一种基于用户好奇心的贝叶斯个性化排序推荐方法与流程
本发明涉及个性化推荐技术领域,尤其涉及一种基于用户好奇心的贝叶斯个性化排序推荐方法。
背景技术:
随着信息技术的发展和互联网的普及,用户能够更方便地接触到更多的信息,但用户在享受信息技术带来便利的同时,也遇到了“信息过载”的问题,导致用户无法从海量的数据中找到自己想要的信息。一般来说,用户接触信息主要靠两种方式,一种是用户在互联网上手动地进行搜索,此时搜索引擎会返回一系列用户可能想要的答案;另一种就是个性化推荐,互联网会根据用户的兴趣、历史记录去为用户推荐用户感兴趣的信息。个性化推荐技术大大的降低了用户面对信息过载时的选择问题。
目前的推荐技术中,应用最广泛的当属协同过滤算法,这类算法充分利用用户的历史记录,比如评分数据、点击记录和购买记录去挖掘用户的兴趣偏好从而进行推荐,该类方法一般推荐与用户历史记录相似度比较高的物品,以寻求准确率上的提升,但是在实际应用中,总是给用户推荐与用户过去喜欢的物品一样的物品,最终会让用户产生乏味的感觉,从而对推荐的物品再也不感兴趣。此时我们需要为用户提供更具有多样性的推荐列表,从而去吸引用户注意。
心理学研究表明,好奇心可以激发起一个人的兴趣并且驱使人去做出探索行为。研究还表明,人的好奇心可以被以下特质所引起,包括新颖性(novelty)、不确定性(uncertainty)、冲突性(conflict)和复杂性(complexity)刺激等。所以本发明的目的是在不损失一定准确率的情况下,考虑用户的好奇心,多多地提升推荐列表的多样性。
技术实现要素:
本发明的目的在于克服现有技术的不足,提供一种基于用户好奇心的贝叶斯个性化排序推荐方法。本发明将用户的好奇心融入到经典的贝叶斯个性化排序中,在保证一定准确率的前提下,大大提升了推荐列表的多样性。
本发明的目的能够通过以下技术方案实现:
一种基于用户好奇心的贝叶斯个性化排序推荐方法,包括步骤:
使用有好友关系的数据集,遍历数据集中每一个用户u的历史数据,根据用户u有过正向反馈的物品构建该用户的正向物品集合(positiveuser-itemset),用字母pu表示;
对于数据集中的每一个用户,构建令用户u感到好奇的物品集合(curiosityuser-itemset),用字母cu表示;
构建用户u的负向物品集合(negativeuser-itemset),用字母nu表示。
提出优化排序准则,获取用户矩阵p和物品矩阵q;
对于每一个用户,随机从nu、pu、cu中选择物品组成物品对(positive,negative)和(curiosity,negative)进行训练,在每一次的训练迭代中不断地更新用户矩阵p和物品矩阵q。
对用户u所有没有过反馈的物品进行预测评分,选取分数最高的topn个物品进行推荐。
具体地,所述使用有好友关系的数据集里面包括两种类型的数据;一个是用户对物品的评分数据,一个是用户与用户之间的关系数据,第二个数据可以直接表示朋友关系,因此能够获得朋友的打分行为。
具体地,所述“有过正向反馈”表示该行为记录可以显示出用户的偏好,包括显性反馈数据集和隐性反馈数据集。
对于显性反馈数据集,通过用户的评分可以表示出用户的喜好,规定超过某个阈值分数的反馈可以认为用户u对此物品i有正向反馈。比如,如果是评分范围为1-5分,则规定5分才算是用户的正向反馈。
对于隐性反馈数据集,用户对某一物品产生的行为次数可以表示出用户的喜好,规定超过某个阈值次数的反馈可以认为用户u对此物品i有正向反馈。比如,如果次数无上限,则规定用户u对物品i有过2次以上的行为记录为用户对该物品有正向反馈。
本发明使用显性反馈数据。
具体地,所述对于数据集中的每一个用户,构建令用户u感到好奇的物品集合cu的步骤中,包括:
构建会令用户u产生新颖性感觉的物品集合c1;
构建会令用户u产生不确定性感觉的物品集合c2;
构建会令用户u产生冲突性感觉的物品集合c3;
构建会令用户u产生复杂性感觉的物品集合c4。
具体地,所述“会令用户u感到好奇的物品集合”表示会让用户u产生新颖性、不确定性、冲突性或者复杂性感觉的物品集合,表示为:
cu=c1∩c2∩c3∩c4
其中,cu是c1、c2、c3、c4的并集。
具体地,对于构建集合c1,使用现有的基于准确率提升的方法,比如mf算法,可以得到用户u的朋友对所有评过分的物品i的预测分数,比较预测分数与用户u的朋友对物品i打的实际分数的差值,如果差值达到一定阈值,则把物品i归为会令用户u产生新颖性感觉的物品集合c1。所述物品i不包括用户对其有过正向反馈的物品。
具体地,对于构建集合c2,统计用户u的所有朋友对物品i的评分个数,所述物品i不包括用户u对其有过正向反馈的物品,使用
例如,用户u有10个朋友,其中有5个朋友打了5分,3个朋友打了4分,2个朋友打了1分,则用户u的朋友中,对物品i的打分是5分的概率是1/2,对物品i的打分是4分的概率是3/10,对物品i的打分是1分的概率是1/10。
根据香浓熵公式计算出用户u对朋友们对物品i打分给用户u产生的不确定性感觉entropy(u,i)的大小,公式为:
根据dempster–shafer理论来支撑计算得到的entropy(u,i)表达‘不确定’的能力,使用符号ds(u,i)来进行表示:
其中,r表示打分分数段的最高分数值。(比如1-5分中,r=5)
则用户u对物品i产生的总不确定性感觉uncertainty(u,i)可以通过下面的公式来进行计算:
得到用户i对所有物品的不确定感觉之后,选择前topn个物品组成会令用户u产生不确定性感觉的物品集合c2。
对于构建集合c3,统计用户u的所有朋友对物品i产生正向反馈和产生负向反馈的比例p1和p2,两者相乘的值为用户u对物品i产生的冲突性强度,选择前topn个物品归为会令用户u产生冲突性感觉的物品集合c3。所述物品i不包括用户对其有过正向反馈的物品。
对于构建集合c4,用户u对物品i产生的复杂性感觉可以根据该物品和用户以往有过正反馈的物品的相似度差别是否大来进行衡量,物品i和用户历史记录中的物品越不相似,则给用户带来的复杂性感觉越大。所述物品i不包括用户对其有过正向反馈的物品。
具体地,计算两个物品之间的相似度,直接利用现有的mf算法得到的物品矩阵q。q矩阵中的每一列都代表一个物品,所以两列元素的余弦值可以表示这两个物品的相似度值,从而可以求得物品i与用户历史记录里面的所有物品的相似度平均值sui。对于所有的物品,按照从低到高进行排序,选择前topn个物品组成会令用户u产生复杂性感觉的物品集合c4。
具体地,所述构建用户u的负向物品集合的步骤中,把用户u有过负向反馈或者没有过反馈的物品归入集合nu,主要包括两部分物品:一种是用户有过反馈,但是反馈是负的,也即表示用户对此有不喜欢的打分;另一种是用户没有过反馈并且也不是用户可能会产生好奇的物品,即不属于集合cu的物品,则默认为用户对没有产生好奇的物品。
因此,m表示所有物品的总数量,m的大小为:
m=|pu|∪|cu|∪|nu|
具体地,本发明提出排序优化准则如下所示:
xui≥xuj,xuc≥xuj
其中,ui表示从用户u的正向反馈集合pu里面随机选择的物品i,uj表示从用户u的的负向反馈集合nu里面随机选择的物品j,uc表示从用户u的好奇心物品集合cu里面随机选择的物c。xui≥xuj优化准则假设对于用户u来说,用户u更加喜欢自己有过正向反馈的物品i而不是用户有过负向反馈的物品j;xuc≥xuj优化准则假设对于用户u来说,用户u更加喜欢能让自己产生好奇心的物品c而不是会产生负向反馈的物品j。该公式的目的是通过训练去加大用户u喜欢i物品和喜欢j物品的概率差值以及用户u喜欢c物品和喜欢j物品的概率差值,希望最后可以得到一个很好的排序顺序列表。
现在,这里使用下面的公式来表示上面两个假设:
其中,pr(xui≥xuj)表示xui≥xuj的概率,pr(xuc≥xuj)表示xuc≥xuj的概率,δ(·)和∈(·)是二进制的常量,表示为:
所以上述的公式可以被重写为:
这里使用sigmoid函数
其中,
(5)这里使用sgd去优化以上公式。对于每一个用户,首先是随机从nu、pu、cu中选择物品组成物品对(positive,negative)和(curiosity,negative)进行训练,在每一次的训练迭代中不断地更新用户矩阵p和物品矩阵q。
具体的cbpr算法公式推导如下,令
xui表示的是用户u对物品i的预测评分,具体计算是通过计算用户矩阵p中的第u行与物品矩阵q中的第i行的乘积得到的。xuj以及xuc的计算也是类推,xuij表示的是预测用户u对物品i和物品j喜欢的评分差值,xucj表示的是预测用户u对物品c和物品j喜欢的评分差值。d在这里指的是p和q矩阵中的隐因子的大小,puf表示的是p矩阵第u行第f列的一个元素值,其他qif和qcf的意思也是类推。
cbpr算法的最终目的是训练参数,得到最后想要的用户矩阵p和物品矩阵q,从而进行推荐,以下是cbpr公式的具体推导过程:
根据sgd公式,可以得到:
所以可以得到:
因此有:
当θ=puf时,
当θ=qif时,
当θ=qjf时,
当θ=qcf时,
当θ=bi时,
当θ=bj时,
当θ=bc时,
根据以上公式对用户矩阵p和物品矩阵q进行梯度更新。
具体地,所述对用户u所有没有过反馈的物品进行预测评分,选取分数最高的topn个物品进行推荐的步骤中,预测评分公式为:
其中xuj表示用户u对物品j的最后预测评分。
本发明相较于现有技术,具有以下的有益效果:
本发明可以量化能激起用户好奇心的物品,包括让用户感觉到新颖的物品(novelty)、让用户产生不确定感觉的物品(uncertainty)、让用户产生强烈冲突的物品(conflict)以及让用户觉得复杂的物品(complexity),并利用心理学中的好奇心相关理论,在不损失一定准确度的前提下,提升了排序结果的多样性。本发明在给用户进行物品推荐时,不仅考虑到用户的历史兴趣偏好,还考虑到用户的好奇心。
附图说明
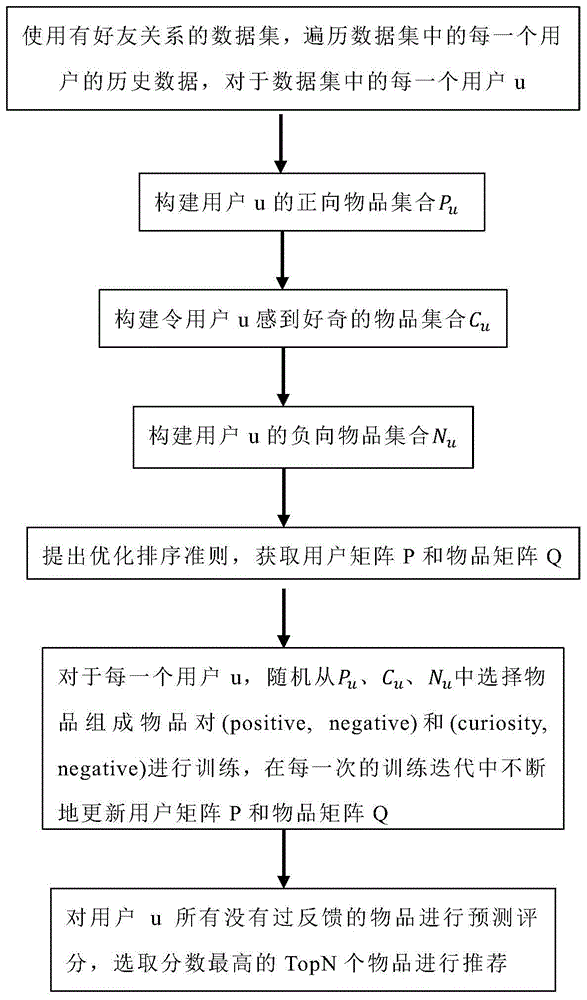
图1为基于用户好奇心的贝叶斯个性化排序方法(cbpr)的计算流程图。
具体实施方式
下面结合实施例及附图对本发明作进一步详细的描述,但本发明的实施方式不限于此。
实施例1
如图1所示为一种基于用户好奇心的贝叶斯个性化排序推荐方法的流程图,所述方法包括步骤:
(1)使用有好友关系的数据集,遍历数据集中每一个用户u的历史数据,根据用户u有过正向反馈的物品构建该用户的正向物品集合(positiveuser-itemset),用字母pu表示;
具体地,所述“有过正向反馈”表示该行为记录可以显示出用户的偏好,包括显性反馈数据集和隐性反馈数据集。
对于显性反馈数据集,通过用户的评分可以表示出用户的喜好,规定超过某个阈值分数的反馈可以认为用户u对此物品i有正向反馈。比如,如果是评分范围为1-5分,则规定5分才算是用户的正向反馈。
对于隐性反馈数据集,用户对某一物品产生的行为次数可以表示出用户的喜好,规定超过某个阈值次数的反馈可以认为用户u对此物品i有正向反馈。比如,如果次数无上限,则规定用户u对物品i有过2次以上的行为记录为用户对该物品有正向反馈。
本发明使用显性反馈数据。
(2)对于数据集中的每一个用户,构建令用户u感到好奇的物品集合(curiosityuser-itemset),用字母cu表示,包括:
(2-1)构建会令用户u产生新颖性感觉的物品集合c1;
具体地,使用现有的基于准确率提升的方法,比如mf算法,可以得到用户u的朋友对所有评过分的物品i的预测分数,比较预测分数与用户u的朋友对物品i打的实际分数的差值,如果差值达到一定阈值,则把物品i归为会令用户u产生新颖性感觉的物品集合c1。所述物品i不包括用户对其有过正向反馈的物品。
(2-2)构建会令用户u产生不确定性感觉的物品集合c2;
具体地,统计用户u的所有朋友对物品i的评分个数,所述物品i不包括用户对其有过正向反馈的物品,使用
根据香浓熵公式可以计算出用户u对朋友们对物品i打分给用户u自己产生的不确定性感觉的大小,公式为:
根据dempster–shafer理论来支撑计算得到的entropy(u,i)表达‘不确定’的能力,使用ds(u,i)来进行表示:
其中,r表示打分分数段的最高分数。则用户u对物品i产生的总不确定性感觉uncertainty(u,i)可以通过下面的公式来进行计算:
得到用户i对所有物品的不确定感觉,选择前topn个物品组成会令用户u产生不确定性感觉的物品集合c2。
(2-3)构建会令用户u产生冲突性感觉的物品集合c3;
统计用户u的所有朋友对物品i产生正向反馈和产生负向反馈的比例p1和p2,两者相乘的值为用户u对物品i产生的冲突性强度,选择前topn个物品归为会令用户u产生冲突性感觉的物品集合c3。所述物品i不包括用户对其有过正向反馈的物品。
(2-4)构建会令用户u产生复杂性感觉的物品集合c4。
本发明认为用户u对物品i产生的复杂性感觉可以根据该物品和用户以往有过正反馈的物品的相似度差别是否大来进行衡量,物品i和用户历史记录中的物品越不相似,则给用户带来的复杂性感觉越大。所述物品i不包括用户对其有过正向反馈的物品。
具体地,计算两个物品之间的相似度,直接利用已有的算法mf得到的物品矩阵q。q矩阵中的每一列都代表一个物品,所以两列元素的余弦值可以表示这两个物品的相似度值,从而可以求得物品i与用户历史记录里面的所有物品的相似度平均值sui。对于所有的物品,按照从低到高进行排序,选择前topn个物品组成会令用户u产生复杂性感觉的物品集合c4。
更进一步地,所述“会令用户u感到好奇的物品集合”表示会让用户u产生新颖性、不确定性、冲突性或者复杂性感觉的物品集合,表示为:
cu=c1∩c2∩c3∩c4
其中,cu是c1、c2、c3、c4的并集。
(3)把用户u有过负向反馈或者没有过反馈的物品归为该用户的负向物品集合(negativeuser-itemset),用字母nu表示。
nu主要包括两部分物品,首先是用户有过反馈,但是反馈是负的,也即表示用户对此有不喜欢的打分,另一种是用户没有过反馈并且也不是用户可能会产生好奇的物品。
因此,m表示所有物品的总数量,m的大小为:
m=|pu|∪|cu|∪|nu|
(4)提出排序优化准则,获取用户矩阵p和物品矩阵q;
具体地,本发明提出排序优化准则如下所示:
xui≥xuj,xuc≥xuj
其中,ui表示从用户u的正向反馈集合pu里面随机选择的物品i,uj表示从用户u的的负向反馈集合nu里面随机选择的物品j,uc表示从用户u的好奇心物品集合cu里面随机选择的物c。xui≥xuj优化准则假设对于用户u来说,用户u更加喜欢自己有过正向反馈的物品i而不是用户有过负向反馈的物品j;xuc≥xuj优化准则假设对于用户u来说,用户u更加喜欢能让自己产生好奇心的物品c而不是会产生负向反馈的物品j。该公式的目的是通过训练去加大用户u喜欢i物品和喜欢j物品的概率差值以及用户u喜欢c物品和喜欢j物品的概率差值,希望最后可以得到一个很好的排序顺序列表。
现在,这里使用下面的公式来表示上面两个假设:
其中δ(·)和∈(·)是二进制的常量,表示为:
所以上述的公式可以被重写为:
这里使用sigmoid函数
其中,
(5)这里使用sgd去优化以上公式。对于每一个用户,首先是随机从nu、pu、cu中选择物品组成物品对(positive,negative)和(curiosity,negative),在每一次的训练迭代中不断地更新用户矩阵p和物品矩阵q。
cbpr算法的最终目的是训练参数,得到最后想要的用户矩阵p和物品矩阵q,从而进行推荐,以下是cbpr公式的具体推导过程:
其中,xui表示的是用户u对物品i的预测评分,具体计算是通过计算用户矩阵p中的第u行与物品矩阵q中的第i行的乘积得到的。xuj表示的是用户u对物品j的预测评分,xuc表示的是用户u对物品c的预测评分,xuij表示的是预测用户u对物品i和物品j喜欢的评分差值,xucj表示的是预测用户u对物品c和物品j喜欢的评分差值。d在这里指的是p和q矩阵中的隐因子的大小,puf表示的是p矩阵第u行第f列的一个元素值,qif表示的是q矩阵第i行第f列的一个元素值,qjf表示的是q矩阵第j行第f列的一个元素值,qcf表示的是q矩阵第c行第f列的一个元素值。
根据sgd公式,可以得到:
所以可以得到:
因此有:
当θ=puf时,
当θ=qif时,
当θ=qjf时,
当θ=qcf时,
当θ=bi时,
当θ=bj时,
当θ=bc时,
根据以上公式对用户矩阵p和物品矩阵q进行梯度更新。
(6)对用户u所有没有过反馈的物品进行预测评分,选取分数最高的topn个物品进行推荐,公式如下:
其中xuj表示用户u对物品j的最后预测评分。
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!