一种HDFS删除文件恢复方法、终端设备及存储介质与流程
本发明涉及文件恢复领域,尤其涉及一种hdfs删除文件恢复方法、终端设备及存储介质。
背景技术:
hdfs文件系统是运行在通用硬件上的分布式文件系统,随着大数据的发展与普及,其删除文件的恢复技术在智能设备安全、网络信息安全领域将是一个备受关注的热点。目前对hdfs文件系统的文件提取均需通过hadoop服务器进行文件读取,在hadoop服务器未启动情况下,无法读取hdfs文件系统存储的文件;在hdfs文件删除情况下,国内外还没有发现有软件支持hdfs文件系统的删除恢复,导致无法深入对hdfs分布式文件系统删除文件进行取证。
技术实现要素:
为了解决上述问题,本发明提出了一种hdfs删除文件恢复方法、终端设备及存储介质。
具体方案如下:
一种hdfs删除文件恢复方法,包括以下步骤:
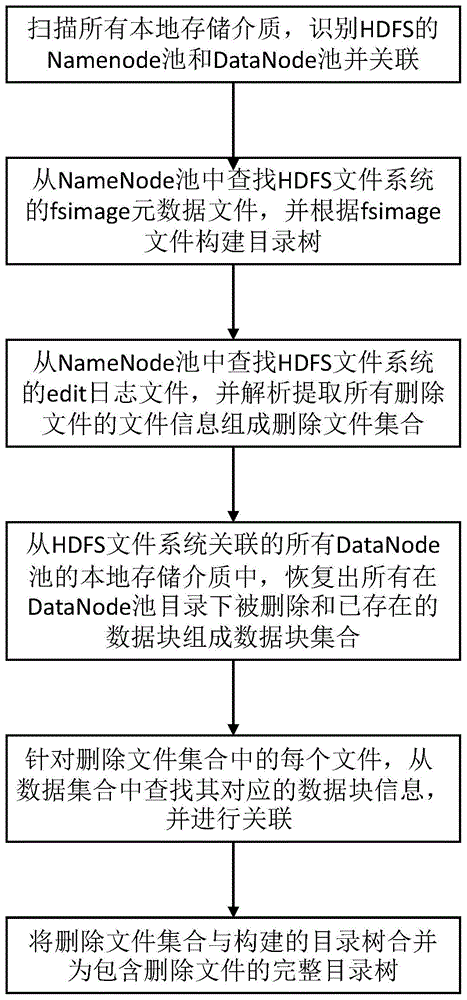
s1:扫描所有本地存储介质,识别hdfs的namenode池和datanode池,并关联同一个hdfs对应的namenode池和datanode池;
s2:从hdfs的namenode池中查找hdfs文件系统的fsimage元数据文件,并根据fsimage文件构建目录树;
s3:从hdfs的namenode池中查找hdfs文件系统的edit日志文件,并解析hdfs的edit日志文件,提取所有删除文件的文件信息组成删除文件集合;
s4:从hdfs文件系统关联的所有datanode池的本地存储介质中,恢复出所有在datanode池目录下被删除和已存在的数据块组成数据块集合;
s5:针对删除文件集合中的每个文件,从数据集合中查找其对应的数据块信息,并进行关联;当删除文件的数据块信息记载的所有数据块都完整查找到,将该文件标注为可恢复;当删除文件的数据块信息记载的数据块只有部分能够查找到,将该文件标注为部分可恢复;当删除文件的数据块信息记载的部分数据块都查找不到,将该文件标注为不可恢复;
s6:将删除文件集合与构建的目录树合并为包含删除文件的完整目录树。
进一步的,步骤s1具体包括以下步骤:
s11:扫描所有本地存储介质,获取所有具有hdfs目录结构的目录;
s12:读取hdfs目录结构下的version文件,并获取clusterid和uuid;
s13:通过clusterid和uuid,关联同一个hdfs的数据池,即namenode池和datanode池。
进一步的,步骤s2中目录树的构建方法包括以下步骤:
s21:根据fsimage文件中的filesummarylength,计算filesummary所占的位置和长度;
s22:根据filesummary文件,解析其中的inodesection和directionsection两个块的位置和长度;
s23:根据inodesection,提取hdfs文件系统存储的所有文件的文件系统以及文件的数据块信息;
s24:根据directionsection,构建hdfs文件系统的目录树。
进一步的,步骤s3中删除文件集合的获取方法包括以下步骤:
s31:提取hdfs文件系统对应的所有edit日志文件组成日志集合;
s32:依次解析日志集合中的每个日志文件,筛选出所有的opcode参数值为op_add的日志文件,并提取其对应的文件属性和数据块信息,将所有筛选出的日志文件对应的文件属性和数据块信息组成新增文件集合;
s33:依次解析日志集合中的每个日志文件,筛选出所有的opcode参数值为op_delete的日志文件,并提取其对应的文件属性和数据块信息,将所有筛选出的日志文件对应的文件属性和数据块信息组成的集合与新增文件集合的交集作为删除文件集合。
一种hdfs删除文件恢复终端设备,包括处理器、存储介质以及存储在所述存储介质中并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现本发明实施例上述的方法的步骤。
一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现本发明实施例上述的方法的步骤。
本发明采用如上技术方案,基于hdfs的日志特点结合本地存储介质文件系统的删除恢复功能,通过日志重新构建文件系统目录结构,恢复出丢失文件,为hdfs文件系统上因为误删除或者恶意删除导致的数据丢失提供了解决方案,填补了国内hdfs删除文件恢复技术方便的空白。恢复过程不需要hadoop服务运行和hadoop服务器运行日志以及hadoop的软件支撑。
附图说明
图1所示为本发明实施例一的流程图。
图2所示为该实施例中hdfs文件系统的结构示意图。
图3所示为该实施例中hdfs文件系统的框架示意图。
图4所示为该实施例中fsimage文件的结构示意图。
图5所示为该实施例中的实验结果示意图。
具体实施方式
为进一步说明各实施例,本发明提供有附图。这些附图为本发明揭露内容的一部分,其主要用以说明实施例,并可配合说明书的相关描述来解释实施例的运作原理。配合参考这些内容,本领域普通技术人员应能理解其他可能的实施方式以及本发明的优点。
现结合附图和具体实施方式对本发明进一步说明。
实施例一:
本发明实施例提出一种hdfs删除文件恢复方法,如图1所示,包括以下步骤:
s1:扫描所有本地存储介质,识别hdfs的namenode池和datanode池,并关联同一个hdfs对应的namenode池和datanode池。
hdfs会在其所在的hadoop服务器运行的主机集群上创建一个namenode池和若干个datanode池。所有datanode池和namenode池都有一个version文件,version文件包含当前数据池的clusterid、uuid以及数据池类型。当扫描到存储介质中存在目录结构与hdfs数据池的目录结构一致时候,读取version文件内容,通过version文件的内容可以判断是否为hdfs的数据池。所有存储介质扫描结束后,通过version文件的clusterid和uuid关联同一个hdfs的namenode和所有datanode。
需要说明的是,单个本地主机通常只会运行一个hdfs,但是存在格式化后重建hadoop服务的情况,所以需要重新识别数据池所属的hdfs。再者可能会存在多块存储介质进行数据恢复时候,在不同存储介质中可能存在多个hdfs文件系统的数据池,因此也需要重新区分。
步骤s1具体包括以下步骤:
s11:扫描所有本地存储介质,获取所有具有hdfs目录结构的目录。
s12:读取hdfs目录结构下的version文件,并获取clusterid和uuid。
s13:通过clusterid和uuid,关联同一个hdfs的数据池,即namenode池和datanode池。
s2:从hdfs的namenode池中查找hdfs文件系统的fsimage元数据文件,并根据fsimage文件构建目录树。
hdfs文件系统是一种主从体系的分布式文件系统,其概念图如图2所示,其中,master代表hdfs的主机,slave代表hdfs的从机,clien代表用户客户端。
hdfs文件系统在主从机器的磁盘上建立namenode和datanode两类节点用来存放元数据和数据。也就是说hdfs是建立在本地文件系统之上的分布式文件系统,其框架图如图3所示。
namenode为hdfs的名称节点,相当于hdfs的元数据。namenode用来管理hdfs中的目录树、文件以及文件信息。datanode为hdfs的数据节点,负责存储hdfs的数据。block为数据块,hdfs文件系统将一个文件分割成若干个数据块后,再将均匀分布存放在从机的datanode节点上。
hdfs在主机的namenode节点上创建一个以“fsimage”开头的文件用来存放元数据(下面统称为fsimage文件),并创建一系列以“edit”开头的文件(下面统称为edit日志)用来存放操作日志。
hdfs将元数据保存到fsimage文件中,fsimage文件用于存储文件的属性以及数据块信息。通过分析fsimage的文件结构才能进行文件解析。fsimage的文件结构如图4所示。
在hdfs中,文件和文件夹都被抽象成一个inode(索引节点),使用fsimage文件中的inodesection片段管理文件和文件夹信息。而文件的目录使用fsimage文件中的directorysection片段进行管理。
目录树的构建方法包括以下步骤:
s21:根据fsimage文件中的filesummarylength,计算filesummary所占的位置和长度。
s22:根据filesummary,解析其中的inodesection和directionsection两个块的位置和长度。
s23:根据inodesection,提取hdfs文件系统存储的所有文件的文件系统以及文件的数据块信息。
s24:根据directionsection,构建hdfs文件系统的目录树。
s3:从hdfs的namenode池中查找hdfs文件系统的edit日志文件,并解析hdfs的edit日志文件,提取所有删除文件的文件信息组成删除文件集合。
edit日志保存着hdfs的操作日志,包括创建文件,创建路径,删除文件等动作。edit日志中通过参数opcode来记录用户操作,参数opcode为op_add时表示用户添加文件,opcode为op_delete时表示用户删除文件,opcode为op_close时表示用户操作完成。用户删除文件时候,hdfs只会通过path这个参数来记载哪个文件被删除。而用户添加文件时候,hdfs会记录用户添加文件的时间、文件长度,以及数据块信息,数据块信息是恢复文件的重要信息,在edit日志中通过参数block来记录数据块信息,该实施例中所述数据块信息包括数据块的id,数据块的大小等。在hdfs中只需要获取到数据块的id,就可以在datanode中获取到数据块。即通过获取到被删除文件的参数block,就可以实现数据恢复。
删除文件集合的获取方法包括以下步骤:
s31:提取hdfs文件系统对应的所有edit日志文件组成日志集合。
s32:依次解析日志集合中的每个日志文件,筛选出所有的opcode参数值为op_add的日志文件,并提取其对应的文件属性和数据块信息,将所有筛选出的日志文件对应的文件属性和数据块信息组成新增文件集合。
s33:依次解析日志集合中的每个日志文件,筛选出所有的opcode参数值为op_delete的日志文件,并提取其对应的文件属性和数据块信息,将所有筛选出的日志文件对应的文件属性和数据块信息组成的集合与新增文件集合的交集作为删除文件集合。
所述文件属性为文件的时间、文件长度,所述数据块信息为包含参数block的信息。
s4:从hdfs文件系统关联的所有datanode池的本地存储介质中,利用本地存储介质的文件系统或者其他存储特性的数据恢复技术,恢复出所有在datanode池目录下被删除和已存在的数据块,并组成数据块集合。
s5:针对删除文件集合中的每个文件,从数据集合中查找其对应的数据块信息,并进行关联;当删除文件的数据块信息记载的所有数据块都完整查找到,将该文件标注为可恢复;当删除文件的数据块信息记载的数据块只有部分能够查找到,将该文件标注为部分可恢复;当删除文件的数据块信息记载的部分数据块都查找不到,将该文件标注为不可恢复。
通过对删除文件进行标注,可以帮助用户确定删除文件的内容是否恢复完全。当标注为可恢复时,文件可以完整显示;当标注为部分可恢复时,文件仅可部分显示或不能显示,其根据具体的文件特性决定;当标注为不可恢复时,文件不能显示。
s6:将删除文件集合与构建的目录树合并为包含删除文件的完整目录树,实现删除文件的恢复。
将删除文件集合中的被删除文件添加至目录树中,更新后的目录树为包含被删除文件的完整目录树,则hdfs文件系统中可以显示被删除的文件。
实验结果:
为验证本实施例的正确性和有效性,进行以下实验:
1、搭建一个三个节点的hdfs集群文件系统;
2、运行hdfs集群,往hdfs文件系统中加入文件movi9936.avi等文件;
3、删除movi9936.avi文件;
4、关闭hdfs集群,然后将hdfs集群三个节点的主机硬盘作成镜像;
5、解析hdfs主机的硬盘镜像,解析中发现存在hdfs集群,采用本实施例中方法对hdfs集群进行数据恢复。恢复效果如图5所示,从图中可以看出,movi9936.avi文件已被完整恢复。
本发明实施例在对hdfs运行原理进行研究以及大量实验的基础上,提出一种hdfs删除文件的恢复方法。该方法为hdfs文件系统上因为误删除或者恶意删除导致的数据丢失提供了解决方案,填补了国内hdfs删除文件恢复技术方便的空白。本实施例利用hdfs文件系统的日志特性并结合本地磁盘文件系统的数据恢复方法,挖掘其中存在过的痕迹,达到恢复文件的目的。
本发明实施例并不局限于本地存储介质的类型以及本次存储介质上搭载文件系统的类型,不需要hadoop服务运行和hadoop服务器运行日志以及不需要hadoop的任何软件帮助下,直接从本地存储介质中识别出hdfs文件系统部署过的痕迹,再利用hdfs文件系统的日志特性并结合本地磁盘文件系统的数据恢复方法,挖掘其中存在过的痕迹,达到恢复文件的目的。
实施例二:
本发明还提供一种hdfs删除文件恢复终端设备,包括存储介质、处理器以及存储在所述存储介质中并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现本发明实施例一的上述方法实施例中的步骤。
进一步地,作为一个可执行方案,所述hdfs删除文件恢复终端设备可以是桌上型计算机、笔记本、掌上电脑及云端服务器等计算设备。所述hdfs删除文件恢复终端设备可包括,但不仅限于,处理器、存储介质。本领域技术人员可以理解,上述hdfs删除文件恢复终端设备的组成结构仅仅是hdfs删除文件恢复终端设备的示例,并不构成对hdfs删除文件恢复终端设备的限定,可以包括比上述更多或更少的部件,或者组合某些部件,或者不同的部件,例如所述hdfs删除文件恢复终端设备还可以包括输入输出设备、网络接入设备、总线等,本发明实施例对此不做限定。
进一步地,作为一个可执行方案,所称处理器可以是中央处理单元(centralprocessingunit,cpu),还可以是其他通用处理器、数字信号处理器(digitalsignalprocessor,dsp)、专用集成电路(applicationspecificintegratedcircuit,asic)、现场可编程门阵列(field-programmablegatearray,fpga)或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件等。通用处理器可以是微处理器或者该处理器也可以是任何常规的处理器等,所述处理器是所述hdfs删除文件恢复终端设备的控制中心,利用各种接口和线路连接整个hdfs删除文件恢复终端设备的各个部分。
所述存储介质可用于存储所述计算机程序和/或模块,所述处理器通过运行或执行存储在所述存储介质内的计算机程序和/或模块,以及调用存储在存储介质内的数据,实现所述hdfs删除文件恢复终端设备的各种功能。所述存储介质可主要包括存储程序区和存储数据区,其中,存储程序区可存储操作系统、至少一个功能所需的应用程序;存储数据区可存储根据手机的使用所创建的数据等。此外,存储介质可以包括高速随机存取存储介质,还可以包括非易失性存储介质,例如硬盘、内存、插接式硬盘,智能存储卡(smartmediacard,smc),安全数字(securedigital,sd)卡,闪存卡(flashcard)、至少一个磁盘存储介质、闪存器件、或其他易失性固态存储介质。
本发明还提供一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行时实现本发明实施例上述方法的步骤。
所述hdfs删除文件恢复终端设备集成的模块/单元如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本发明实现上述实施例方法中的全部或部分流程,也可以通过计算机程序来指令相关的硬件来完成,所述的计算机程序可存储于一计算机可读存储介质中,该计算机程序在被处理器执行时,可实现上述各个方法实施例的步骤。其中,所述计算机程序包括计算机程序代码,所述计算机程序代码可以为源代码形式、对象代码形式、可执行文件或某些中间形式等。所述计算机可读介质可以包括:能够携带所述计算机程序代码的任何实体或装置、记录介质、u盘、移动硬盘、磁碟、光盘、计算机存储器、只读存储器(rom,rom,read-onlymemory)、随机存取存储器(ram,randomaccessmemory)以及软件分发介质等。
尽管结合优选实施方案具体展示和介绍了本发明,但所属领域的技术人员应该明白,在不脱离所附权利要求书所限定的本发明的精神和范围内,在形式上和细节上可以对本发明做出各种变化,均为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!