一种基于智能学习的非侵入式非居民用户负荷辨识方法与流程
本发明属于智能用电及非侵入式负荷辨识技术领域,具体涉及一种基于智能学习的非侵入式非居民用户负荷辨识方法。
背景技术:
随着智能电网建设的飞速发展,电力需求侧管理作为一种由客户参与负荷的控制和电能的挖掘的一种管理方法也随之不断发展,这也让我国能更加合理有效的配置电力资源和有效提高了终端的电能使用效率。同时,非侵入式负荷监测有着巨大的研究空间并且受到了国内外的广泛关注。但是目前多应用于居民用户的各类电器的监测,而对于电网负荷重要组成部分的非居民用户负荷,我们进行的相关研究却不多。非侵入负荷监测一般分为事件探测、特征提取和负荷识别三个主要步骤。然而,目前使用的负荷辨识方法都存在着部分负荷特征重叠难以辨识的问题,这也导致了现今非侵入式负荷监测系统中的负荷辨识准确性不足。
技术实现要素:
本发明为了解决现有技术中部分负荷特征重叠难以辨识的问题,提供一种非侵入式非居民用户负荷辨识方法。
具体而言本发明提供了一种基于智能学习的非侵入式非居民用户负荷辨识方法,其特征在于,所述协同管控方法包括以下步骤:
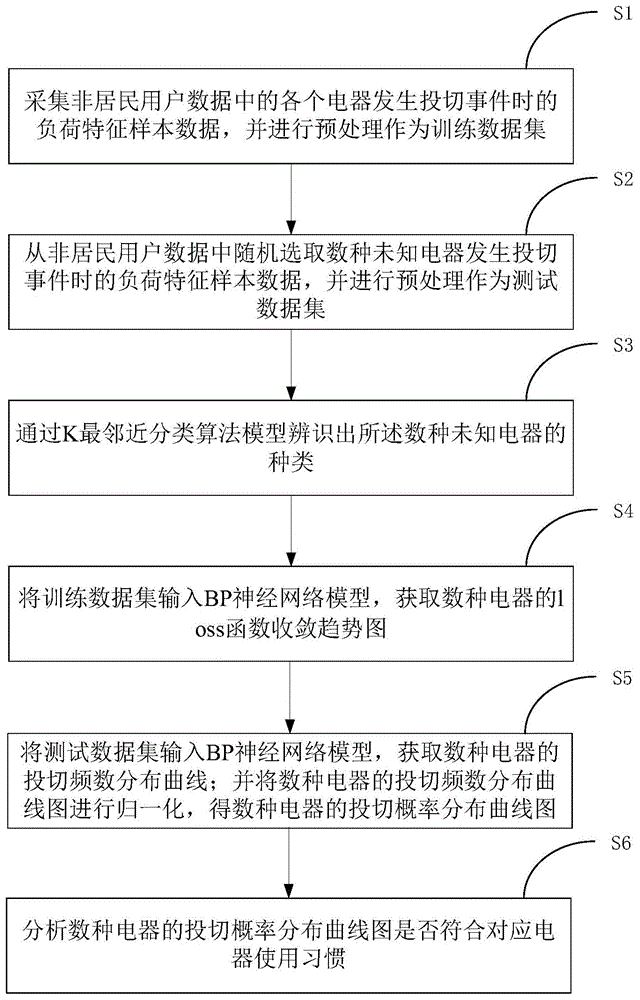
步骤s1:采集非居民用户数据中的各个电器发生投切事件时的负荷特征样本数据,并进行预处理作为训练数据集;
步骤s2:从非居民用户数据中随机选取数种未知电器发生投切事件时的负荷特征样本数据,并进行预处理作为测试数据集;
步骤s3:通过k最邻近分类算法模型辨识出所述数种未知电器的种类;
步骤s4:将所述训练数据集输入bp神经网络模型,直到所述训练数据集穷尽或者误差函数满足要求;
步骤s5:将所述测试数据集输入bp神经网络模型,获得数种电器的投切概率与投切时间的关系;
步骤s6:分析数种电器的投切概率与投切时间的关系是否符合对应电器使用习惯,验证辨识得到的电器种类是否正确。
更进一步地,在步骤s1中,所述训练数据集通过采集到的非居民用户数据中的各个电器发生投切事件时的稳态工作电流数据,对所述电流数据进行傅里叶级数展开,将展开后得到的幅值比较大的电流谐波幅值作为所述训练数据集。
更进一步地,步骤s2中,所述测试数据集通过采集到的非居民用户数据中的数种电器发生投切事件时的稳态工作电流数据,对所述电流数据进行傅里叶级数展开,将展开后得到的幅值比较大的电流谐波幅值作为所述测试数据集。
更进一步地,步骤s3中,还包括以下步骤:
步骤s31:向所述k最邻近分类算法模型输入所示训练数据集和测试数据集并设定k的值;
步骤s32:采用加权欧式距离计算距离度量,并获得k个与测试数据相近的训练数据;
步骤s33:将测试数据的类别判定为距离其更近的训练数据的类别,得出分类结果。
更进一步地,步骤s32中,所述加权欧式距离表示为:
其中,wk是每个样本的权重;xi是第i个测试数据向量,xj是第j个训练数据向量,xi和xj均具有n个特征分量;xik即第i个测试数据的第k个特征分量,xjk即第j个训练数据的第k个特征分量。
更进一步地,步骤s33中,所述分类结果表示为:
其中,
更进一步地,步骤s33中,所述投票的权重表示为:
更进一步地,步骤s5中,所示数种电器的投切概率与投切时间的关系通过所示测试数据集获取数种电器的投切频数分布曲线图,并对数种电器的所述投切频数分布曲线进行积分得到各个曲线下的面积,再用数种电器的所述投切频数分布曲线除以所述面积,获取数种电器的投切概率分布图。
本发明的有益效果是:
本发明对于解决非居民用户负荷种类多,负荷辨识误差较大等问题具有显著优势。利用非侵入式负荷监测系统来采集非居民用户用电数据进而实现对各类非居民负荷的能耗进行监测和分时段计费,然后从这些数据中提取出负荷的各类特征。
本发明通过k最邻近算法模型初步对多种非居民用户负荷进行分类,k0最邻近算法模型分类器不需要提前使用训练集进行训练,训练时间复杂度为0,使多种非居民用户负荷初步分类更加方便快捷。
本发明通过利用这些特征进行负荷识别进而建立泛化的智能学习模型,来拟合非居民负荷的投切概率分布曲线,来了解大家对不同负荷的使用习惯,进而帮助负荷辨识进行进一步的判断。本方法准确性较高,对于负荷辨识精确度有显著提升,原理简单,实施方便。
附图说明
图1是本发明实施例提供的一种基于智能学习的非侵入式非居民用户负荷辨识方法的步骤示意图;
图2是本发明实施例提供的教室电灯的电流波形图;
图3是本发明实施例提供的投影仪的电流波形图;
图4是本发明实施例提供的教室电灯的loss函数收敛趋势图;
图5是本发明实施例提供的投影仪的loss函数收敛趋势图;
图6是本发明实施例提供的教室电灯的概率分布图;
图7是本发明实施例提供的投影仪的概率分布图。
具体实施方式
下面通过实施例,并结合附图1-7,对本发明的技术方案作进一步具体的说明。
如附图1所示,本申请的实施例提供了一种基于智能学习的非侵入式非居民用户负荷辨识方法,包括以下步骤:
步骤s1:采集非居民用户数据中的各个电器发生投切事件时的负荷特征样本数据,并进行预处理作为训练数据集;
步骤s2:从非居民用户数据中随机选取数种未知电器发生投切事件时的负荷特征样本数据,并进行预处理作为测试数据集;
步骤s3:通过k最邻近分类算法模型辨识出数种未知电器的种类;
步骤s4:将所述训练数据集输入bp神经网络模型,直到所述训练数据集穷尽或者误差函数满足要求;
步骤s5:将所述测试数据集输入bp神经网络模型,获得数种电器的投切概率与投切时间的关系;
步骤s6:分析数种电器的投切概率与投切时间的关系是否符合对应电器使用习惯,验证辨识得到的电器种类是否正确。
具体的,在步骤s1中,提取出采集到的非居民用户数据中的各个电器发生投切事件时的稳态工作电流数据,并对这些电流数据进行傅里叶级数展开,将展开后得到的幅值比较大的电流谐波幅值作为负荷特征样本作为训练数据集。
在步骤s2中,随机地再从采集到的非居民用户数据中,选取数种未知电器发生投切事件时的稳态工作电流数据,并对这些电流数据进行傅里叶级数展开,将展开后得到的幅值比较大的电流谐波幅值作为负荷特征样本作为测试数据集。
在步骤s3中,利用k最邻近分类算法进行非侵入式负荷辨识,k最邻近分类算法是一种基于距离的智能学习方法。
由于用k最邻近分类算法建立的模型没有非常明显的训练过程,所以将训练数据集输入后它还不会开始计算,只有当将测试数据集输入进行分类时它才真正开始计算。对于输入的测试数据集,k最邻近分类算法模型首先会找出距离测试数据最近的k个训练数据,最后根据k个训练数据的类别标记来用投票的方法来判定测试数据的所属类别。
利用k最邻近算法模型进行非侵入式负荷辨识过程还包括以下步骤:
步骤s31:向所述k最邻近分类算法模型输入所示训练数据集和测试数据集并设定k的值。
步骤s32:采用加权欧式距离计算距离度量,并获得k个与测试数据相近的训练数据;其中,加权欧式距离表示为:
其中,wk是每个样本的权重;xi是第i个测试数据向量,xj是第j个训练数据向量,xi和xj均具有n个特征分量;xik即第i个测试数据的第k个特征分量,xjk即第j个训练数据的第k个特征分量。
k最邻近分类算法模型根据测试数据和邻近训练数据的距离来进行加权,和测试数据距离越近的训练数据的权重越大,在这里主要通过遍历的方法来选择最优的权重值。在遍历结束之后,根据权重的大小获得k个与测试数据相近的训练数据。
步骤s33:将测试数据判定为距离其更近的训练数据的类别,分类得出的结果可以表示为:
其中,
通过k最邻近分类算法模型即可辨识出了数种未知电器的种类。由于k值已经提前确定,所以选取与测试数据最近的k个训练数据。我们将训练数据进行分类,并进行标号,yi就表示第i类负荷,只有当第j个训练数据的标号f(x′j)与yi相同时,δ(yi,f(x′j))才能取1,否则取0;这样就可以通过改变yi中的i值,分别计算出yi中各i值相应的和。通过
在步骤s4中,由于目前大多使用的负荷辨识方法都是把提取出来的特征和特征库中的特征来进行比较进而将最接近的判定为该类负荷,所以要是提取的几种负荷特征存在特征相近的问题就有可能发生误判。针对利用非侵入式负荷辨识得到的负荷投切时间数据进行概率分布的研究,可以了解用户对于不同电器的使用习惯进而对负荷辨识出的结果进行进一步的判断,从而保证负荷辨识的准确度。
bp神经网络作为一种应用广泛的神经网络算法,对于大量的输入—输出的映射关系具有很强的学习能力和存储能力。除此之外,由于bp神经网络主要由大量的神经元构成的自适应非线性动态系统,所以其对于拟合非线性函数曲线具有非常好的效果。因此,本发明采用bp神经网络算法来拟合负荷投切概率分布曲线。
将训练数据集输入bp神经网络模型,让bp神经网络模型进行10000次迭代训练,不断调整直到训练数据穷尽集或者误差函数满足要求时模型训练完毕,此时得到的实际输出最接近于期望结果。
在步骤s5中,将测试数据集输入训练好的bp神经网络模型进行10000次的迭代运算,通过梯度下降法不断调整神经网络单元间的权值来选出最优权值,使得输出结果尽可能地接近期望值,解决bp神经网络模型中的误差纠正问题,可以得到数种电器的投切频数分布曲线。然后对数种电器的投切频数分布曲线图进行归一化,即对各个电器的投切频数分布曲线进行积分得到各个曲线下的面积,再用各个电器的投切频数分布曲线除以得到的面积,通过归一化可以获得数种电器的投切概率分布曲线图。
在步骤s6中,分析数种电器的投切概率分布曲线图是否符合对应电器使用习惯。这样,对得出的数种电器的投切概率分布曲线图进行分析,图中横坐标为一天24小时,纵坐标为概率密度,因此每个时间段内该电器被使用的概率为对应此时间段时曲线下方的面积。通过得到的概率分布曲线图对k最邻近算法辨识出的结果进行了再一次的判定,纠正了其发生的误判情况,保证了负荷辨识的准确性。
如附图2-3所示,在一种实施例中,采集学校内各个电器发生投切事件时的稳态工作电流数据,通过傅里叶级数展开并选取幅值比较大的电流谐波幅值作为训练数据输入k最邻近算法所建立的学校内负荷辨识模型中;并随机采集学校内两种电器发生投切事件时的稳态工作电流数据,通过傅里叶级数展开并选取幅值比较大的电流谐波幅值作为测试数据输入k最邻近算法所建立的学校内负荷辨识模型中。通过k最邻近分类算法模型辨识出了两种未知电器的种类:教室电灯和投影仪。
如附图4-5所示,将训练数据输入bp神经网络模型中进行训练,得到的各个电器的损失函数loss收敛趋势图,经过10000次迭代,损失函数loss趋于0,此时输入测试数据可获得最优效果。
如附图6-7所示,将测试数据输入训练好的bp神经网络模型进行迭代运算可以得到两种电器的投切频数分布曲线,对两种电器的投切频数分布曲线图进行归一化,获得两种电器的投切概率分布曲线图。
先对教室电灯进行分析,可以发现电灯一天中基本都在被使用且被使用的时间段表现得非常规律,而教室电灯正常来说一般在晚上六点以后被使用的概率比较大,其他时间段很少被使用甚至不被使用,由此得知此投切概率分布曲线图对应的电器不是教室电灯,则可以判定在利用k最邻近算法进行负荷辨识时发生了误判,此时应将此电器归类为负荷辨识时找出的第二大类电器-学校超市的电冰箱,可以发现学校超市的电冰箱被使用的时间段与投切概率分布曲线所表现的情况吻合。同理可以判断投影仪被使用的时间符合教学习惯,在每天的上午、下午及晚上的上课时间使用比较频繁。因此可以得到此发明可根据非居民用户对电器的使用习惯,提高负荷辨识的精确度。
虽然本发明已经以较佳实施例公开如上,但实施例并不是用来限定本发明的。在不脱离本发明之精神和范围内,所做的任何等效变化或润饰,同样属于本发明之保护范围。因此本发明的保护范围应当以本申请的权利要求所界定的内容为标准。
- 还没有人留言评论。精彩留言会获得点赞!