数据脱敏方法与装置、电子设备及存储介质与流程
本公开涉及数据处理技术领域,尤其涉及一种数据脱敏方法与装置、电子设备及计算机可读存储介质。
背景技术:
在各个领域中,随着信息化建设进程的推进,对数据的互联互通的需求与日俱增,但与此同时,数据的安全问题也较为突出。数据脱敏可以对某些敏感信息通过脱敏规则进行数据的变形,实现敏感隐私数据的可靠保护。例如,在医疗领域,医疗数据脱敏是将涉及到患者基本信息、医疗过程中的敏感信息通过脱敏规则进行数据的变形,以达到保护敏感数据的目的。相关技术中,敏感数据的识别依赖人工整理的字段信息、黑白名单或规则,识别的效率及准确率较低,导致数据脱敏的效率及准确率较低。
技术实现要素:
本公开的目的在于提供一种数据脱敏方法与装置、电子设备及计算机可读存储介质,进而至少在一定程度上克服由于现有技术的限制和缺陷而导致的数据脱敏的效率及准确率较低的问题。
本公开的其他特性和优点将通过下面的详细描述变得显然,或部分地通过本公开的实践而习得。
根据本公开的第一方面,提供一种数据脱敏方法,包括:
获取待脱敏文本,并对所述待脱敏文本进行分词,得到多个词语和该词语的词性,根据所述词语的词性对所述词语进行过滤处理,得到待脱敏数据;
根据预设的独立敏感数据识别模型和部分敏感数据识别模型,对所述待脱敏数据中的词语进行脱敏。
可选的,通过预设的独立敏感数据识别模型对所述待脱敏数据中的词语进行脱敏,包括:
针对所述待脱敏数据中的每个词语,将该词语及该词语的属性信息转换为对应的属性向量;
通过独立敏感数据识别模型对所述属性向量进行处理,得到所述属性向量对应的属性值;
根据所述属性值确定该词语是否是独立敏感数据,并在确定该词语是独立敏感数据时,对该词语进行脱敏。
可选的,所述独立敏感数据识别模型是通过以下方式训练得到:
获取经过敏感数据标记的原始数据集,根据所述原始数据集中标记的敏感数据构建敏感词库;
按照预设规则对所述敏感词库中的词语进行分类,确定所述敏感词库中每个词语所属的敏感数据类型;
针对独立敏感数据类型的每个词语,将该词语及该词语的属性信息转换为对应的属性向量;
根据所述独立敏感数据类型的词语对应的属性向量及预先设置的属性值,通过逻辑回归算法建立所述独立敏感数据识别模型。
可选的,所述部分敏感数据识别模型是通过以下方式训练得到:
针对部分敏感数据类型的每个词语,确定该词语在所述原始数据集中对应的目标敏感数据;
获取与该词语相似度大于相似度阈值的相似词语,将所述目标敏感数据中的该词语替换为所述相似词语,得到更新的数据;
在所述原始数据集中检索不到所述更新的数据时,获取用户针对所述更新的数据输入的敏感数据识别结果;
将所述更新的数据及所述敏感数据识别结果添加至所述原始数据集中,将更新后的原始数据集作为所述部分敏感数据识别模型。
可选的,通过预设的部分敏感数据识别模型对所述待脱敏数据中的词语进行脱敏,包括:
针对所述待脱敏数据中的每个词语,在所述部分敏感数据识别模型中对该词语进行检索;
在检索到该词语时,判断该词语是否是敏感数据;
在该词语是敏感数据时,对该词语进行脱敏。
可选的,根据预设的独立敏感数据识别模型和部分敏感数据识别模型,对所述待脱敏数据中的词语进行脱敏,包括:
确定所述待脱敏数据中每一词语的敏感数据类型;
将属于独立敏感数据类型的词语通过预设的独立敏感数据识别模型进行脱敏;
将属于部分敏感数据类型的词语通过预设的部分敏感数据识别模型进行脱敏。
可选的,在建立所述独立敏感数据识别模型后,所述方法还包括:
获取经过敏感数据标记的训练数据集,从所述训练数据集的敏感数据中选取敏感数据类型为独立敏感数据类型的第一目标训练词语;
通过所述独立敏感数据识别模型对所述第一目标训练词语进行识别,得到预测值;
选取与所述独立敏感数据类型对应的属性值的差值小于差值阈值的预测值;
根据所选取的预测值对应的第二目标训练词语对所述独立敏感数据识别模型进行更新。
根据本公开的第二方面,提供一种数据脱敏装置,包括:
预处理模块,用于获取待脱敏文本,并对所述待脱敏文本进行分词,得到多个词语和该词语的词性,根据所述词语的词性对所述词语进行过滤处理,得到待脱敏数据;
脱敏模块,用于根据预设的独立敏感数据识别模型和部分敏感数据识别模型,对所述待脱敏数据中的词语进行脱敏。
可选的,所述脱敏模块,包括:第一脱敏子模块,所述第一脱敏子模块包括:
向量转换单元,用于针对所述待脱敏数据中的每个词语,将该词语及该词语的属性信息转换为对应的属性向量;
属性值确定单元,用于通过独立敏感数据识别模型对所述属性向量进行处理,得到所述属性向量对应的属性值;
独立敏感数据脱敏单元,用于根据所述属性值确定该词语是否是独立敏感数据,并在确定该词语是独立敏感数据时,对该词语进行脱敏。
可选的,本公开实施例的数据脱敏装置,还包括:
敏感词库构建模块,用于获取经过敏感数据标记的原始数据集,根据所述原始数据集中标记的敏感数据构建敏感词库;
敏感数据类型确定模块,用于按照预设规则对所述敏感词库中的词语进行分类,确定所述敏感词库中每个词语所属的敏感数据类型;
属性向量确定模块,用于针对独立敏感数据类型的每个词语,将该词语及该词语的属性信息转换为对应的属性向量;
独立敏感数据识别模型建立模块,用于根据所述独立敏感数据类型的词语对应的属性向量及预先设置的属性值,通过逻辑回归算法建立所述独立敏感数据识别模型。
可选的,本公开实施例的数据脱敏装置,还包括:
目标敏感数据确定模块,用于针对部分敏感数据类型的每个词语,确定该词语在所述原始数据集中对应的目标敏感数据;
相似词语替换模块,用于获取与该词语相似度大于相似度阈值的相似词语,将所述目标敏感数据中的该词语替换为所述相似词语,得到更新的数据;
识别结果获取模块,用于在所述原始数据集中检索不到所述更新的数据时,获取用户针对所述更新的数据输入的敏感数据识别结果;
部分敏感数据识别模型建立模块,用于将所述更新的数据及所述敏感数据识别结果添加至所述原始数据集中,将更新后的原始数据集作为所述部分敏感数据识别模型。
可选的,所述脱敏模块,包括:第二脱敏子模块,所述第二脱敏子模块包括:
检索单元,用于针对所述待脱敏数据中的每个词语,在所述部分敏感数据识别模型中对该词语进行检索;
敏感数据判断单元,用于在检索到该词语时,判断该词语是否是敏感数据;
敏感数据脱敏单元,用于在该词语是敏感数据时,对该词语进行脱敏。
可选的,所述脱敏模块,具体用于确定所述待脱敏数据中每一词语的敏感数据类型;将属于独立敏感数据类型的词语通过预设的独立敏感数据识别模型进行脱敏;将属于部分敏感数据类型的词语通过预设的部分敏感数据识别模型进行脱敏。
可选的,本公开实施例的数据脱敏装置,还包括:
模型更新模块,用于获取经过敏感数据标记的训练数据集,从所述训练数据集的敏感数据中选取敏感数据类型为独立敏感数据类型的第一目标训练词语;通过所述独立敏感数据识别模型对所述第一目标训练词语进行识别,得到预测值;选取与所述独立敏感数据类型对应的属性值的差值小于差值阈值的预测值;根据所选取的预测值对应的第二目标训练词语对所述独立敏感数据识别模型进行更新。
根据本公开的第三方面,提供一种电子设备,包括:处理器;以及存储器,用于存储所述处理器的可执行指令;其中,所述处理器配置为经由执行所述可执行指令来执行上述任意一项所述的方法。
根据本公开的第四方面,提供一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现上述任意一项所述的方法。
本公开的示例性实施例具有以下有益效果:
本公开的示例性实施例提供的数据脱敏方法及装置中,通过独立敏感数据识别模型和部分敏感数据识别模型,对待脱敏数据中的词语进行脱敏,可以自动对待脱敏数据进行数据脱敏,可以减少人工成本,提高数据脱敏的效率。并且,不同敏感数据类型的词语可以建立不同的模型,即独立敏感数据识别模型和部分敏感数据识别模型,根据多个不同的模型进行数据脱敏,可以提高数据脱敏的准确性。另外,通过对待脱敏文本进行分词和过滤处理,得到待脱敏数据,可以降低计算的复杂度,提高数据脱敏的效率。
应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本公开。
附图说明
此处的附图被并入说明书中并构成本说明书的一部分,示出了符合本公开的实施例,并与说明书一起用于解释本公开的原理。显而易见地,下面描述中的附图仅仅是本公开的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1示出了通过xml路径语言识别和标记半结构化数据中的数据的一种示意图;
图2示出了本公开实施例中数据脱敏方法的一种流程图;
图3示出了本公开实施例中独立敏感数据识别模型和部分敏感数据识别模型建立方法的一种流程图;
图4示出了一种依存关系示意图;
图5示出了本公开实施例中通过独立敏感数据识别模型对待脱敏数据中的词语进行脱敏的方法流程图;
图6示出了本公开实施例中通过部分敏感数据识别模型对待脱敏数据中的词语进行脱敏的方法流程图;
图7示出了本公开实施例中通过独立敏感数据识别模型和部分敏感数据识别模型进行数据脱敏方法的一种流程图;
图8示出了本公开实施例中对独立敏感数据识别模型进行更新的一种流程图;
图9示出了本公开实施例中数据脱敏装置的一种结构示意图;
图10示出了用于实现本公开实施例的电子设备的计算机系统的结构示意图。
具体实施方式
现在将参考附图更全面地描述示例实施方式。然而,示例实施方式能够以多种形式实施,且不应被理解为限于在此阐述的范例;相反,提供这些实施方式使得本公开将更加全面和完整,并将示例实施方式的构思全面地传达给本领域的技术人员。所描述的特征、结构或特性可以以任何合适的方式结合在一个或更多实施方式中。
需要说明的是,本公开中,用语“包括”、“配置有”、“设置于”用以表示开放式的包括在内的意思,并且是指除了列出的要素/组成部分/等之外还可存在另外的要素/组成部分/等;用语“第一”、“第二”等仅作为标记使用,不是对其对象数量或次序的限制。
敏感数据是指涉及用户的安全和隐私的数据,包括:身份证号码、电话号码、住址、银行卡号等,涉及到医疗领域的敏感数据包含过敏药物、传染病史、饮食习惯、基因信息等。敏感数据的泄露不仅对企业自身的核心机密、同行业竞争力和市场声誉造成严重的影响,也对用户的隐私和个人信息安全造成不同程度的危害。因此,在涉及客户安全数据或者一些商业性敏感数据的情况下,可以对真实数据进行改造,例如,可以对身份证号码、手机号码、卡号、客户号等个人敏感信息进行数据脱敏。
现有的敏感数据识别方式主要包括以下三种:
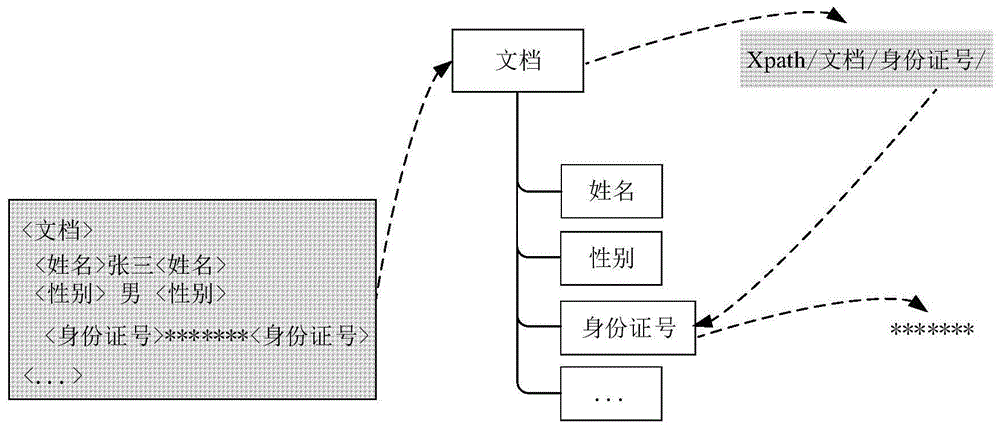
1)人工查看原始数据,并指定敏感数据所在的数据列,或指定半结构化数据中的特殊数据节点。参见图1,图1示出了通过xml(可扩展标记语言)路径语言识别和标记半结构化数据中的数据的一种示意图。xml路径语言是一种用来确定xml文档中某部分位置的语言,可以看出,通过xml路径语言可以识别出身份证号码。
2)人工提供需要脱敏的的数据的全集(白名单)以及例外名单(黑名单),扫描全部数据发现匹配的白名单数据。
3)人工根据需要脱敏的数据特征定制规则(例如,正则表达式),通过规则配置寻找敏感数据。其中,正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
可见,现有方案中提到的多种敏感数据识别的方式,均以人工的方式进行敏感数据的识别,并且,需要人工对数据本身做大量的标注工作,识别效率及准确率较低。相应地,数据脱敏的效率及准确率较低。
为了解决上述问题,本公开实施例提供了一种数据脱敏方法与装置、电子设备及计算机可读存储介质,可以提高数据脱敏的效率及准确性。
下面首先对本公开实施例所提供的数据脱敏方法进行介绍。
其中,数据的类型包括:
1.结构化数据:关系型数据库数据,excel、csv(逗号分隔值)等表格数据。
2.半结构化数据:以json(js对象简谱)、xml、html(超文本标记语言)等方式存储的数据。
3.非结构化数据:纯文本、文本扫描件、医学影像数据等。
各种敏感数据识别方式支持的数据类型可参见表1:
表1
表1中的*表示人工指定的半结构化数据对数据格式和规范有一定限制。对于非结构化数据,敏感信息无法准确的用行列编号标记,且通常与非敏感信息混合在一起,对于这种海量的信息通过人工标注几乎是不可实现的。规则匹配的方式虽然可以部分实现非结构化数据的敏感数据识别,但需要对既有的敏感数据做大量的归纳和抽象,再翻译成规则语言,这对数据处理者提出了很高的要求。
其中,医疗敏感数据并不局限于某种方式的数据,因此,医疗领域的敏感数据识别包含结构化数据、半结构化数据以及非结构化数据中以文本方式存储的数据等。
参见图2,图2示出了本公开实施例中数据脱敏方法的一种流程图,可以包括以下步骤:
步骤s210,获取待脱敏文本,并对待脱敏文本进行分词,得到多个词语和该词语的词性,根据词语的词性对词语进行过滤处理,得到待脱敏数据。
步骤s220,根据预设的独立敏感数据识别模型和部分敏感数据识别模型,对待脱敏数据中的词语进行脱敏。
通过独立敏感数据识别模型和部分敏感数据识别模型,对待脱敏数据中的词语进行脱敏,可以自动对待脱敏数据进行数据脱敏,可以减少人工成本,提高数据脱敏的效率。并且,不同敏感数据类型的词语可以建立不同的模型,即独立敏感数据识别模型和部分敏感数据识别模型,根据多个不同的模型进行数据脱敏,可以提高数据脱敏的准确性。另外,通过对待脱敏文本进行分词和过滤处理,得到待脱敏数据,可以降低计算的复杂度,提高数据脱敏的效率。
以下对本公开实施例的数据脱敏方法进行更加详细的介绍:
本公开实施例中,由于在进行数据脱敏时所使用的独立敏感数据识别模型和部分敏感数据识别模型是预先建立的,以下首先对独立敏感数据识别模型和部分敏感数据识别模型的建立方法进行介绍。
参见图3,图3示出了本公开实施例中独立敏感数据识别模型和部分敏感数据识别模型的建立方法的一种流程图,可以包括以下步骤:
步骤s310,获取经过敏感数据标记的原始数据集,根据原始数据集中标记的敏感数据构建敏感词库。
本公开实施例中,原始数据集可以是通过传统方式进行敏感数据标记的数据集,例如,可以通过标红或其他方式对原始数据集中的敏感数据标记,得到敏感数据。文本数据按照包含信息的粒度可以分为长文本、句子、词语等,其中,词语是表示语义的最小单位,标记的敏感数据可以是长文本、句子、词语等。
在本公开的一示例性实施例中,可以对原始数据集中标记的敏感数据进行分词处理,得到多个词语。由于得到的多个词语中可能存在非敏感词语,在此,可以对多个词语进行过滤处理,将过滤后的词语的集合作为敏感词库。
可选的,可以对多个词语中的每个词语进行词性标注,得到每个词语的词性。例如,可以通过语言分析工具对词语进行词性标注。其中,汉语的词性可以分为12个类别:
1)名词:表示人和事物名称的词。
2)动词:表示人和事物动作、行为、发展、变化。
3)形容词:表示事物的形状、性质、颜色、状态等属性信息。
4)副词:修饰和限制动词,表示时间、频率、范围、程度、语气等。
5)代词:代替不确定的人或事物的词和短语;如你、我、他、谁等。
6)介词:与其他词一起构成介词短语。
7)量词:表示事物或动作单位的词。
8)连词:连接词和句子的词。
9)助词:附加在词或句子起辅助作用的词,如:的、地、得等。
10)数词:表示数字的词。
11)叹词:表示情感、感叹、呼唤、应答的词。
12)拟声词:表示声音的词。
其中,名词是包含敏感信息最多的词,因此,可以将名词细分为:专用名词、人名、地名、机构名等;通过相关规则可以更细致的分析出名词中的电话、身份证号码、地址等敏感信息。而对于形容词、副词、代词、介词、叹词、拟声词等通常不包含敏感信息,因此,可以根据多个词语的词性对多个词语进行过滤处理。具体的,可以将多个词语中词性为形容词、副词、代词、介词、叹词、拟声词等不可能包含敏感信息的词语过滤掉,从而得到敏感词库。当然,本公开也可以通过其他方法进行过滤,在此并不以此为限。
步骤s320,按照预设规则对敏感词库中的词语进行分类,确定敏感词库中每个词语所属的敏感数据类型。
其中,词语可以包括:非敏感词语(即与敏感数据无关的词语)和敏感词语,敏感词语包括:独立敏感数据类型的词语和部分敏感数据类型的词语,独立敏感数据类型的词语指词语无需其他词语修饰即是敏感数据,例如,电话号码、身份证号码、家庭住址等。部分敏感数据类型的词语指词语需要与其他词语一起组成组合词语或短句才是敏感数据,例如,李某在某建设兵团服役期间曾患某种疾病,有的脱敏需求是对国家保密单位出现的特殊病史进行脱敏,但如果患者不涉及到国家保密单位,则这些信息是不需要脱敏的。
本公开实施例中,预设规则可以包含多种规则,例如,针对身份证号码的规则,可以将连续18个数字,且第7~10位在1900~2019范围内的数字识别为独立敏感数据类型。针对地址的规则,可以是如果判断地址为具体的家庭住址,则识别为独立敏感数据类型。对于某些部分敏感数据类型的词语,可以直接根据预先建立的数据库进行识别,如果匹配到,则确定为部分敏感数据类型。
需要说明的是,对于敏感词库中的部分词语,按照预设规则可能是不能识别的。在此,还可以为用户提供界面,通过交互的形式,将无法识别的词语通过人工方式进行识别,从而确定每个词语所属的敏感数据类型。
本公开实施例中,对于独立敏感数据类型的词语,可以直接根据该词语进行脱敏。而对于部分敏感数据类型的词语,是不能通过独立的词语来脱敏的,可以根据该词语与上下文词语之间的关系进行脱敏。因此,为了提高数据脱敏的准确性,可以根据不同敏感数据类型的词语,建立多个不同的模型,并通过多个不同的模型进行数据脱敏。下述步骤s330~步骤340为根据独立敏感数据类型的词语建立独立敏感数据识别模型的过程,步骤s350~步骤s380为根据部分敏感数据类型的词语建立部分敏感数据识别模型的过程。
步骤s330,针对独立敏感数据类型的每个词语,将该词语及该词语的属性信息转换为对应的属性向量。
本公开实施例中,词语的属性信息包括:词频、词性、上下文词语、与上下文词语之间的依存关系等。词频也就是该词语出现的频率,词性指前述的名词、形容词等,上下文词语指的是和该词语在相同句子中的其他词语,可以是相邻的词语,也可以不是相邻的词语。依存关系是句子的句法结构或者句子中词汇之间的依存关系,词语之间的依存关系可参见表2。
表2
其中,词语与上下文词语之间的依存关系可以通过语言分析工具确定。例如,若某一句子为:王**孕12周就诊我院超声提示宫内妊娠,通过语言分析工具得到的各词语和上下文词语之间的依存关系可参见图4。
需要说明的是,对于词性、依存关系等非数值的属性信息,可以通过数值进行量化,之后,再根据量化结果将属性信息转换为属性向量。例如,主谓关系可以表示为1,动宾关系可以表示为2,间宾关系可以表示为3,依次类推。对于词语本身,可以通过word2vec转换为对应的词向量。可见,最终得到的属性向量是由多个向量构成的向量,并且,对于不同的词语,对应的属性向量不同。
步骤s340,根据独立敏感数据类型的词语对应的属性向量及预先设置的属性值,通过逻辑回归算法建立独立敏感数据识别模型。
需要说明的是,独立敏感数据类型和部分敏感数据类型对应的属性值可以是预先设定的值,例如,可以分别是1和0。当然,也可以是其他值,在此不做限定。这样,对于敏感词库中属于独立敏感数据类型的每个词语,可以得到该词语对应的属性向量和属性值。在此,不同词语的属性值是相同的,从而可以建立各属性向量和属性值之间的对应关系,并根据该对应关系,通过逻辑回归算法建立独立敏感数据识别模型。
本公开实施例中,可以通过k折交叉验证的方式将数据集a(即各属性向量和属性值之间的对应关系)随机分为k个包,每次将其中一个包作为测试集,剩下k-1个包作为训练集进行训练。也就是,取其中的k-1个包进行逻辑回归运算。其中,逻辑回归运算可以是logistic回归或其他回归方法,logistic回归是一种广义的线性回归分析模型,常用于数据挖掘,疾病自动诊断,经济预测等领域。例如,探讨引发疾病的危险因素,并根据危险因素预测疾病发生的概率等。
logistic回归与多重线性回归分析有很多相同之处,它们的模型形式基本上相同,都具有w′x+b,其中w和b是待求参数,其区别在于它们的因变量不同,多重线性回归直接将w‘x+b作为因变量,即y=w′x+b,而logistic回归则通过函数l将w′x+b对应一个隐状态p,p=l(w′x+b),然后根据p与1-p的大小决定因变量的值。如果l是logistic函数,就是logistic回归,如果l是多项式函数就是多项式回归。
步骤s350,针对部分敏感数据类型的每个词语,确定该词语在原始数据集中对应的目标敏感数据。
本公开实施例中,由于部分敏感数据类型的词语需要和其他词语一起组成组合词语或短句才是敏感数据,因此,针对部分敏感数据类型的每个词语,可以确定该词语在原始数据集中对应的目标敏感数据,根据该词语与目标敏感数据中其他词语之间的依存关系,确定部分敏感数据识别模型。其中,词语对应的目标敏感数据指的是该词语所在的句子或段落等,根据目标敏感数据可以分析该词语与其他词语之间的依存关系,并根据该依存关系,确定部分敏感数据识别模型。
步骤s360,获取与该词语相似度大于相似度阈值的相似词语,将目标敏感数据中的该词语替换为相似词语,得到更新的数据。
通常情况下,各领域(例如医疗领域等)的数据文档属于严谨的文本数据,虽然存储的格式多样,但针对绝大多数据文档都有相关的标准可供参考。因此,大部分的文档数据的格式和内容顺序是收敛的。也就是说,在书写规范确定的情况下,虽然数据是自由文本书写,但描述同样分类内容的数据依存结构相似。相同的依存结构中如果套用的是近似或类似的词语,那么这个短语描述的信息可以是近似的。
基于该原理,可以将目标敏感数据中的词语进行近义词替换,得到更新的数据。目前可以通过很多相关工具分析词语的相关性,例如,word2vec可以将词语向量化,这样词语与词语之间就可以定量的度量它们之间的关系,挖掘词语之间的联系。通过整理所有被标记为敏感数据的数据,分析依存结构s和其组成的词w,保持依存结构s不变,不断替换敏感数据中与w密切相关的词语w’,即可得到更新的数据,通常更新的数据是敏感数据的概率较高。
步骤s370,在原始数据集中检索不到更新的数据时,获取用户针对更新的数据输入的敏感数据识别结果。
具体的,可以在原始数据集中检索更新的数据,如果检索到更新的数据,可以直接根据敏感数据标记结果,确定更新的数据是否是敏感数据。如果没有检索到更新的数据,可以为用户提供界面,以人工的方式进行识别,也就是以人工方式进行标注,得到敏感数据识别结果。
步骤s380,将更新的数据及敏感数据识别结果添加至原始数据集中,将更新后的原始数据集作为部分敏感数据识别模型。
本公开实施例中,敏感数据识别结果包括:是敏感数据和不是敏感数据,不论更新的数据是否是敏感数据,都可以将更新的数据及对应的敏感数据识别结果添加至原始数据集中,使原始数据集中的数据得到扩充,得到部分敏感数据识别模型。可见,部分敏感数据识别模型是一个经过敏感数据标记的数据集。部分敏感数据识别模型中的数据越多,越能准确快速地进行敏感数据的识别。
至此,建立了独立敏感数据识别模型和部分敏感数据识别模型,下面是根据独立敏感数据识别模型和部分敏感数据识别模型进行数据脱敏的具体方法。
在步骤s210中,获取待脱敏文本,并对待脱敏文本进行分词,得到多个词语和该词语的词性,根据词语的词性对词语进行过滤处理,得到待脱敏数据。
本公开实施例中,待脱敏文本是有脱敏需求的文本,待脱敏文本中通常包含敏感数据。待脱敏文本可以是word文档、txt文档等,由于本步骤的处理过程与步骤s310相同,在此不再详述。通过对待脱敏文本进行分词及过滤,得到待脱敏数据,可以降低计算的复杂度,提高脱敏效率。
在步骤s220中,根据预设的独立敏感数据识别模型和部分敏感数据识别模型,对待脱敏数据中的词语进行脱敏。
具体的,由于数据识别模型包括:独立敏感数据识别模型和部分敏感数据识别模型,在此可以通过并行的方式进行脱敏,也就是,分别通过独立敏感数据识别模型和部分敏感数据识别模型进行脱敏。在本公开的一种示例性实施例中,还可以先通过独立敏感数据识别模型对每个词语进行识别,如果该词语属于独立敏感数据类型,可以对该词语进行脱敏。之后,再通过部分敏感数据识别模型对剩余的每个词语进行识别。这样,可以避免重复计算,提高识别效率。
其中,通过独立敏感数据识别模型对待脱敏数据中的词语进行脱敏的方法,可以参见图5,包括以下步骤:
步骤s510,针对待脱敏数据中的每个词语,将该词语及该词语的属性信息转换为对应的属性向量。
由于本步骤的处理过程与步骤s330相同,在此不再详述。
步骤s520,通过独立敏感数据识别模型对属性向量进行处理,得到属性向量对应的属性值。
具体的,在建立独立敏感数据识别模型之后,得到了独立敏感数据识别模型中的参数值。那么,通过独立敏感数据识别模型对属性向量进行处理,也就是将属性向量代入独立敏感数据识别模型中,即可得到属性向量对应的属性值。
步骤s530,根据属性值确定该词语是否是独立敏感数据,并在确定该词语是独立敏感数据时,对该词语进行脱敏。
本公开实施例中,如果得到的属性值接近于独立敏感数据类型对应属性值,则可以认为该词语属于独立敏感数据类型,并对该词语进行脱敏。例如,在独立敏感数据类型和部分敏感数据类型的属性值分别为1和0时,如果属性值接近于1,例如0.95,那么,可以认为该词语是独立敏感数据类型。
之后,可以通过部分敏感数据识别模型继续进行判断,通过部分敏感数据识别模型对待脱敏数据中的词语进行脱敏的方法,可以参见图6,包括以下步骤:
步骤s610,针对待脱敏数据中的每个词语,在部分敏感数据识别模型中对该词语进行检索。
具体的,可以在部分敏感数据识别模型中对该词语与该词语的上下文词组成的组合词语或短句进行检索,如果检索到,可以直接判断是否为敏感数据。如果没有检索到,还可以为用户提供的界面,借助人工的方式进行识别。
步骤s620,在检索到该词语时,判断该词语是否是敏感数据。
在检索到该词语时,部分敏感数据识别模型中包含该词语对应的标记结果,可以直接根据该标记结果确定该词语是否是敏感数据。
步骤s630,在该词语是敏感数据时,对该词语进行脱敏。
在识别出敏感数据之后,可以对敏感数据进行脱敏。脱敏方法包括:数字摘要、字符掩码(例如电话号码,可以用1*****替换)、部分脱敏(只脱敏关键部分,例如,脱敏后的地址为北京市xxxxxxx)等。其中,数字摘要就是采用单向hash函数将需要加密的明文“摘要”成一串固定长度(128位)的密文,而且不同的明文摘要成密文,其结果总是不同的,而同样的明文其摘要必定一致。
另外,在该词语不是敏感数据时,可以不做处理,也就是对该词语的处理流程结束。
在本公开的一种示例性实施例中,数据脱敏的方法还可以参见图7,包括以下步骤:
步骤s710,确定待脱敏数据中每一词语的敏感数据类型。
本公开实施例中,待脱敏数据中每一词语的敏感数据类型可以通过该词语的属性确定。例如,预先定义好哪些数据是需要全部脱敏的,这部分数据为独立敏感数据。预先定义好哪些数据是需要与其他数据相结合才需要脱敏的,这部分数据为部分敏感数据。之后,分别根据词语的敏感数据类型,选取对应的模型进行脱敏。
步骤s720,将属于独立敏感数据类型的词语通过预设的独立敏感数据识别模型进行脱敏。
步骤s730,将属于部分敏感数据类型的词语通过预设的部分敏感数据识别模型进行脱敏。
需要说明的是,步骤s720和步骤s730的具体脱敏方法已经在前文中进行了详细描述,在此不再赘述。
在本公开的一种示例性实施例中,还可以获取新的数据集,对独立敏感数据识别模型进行更新,以提高独立敏感数据识别模型的准确率。可参见图8,包括以下步骤:
步骤s810,获取经过敏感数据标记的训练数据集,从训练数据集的敏感数据中选取敏感数据类型为独立敏感数据类型的第一目标训练词语。
本公开实施例中,训练数据集与前述的原始数据集类似,均是经过敏感数据标记的数据集。类似地,可以对训练数据集中的敏感数据进行分词处理,并通过过滤得到训练数据集对应的敏感词库。由于独立敏感数据识别模型是针对独立敏感数据类型的模型,因此,对训练数据集对应的敏感词库中的词语进行分类之后,可以选取敏感数据类型为独立敏感数据类型的第一目标训练词语。也就是,通过第一目标训练词语对独立敏感数据识别模型型进行更新。
步骤s820,通过独立敏感数据识别模型对第一目标训练词语进行识别,得到预测值。
本公开实施例中,独立敏感数据识别模型对第一目标训练词语识别的方法具体可以为:将第一目标训练词语按照前述方法转换为对应的属性向量,并将该属性向量代入独立敏感数据识别模型,从而可以得到预测值。通常情况下,预测值与实际值之间是存在偏差的,偏差越小,表示独立敏感数据识别模型的准确性越高;偏差越大,表示独立敏感数据识别模型的准确性越低。因此,独立敏感数据识别模型对第一目标训练词语识别的过程,可以验证独立敏感数据识别模型的准确性。
步骤s830,选取与独立敏感数据类型对应的属性值的差值小于差值阈值的预测值;根据所选取的预测值对应的第二目标训练词语对独立敏感数据识别模型进行更新。
可以理解的是,第一目标训练词语是经过标记的词语,第一目标训练词语对应的属性值也就是独立敏感数据类型对应属性值。将预测值和实际的属性值进行比较,如果差值小于差值阈值,则表示独立敏感数据识别模型对第一目标训练词语识别的准确率较高,即第一目标训练词语可以通过独立敏感数据识别模型识别。相应地,可以通过该第一目标训练词语进行更新,以完善独立敏感数据识别模型,提高独立敏感数据识别模型的准确率。否则,表示第一目标训练词语不适合通过独立敏感数据识别模型进行识别。其中,预测值与属性值的差值指的是差值的绝对值,差值阈值可以是根据经验设置的值,例如,可以是0.1、0.05等,在此不做限定。
本公开实施例中,可以将第一目标训练词语中对应的预测值与独立敏感数据类型对应属性值的差值小于差值阈值的词语作为第二目标训练词语,通过第二目标训练词语对独立敏感数据识别模型进行更新。具体方法可以是:将第二目标训练词语按照前述方法转换为对应的属性向量,根据该属性向量以及属性值对独立敏感数据识别模型中的参数值进行调整,以进一步优化独立敏感数据识别模型,提高独立敏感数据识别模型的准确性。当然,第二目标训练词语越多,更新后的独立敏感数据识别模型的准确率越高。需要说明的是,之后,还可以通过不断获取新的训练数据集,来不断更新独立敏感数据识别模型。随着数据集的积累,可以不断提高独立敏感数据识别模型的准确性。
本公开实施例的数据脱敏方法中,根据经过敏感数据标记的原始数据集,分别建立独立敏感数据识别模型和部分敏感数据识别模型,通过独立敏感数据识别模型和部分敏感数据识别模型可以自动对待脱敏数据进行数据脱敏,可以减少人工成本,提高脱敏的效率及准确性。并且,还可以通过数据的积累对独立敏感数据识别模型和部分敏感数据识别模型进行更新,以提高独立敏感数据识别模型和部分敏感数据识别模型进行数据脱敏的准确性。并且,独立敏感数据识别模型本身已经对词语进行了向量化,因此,无需担心独立敏感数据识别模型型会泄漏隐私数据。
应当注意,尽管在附图中以特定顺序描述了本公开中方法的各个步骤,但是,这并非要求或者暗示必须按照该特定顺序来执行这些步骤,或是必须执行全部所示的步骤才能实现期望的结果。附加的或备选的,可以省略某些步骤,将多个步骤合并为一个步骤执行,以及/或者将一个步骤分解为多个步骤执行等。
进一步的,本示例实施方式中,还提供了一种数据脱敏装置900,参见图9,图9示出了本公开实施例中数据脱敏装置的一种结构示意图,包括:
预处理模块910,用于获取待脱敏文本,并对待脱敏文本进行分词,得到多个词语和该词语的词性,根据词语的词性对词语进行过滤处理,得到待脱敏数据;
脱敏模块920,用于根据预设的独立敏感数据识别模型和部分敏感数据识别模型,对待脱敏数据中的词语进行脱敏。
可选的,脱敏模块,包括:第一脱敏子模块,第一脱敏子模块包括:
向量转换单元,用于针对待脱敏数据中的每个词语,将该词语及该词语的属性信息转换为对应的属性向量;
属性值确定单元,用于通过独立敏感数据识别模型对属性向量进行处理,得到属性向量对应的属性值;
独立敏感数据脱敏单元,用于根据属性值确定该词语是否是独立敏感数据,并在确定该词语是独立敏感数据时,对该词语进行脱敏。
可选的,本公开实施例的数据脱敏装置,还包括:
敏感词库构建模块,用于获取经过敏感数据标记的原始数据集,根据原始数据集中标记的敏感数据构建敏感词库;
敏感数据类型确定模块,用于按照预设规则对敏感词库中的词语进行分类,确定敏感词库中每个词语所属的敏感数据类型;
属性向量确定模块,用于针对独立敏感数据类型的每个词语,将该词语及该词语的属性信息转换为对应的属性向量;
独立敏感数据识别模型建立模块,用于根据独立敏感数据类型的词语对应的属性向量及预先设置的属性值,通过逻辑回归算法建立独立敏感数据识别模型。
可选的,本公开实施例的数据脱敏装置,还包括:
目标敏感数据确定模块,用于针对部分敏感数据类型的每个词语,确定该词语在原始数据集中对应的目标敏感数据;
相似词语替换模块,用于获取与该词语相似度大于相似度阈值的相似词语,将目标敏感数据中的该词语替换为相似词语,得到更新的数据;
识别结果获取模块,用于在原始数据集中检索不到更新的数据时,获取用户针对更新的数据输入的敏感数据识别结果;
部分敏感数据识别模型建立模块,用于将更新的数据及敏感数据识别结果添加至原始数据集中,将更新后的原始数据集作为部分敏感数据识别模型。
可选的,脱敏模块,包括:第二脱敏子模块,第二脱敏子模块包括:
检索单元,用于针对待脱敏数据中的每个词语,在部分敏感数据识别模型中对该词语进行检索;
敏感数据判断单元,用于在检索到该词语时,判断该词语是否是敏感数据;
敏感数据脱敏单元,用于在该词语是敏感数据时,对该词语进行脱敏。
可选的,脱敏模块,具体用于确定待脱敏数据中每一词语的敏感数据类型;将属于独立敏感数据类型的词语通过预设的独立敏感数据识别模型进行脱敏;将属于部分敏感数据类型的词语通过预设的部分敏感数据识别模型进行脱敏。
可选的,本公开实施例的数据脱敏装置,还包括:
模型更新模块,用于获取经过敏感数据标记的训练数据集,从训练数据集的敏感数据中选取敏感数据类型为独立敏感数据类型的第一目标训练词语;通过独立敏感数据识别模型对第一目标训练词语进行识别,得到预测值;选取与独立敏感数据类型对应的属性值的差值小于差值阈值的预测值;根据所选取的预测值对应的第二目标训练词语对独立敏感数据识别模型进行更新。
上述装置中各模块/单元的具体细节在方法部分的实施例中已经详细说明,因此不再赘述。
应当注意,尽管在上文详细描述中提及了用于动作执行的设备的若干模块或者单元,但是这种划分并非强制性的。实际上,根据本公开的实施方式,上文描述的两个或更多模块或者单元的特征和功能可以在一个模块或者单元中具体化。反之,上文描述的一个模块或者单元的特征和功能可以进一步划分为由多个模块或者单元来具体化。
在本公开的示例性实施例中,还提供一种电子设备,包括:处理器;用于存储处理器可执行指令的存储器;其中,所述处理器被配置为执行本示例实施方式中任一所述的方法。
图10示出了用于实现本公开实施例的电子设备的计算机系统的结构示意图。需要说明的是,图10示出的电子设备的计算机系统1000仅是一个示例,不应对本公开实施例的功能和使用范围带来任何限制。
如图10所示,计算机系统1000包括中央处理单元1001,其可以根据存储在只读存储器1002中的程序或者从存储部分1008加载到随机访问存储器1003中的程序而执行各种适当的动作和处理。在随机访问存储器1003中,还存储有系统操作所需的各种程序和数据。中央处理单元1001、只读存储器1002以及随机访问存储器1003通过总线1004彼此相连。输入/输出接口1005也连接至总线1004。
以下部件连接至输入/输出接口1005:包括键盘、鼠标等的输入部分1006;包括诸如阴极射线管(crt)、液晶显示器(lcd)等以及扬声器等的输出部分1007;包括硬盘等的存储部分1008;以及包括诸如局域网(lan)卡、调制解调器等的网络接口卡的通信部分1009。通信部分1009经由诸如因特网的网络执行通信处理。驱动器1010也根据需要连接至输入/输出接口1005。可拆卸介质1011,诸如磁盘、光盘、磁光盘、半导体存储器等等,根据需要安装在驱动器1010上,以便于从其上读出的计算机程序根据需要被安装入存储部分1008。
特别地,根据本公开的实施例,上文参考流程图描述的过程可以被实现为计算机软件程序。例如,本公开的实施例包括一种计算机程序产品,其包括承载在计算机可读介质上的计算机程序,该计算机程序包含用于执行流程图所示的方法的程序代码。在这样的实施例中,该计算机程序可以通过通信部分1009从网络上被下载和安装,和/或从可拆卸介质1011被安装。在该计算机程序被中央处理单元1001执行时,执行本申请的装置中限定的各种功能。
在本公开的示例性实施例中,还提供一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现上述任意一项所述的方法。
需要说明的是,本公开所示的计算机可读存储介质例如可以是—但不限于—电、磁、光、电磁、红外线、或半导体的系统、装置或器件,或者任意以上的组合。计算机可读存储介质的更具体的例子可以包括但不限于:具有一个或多个导线的电连接、便携式计算机磁盘、硬盘、随机访问存储器、只读存储器、可擦式可编程只读存储器(eprom或闪存)、光纤、便携式紧凑磁盘只读存储器(cd-rom)、光存储器件、磁存储器件、或者上述的任意合适的组合。在本公开中,计算机可读存储介质可以是任何包含或存储程序的有形介质,该程序可以被指令执行系统、装置或者器件使用或者与其结合使用。而在本公开中,计算机可读的信号介质可以包括在基带中或者作为载波一部分传播的数据信号,其中承载了计算机可读的程序代码。这种传播的数据信号可以采用多种形式,包括但不限于电磁信号、光信号或上述的任意合适的组合。计算机可读的信号介质还可以是计算机可读存储介质以外的任何计算机可读介质,该计算机可读介质可以发送、传播或者传输用于由指令执行系统、装置或者器件使用或者与其结合使用的程序。计算机可读介质上包含的程序代码可以用任何适当的介质传输,包括但不限于:无线、电线、光缆、射频等等,或者上述的任意合适的组合。
本领域技术人员在考虑说明书及实践这里公开的发明后,将容易想到本公开的其他实施例。本申请旨在涵盖本公开的任何变型、用途或者适应性变化,这些变型、用途或者适应性变化遵循本公开的一般性原理并包括本公开未公开的本技术领域中的公知常识或惯用技术手段。说明书和实施例仅被视为示例性的,本公开的真正范围和精神由权利要求指出。
应当理解的是,本公开并不局限于上面已经描述并在附图中示出的精确结构,并且可以在不脱离其范围进行各种修改和改变。本公开的范围仅由所附的权利要求来限。
- 还没有人留言评论。精彩留言会获得点赞!