一种基于知识图谱的大数据显示方法与流程
本发明涉及知识图谱领域,具体而言,涉及一种基于知识图谱的大数据显示方法。
背景技术:
知识图谱(knowledgegraph/vault)又称为科学知识图谱,是显示知识发展进程与结构关系的一系列各种不同的图形,它充分利用人工智能(ai,artificialintelligence)技术把复杂的知识领域通过数据挖掘、信息处理、知识计量和图形绘制抽象成实体而显示出来,揭示知识领域的动态发展规律,为学科研究提供切实的、有价值的参考。
在进行知识图谱的页面展示时,经常因为展示的数据(图谱层级+关系)数量巨大,而导致无法展示,甚至机器崩溃。因此,在相关技术中,在进行页面展示的时候,一般会通过一定的延迟,进行缓慢加载和缓慢渲染,进行更大数据量的展示。但是上述处理方式并不能从根本上解决知识图谱数据量大,无法展示的问题;并且当知识图谱中包括的数据量进一步加大时,依然会出现崩溃的问题,从而导致展示速度更加缓慢。
面对庞大用户数据,必然要面临信息超载的问题,要解决这样的问题有两种方式,一种是增加工作人数,这样势必增加管理与生产成本,另一种方法是利用计算机可视化技术在有限的用户界面中对多维复杂的数据以符合感知与认知规律的方式进行图形呈现,帮助发现洞察数据的真实含义。
技术实现要素:
鉴于针对大数据可视化出现的上述问题,本发明请求保护一种基于知识图谱的大数据显示方法,可有效的对数据进行知识图谱的可视化展示,并可对图谱进行质量修订和评价。
本发明请求保护一种基于知识图谱的大数据显示方法,其特征在于:
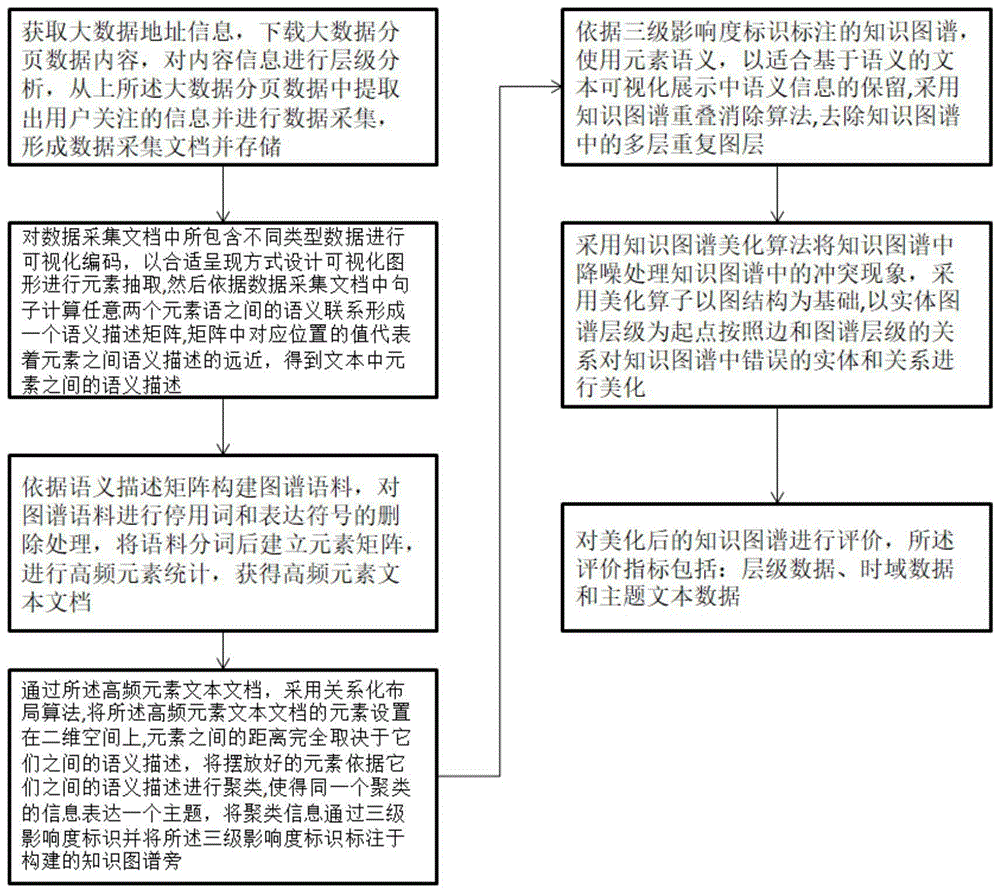
步骤1:获取大数据地址信息,下载大数据分页数据内容,对内容信息进行层级分析,从上所述大数据分页数据中提取出用户关注的信息并进行数据采集,形成数据采集文档并存储;
步骤2:对数据采集文档中所包含不同类型数据进行可视化编码,以合适呈现方式设计可视化图形进行元素抽取,然后依据数据采集文档中句子计算任意两个元素语之间的语义联系形成一个语义描述矩阵,矩阵中对应位置的值代表着元素之间语义描述的远近,得到文本中元素之间的语义描述;
步骤3:依据语义描述矩阵构建图谱语料,对图谱语料进行停用词和表达符号的删除处理,将语料分词后建立元素矩阵,进行高频元素统计,获得高频元素文本文档;
步骤4:通过所述高频元素文本文档,采用关系化布局算法,将所述高频元素文本文档的元素设置在二维空间上,元素之间的距离完全取决于它们之间的语义描述,将摆放好的元素依据它们之间的语义描述进行聚类,使得同一个聚类的信息表达一个主题,将聚类信息通过三级影响度标识并将所述三级影响度标识标注于构建的知识图谱旁;
步骤5:依据三级影响度标识标注的知识图谱,使用元素语义,以适合基于语义的文本可视化展示中语义信息的保留,采用知识图谱重叠消除算法,去除知识图谱中的多层重复图层;
步骤6:采用知识图谱美化算法将知识图谱中降噪处理知识图谱中的冲突现象,采用美化算子以图结构为基础,以实体图谱层级为起点按照边和图谱层级的关系对知识图谱中错误的实体和关系进行美化;
步骤7:对美化后的知识图谱进行评价,所述评价指标包括:层级数据、时域数据和主题文本数据。
本发明中的知识图谱的展示方法通过数据元素的语义描述信息进行高频元素文本文档统计汇总,采用关系化布局算法,相对于相关技术中的知识图谱展示方式,采用本发明实施例中的知识图谱展示方式可以有效解决相关技术中存在的知识图谱展示缓慢的问题,达到快速有效的展示知识图谱的效果;并且其通过对生成的知识图谱进行美化降噪处理知识图谱中的冲突现象,对美化后的知识图谱进行评价,保证了知识图谱的展示效果符合视觉需要。
附图说明
为了更清楚地说明本申请实施例的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,应当理解,以下附图仅示出了本申请的某些实施例,因此不应被看作是对范围的限定,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他相关的附图。
图1示出了根据本发明种基于知识图谱的大数据显示方法的工作流程图;
图2示出了根据本发明种基于知识图谱的大数据显示方法实施例一的工作流程图。
具体实施方式
下面将参照附图更详细地描述本公开的示例性实施例。虽然附图中显示了本公开的示例性实施例,然而应当理解,可以以各种形式实现本公开而不应被这里阐述的实施例所限制。相反,提供这些实施例是为了能够更透彻地理解本公开,并且能够将本公开的范围完整的传达给本领域的技术人员。
附图1示出了根据本发明种基于知识图谱的大数据显示方法的工作流程图。
本发明请求保护一种基于知识图谱的大数据显示方法,其特征在于:
步骤1:获取大数据地址信息,下载大数据分页数据内容,对内容信息进行层级分析,从上所述大数据分页数据中提取出用户关注的信息并进行数据采集,形成数据采集文档并存储;
步骤2:对数据采集文档中所包含不同类型数据进行可视化编码,以合适呈现方式设计可视化图形进行元素抽取,然后依据数据采集文档中句子计算任意两个元素语之间的语义联系形成一个语义描述矩阵,矩阵中对应位置的值代表着元素之间语义描述的远近,得到文本中元素之间的语义描述;
步骤3:依据语义描述矩阵构建图谱语料,对图谱语料进行停用词和表达符号的删除处理,将语料分词后建立元素矩阵,进行高频元素统计,获得高频元素文本文档;
步骤4:通过所述高频元素文本文档,采用关系化布局算法,将所述高频元素文本文档的元素设置在二维空间上,元素之间的距离完全取决于它们之间的语义描述,将摆放好的元素依据它们之间的语义描述进行聚类,使得同一个聚类的信息表达一个主题,将聚类信息通过三级影响度标识并将所述三级影响度标识标注于构建的知识图谱旁;
步骤5:依据三级影响度标识标注的知识图谱,使用元素语义,以适合基于语义的文本可视化展示中语义信息的保留,采用知识图谱重叠消除算法,去除知识图谱中的多层重复图层;
步骤6:采用知识图谱美化算法将知识图谱中降噪处理知识图谱中的冲突现象,采用美化算子以图结构为基础,以实体图谱层级为起点按照边和图谱层级的关系对知识图谱中错误的实体和关系进行美化;
步骤7:对美化后的知识图谱进行评价,所述评价指标包括:层级数据、时域数据和主题文本数据。
优选的,所述步骤1:获取大数据地址信息,下载大数据分页数据内容,对内容信息进行层级分析,从上所述大数据分页数据中提取出用户关注的信息并进行数据采集,形成数据采集文档并存储,具体包括:
对下载的大数据分页数据内容进行层级划分,社交网络层为最顶层(根图谱层级),其下层(子图谱层级)是包括各类分区的区域层,在区域层下是包含各类论坛的论坛层,直到社区底层的主题层,采集用户关注的信息数据;
对采集到的所述用户关注的信息数据进行数据处理,并以结构化的方式存储起来,所述结构化方式为json数据结构存储,所有论坛以对象数组的形式保存,每个对象包括论坛名称、地址、层级深度、父层级名称、子层级名称矩阵、当日主题数、主题总数以及发帖总数,周期性在虚拟机服务器后台进行定时任务,对整个社交网络数据进行遍历,将论坛对象数组添加时间信息后,存入数据库;
所述将论坛对象数组添加时间信息时选择论坛数组上的主题ti相应的部分ai,其时间信息采用区间标识,开始标识tstart和结束标识tend之间的时间构成了所述区间标识[tstart·tend],将所述区间等分成m-1段,每个时间段的长度为
依次以均分时刻tstart+pδt为核心,依据δt在部分ai上挖取子部分ai,j,在每一个子部分上放置所述对象中的元素值,生成主题ti的知识图谱草稿并存入数据库。
优选的,所述步骤2:对数据采集文档中所包含不同类型数据进行可视化编码,以合适呈现方式设计可视化图形进行元素抽取,然后依据数据采集文档中句子计算任意两个元素语之间的语义联系形成一个语义描述矩阵,矩阵中对应位置的值代表着元素之间语义描述的远近,得到文本中元素之间的语义描述,具体包括:
将所述不同类型数据进行向量转写,采用行向量获取各类型数据的共现元素矩阵,mi表示第i个共现元素矩阵m的第i行,使用cos函数定义两元素之间的语义描述矩阵:
sim(ei,ej)表示ei和ej之间的相似性,如果ei和ej有较高的相似性,那么他们两个的语义具有较高的相似性,通过不同元素对之间的相似度计算可以构建语义描述矩阵
优选的,参照附图2,示出了根据本发明种基于知识图谱的大数据显示方法实施例一的工作流程图,所述步骤3:依据语义描述矩阵构建图谱语料,对图谱语料进行停用词和表达符号的删除处理,将语料分词后建立元素矩阵,进行高频元素统计,获得高频元素文本文档,具体包括:
步骤31:当前指针的位置在准备分词文本中的第n个字,n也表示最大词长的长度,首先判断输入进去的字符串是否为空,是的话则直接输出结果空格,否则进行步骤32;
步骤32:将当前位置前n个字的组合和词典中词条逐个进行比对,如果n个字与词典中的词条比对成功,就把这n个字的组合以词的形式划分出来;如果与词典中的词条一一比对后都没有匹配上,就说明这n个字没有词出现;
步骤33:将这n个字的字符串最右侧的一个字去除,剩下的n-1个字组合再与词典中的词条进行比对,重复步骤31和32,一直到这n个字的组合长度为0时结束;
步骤34:再取出下一个字后面的n个字作为新的待分词文本与词典中的词条进行比对,重复31、32、33步骤直到文档结尾;
步骤35:进一步将上述得到的匹配的字符串进行频率统计,将出现频率相似度大于阈值的元素认定为高频元素,所述具有高频元素的文档为高频元素文本文档;
所述频率相似度的计算公式为:
其中,t1,t2代表的是两个需要计算频率相似度的相互匹配的字符串,ω1i和ω2i表示在字符串中第n个字分别在t1,t2中的权重;
优选的,所述步骤4:通过所述高频元素文本文档,采用关系化布局算法,将所述高频元素文本文档的元素设置在二维空间上,元素之间的距离完全取决于它们之间的语义描述,将摆放好的元素依据它们之间的语义描述进行聚类,使得同一个聚类的信息表达一个主题,将聚类信息通过三级影响度标识并将所述三级影响度标识标注于构建的知识图谱旁,具体包括:
预设一弱化因子σ,随着所述元素之间距离的增加,因子的值会减小,对于文档内容信息、情感,以及相互关系信息,根据其关系进行加权融合,计算公式如下:
ti=α*(ci*emovalue)+β*(σ1li1+σ2li2+σ3li3)
其中,ti表示文档的三级影响度之和,即文档影响度,ci表示文档内容影响度,emovalue表示文档情感值,li1、li2、li3分别代表每级的影响度,α、β为评价影响度的各个指标的权重。
优选的,所述步骤5:依据三级影响度标识标注的知识图谱,使用元素语义,以适合基于语义的文本可视化展示中语义信息的保留,采用知识图谱重叠消除算法,去除知识图谱中的多层重复图层,具体包括:
将所述高频元素文本文档的元素设置在二维空间上,将高频元素a和高频元素b在重叠区域引入互斥作用力,如果高频元素a和高频元素b不存在重叠部分,他们之间就不存在互斥作用力,互斥作用力的计算公式如下:
其中,k是一个给定的权重,δx,δy分别代表高频元素a和高频元素b在x轴和y轴方向上重叠的长度。
优选的,所述步骤6:采用知识图谱美化算法将知识图谱中降噪处理知识图谱中的冲突现象,采用美化算子以图结构为基础,以实体图谱层级为起点按照边和图谱层级的关系对知识图谱中错误的实体和关系进行美化,具体包括:
所述冲突现象包括:聚类冲突,即性质相同的实体,其分类关系和成员关系中存在的冲突;内部冲突,即集合及其子集之间所属关系中的冲突;宏观冲突,即整体与其组成部分之间的冲突。
如果美化前的知识图谱满足一致性约束,则进行美化之后也应该满足一致性,并且美化过程中需要最大限度的知识图谱原有的的信息和结构。
优选的,所述步骤7:对美化后的知识图谱进行评价,所述评价指标包括:层级数据、时域数据和主题文本数据,具体包括:
确定与所述个人图谱中的每个知识图谱层级相连的至少一个第一紧邻知识图谱层级,其中,所述第一紧邻知识图谱层级包括与所述每个知识图谱层级相连的上一级知识图谱层级和下一级知识图谱层级;确定所述每个知识图谱层级与所述至少一个第一紧邻知识图谱层级中的每个紧邻知识图谱层级的第三关联性时域数据;在个人知识图谱中,与每个当前知识图谱层级紧邻的所有知识图谱层级的数目,用m表示;该当前知识图谱层级与每个紧邻知识图谱层级之间的连线的粗细对应着该方向上的关联性强弱,用si(即该当前知识图谱层级与该紧邻知识图谱层级的第三关联性时域数据)表示;对于该当前知识图谱层级i,其发出的关联性时域数据即第三关联性时域数据之和的计算公式如:
其中,当前知识图谱层级i对应的r(x)越大,表示在用户的认知中,该当前知识图谱层级i对应的知识模块或知识点与其周围相邻的知识图谱层级对应的知识模块或知识点的关联性越强
以上所述仅为本申请的实施例而已,并不用于限制本申请。对于本领域技术人员来说,本申请可以有各种更改和变化。凡在本申请的精神和原理之内所作的任何修改、等同替换、改进等,均应包含在本申请的权利要求范围之内。
- 还没有人留言评论。精彩留言会获得点赞!