”、“前”、“后”、“左”、“右”、“竖直”、“水平”、“顶”、“底”、“内”、“外”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。
以上所述的实施例仅是对本发明的优选方式进行描述,并非对本发明的范围进行限定,在不脱离本发明设计精神的前提下,本领域普通技术人员对本发明的技术方案做出的各种变形和改进,均应落入本发明权利要求书确定的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!