一种数据包文件时序恢复系统的制作方法
本申请涉及数据恢复相关领域,具体是一种数据包文件时序恢复系统。
背景技术:
现有的网络流量分析产品主要的设计目标是解决实时流量的分析和处理。但在实际业务工作中存在特别多的数据包文件,这些文件是由于临时检测任务,或者移动介质或文件服务器拷贝而来。虽然都是以数据包为单位的流量,但流量转存为文件后把原本连续的时序切割的支离破碎,让传统的流量分析产品遇到了很大的困难,因为大多数的流量分析产品只能够分析顺序到达的数据包流量。
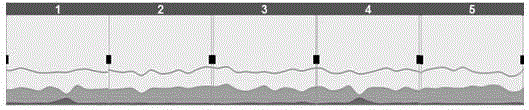
图1是正常的连续5秒到达的数据流量,图2是假设每1秒转存一个数据包文件,5秒后切割成了5个独立的数据包文件,再次读取文件的分析的时候,如果要保证正常的时序。要么就只读一个文件,通常单文件内时序是正常的。但这样的只能见局部,没有了整体视角。形成分析的孤岛。通常因为时间太短,会话都被截断不完整,一个数据包文件连一个会话都分析不了。
如果把按顺序读取文件,从第一秒到第二秒。困难在于文件之间已经相互独立,通常遇到的图3所示已经无法读取时序。第一秒的数据包文件不会自己站出来,而且真实的业务中数据文件远远不只5个,而是成千上万,数据包文件的名字也起的千奇百怪。导致众多数据包文件无法恢复到正确的时序。
现有专利如专利申请号为201910125261.9,名称为《一种无线传感器网络数据传输和恢复的方法》,其技术方案如下:本发明公开了一种无线传感器网络数据传输和恢复的方法,针对实时性要求不高的无线传感器网络,周期进行采集和传输数据,包括传感器节点传输数据方法和对应的基站接收到数据后恢复数据方法两个方面。传感器节点每周期随机选取确定数量的少量时序,感知信息得到数据,基于无线传感器网络数据随时间变化小的特点,传感器节点去除未感知的时序,得到新的不含零的数据集,根据压缩感知方法进行数据编码压缩并传输;基站接收到数据后先用重构方法重构出少量时序的数据集,再用矩阵填充方法恢复出完整数据。
上述专利虽然也是一种数据传输和恢复方法,当时其仍然不能很好解决现有技术中存在的大规模数据下的数据时序恢复的问题。
技术实现要素:
本申请针对上述现有应用中存在的不足和问题,提供一种解决海量的数据包文件的时序恢复处理,实现乱序的输入,顺序的输出,把转存文件后支离破碎的时序再重现连接到一起的数据包文件时序恢复系统。
为实现上述技术效果,本申请的技术方案如下:
一种数据包文件时序恢复系统,其特征在于,包括:
存储系统,用于实现数据包文件的存储;
时间片索引系统,用于按时间片记录数据包文件的链路信息和存储偏移信息;链路信息具体是指数据包文件从哪个链路而来。
排序系统,用于实现单时间片内的数据包文件时间排序;
其工作流程如下:
首先,将得到的数据包逐个进行处理,读取数据包的时间戳后,按照时间片对单个数据包进行切割处理,得到切割后的数据包文件,并将各数据包文件写入存储系统;
其次,记录每个数据包文件在单位时间片内的beginoffset和offsetlength信息,并且将每个数据包文件的时间片信息、beginoffset和offsetlength信息记录到时间片索引系统;偏移信息包括beginoffset和offsetlength信息。
再次,要进行数据输出时,先指定具体的链路和时间范围,按照时间顺序从第一个时间片开始,时间片索引系统读取由相应偏移信息构成的索引偏移序列,并读取存储系统中对应的数据包文件。
最后,读取完成同一个时间片的数据包文件后,将其缓存至内存中,并放入排序系统进行实时排序,完成时间片内排序后,再推送到查询接口。因为数据包的时间戳精度往往在微秒甚至纳秒级别,在时间片内依然存在数据包乱序,但经过前序的系统处理,时间片内乱序的数据大小已经可控,完全可以放在内存中进行高性能的实时排序。具体排序系统如何排序属于本领域的常规技术,本申请不做赘述。
进一步地,时间片索引系统为多链路时序连接的并发系统。由于数据包文件可能来源于不同的链路,并且不同的链路流量是相互独立的,所以多链路的并发系统可以同时处理不同链路流量的时序连接。
进一步地,所述时间片的范围为1秒-10秒。
进一步地,每个时间片下挂载了数据包文件对应于该时间片的偏移序列。
进一步地,将数据包文件写入存储系统后,记录
第1秒的beginoffset和offsetlength;
第2秒的beginoffset和offsetlength;……;
第n秒的beginoffset和offsetlength。n为自然数,表示持续的秒数。
beginoffset指数据包文件的偏移起始点,offsetlength标识数据包文件的偏移长度。
不同的数据包文件中可能有对应同一时间片的流量,所以通常时间片索引连接的是来源不同的数据包文件的偏移信息。如图4所示,在时间片为1秒的前提下,链路a的第1秒包括了三个不同的额数据包文件的偏移信息,即数据包文件a,和数据包文件b和数据包文件c,三个不同来源的数据包文件同时对应相同的时间片上。
本申请有益效果:
1、本申请的时间片索引系统把针对于大规模数据包文件的乱序问题简化为时间片内乱序问题,然后通过时间片内排序实现时序恢复的效果,并能支持多链路的并发写入与输出。
2、本系统可使用普通的硬件服务器,便能支持秒内数据输出响应,能实现纳秒级精度的数据包排序。
附图说明
图1为正常的连续5秒到达的数据流量。
图2为假设每1秒转存一个数据包文件示意。
图3为无法读取时序的数据包文件示意。
图4为本申请时间片索引系统的结构示意图。
具体实施方式
实施例1
一种数据包文件时序恢复系统,包括:
存储系统,用于实现数据包文件的存储;
时间片索引系统,用于按时间片记录数据包文件的链路信息和存储偏移信息;链路信息具体是指数据包文件从哪个链路而来。
排序系统,用于实现单时间片内的数据包文件时间排序;
其工作流程如下:
首先,将得到的数据包逐个进行处理,读取数据包的时间戳后,按照时间片对单个数据包进行切割处理,得到切割后的数据包文件,并将各数据包文件写入存储系统;
其次,记录每个数据包文件在单位时间片内的beginoffset和offsetlength信息,并且将每个数据包文件的时间片信息、beginoffset和offsetlength信息记录到时间片索引系统;偏移信息包括beginoffset和offsetlength信息。所述时间片的范围为1秒-10秒。将数据包文件写入存储系统后,记录
第1秒的beginoffset和offsetlength;第2秒的beginoffset和offsetlength……第n秒的beginoffset和offsetlength。beginoffset指数据包文件的偏移起始点,offsetlength标识数据包文件的偏移长度。
再次,要进行数据输出时,先指定具体的链路和时间范围,按照时间顺序从第一个时间片开始,时间片索引系统读取由相应偏移信息构成的索引偏移序列,并读取存储系统中对应的数据包文件。每个时间片下挂载了数据包文件对应于该时间片的偏移序列。
最后,读取完成同一个时间片的数据包文件后,将其缓存至内存中,并放入排序系统进行实时排序,完成时间片内排序后,再推送到查询接口。因为数据包的时间戳精度往往在微秒甚至纳秒级别,在时间片内依然存在数据包乱序,但经过前序的系统处理,时间片内乱序的数据大小已经可控,完全可以放在内存中进行高性能的实时排序。具体排序系统如何排序属于本领域的常规技术,本申请不做赘述。
进一步地,时间片索引系统为多链路时序连接的并发系统。由于数据包文件可能来源于不同的链路,并且不同的链路流量是相互独立的,所以多链路的并发系统可以同时处理不同链路流量的时序连接。
不同的数据包文件中可能有对应同一时间片的流量,所以通常时间片索引连接的是来源不同的数据包文件的偏移信息。如图4所示,同时包含有链路a、链路b和链路c,三个不同的链路可同时工作,在时间片为1秒的前提下,链路a的第1秒包括了三个不同的额数据包文件的偏移信息,即数据包文件a,和数据包文件b和数据包文件c,三个不同来源的数据包文件同时对应相同的时间片上。
本申请的时间片索引系统把针对于大规模数据包文件的乱序问题简化为时间片内乱序问题,然后通过时间片内排序实现时序恢复的效果,并能支持多链路的并发写入与输出。本系统可使用普通的硬件服务器,便能支持秒内数据输出响应,能实现纳秒级精度的数据包排序。
实施例2
在实施例1的基础上,下面用具体的例子对本申请的文件时序回复系统进行说明。
文件a属于链路a的流量,并且持续5秒。
此时按时间片为1秒将流量切分为5段(即5个偏移块),写入存储系统起始偏移为0。其偏移信息如下表所示:
文件b也属于链路a的流量,持续5秒,从第5秒开始,与a文件有一秒的重叠时间。
按时间片为1秒切分为5段(即5个偏移块),由于先写入了a文件,起始偏移为5,242,880,其偏移信息如下表所示:
文件c属于链路b的流量,持续5秒,按时间片为1秒切分为5段(即5个偏移块),由于先写入了链路a的文件a和文件b,所以起始偏移为10,485,760,其偏移信息如下表所示:
则最后经过文件时序恢复系统进行时序恢复后的流量数据如下:
- 还没有人留言评论。精彩留言会获得点赞!