景深图像重聚焦的制作方法
本发明涉及执行图像重聚焦。一些方面涉及训练执行输入图像的重聚焦的图像处理模型。
背景技术:
图像的景深(depthoffield,dof)是指所有对象都清晰(对焦)的深度范围。例如,浅dof图像可用于将对象与其背景分离,通常用于人像和微距摄影。
图像的景深部分取决于用于捕获图像的设备的孔径大小。因此,一些具有窄孔径的图像处理设备(如智能手机)通常无法光学呈现浅景深图像,而是基本上捕获全焦图像。
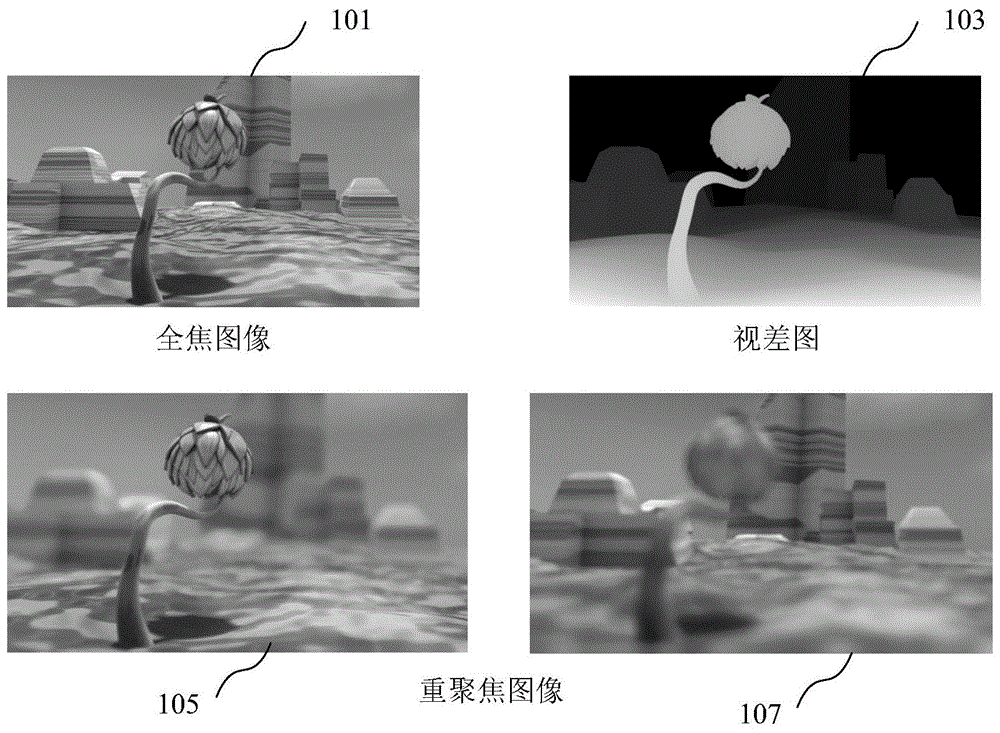
然而,通过合适的数字图像处理技术,可以通过重聚焦数字图像来模拟或合成浅景深效果。一些以计算方式重聚焦数字图像的方法利用了图像的深度信息。图1示出了如何以计算方式重聚焦输入数字图像的示例。
图1示出了全焦图像101。103处示出了包含图像101的深度信息的图。在该示例中,图是视差图,但在其它示例中,它可以是深度图。视差图对表示公共场景的一对(通常是立体)图像的块之间的空间移位进行编码。当所述一对图像由两个空间分离的摄像机捕获时,场景中的一个点投影到每个图像内的不同块位置。这些不同块位置之间的坐标移位是视差。因此,视差图中的每个块对一对图像表示的场景的一部分之间的空间移位进行编码。视差图的块对一对图像中一个图像中的并置块表示的场景的一部分与一对图像中另一个图像表示的场景的所述一部分之间的坐标移位进行编码。视差图的所述块的视差值表示校正图像域中的坐标移位。
块是指图的一个或多个像素的块。与距离图像平面深度较浅的场景部分相比,距离图像平面深度较深的场景部分在一对图像之间的块位移相对较小。因此,视差图的值通常与对应深度图的深度值成反比。
根据输入图像101和图103,重聚焦图像105和107可以通过以计算方式重聚焦图像101来生成。在图像105中,背景通过重聚焦而模糊,前景保持聚焦;在图像107中,前景通过重聚焦而模糊,背景保持聚焦。
技术实现要素:
发明内容介绍了一些概念,在具体实施方式中会进一步描述这些概念。发明内容并非旨在确定所要求保护的主题的关键特征或必要特征,也并非旨在用于限制所要求保护的主题的范围。
根据一个方面,提供了一种图像处理设备,包括处理器,所述处理器用于通过以下步骤根据输入图像和指示所述输入图像的深度信息的图生成重聚焦图像:对于与所述图像内相应深度关联的多个平面中的每个平面:生成深度掩码,所述深度掩码的值指示所述输入图像的区域是否在所述平面的指定范围内,其中,通过评估所述输入图像的区域与根据所述图确定的所述平面之间的范围的可微函数来评估区域是否在所述平面的所述指定范围内;根据所述输入图像和所述生成的深度掩码生成掩码图像;使用模糊核重聚焦所述掩码图像以生成重聚焦的分图像;根据所述多个重聚焦的分图像生成所述重聚焦图像。
这使得可以执行可微的重聚焦步骤,从而允许重聚焦步骤作为可学习流水线内的层实现。
多个平面可以定义深度范围,并且输入图像可以具有跨越多个平面的深度范围的景深。这可以使浅景深图像重聚焦。
指示所述图像的深度信息的所述图可以是视差图,并且所述多个平面中的每个平面可以是处于相应视差值的平面;或者(ii)指示所述图像的深度信息的所述图可以是深度图,并且所述多个平面中的每个平面可以是处于相应深度处的平面。这使得可以在重聚焦阶段灵活使用深度图或视差图。
所述函数可以在定义函数值范围的下界与上界之间平滑变化,当正在评估所述函数的图像区域在所述平面的所述指定范围内时,所述函数具有在其范围的前半部分内的值;当正在评估所述函数的图像区域不在所述平面的所述指定范围内时,所述函数具有在其范围的后半部分内的值。这使从计算函数返回的函数值能够指示图像的区域是否在平面的指定范围内。
可以评估所述可微函数以评估是否满足
深度掩码可以为输入图像的一个或多个像素的每个块指定值。这允许评估图像的每个块,以确定块是否在平面的指定范围内。
所述模糊核是半径为所述孔径大小,以及所述平面与焦平面之间的深度或视差差值的函数的径向核。这使得模糊取决于平面的深度。
生成的掩码图像可以仅包含输入图像中确定在平面的指定范围内的那些区域。这使得每个平面的分图像可以相互在顶部层叠。
根据第二方面,提供了一种训练图像处理模型的方法,所述方法包括:
接收多个图像元组,每个图像元组包括表示公共场景的一对图像和所述场景的重聚焦的训练图像;
对于每个图像元组:
(i)使用所述图像处理模型处理所述一对图像,以估计指示所述场景的深度信息的图;
(ii)对于与所述图像内相应深度关联的多个平面中的每个平面:
生成深度掩码,所述深度掩码的值指示输入图像的区域是否在所述平面的指定范围内,其中,通过评估所述输入图像的区域与根据所述估计图确定的所述平面之间的范围的可微函数来评估区域是否在所述平面的所述指定范围内;
根据所述输入图像和所述生成的深度掩码生成掩码图像;
使用模糊核重聚焦所述掩码图像以生成重聚焦的分图像;
(iii)根据所述多个重聚焦的分图像生成重聚焦图像;
(iv)估计所述生成的重聚焦图像与所述重聚焦的训练图像之间的差异;
(v)根据所述估计的差异调整所述图像处理模型。
这提供了一种训练图像处理模型以生成可通过重聚焦学习的重聚焦图像的方法。
所述生成图可以与所述一对图像的分辨率相同,并且所述输入图像是所述一对图像中的一个图像。这使得重聚焦阶段可以与深度估计阶段一起顺序执行,并且可以从重聚焦阶段生成全分辨率的重聚焦图像,而无需在该阶段中进行上采样。
与所述一对图像相比,所述生成图可以具有降低的分辨率,并且所述输入图像形成为所述一对图像中的一个图像的分辨率降低图像。这使得重聚焦阶段的步骤可以对较少的图像块执行。
生成所述重聚焦图像的所述步骤(iii)可以使用所述分辨率降低图执行,并且还可以包括以下步骤:根据所述多个重聚焦的分图像生成分辨率降低的重聚焦图像;对所述分辨率降低的重聚焦图像进行上采样以生成所述重聚焦图像。这使得可以生成全分辨率的重聚焦图像。
根据第三方面,提供了一种调整图像处理模型的方法,所述方法包括:
接收多个图像元组,每个图像元组包括表示公共场景的一对图像和所述场景的重聚焦的训练图像;
对于每个图像元组:
使用图像处理模型处理所述一对图像,包括:
(i)使用计算神经网络处理所述一对图像,以从所述一对图像中提取特征;
(ii)针对多个视差平面比较所述特征以生成成本量;
(iii)根据所述成本量的相应上采样条带,为与所述图像内的相应深度关联的多个平面中的每个平面生成掩码;
执行重聚焦阶段,包括:
(iv)对于所述多个平面中的每个平面:
根据输入图像和所述生成的掩码生成掩码图像;
使用模糊核重聚焦所述掩码图像以生成重聚焦的分图像;
(v)根据所述多个重聚焦的分图像生成重聚焦图像;
(vi)估计所述生成的重聚焦图像与所述重聚焦的训练图像之间的差异;
(vii)根据所述估计的差异调整所述图像处理模型。
这可以使重聚焦能够直接从成本量执行,并可以减少可学习流水线的步骤数量。
可以提供一种图像处理模型,所述图像处理模型通过本文的方法调整,以根据表示公共场景的一对输入图像生成重聚焦图像。这可以提供一种经过调整或训练的图像处理模型,根据输入图像生成重聚焦图像。
可以提供一种图像处理设备,包括处理器和存储器,所述存储器存储非瞬时形式的指令,所述指令可由所述处理器执行以实现图像处理模型,所述图像处理模型通过本文的任一种方法调整,以根据表示公共场景的一对输入图像生成重聚焦图像。这可以使经过调整或训练的图像处理模型能够在设备内实现,以执行重聚焦。
上述特征可以适当地组合,这对技术人员而言是显而易见的,并且可以与本文描述的示例的任何方面组合。
附图说明
现在参考附图描述示例,其中:
图1示出了根据输入数字图像以计算方式生成重聚焦图像的示例;
图2示出了用于根据输入图像和指示输入图像的深度信息的图生成重聚焦图像的阶段的概述;
图3是用于根据输入图像和指示这些图像的深度信息的图生成重聚焦图像的图像处理设备的示例;
图4是本发明的实施例提供的根据输入图像和指示输入图像的深度信息的图生成重聚焦图像的方法的流程图;
图5是使用可微函数近似赫维赛德(heaviside)阶跃函数的图;
图6是用于根据一对立体图像估计图的示例性stereonet流水线的示意图;
图7是根据一对立体图像生成重聚焦图像的示例性可学习流水线的示意图;
图8示出了使用图7的流水线获得的示例性预测图像;
图9是根据一对立体图像生成重聚焦图像的另一示例性可学习流水线的示意图;
图10是调整图像处理模型的方法的流程图;
图11是根据一对立体图像生成重聚焦图像的另一示例性可学习流水线的示意图;
图12是使用图11中的流水线调整图像处理模型的方法的流程图。
附图示出了各种示例。技术人员将理解,附图中所示的元素边界(例如,框、框组或其它形状)表示边界的一个示例。在一些示例中,一个元素可以设计为多个元素,或者多个元素可以设计为一个元素。在适当的情况下,在所有附图中使用共同的附图标记来表示类似的特征。
具体实施方式
以下描述以示例的方式呈现,以使本领域技术人员能够制造和使用本发明。本发明不限于本文所述的实施例,对所公开实施例的各种修改对本领域技术人员而言是显而易见的。实施例仅通过示例描述。
图2是本发明提供的用于执行计算图像重聚焦的流水线的示意图。
计算流水线分为两个一般阶段:深度估计201和重聚焦203。深度估计阶段201可以由深度估计模块执行,重聚焦阶段可以由重聚焦模块执行。深度估计阶段对表示公共场景的输入图像205进行处理,以生成包含场景的深度信息的图207。在该示例中,图是视差图,但在其它示例中,它可以是深度图。该图(深度图或视差图)是编码输入图像205表示的场景的深度信息的图像。这对图像可以是立体图像。
输入图像之一和图207输入重聚焦阶段203中。输入流水线的重聚焦阶段203的其它参数是重聚焦最终图像所使用的虚拟孔径大小和虚拟焦平面。虚拟孔径大小和焦平面的值可以配置。
现在描述一种执行可由重聚焦模块实现的重聚焦阶段203的方法。
首先,定义平面集合。根据图是深度图或视差图,这些平面可以是深度平面或视差平面。深度平面是位于所获取场景(即图像205表示的场景)内特定深度处的平面。视差平面是位于所获取场景内特定视差值处的平面,即与特定视差值关联的平面。(深度或视差)平面平行于图像平面和焦平面。这些平面也相互平行。这些平面跨越图像内的深度或视差范围。平面的平面间间距可以等于1/a,其中a是孔径大小。平面的跨度可以使得平面覆盖的深度范围小于或等于输入图像的景深;即,输入图像可以具有跨越平面深度范围的景深。
然后,通过迭代执行平面集合的处理步骤序列来执行重聚焦阶段。现在描述该步骤序列。
1.对于每个平面d∈[dmin,dmax,],生成深度掩码,表示为md。深度掩码包含指示输入图像的区域是否在平面d的指定范围内的值。掩码包含对应于输入图像的相应块的值数组,其中,每个块是一个或多个像素的块。如果满足以下条件,则输入图像的块x内的图像部分视为在平面d的指定范围内:
其中,d(x)是块x的图207的值,d′是平面d的深度值或视差值,a是孔径大小。
可以通过评估赫维赛德阶跃函数来评估是否满足等式(1)的条件,赫维赛德阶跃函数写成:
其中,ξ是任意量。因此,在一个示例中,重聚焦模块可以通过如下评估等式(2)来计算深度掩码的值:
其中,md(x)是平面d和块x的深度掩码的值。在该示例中,‘0’值表示图像的区域不在平面d的指定深度内,‘1’值表示图像的区域在平面d的指定范围内。
2.在计算了深度掩码md之后,重聚焦模块根据输入图像和平面d计算的深度掩码计算该平面的掩码图像。掩码图像是仅包含输入图像中确定在深度平面d的指定范围内的那些部分。
用数学方式表示,重聚焦模块可以如下计算平面d的掩码图像,表示为id:
其中,i是输入图像,
3.重聚焦模块计算用于模糊掩码图像的模糊核kr。在该示例中,模糊核是具有半径(表示为r)的径向核。半径的值取决于平面d与焦平面的距离和孔径大小a。半径可以根据以下等式计算:
r=a|d′-df|(5)
其中,df是焦平面的深度值或视差值。
4.然后,重聚焦模块将模糊核应用于掩码图像id,以生成重聚焦的分图像,表示为
重聚焦的分图像和重聚焦的深度掩码可以通过分别将模糊核与分图像和深度掩码卷积来生成。也就是说,重聚焦模块可以通过执行计算生成重聚焦的分图像和重聚焦的深度掩码:
其中,kr是具有半径r的模糊核,*表示卷积。
5.然后,重聚焦模块将平面d的重聚焦的分图像与已经在重聚焦阶段的先前迭代中计算的平面的重聚焦的分图像组合在一起。重聚焦的分图像可以在深度方面从后到前组合,即,这些重聚焦的分图像层叠,其中,来自与较浅深度值关联的平面的重聚焦的分图像层叠在来自与较深深度值关联的平面的重聚焦的分图像的顶部上。重聚焦的分图像可以通过在缓冲区内累积分图像的块值来组合。也就是说,可以集成重聚焦的分图像以形成重聚焦图像。
用数学方式表示,重聚焦模块可以如下在重聚焦阶段的每次迭代中计算层叠图像if:
if的值可以用0初始化。
平面d的重聚焦的深度掩码可以类似地与在重聚焦阶段的先前迭代中计算的平面的重聚焦的深度掩码组合,即,可以集成重聚焦的深度掩码。
用数学方式表示,重聚焦模块可以如下在重聚焦阶段的每次迭代中计算层叠的重聚焦的深度掩码mf:
mf的值可以用0初始化。
6.在对集合中的每个平面执行了步骤1至5的序列后,通过使用层叠的重聚焦的深度掩码mf标准化完成的层叠图像if来生成重聚焦图像。也就是说,重聚焦模块如下计算重聚焦图像:
其中,o是最终重聚焦图像(如图2中209处所示),
虽然上述算法使得能够根据输入图像计算重聚焦图像,但它的缺点是它不能用作可学习流水线内的层。换句话说,无法通过重聚焦算法学习。已经了解,无法通过重聚焦算法学习的原因是,由于算法是不可微的,因此梯度信息不能通过算法的各个阶段反向传播以调整该算法中使用的参数,而算法不可微是因为用于在步骤1生成深度掩码的赫维赛德阶跃函数由于不是连续函数而不可微。
本文描述了一种执行图像重聚焦的方法,该方法可通过合适的机器学习技术学习。
图3示出了包括深度估计模块302和重聚焦模块304的图像处理设备300。模块302和304可以实现为设备300的处理器的一部分。深度估计模块302接收数字图像(通常用306表示)作为其输入,并根据这些数字图像生成包含这些数字图像的深度信息的图。重聚焦模块304接收:(i)来自深度估计模块302的生成图d,其包含数字图像i的深度信息;(ii)已经为其生成图的数字图像i;和(iii)焦平面df和孔径大小a的指示。df和a的值可以是用户设置的,即可以配置。它们可以称为虚拟焦平面和虚拟孔径。在下文示例中,图d可以是视差图或深度图。该图是编码图像i的深度信息的图像。视差图包含输入图像的一个或多个像素的块的视差值,深度图包含输入图像的一个或多个像素的块的深度值。由于视差与深度之间的反关系,视差图通常可以根据深度图计算,反之亦然。
重聚焦模块304用于使用接收到的图d对接收到的输入图像i进行数字重聚焦。重聚焦模块的操作结合图4的流程图描述。
重聚焦模块304定义多个平面d。如果图是视差图,则平面可以是视差平面(即输入图像表示的场景中特定视差值处的平面);或者如果图是深度图,则平面可以是深度平面(即输入图像表示的场景中特定深度值处的平面)。由于深度与视差之间的关系,(视差或深度)平面可以与图像内的深度关联。
这些平面平行于图像平面和焦平面。这些平面也相互平行。这些平面跨越图像内的深度或视差范围,范围为从与最小深度水平(表示为dmin)关联的平面到与最大深度水平(表示为dmax)关联的平面。为了清楚起见,需要说明的是,‘最小深度水平’是指多个平面的最小深度水平,而‘最大深度水平’是指多个平面的最大深度水平,并且不意味着对图像的最大深度和最小深度的值进行任何限制或约束。平面的平面间间距可以等于1/a,其中a是孔径大小。平面的深度跨度可以小于或等于输入图像i的景深;即,输入图像可以具有跨越平面深度范围的景深。在一些示例中,输入图像可以是全焦图像,但不一定是全焦图像。在其它示例中,平面的深度跨度可以与孔径大小a无关,但可以根据经验设置。
对多个平面中的每个平面执行步骤402至408。换句话说,重聚焦模块304对多个平面迭代地执行处理步骤序列(步骤402至408)。从平面dmin或平面dmax开始,依次对每个平面执行步骤402至408。也就是说,重聚焦模块可以从平面dmin开始对每个连续加深的深度平面执行步骤402至408,或者可以从平面dmax开始对每个连续变浅的深度平面执行步骤402至408。
在步骤402中,重聚焦模块304生成平面d的深度掩码,表示为md。深度掩码包含指示输入图像i的区域是否在平面d的指定范围内的值。深度掩码包含对应于图像i的相应块的值数组,其中,每个块是一个或多个像素的块。深度掩码可以包含对应于图像i的每个像素的值。如果满足上文等式(1)中指定的条件(为方便起见,下文重复),则该图像的块x内的图像i的区域视为在平面d的指定范围内:
其中,d(x)是块x的图的值,d′是平面d的深度(如果d是深度图)或视差(如果d是视差图),a是孔径大小。
重聚焦模块304通过评估可微函数来评估区域是否在深度平面的指定范围内。可微函数是输入图像的区域与根据图d(x)确定的平面d之间的范围的函数。换句话说,重聚焦模块304评估图像i的块x的可微函数,以确定该块内的图像的区域是否在平面d的指定范围内;即,评估函数的值指示区域是否在平面d的指定范围内。
因此,重聚焦模块304评估块x的可微函数,以评估该块是否满足等式(1)的条件。
可微函数在定义它的域上是可微的(即在其一阶导数中是连续的)。函数可以在下界与上界之间平滑变化,上界和下界定义函数值的范围。当针对在平面d的指定范围内的图像区域进行评估时,可微函数优先返回在函数值的第一子范围内的值;当针对不在平面d的指定范围内的图像区域进行评估时,可微函数优先返回函数值的第二非重叠子范围内的值。这使评估函数的值能够指示图像区域是否在平面d的指定范围内。
例如,该函数可以从基本上恒定的第一值变化到基本上恒定的第二值,例如通过从第一渐近值平滑地变化到第二渐近值。该函数可以围绕范围等于指定范围的点(即
可微函数可以是赫维赛德阶跃函数的平滑近似。已经了解到,等式(2)的赫维赛德函数的一种有利的可微近似是tanh函数:
图5示出了近似赫维赛德阶跃函数h(x)(以504表示)的示例性tanh函数y=tanh(x)(以502表示)。
因此,在一个示例中,重聚焦模块304可以通过评估等式(10)来计算深度掩码md的值,即
其中,α是控制近似过渡的锐度的常数。α的值可以配置。它可以根据经验设置。通常,α的较大值可用于更接近近似赫维赛德函数。例如,α的值可以大于500或大于1000。
应当了解,在其它示例中,可微函数可以不是tanh函数,而是可以采用不同的形式。
在步骤404中,重聚焦模块304根据输入图像i和深度掩码md生成掩码图像。掩码图像或分图像表示为id,其中,上标‘d’表示针对平面d生成掩码图像。掩码图像是仅包含输入图像中确定在平面d的指定范围内的那些部分,可以根据上文等式(4)计算。
重聚焦模块304还可以计算如上文结合步骤3所述的模糊核。
在步骤406中,重聚焦模块304使用模糊核重聚焦掩码图像id,以计算重聚焦的分图像,表示为
重聚焦模块304还计算模糊的深度掩码
在步骤408中,重聚焦模块304将重聚焦的分图像
用数学方式表示,重聚焦模块304可以如下在重聚焦阶段的每次迭代中创建层叠图像if:
也就是说,重聚焦模块304将平面d的重聚焦的分图像与已经在先前迭代中计算的平面的重聚焦的分图像组合在一起。层叠图像if与项
平面d的重聚焦的深度掩码可以类似地与在重聚焦阶段的先前迭代中计算的平面的重聚焦的深度掩码组合,即,也可以集成重聚焦的深度掩码。
用数学方式表示,重聚焦模块304可以如下在重聚焦阶段的每次迭代中计算层叠的重聚焦的深度掩码mf:
在对多个平面d∈[dmin,dmax]都执行步骤402-408之后,重聚焦模块304已经通过对重聚焦的分图像进行层叠来形成完成的层叠图像if,并且已经形成层叠的重聚焦的深度掩码。由此,重聚焦模块生成重聚焦图像,表示为o。重聚焦图像是通过使用完成的层叠的重聚焦深度掩码mf对完成的层叠图像if进行标准化来生成的。也就是说,重聚焦模块304如下计算重聚焦图像:
因此,重聚焦模块304根据多个重聚焦的分图像生成重聚焦图像。
上述方法使用可微函数为每个平面生成深度掩码,所述深度掩码指示输入图像中在该平面的指定范围内的区域。可微函数的使用使上文结合图4所述的整个算法是可微的。这有利于使该方法能够用作流水线的一部分,用于根据输入图像生成重聚焦图像,该方法可以通过一系列学习技术学习。现在描述如何在可学习的重聚焦流水线内实现该方法的一些示例。
虽然结合图4所述的方法适合于使用一系列学习技术实现,但仅为了说明目的,提供引用“stereonet”流水线的示例。
图6示出了stereonet流水线的示例。stereonet流水线600用于根据表示公共场景的一对图像估计图d。这对图像可以是立体图像。图d可以是视差图或深度图。
这对立体图像在602处示出,包括‘左图像’和‘右图像’。在其它示例中,图像602不是‘左’图像和‘右’图像,而是表示公共场景的一些其它对图像。这对图像输入特征提取网络604中,特征提取网络604从这些图像中提取特征。这些特征可以以与输入图像602的分辨率相比降低的分辨率提取。
然后,对多个视差平面比较提取的特征。为此,从一对图像中的一个图像(在该示例中为左图像)提取的特征被转移到多个视差平面中的每个视差平面,然后与从一对图像中的另一个图像(在该示例中为右图像)提取的特征进行比较。通过计算其中一个图像的转移特征与另一个图像的非转移特征之间的差值来进行比较。这可以通过计算转移特征和非转移特征的并置块之间的差异(例如值)来完成。每个视差平面的计算差值形成成本量606的相应条带。
成本量606通过softmin函数608,并由此计算视差图610。视差图610是低分辨率图像,即与输入图像602相比,分辨率降低。在该示例中,视差图的分辨率是输入图像的分辨率的1/8。然后使用上采样网络612对低分辨率图进行上采样,以生成图614,在该示例中,图614是视差图。在其它示例中,可以处理视差图以生成对应的深度图。图614是与图像602的分辨率相等的图像。
图7示出了一种示例性架构,用于实现根据输入图像计算重聚焦图像以形成可学习的重聚焦流水线的可微方法。
图7中的重聚焦流水线700包括深度估计阶段600和重聚焦阶段702。深度估计阶段600可以通过图3的深度估计模块302实现,重聚焦阶段可以通过重聚焦模块304实现。
为了训练或调整重聚焦流水线700,可以使用多个图像元组。每个图像元组可以包括表示公共场景的一对图像和场景的训练图像。这对图像可以是由‘左图像’和‘右图像’形成的立体图像。这对图像在602处示出。训练图像可以是地面实况图像。训练图像可以是浅dof图像。为了完整起见,需要说明的是,训练图像没有在图7中示出。
对于图像元组,该元组的表示公共场景的一对图像输入深度估计阶段600中。深度估计阶段600根据这对图像估计图614,如上文结合图6所述。
然后,将计算出的图614输入重聚焦阶段702中。一对图像602中的一个图像也输入重聚焦阶段702中。然后,重聚焦阶段702以上文结合图4所述的方式根据估计图614和输入图像计算重聚焦图像704。
然后计算所计算的重聚焦图像704与元组的训练图像之间的差值,并反馈回深度估计阶段600。估计的重聚焦图像与训练图像之间的差值可以作为残差数据反馈。将残差数据反馈回深度估计阶段600,以调整该阶段用于根据一对图像估计图的参数。
图8示出了发明人已经根据地面实况图像804获得的预测的重聚焦图像802的示例。还示出了估计图806。
图9示出了另一种示例性架构,用于实现根据输入图像计算重聚焦图像以形成可学习的重聚焦流水线的可微方法。
图9中的重聚焦流水线900包括深度估计阶段902和重聚焦阶段904。深度估计阶段902可以通过图3的深度估计模块302实现,重聚焦阶段904可以通过重聚焦模块304实现。
为了训练或调整重聚焦流水线900,可以使用多个图像元组。每个图像元组可以包括表示公共场景的一对图像和场景的训练图像。这对图像可以是由‘左图像’和‘右图像’形成的立体图像。这对图像在906处示出。训练图像可以是地面实况浅dof图像。
对于每个图像元组,该元组的表示公共场景的一对图像输入深度估计阶段900中。深度估计阶段900根据这对图像估计图908。
将这对图像输入特征提取网络910中以估计图908,特征提取网络910从这些图像中提取特征。这些特征可以以与输入图像906的分辨率相比降低的分辨率提取。
然后,对多个视差平面比较提取的特征。为此,从一对图像中的一个图像(在该示例中为左图像)提取的特征被转移到多个视差平面中的每个视差平面,然后与从一对图像中的另一个图像(在该示例中为右图像)提取的特征进行比较。通过计算其中一个图像的转移特征与另一个图像的非转移特征之间的差值来进行比较。这可以通过计算转移特征和非转移特征的并置块之间的差异(例如值)来完成。每个视差平面的计算差值形成成本量912的相应条带。
成本量912通过softmin函数914,并由此计算图908。图908是低分辨率图像,即与一对图像906相比,分辨率降低。在该示例中,图的分辨率是输入图像的分辨率的1/8。softmin函数914的输出是视差图,因此图908可以是视差图,或者可以进一步处理以生成深度图。
然后,将计算出的图908输入重聚焦阶段904中。对一对图像906中的一个图像(在该示例中为左图像)进行下采样,也输入重聚焦阶段904中。可以对输入图像进行下采样以具有与图908相同的分辨率。图9未示出下采样。
然后,重聚焦阶段904根据估计图908和输入图像(该输入图像是一对图像906中的一个图像的下采样版本)计算分辨率降低的重聚焦图像916。重聚焦阶段904根据上文结合图4所述的方法根据这些输入计算分辨率降低的重聚焦图像916。
然后,通过上采样网络918对分辨率降低的重聚焦图像916进行上采样,以生成重聚焦图像920。重聚焦图像920是全分辨率图像,即它的分辨率与图像906相同。该上采样也可以由重聚焦模块304执行。
然后计算重聚焦图像920与元组的训练图像之间的差值,并反馈回深度估计阶段902。估计的重聚焦图像920与训练图像之间的差值可以作为残差数据反馈。将残差数据反馈回深度估计阶段902,以调整该阶段用于根据一对图像估计图的参数。
现在结合图10的流程图提供了可以如何训练或调整流水线700和900以根据输入一对图像生成重聚焦图像的概述。
在步骤1002中,例如由深度估计模块302接收多个图像元组。每个图像元组包括表示公共场景的一对图像(例如图像602或906),以及可以是地面实况图像等的重聚焦的训练图像。
对每个图像元组执行步骤1004至1018。
在步骤1004中,使用图像处理模型处理元组的一对图像以估计图d。步骤1004可以由深度估计模块302执行。图像处理模型可以对应于图7所示的深度估计阶段600或图9所示的深度估计阶段902。换句话说,图像处理模型的性能可以包括执行深度估计阶段600或902的步骤。图可以是视差图或深度图。该图的分辨率可以与元组中一对图像的分辨率相同(例如,图614),或者可以与一对图像相比具有降低的分辨率(例如,图908)。
步骤1006至1014可以由重聚焦模块304执行。这些步骤可以对应于图7所示的重聚焦阶段702或图9所示的重聚焦阶段904。这些步骤使用在步骤1004中生成的图d和输入图像i执行。输入图像可以是元组的一对图像中的一个图像(例如,如在流水线700中),也可以是由元组的一对图像中的一个图像形成的图像(例如,如在流水线900中,其中,重聚焦阶段902的输入图像通过对立体图像906中的一个图像进行下采样而形成)。
对与输入图像内的相应深度关联的多个平面中的每个平面执行步骤1006至1012。每个平面可以是深度平面(如果在步骤1004中生成的图是深度图)或视差平面(如果在步骤1004中生成的图是视差图)。
在步骤1006中,生成深度掩码
在步骤1008中,根据深度掩码id和输入图像i生成掩码图像。
在步骤1010中,使用模糊核kr重聚焦掩码图像,以生成重聚焦的分图像
在步骤1012中,重聚焦的分图像在部分重建的重聚焦图像if上层叠。
步骤1006至1012对应于图4的步骤402至408,因此在此不再重复对这些步骤的详细描述。
在对每个平面执行步骤1006至1012后,在步骤1014中生成重聚焦图像o。
重聚焦图像可以直接通过使用层叠的模糊深度掩码mf对最终层叠图像if进行标准化来生成,例如,如流水线700中的重聚焦图像704。当最终层叠图像if的分辨率与元组的一对图像相等时,可以使用这种方法(例如,如在流水线700中)。
或者,可以通过如下方式生成重聚焦图像:首先使用层叠的模糊深度掩码mf对最终层叠图像if进行标准化,以生成分辨率降低的重聚焦图像,然后对该图像进行上采样以生成重聚焦图像o。例如,流水线900中就是这种情况,其中,最终层叠图像if与图像906相比具有降低的分辨率,并用于生成分辨率降低的重聚焦图像916。然后对图像916进行上采样以生成重聚焦图像920。
在步骤1016中,估计重聚焦图像与元组的训练图像之间的差值。然后,将估计的差值反馈回深度估计阶段,并用于调整图像处理模型(步骤1018)。
上文示例说明了可以如何使用可微函数根据输入图像生成重聚焦图像,以产生用于执行重聚焦的完全可学习的流水线的方法。
图11示出了另一种示例性架构,用于根据输入图像计算重聚焦图像以形成可学习的重聚焦流水线。流水线1100包括使用图像处理模型实现的深度处理阶段1102和重聚焦阶段1104。深度处理阶段1102可以由深度估计模块302执行,重聚焦阶段1104可以由重聚焦模块304执行。
流水线1100的操作结合图12的流程图描述。
在步骤1202中,例如由深度估计模块302接收多个图像元组。每个图像元组包括表示公共场景的一对图像,以及可以是地面实况图像等的重聚焦的训练图像。每对图像可以是包括‘左图像’和‘右图像’的立体图像。一对立体图像的示例在1106处示出。训练图像可以是全焦图像,但不一定是全焦图像。
对每个图像元组执行步骤1204至1218。
步骤1204至1208构成图像处理模型的一部分,用于处理一对图像1106,作为深度处理阶段1102的一部分。换句话说,深度处理阶段1102通过使用图像处理模型来根据步骤1204至1208处理一对图像1106来执行。
在步骤1204中,将一对图像1106输入特征提取网络1108中。特征提取网络1108是从图像中提取特征的计算神经网络。这些特征可以以与输入图像1106的分辨率相比降低的分辨率提取。
在步骤1206中,对多个视差平面比较提取的特征。为此,从一对图像中的一个图像(在该示例中为左图像)提取的特征被转移到多个视差平面中的每个视差平面,然后与从一对图像中的另一个图像(在该示例中为右图像)提取的特征进行比较。通过计算其中一个图像的转移特征与另一个图像的非转移特征之间的差值来进行比较。这可以通过计算转移特征和非转移特征的对应块之间的差异(例如值)来完成。每个视差平面的计算差值形成成本量1110的相应条带。成本量的条带在图11中表示为c0、c1和c2。成本量的每个条带表示输入一对图像1106的(分辨率降低的)视差信息。因此,成本量的每个条带都与相应的视差平面关联。
在步骤1208中,通过上采样成本量1110的相应条带,为与一对图像1106中的一个图像内的相应深度关联的多个平面d中的每个平面生成掩码md。换句话说,对成本量的每个条带进行上采样以形成相应的掩码md,该掩码与平面d关联。上采样在1112处示出。
与掩码关联的平面可以是视差平面或深度平面。与相应视差平面关联的掩码可以直接通过对成本量的相应条带进行上采样来生成。为了生成与深度平面关联的掩码,对成本量进行上采样,并进一步处理所得到的掩码(与视差平面关联),以生成与相应深度平面关联的掩码。通过对成本量的相应条带进行上采样而创建的掩码在1114处示出。
然后,将计算出的掩码md用于流水线的重聚焦阶段1104。因此,与在重聚焦阶段内使用根据估计的深度/视差图生成的深度掩码md的上述方法相比,在该方法中,在重聚焦阶段内使用了通过对成本量的条带进行上采样创建的掩码md。换句话说,重聚焦阶段是使用成本量而不是估计的深度图/视差图d执行的。与估计深度图/视差图的流水线相比,这有利于减少流水线的处理步骤。
流水线1104的重聚焦阶段通过执行步骤1210至1214来执行。这些步骤使用在步骤1208中生成的掩码1114和输入图像i执行。在该示例中,输入图像是元组的一对图像中的一个图像,即一对图像1106中的一个图像。
对与生成的掩码关联的多个平面中的每个平面执行步骤1210-1212。如上所述,这些平面可以是视差平面或深度平面。
在步骤1210中,根据输入图像和为该平面生成的掩码md生成平面d的掩码图像。掩码图像表示为id。掩码图像可以通过将掩码与输入图像i相乘来生成。掩码图像在图像11中以1116示出。
在步骤1212中,使用模糊核kr重聚焦掩码图像id,以生成重聚焦的分图像
然后,如上所述将重聚焦的分图像
在对每个平面执行步骤1210和1212后,以上述方式在步骤1214中生成重聚焦图像o。重聚焦图像在1120处示出。
在步骤1216中,估计重聚焦图像1120与元组的训练图像之间的差值。然后,将估计的差值反馈回深度估计阶段,并用于调整图像处理模型(步骤1218)。
本文描述了重聚焦输入图像的可微方法,这些方法使得能够形成可通过机器学习技术学习的用于重聚焦输入图像的流水线。在本文的一些示例中,流水线在深度估计阶段与重聚焦阶段之间产生深度图/视差图,使得估计的深度图能够通过合适的深度学习技术来改良。可以使本文描述的方法和流水线在计算上高效和易于处理,从而使它们能够部署在各种计算架构(例如智能手机架构)中。此外,本文描述的重聚焦图像的方法产生了由图像的深度信息驱动的散景(bokeh),该散景可以提供比其它类型的模糊(如高斯模糊)质量更高的结果。本文所述的技术还使得重聚焦图像能够以任意等效孔径大小或焦平面呈现,例如通过合适地设置等式(1)中的参数。
虽然本文已经描述了在使用stereonet执行深度估计的流水线内实现重聚焦阶段的示例,但应理解,这仅用于说明目的,并且本文描述的重聚焦的方法不依赖于正在使用的特定类型的深度估计。由此可见,本文描述的重聚焦阶段可以用各种深度学习技术实现,以形成可学习的流水线,并且不限于用stereonet流水线实现。
本文描述的图像处理设备可以用于执行本文描述的任何方法。通常,上述任何方法、技术或组件都可以以软件、硬件或其任何组合实现。术语“模块”和“单元”通常可用于表示软件、硬件或其任何组合。在软件实现的情况下,模块或单元表示在处理器中执行时执行指定任务的程序代码。本文所述的任何算法和方法都可以由一个或多个处理器执行,所述一个或多个处理器执行使一个或多个处理器执行算法/方法的代码。代码可以存储在非瞬时性计算机可读存储介质中,例如随机存取存储器(random-accessmemory,ram)、只读存储器(read-onlymemory,rom)、光盘、硬盘存储器和其它存储设备。代码可以是任何合适的可执行代码,例如计算机程序代码或计算机可读指令。
申请人在此单独公开本文所述的每一个体特征及两个或两个以上此类特征的任意组合。以本领域技术人员的普通知识,能够根据本说明书将此类特征或组合作为整体实现,而不考虑此类特征或特征的组合是否能解决本文所公开的任何问题。鉴于上文描述,可在本发明的范围内进行各种修改对本领域技术人员来说是显而易见的。
- 还没有人留言评论。精彩留言会获得点赞!