卷积电路的制作方法
本实用新型涉及卷积运算领域,尤其涉及一种卷积电路。
背景技术:
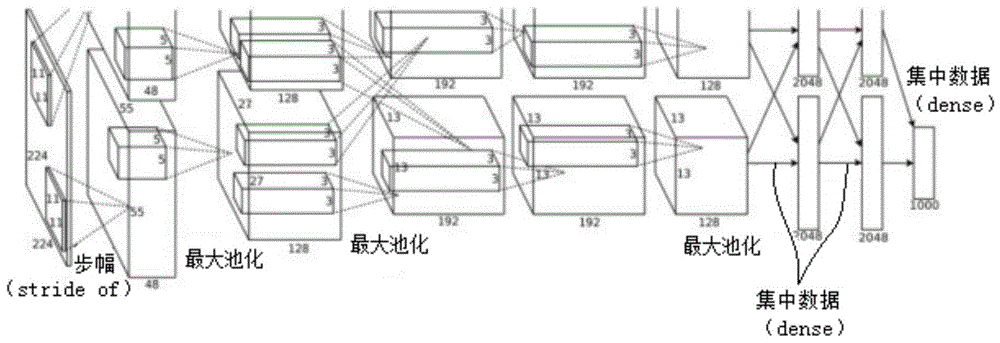
近几年,卷积神经网络(convolutionalneuralnetwork,cnn)在深度学习中取得了重大的进展。alexkrizhevsky等人2012年提出了经典的cnn计算结构alexnet,在图像分类和识别中获得了巨大成功。alexnet的输入为一个3通道的227×227图片数据,如图1所示,其整个处理过程总共包括8层运算,前五层为卷积层,后三层为全连接层,其中第一层卷积采用3×11×11宽度的卷积核,卷积核个数为96,第二层卷积采用96×5×5宽度的卷积核,卷积核个数为256,余下三层卷积都采用不同通道数的3×3宽度卷积核。alexnet的总参数量超过了8mb,并且单通道卷积核大小不一致,运算复杂。之后,研究人员又提出了其他的更为完善和优化的方法,其中最著名结构有zfnet[2013年],vggnet[2014年],resnet[2015],googlenet[2015年]和squeezenet(压缩卷积神经网络)[2016年]等,它们从性能和资源使用率等不同的方面进行优化,不同的cnn结构具有不同的卷积层数、通道维度、卷积核大小、以及每一层卷积核个数等。通常,cnn网络运算包括:卷积运算、pooling池化运算和fc全连接运算。
卷积运算是cnn计算结构中最为关键的运算,其运算量占据整个网络的90%以上。卷积运算又按不同的卷积尺寸进行划分,常用的卷积核包括1×1的卷积核、3×3的卷积核、5×5的卷积核心和7×7的卷积核。目前主流的卷积神经网络大尺寸的卷积核心比较少,最常用的卷积尺寸为3×3和5×5。
卷积神经网络最初输入的数据为图像数据,中间经过多层卷积运算。每一层卷积计算输出数据称为卷积特征图featuremap数据。上层的卷积特征图featuremap数据作为下一层卷积运算的输入参与卷积运算。最后一层的计算结果为该卷积神经网络的最终结果。
如图2所示,卷积运算是一个三维立体的运算过程。卷积运算包括卷积数据和卷积参数输入。卷积图像数据和卷积参数都是三维结构。运算是卷积核从输入图像的左上角开始,向右逐层滑动,每滑动一次,卷积核与其覆盖的输入数据进行点积并求和运算,得到输出一个卷积特征图featuremap上的一个数据。如果有n个卷积核,那么输出卷积特征图featuremap数据个数也为n。
其中,卷积运算公式为:
通过切分的方式,可将三维的卷积运算转换成多次的二维卷积运算,如图3所示,卷积运算相当于卷积核在二维的卷积特征图featuremap上从左至右,从上至下的划窗操作,窗口内的数据与卷积核进行乘累加操作。如此,可将三维的多通道卷积运算拆分成多个如图3所示的单通道卷积运算。
针对二维划窗操作,可通过移位寄存器链实现卷积运算,传统的卷积数据寄存器链采用的是通用寄存器,如果卷积数据寄存器链的长度太大,则会消耗更多的寄存器资源,特别是对于输入的卷积数据个数nin很大而无法进行卷积运算的情形,会消耗过多的寄存器资源,导致硬件资源开销更大,从而对硬件资源提出了很高的要求。
技术实现要素:
本实用新型的目的在于提供一种卷积电路,以解决现有技术中通过采用通用寄存器的移位寄存器链实现卷积运算而导致硬件资源开销较大的问题。
为实现上述目的,本实用新型是这样实现的:
本实用新型提供一种卷积电路,其包括:
移位卷积数据链,用于响应于输入的运算模式控制指令,向卷积运算器输入目标卷积数据,所述移位卷积数据链为第一fifo队列,所述fifo队列存储有所述目标卷积数据;
卷积参数存储器,用于向所述卷积运算器输入卷积参数;
卷积运算器,用于基于所述目标卷积数据和所述卷积参数数据,生成卷积结果数据;
其中,所述卷积运算器包括池化运算器,用于对所述卷积结果数据进行池化运算,以得到目标卷积结果,所述池化运算器包括第二fifo队列。
本实用新型实施例的卷积电路通过采用先入先出fifo队列的移位卷积数据链存储卷积数据,以在卷积运算时,通过fifo队列输出目标卷积数据,从而使卷积运算器根据接收的目标卷积数据和卷积参数执行卷积运算。由于fifo队列一般是基于易失性存储介质实现,由此,移位卷积数据链中的目标卷积数据不占用寄存器资源,因此,可以节约寄存器资源,从而降低硬件资源开销,解决了现有技术中通过采用通用寄存器的移位寄存器链实现卷积运算而导致硬件资源开销较大的问题。
附图说明
图1为alexnet的示意性结构图;
图2为三维卷积运算的示意性原理图;
图3为二维卷积运算的示意性原理图;
图4为根据本实用新型一个实施例的卷积电路的示意性结构图;
图5为图4的卷积电路中池化运算器的示意性结构图;
图6为图4的卷积电路中的移位卷积数据链的示意性结构原理图;
图7为根据本实用新型一个实施例的卷积电路中移位卷积数据链与卷积运算器的示意性连接结构图;
图8为根据本实用新型另一个实施例的卷积电路中移位卷积数据链与卷积运算器的示意性连接结构图;
图9为根据本实用新型再一个实施例的卷积电路中移位卷积数据链与卷积运算器的示意性连接结构图;
图10为根据本实用新型再一个实施例的卷积电路中移位卷积数据链与卷积运算器的示意性连接结构图;
图11为根据本实用新型一个实施例的卷积运算器的示意性结构图;
图12为根据本实用新型另一个实施例的卷积运算器的示意性结构原理图;
图13为根据本实用新型一个实施例的卷积电路与控制终端的示意性连接结构图;
图14为根据本实用新型另一个实施例的卷积电路的示意性结构图。
具体实施方式
下面结合附图所示的各实施方式对本实用新型进行详细说明,但应当说明的是,这些实施方式并非对本实用新型的限制,本领域普通技术人员根据这些实施方式所作的功能、方法、或者结构上的等效变换或替代,均属于本实用新型的保护范围之内。
以下结合附图,详细说明本实用新型各实施例提供的技术方案。
图4是根据本实用新型一个实施例的卷积电路400的示意性结构图,以解决现有技术中通过采用通用寄存器的移位寄存器链实现卷积运算而导致硬件资源开销较大的问题。本实用新型实施例的卷积电路400包括:移位卷积数据链500,用于响应于输入的运算模式控制指令,向卷积运算器700输入目标卷积数据,移位卷积数据链500为第一fifo队列,fifo队列存储有目标卷积数据;卷积参数存储器600,用于向卷积运算器输入卷积参数;卷积运算器700,用于基于目标卷积数据和卷积参数数据,生成卷积结果数据;其中,卷积运算器700包括池化运算器,用于对卷积结果数据进行池化运算,以得到目标卷积结果,池化运算器包括第二fifo队列。
本实用新型实施例的卷积电路通过采用先入先出fifo队列的移位卷积数据链存储卷积数据,以在卷积运算时,通过fifo队列输出目标卷积数据,从而使卷积运算器根据接收的目标卷积数据和卷积参数执行卷积运算。由于fifo队列一般是基于易失性存储介质实现,由此,移位卷积数据链中的目标卷积数据不占用寄存器资源,因此,可以节约寄存器资源,从而降低硬件资源开销,解决了现有技术中通过采用通用寄存器的移位寄存器链实现卷积运算而导致硬件资源开销较大的问题。
其中,对于卷积运算器中的池化运算器来讲,以i=3,m=4为例,若上述实施例的卷积电路为构建3×3(j=3)的卷积运算电路,则在生成4组卷积结果数据后,4组3×3卷积运算结果为池化运算器的输入数据;若上述实施例的卷积电路为构建5×5(j=5)的卷积运算电路,则在生成4组卷积结果数据后,1组5×5卷积运算结果为池化运算器的输入数据。
需要说明的是,如图5所示,池化运算器内部可以包括多个(假设4个)基于第二fifo队列的移位数据链,以及一组(共25*4)个数据寄存器和一组控制参数。池化运算器运算时,移位数据链以串行方式或并行方式连接,形成移位数据链。基于控制参数输入数据运算时,从而输入端(即图5中的行54)逐拍输入移位数据链,该移位数据链则根据输入端所输入数据逐拍输出5组数据。当mode_sel(卷积运算模式控制指令)指示3×3卷积运算模式时,从5组数据中,选择连续3组(可1~3,或2~4或3~5)共9个数据进行池化运算,可以配置成max运算或min运算等,移位数据链逐拍输出过程中,同时完成池化运算,并将输出池化后的结果作为3×3的目标卷积结果(即图5中的3×3pooling4d输出)。当mode_sel指示5×5模式运算时,对5组数据中共25个数据进行池化运算,可以是max运算或min运算等,移位数据链逐拍输出过程中,同时完成池化运算,并将输出池化运算后的结果作为5×5的目标卷积结果(即图5中的3×3pooling1d输出)。
可见,第二fifo队列的数量为j-1,其中,目标卷积运算模式对应的卷积运算的最大卷积尺寸为j×j,目标卷积运算模式基于输入的运算模式控制指令进行确定。
在上述实施例中,第一fifo队列的数量为j-1,其中,目标卷积运算模式对应的卷积运算的最大卷积尺寸为j×j,所述目标卷积运算模式基于输入的运算模式控制指令进行确定。
可以理解的是,移位卷积数据链可以由多个第一fifo队列构成,即在根据输入的运算模式控制指令确定目标卷积模式后,按照目标卷积模式对应的卷积尺寸选择多个第一fifo队列中的几个(或者所有第一fifo队列)向卷积运算器输入目标卷积数据。一般,若第一fifo队列的数量大于目标卷积尺寸j×j,则会从第一fifo队列中选择与目标卷积尺寸相同的j个第一fifo队列输出的数据至卷积运算器,以使卷积运算器根据j个第一fifo队列输出的卷积数据以及卷积参数存储输出的卷积参数生成卷积结果数据,从而完成目标尺寸的卷积运算。由于fifo队列一般是基于易失性存储介质实现,由此,移位卷积数据链中的目标卷积数据不占用寄存器资源,以降低硬件资源开销。
如图6所示,以移位卷积数据链内部为4个fifo队列为例,多条数据链以串行方式或并联方式连接,形成移位卷积数据链,由此,该移位卷积数据链最多可输出5组卷积数据至卷积运算器,即,可支持最大卷积尺寸为5×5的卷积运算。具体而言,在接收到运算模式控制指令后,若卷积运算模式对应的卷积尺寸为3×3,则卷积运算器只接收移位卷积数据链中的其中3组卷积数据,以在卷积运算器执行相应的卷积运算;若卷积运算模式对应的卷积尺寸为5×5,则卷积运算器接收移位卷积数据链的所有组(即5组)卷积数据,从而完成目标尺寸的卷积运算。由于fifo队列一般是基于易失性存储介质实现,由此,移位卷积数据链中的目标卷积数据不占用寄存器资源,以降低硬件资源开销。
一般,传统卷积运算系统通过复制多个单独的卷积运算单元(包括不同尺寸的卷积核),并行执行卷积运算,由此,在进行卷积运算时,每个卷积运算单元需要加载同一组输入卷积特征图featuremap数据,从而会导致输入数据带宽瓶颈或数据重复输入,而降低整个系统的运行效率,此外,该传统卷积运算系统会受限于内部的移位寄存器资源,通过复制多个卷积运算单元完成卷积运算会受到寄存器资源的限制。
为了解决上述技术问题,本实用新型实施例的卷积电路400可包括多个卷积运算器700,多个卷积运算器700与移位卷积数据链500之间的连接方式,如图7所示,多个卷积运算器700之间首尾相连,且移位卷积数据链500与位于首端的卷积运算器700通信连接。
或者,如图8所示,多个卷积运算器700的输入端相并联,且移位卷积数据链500与多个卷积运算器700相并连接的输入端相连。
又或者,如图9或图10所示,多个卷积运算器700之间相混连,即,多个卷积运算器700之间有相互串联,也有相互并联,但是,移位卷积数据链500与呈混连结构的卷积运算器700的输入端相连,即将混连结构的卷积运算器作为整体,将该整体结构的输入端与移位卷积数据链500相连。
由此可见,本实用新型实施例的卷积电路中的多个卷积运算器700可共享一移位卷积数据链500,在进行规模扩展时的开销比较小,因此,本实用新型实施例的卷积电路具有更好的扩展性,硬件开销小,可通过简单的硬件单元扩展和复制,并可同时处理多个卷积特征图featuremap的并行计算。并且,基于移位卷积数据链500、卷积参数存储器600和卷积运算器700,可实现3×3、5×5、7×7等多种尺寸的卷积运算,并可支持池化运算。
此外,卷积运算器的级联扩展实现方式可以有多种扩展方式,不限于本实用新型实施例所述的几种连接方式,该卷积电路通过简单地复制卷积运算器,可采用多种方式连接方式,实现较大规模卷积运算的并行处理,具有较好的可扩展性。
需要说明的是,卷积运算器700采用的重构设计思想,可以构建如3×3、5×5、7×7等卷积运算。比如,在构建5×5的卷积运算时,卷积运算器700内部需要设置4个3×3的卷积核,可重构支持4组3×3卷积运算,1组5×5卷积运算;在构建7×7的卷积运算时,卷积运算器700内部需要设置6个3×3的卷积核,可重构支持6组3×3卷积运算,2组5×5卷积运算和1组7×7卷积运算;在构建9×9的卷积运算时,卷积运算器700内部需要设置12个3×3的卷积核,可重构支持12组3×3卷积运算,4组5×5卷积运算和2组7×7卷积运算,1组9×9卷积运算等等,在此不一一举例说明。
上述任一项实施例中的卷积电路400中的卷积运算器700可作为卷积电路400的一部分,也可以作为一个独立的整体。当卷积运算器700作为一个独立的整体(比如作为一个独立的设备或者是具有ui界面的计算机装置等)时,其可接收移位卷积数据链500输出的卷积数据、以及卷积参数存储器600输出的卷积参数,并根据卷积数据和卷积参数进行卷积运算,生成卷积结果数据。
具体而言,本实用新型实施例还可以提供一种卷积运算器700,如图11所示,其可包括具有m个卷积尺寸为i×i卷积核7061的卷积运算单元706、卷积数据寄存器702和参数移位寄存器704;参数移位寄存器704响应于输入的运算模式控制指令,确定目标卷积运算模式,并基于目标卷积运算模式获取卷积参数,以基于卷积参数形成n组尺寸为j×j的卷积参数方阵,目标卷积运算模式对应的卷积运算的目标卷积尺寸为j×j;卷积数据寄存器702基于目标卷积运算模式获取目标卷积数据,以形成尺寸为j×j的目标卷积方阵;m个卷积核7061分别基于目标卷积方阵和卷积参数方阵,生成m组卷积结果数据。其中,卷积核7061的卷积尺寸为i×i,i=2m+1,j=2n+1,m,n为正整数,m=2k,k为大于1的正整数,n=(m*i*i)/(j*j),m>=(j*j)/(i*i),m和n为正整数,且n小于或等于m。
需要说明的是,卷积尺寸j×j表示目标卷积运算模式对应的卷积运算的最大卷积尺寸,卷积尺寸j×j则表示目标卷积运算模式对应的目标卷积尺寸,即j小于或等于j。
由于卷积运算器700通过参数移位寄存器704基于目标卷积运算模式对应的卷积尺寸j×j,获取卷积参数,并通过卷积数据寄存器702获取目标卷积数据,分别形成n组尺寸为j×j的卷积参数方阵、j×j的目标卷积方阵,然后通过m个卷积核7061分别对目标卷积方阵和卷积参数方阵进行卷积运算,生成m个卷积结果,从而可以支持n组尺寸为j×j的卷积运算。如此,由于本实用新型实施例的卷积参数以及卷积数据的获取是基于卷积运算的模式(即对应不同的卷积尺寸)进行获取,以通过m个卷积核根据获取的卷积参数和卷积数据完成卷积运算,因此,本实用新型实施例的卷积运算器700可以支持不同卷积尺寸的卷积运算。
其中,参数移位寄存器704可配置成:若n=m,则将n组卷积参数方阵中的卷积参数分组输入至m个卷积核中,以将目标卷积方阵分别与每一卷积核中的卷积参数进行卷积运算,生成m组卷积结果数据。若n<m,则将n组卷积参数方阵中的卷积参数、以及(m*i*i-n*j*j)个无效参数依次输入至m个卷积核中,以将目标卷积方阵分别与每一卷积核中的卷积参数进行卷积运算,生成m组卷积结果数据。
由于本实用新型实施例的卷积运算器700基于卷积运算的模式(即对应不同的卷积尺寸)获取卷积参数以及卷积数据,以通过m个卷积核根据获取的卷积参数和卷积数据完成卷积运算,因此,本实用新型实施例的卷积运算器700可以支持不同卷积尺寸的卷积运算。
在上述一个实施例中,卷积运算单元706还包括偏移量存储器7062,用于存储j×j偏移数据方阵,以在n=m或j=i时,使m个卷积核基于m组卷积结果数据与偏移数据方阵,生成m组累加运算结果。比如,以构建3×3卷积运算为例,4个卷积核根据4组卷积结果数据与偏移数据方阵,即可生成4组卷积结果数据。也就是说,对于所构建的目标卷积运算的卷积尺寸与卷积运算模块中卷积核的卷积尺寸相等的情况,在卷积核进行卷积运算时,在卷积运算单元706内部自动根据偏移量数据、目标卷积数据和卷积参数进行计算以得到卷积结果数据。
在上述另一个实施例中,卷积运算器700包括:累加运算器710和用于存储j×j偏移数据方阵的偏移量存储器712。其中,累加运算器710用于在n<m或j>i时,基于偏移数据方阵和m组卷积结果数据,得到目标卷积尺寸为j×j的累加运算结果。比如,以构建5×5卷积运算为例,则需要通过5×5累加模块获取5×5偏移数据方阵,以完成4组卷积结果数据与5×5偏移量的累加,从而得到5×5的卷积结果。
即,对于构建j(等于i)的卷积运算,偏移量是在卷积核内部完成运算,而对于构建j(不等于i)的卷积运算,偏移量则是在卷积核根据卷积参数和目标卷积数据完成卷积运算后,通过j×j累加运算模块获取偏移量数据,并通过j×j累加运算模块对偏移量数据和m组卷积运算结果进行累加计算,得到j×j的卷积运算结果。
在一个具体的实施例中,i=3,m=4,j=3时n=4,或i=3,m=4,j=5时n=1。即本实用新型一个具体的实施例提供了一种卷积运算器700,可结合图12进行说明,该卷积运算器可包括1组卷积数据寄存器702,寄存器组一共25(5×5)个寄存器,用于为卷积运算单元中3×3和5×5卷积核7061进行卷积运算共享;1组可重构支持3×3和5×5卷积的参数移位寄存器704,参数移位寄存器704内部一共36(4×3×3)个寄存器;4个流水3×3卷积核7061,卷积核由多个乘加器级联组成,卷积核7061内置3×3计算偏移量bias寄存器,其原始数据存储在偏移量存储器7062中,运算时从偏移量存储器7062中读取参与运算;1组5×5累加运算器710;5×5卷积运算所需的累加计算偏移量bias也存放在偏移量存储器712中,运算时实时读取;4组并行pooling池化运算器708。其中pooling单元内部是基于fifo实现的移位数据链,支持最大池化maxpooling和最小池化minpooling运算。偏移量存储器7062和偏移量存储器712内按地址顺序(升序或降序)存放了bias参数。运算时,偏移量存储器7062和偏移量存储器712的读地址由biasaddr寄存器指示,biasaddr指示当前所运算所需要的bias参数地址,以根据当前运算的进度顺次指示读取偏移量存储器7062或偏移量存储器712内的内容进行卷积累加运算。
由于卷积运算器700通过参数移位寄存器704基于目标卷积运算模式对应的卷积尺寸j×j,获取卷积参数,并通过卷积数据寄存器702获取目标卷积数据,分别形成n组尺寸为j×j(4组3×3或1组5×5)的卷积参数方阵、j×j(3×3或5×5)的目标卷积方阵,然后通过4个卷积核分别对目标卷积方阵和卷积参数方阵进行卷积运算,生成4个卷积结果,从而可以支持n组尺寸为j×j(4组3×3或1组5×5)的卷积运算。如此,本实用新型实施例的卷积运算器700可以支持不同卷积尺寸的卷积运算。
在上述任一项实施例中,结合图11和图12进行说明,卷积运算器700还包括卷积运算模式控制端口716,用于接收输入的卷积运算控制指令,以使参数移位寄存器704基于运算模式控制指令确定目标卷积运算模式。
比如,通过mode_sel输入的控制指令可控制支持3×3和5×5两种卷积运算模式。卷积运算器包括4个3×3卷积核,内含4个偏移量寄存器。4个卷积核分别采用数据(d11~d55)中对应的卷积数据和参数(w11~w55)中对应的卷积参数,进行卷积乘加运算,形成4个卷积结果r1~r4。
卷积运算器700工作于3×3卷积运算模式时,参数移位寄存器704为4个3×3卷积核供应卷积参数,36个参数分成4组,分别输入给4个卷积核进行并行计算。移位卷积数据链500负责输出的3×3矩阵窗口的数据共7个数据,串行写入可重构卷积数据寄存器702,由可重构卷积数据寄存器将7个卷积数据共享输入给4个3×3卷积核。4个卷积核分别从偏移量存储器7062中读取偏移量数据,并与卷积参数、卷积数据完成3×3卷积运算。卷积完成后,4组卷积结果数据并行输入relu模块完成激活函数运算。完成激活运算后的结果并行输入pooling模块,根据pool_len完成池化运算。根据当前计算结果性质,如果是中间结果且总量较小,则将结果存储在内部存储器中,用于后续运算,如果是最终结果或结果量较大,则输出到外部存储器当中。卷积运算器700工作于5×5卷积运算模式时的原理与5×5卷积运算模式的原理相同,在此不再赘述。如此,本实用新型实施例的卷积运算器700可以支持不同卷积尺寸的卷积运算。
需要说明的是,如图12所示,卷积运算器700的运行模式由外部输入的控制信号conv_len(卷积数据移位链长度选择)、conv_stride(移位数据链步长)、pool_len(池化移位链长度)、pool_stride(池化移位链步长)、mode_sel(卷积运算模式选择)确定。其中,移位链长度选择根据输入卷积特征图featuremap数据的长度来配置;3×3卷积运算或5×5卷积运算模式则根据mode_sel输入的指令进行确定。
在卷积运算器700中,还包括多路选择器714(mux),以从多个输入里面选择一组数据进行输出。也就是说,当卷积运算器的运行模式确定3×3卷积运算模式时,则选择一组3×3卷积结果至池化运算器708,池化运算器708基于该组3×3卷积结果和其它三组3×3卷积结果,执行池化运算,从而输出池化运算后的结果作为3×3的目标卷积结果;当卷积运算器的运行模式确定5×5卷积运算模式时,则选择一组5×5的累加运算结果至池化运算器708,此时,虽然图12中的池化运算器708的输入还包含有3组3×3卷积结果,但由于此时卷积运算器的运行模式确定5×5卷积运算模式,因此,输入至池化运算器708的三组3×3卷积结果数据此时为无效数据,即池化运算器708只基于一组5×5的累加运算结果进行池化运算,从而得到5×5的目标卷积结果。
如此,本实用新型实施例的卷积电路根据输入的控制信号控制基于fifo的卷积数据移位链的长度,并根据mode_sel决定所内部进行的卷积运算的方式(3×3或5×5),构建支持3×3和5×5卷积运算器,从而可以支持不同卷积尺寸的卷积运算,解决了现有技术中无法支持多种卷积尺寸的卷积运算的问题。
并且,卷积运算器接收的卷积数据是基于移位卷积数据链内部的fifo实现的,在不同尺寸的卷积运算模式时,移位卷积数据链工作时输出的卷积数据可以通过级联方式共享至各卷积运算器,在进行规模扩展时,硬件开销比较小,因此,本实用新型实施例的卷积电路具有更好的扩展性,硬件开销小,可通过简单的硬件单元扩展和复制,并可同时处理多个卷积特征图featuremap的并行计算。
此外,卷积电路中的移位卷积数据链500是基于fifo实现的移位数据链,由于fifo队列可采用sram(静态随机存取存储器)实现,即移位卷积数据链可作为另一种硬件资源,不占用寄存器,从而可以减小寄存器资源的消耗,因此,可以解决现有技术中需要消耗较多寄存器资源而导致硬件资源开销比较大的问题。
上述任一项所述的卷积运算器或卷积电路主要应用于cnn深度学习领域的图像卷积运算加速领域中,主要用于图像识别,人脸识别等等。
卷积运算器或卷积电路无论是工作于哪种卷积尺寸的卷积运算,整个系统的运算均是流水运算,而图片或者其他类型的实体数据的卷积处理性能取决于硬件装置的工作主频和输入图片的大小。
在上述一些实施例中,如图13所示,卷积电路400可作为受控终端,响应于控制终端1302发出的运算模式控制指令,确定目标卷积运算模式,以执行上述任一项实施例所述的目标卷积运算。其中,移位卷积数据链500和卷积参数存储器600作为卷积电路的控制模块1304,分别接收控制终端1302发出的运算模式控制指令,并分别向卷积运算器700输入目标卷积数据和卷积参数,以使卷积运算器根据目标卷积数据和卷积参数生成卷积结果数据。从而可以支持多种尺寸的卷积运算。
当然,在另一些实施例中,如图14所示,卷积电路400可包括控制终端和受控终端,其中,卷积运算器700可作为受控终端,移位卷积数据链500和卷积参数存储器600则作为控制终端1302的控制模块1304,分别向卷积运算器700输入目标卷积数据和卷积参数,以使卷积运算器根据目标卷积数据和卷积参数生成卷积结果数据。从而可以支持多种尺寸的卷积运算。
其中,受控终端以及控制终端可以配置为虚拟机、应用程序、运行ui的计算机装置等终端设备。需要说明的是,在本实施例中,术语“受控终端”与术语“控制终端”互为控制与被控制的角色关系;例如,当卷积电路400作为受控终端时,控制终端1302与卷积电路400互为控制与被控制的角色关系。当移位卷积数据链500和卷积参数存储器600作为卷积电路400的控制模块1304以作为控制终端1302,卷积运算器700作为受控终端时,控制模块1304与卷积运算器700互为控制与被控制的角色关系。
上文所列出的一系列的详细说明仅仅是针对本实用新型的可行性实施方式的具体说明,它们并非用以限制本实用新型的保护范围,凡未脱离本实用新型技艺精神所作的等效实施方式或变更均应包含在本实用新型的保护范围之内。
对于本领域技术人员而言,显然本实用新型不限于上述示范性实施例的细节,而且在不背离本实用新型的精神或基本特征的情况下,能够以其他的具体形式实现本实用新型。因此,无论从哪一点来看,均应将实施例看作是示范性的,而且是非限制性的,本实用新型的范围由所附权利要求而不是上述说明限定,因此旨在将落在权利要求的等同要件的含义和范围内的所有变化囊括在本实用新型内。不应将权利要求中的任何附图标记视为限制所涉及的权利要求。
此外,应当理解,虽然本说明书按照实施方式加以描述,但并非每个实施方式仅包含一个独立的技术方案,说明书的这种叙述方式仅仅是为清楚起见,本领域技术人员应当将说明书作为一个整体,各实施例中的技术方案也可以经适当组合,形成本领域技术人员可以理解的其他实施方式。
- 还没有人留言评论。精彩留言会获得点赞!