内容的分类方法及分类模型的生成方法与流程
本发明的一个方式涉及一种利用计算机设备的内容分类方法、内容分类系统、分类模型的生成方法以及图形用户界面。
另外,本发明的一个方式涉及一种计算机设备。本发明的一个方式涉及一种利用计算机设备的电子化内容(文字数据、图像数据、音频数据或视频数据)分类方法。尤其是,本发明的一个方式涉及一种利用机械学习基于内容集合高效地进行分类的内容分类系统。另外,本发明的一个方式涉及一种利用计算机设备使用程序管理的图形用户界面的内容分类方法、内容分类系统以及分类模型的生成方法。
背景技术:
用户想从内容集合容易分类并提取与用户所指定的题目有关的信息。但是,当从大量内容中分类符合目的条件的内容时,基于个人的知识或经验等而内容分类结果有差异。
近年来,有如下提案:将根据个人的知识或经验分类的内容分类结果作为监督数据提供给计算机设备,使其机械学习内容分类方法。例如,专利文献1公开了用来决定与用户所指定的题目之间的相关性高的文档的机械学习的研究。
[先行技术文献]
[专利文献]
[专利文献1]日本专利申请公开第2009-104630号公报
技术实现要素:
发明所要解决的技术问题
有时按照目的对某个内容集合进行分类。在本发明的一个方式中,说明内容为专利的情况。专利都被分配特有的专利号。因此,以下有时将内容换称为专利号而进行说明。注意,在本发明的一个方式中说明的内容分类方法中,着眼于分配到专利号的多个管理参数。注意,内容不局限于专利文献。内容也可以是文字数据、图像数据、音频数据或视频数据等信息。
利用各种元信息管理内容。元信息不是指某个内容本身,而是记述该内容所属的属性或相关信息的数据。作为一个例子,将权利要求书、说明书摘要、附图及说明书作为内容之内容与专利号相关联。并且,专利号被添加元信息(评价信息、经过天数、同族信息等)并使用元信息受管理。通过利用元信息进行基于重要性的专利号分类。分类的精度或效率根据作为对象的文件的内容而不同但是易于产生基于用户的经验或熟练程度的差异,并且需要对大量文件进行分类,因此在效率化方面有问题。
在利用机械学习的分类模型的生成中,需要准备大量的学习数据,因此有用户的负担过重的问题。有包括在学习数据中的分类内容数量的不均匀给分类模型的精度带来影响的问题。
鉴于上述问题,本发明的一个方式的目的之一是提供一种高效地生成分类模型且使用其进行信息分类的方法。另外,本发明的一个方式的目的之一是提供一种用来交互地生成分类模型的图形用户界面。另外,本发明的一个方式的目的之一是提供一种进行概率高的信息的分类的程序。
注意,这些目的的记载不妨碍其他目的的存在。本发明的一个方式并不需要实现所有上述目的。此外,上述以外的目的是可以从说明书、附图及权利要求书等的记载中自然得知并衍生出来的。
解决技术问题的手段
计算机设备所包括的存储装置储存有程序。程序可以通过图形用户界面(以下,gui)使计算机设备所包括的显示装置显示各种信息。此外,用户可以通过gui使计算机设备进行程序的操作、信息添加、响应数据库、机械学习的指令等。另外,程序可以通过gui将利用机械学习的运算处理结果、从数据库下载的学习内容或未分类内容的内容等显示在显示装置上。注意,以下,简单地记载为“内容”的情况下,包括学习内容、未分类内容或已分类内容。
所提案的内容分类系统利用机械学习生成内容的分类模型,利用所生成的内容的分类模型对未分类内容进行分类。例如,将包括多个元信息的内容作为学习内容。而且,当学习内容被添加学习标签时从学习内容生成特征向量。注意,在生成特征向量的情况下,可以将元信息或学习标签用作学习内容的特征量。
学习内容被用作监督数据。分类模型可以基于学习内容进行机械学习来取得。在此得到的分类模型进行包括多个元信息的内容的分类。根据用户的目的分类种类可以是两种,也可以是三种以上。与通过手工或目视进行所有文件的判断的情况相比,用户通过利用分类模型可以以更短的时间进行整个文件的分类。
可以从储存在数据库中的学习内容下载学习内容。或者,可以使用储存在计算机设备的存储装置中的学习内容。注意,学习内容也可以包括学习标签而受管理。并且,也可以下载储存在数据库中的分类模型。或者,也可以使用储存在计算机设备的存储装置中的分类模型。
本发明的一个方式是一种内容分类方法,包括学习内容及内容,给学习内容添加第一特征量及学习标签,给内容添加第二特征量,并且包括如下步骤:通过机械学习利用多个学习内容生成多个第一分类模型的步骤;利用多个第一分类模型生成第二分类模型的步骤;以及利用第二分类模型给多个内容添加判定信息且将其显示在图形用户界面上的步骤。
本发明的一个方式是一种内容分类方法,包括学习内容及内容,给学习内容添加第一特征量及学习标签,给内容添加第二特征量,并且包括如下步骤:通过机械学习利用多个学习内容生成多个第一分类模型的步骤;从多个第一分类模型的输出计算出平均值的步骤;利用多个平均值生成第二分类模型的步骤;以及利用第二分类模型给多个内容添加判定信息且将其显示在图形用户界面上的步骤。
本发明的一个方式是一种内容分类方法,包括学习内容及内容,给学习内容添加第一特征量及学习标签,给内容添加第二特征量,并且包括如下步骤:通过机械学习利用多个学习内容生成多个第一分类模型的步骤;多个第一分类模型中的每一个基于第一评价标准进行评价的步骤;多个第一分类模型中的每一个基于第二评价标准进行评价的步骤;根据基于多个第一评价标准的评价结果和基于第二评价标准的评价结果生成第二分类模型的步骤;以及利用第二分类模型给多个内容添加判定信息且将其显示在图形用户界面上的步骤。
在具有上述各结构的内容分类方法中,优选第一评价标准为精度(precision)且第二评价标准为灵敏度(sensitivity)。
在具有上述各结构的内容分类方法中,优选包括利用任意学习内容生成第一分类模型的步骤。
在具有上述各结构的内容分类方法中,优选的是,学习内容还被添加分类信息,包括利用第二分类模型的输出从添加有分类标签的多个内容中选择包括与分类信息相同的判定信息的内容且将其显示在图形用户界面上的步骤。
在具有上述各结构的内容分类方法中,添加到学习内容及内容的特征量优选为管理参数。
在具有上述各结构的内容分类方法中,判定信息优选包括分类标签或分数。
在具有上述结构的内容分类方法中,优选的是,包括图形用户界面指定分数中的特定数值范围并列出显示相应内容的步骤。
发明效果
本发明的一个方式可以提供一种以高精度进行信息分类的方法。另外,本发明的一个方式可以提供一种以高精度进行信息分类的用户界面。另外,本发明的一个方式可以提供一种以高精度进行信息分类的程序。
另外,本发明的一个方式可以给用户提供一种用来生成利用机械学习的分类模型的交互式界面,可以减轻监督数据的准备或学习结果的评价等用户的负担。
注意,本发明的一个方式的效果不局限于上述效果。上述效果并不妨碍其他效果的存在。另外,其他效果是上面没有提到而将在下面的记载中进行说明的效果。所属技术领域的普通技术人员可以从说明书或附图等的记载中导出并适当抽取上面没有提到的效果。注意,本发明的一个方式具有上述效果及/或其他效果中的至少一个效果。因此,本发明的一个方式根据情况有时不具有上述效果。
附图说明
图1是说明分类方法的流程图。
图2是说明分类方法的流程图。
图3是说明分类系统100与网络的连接的图。
图4是说明分类系统的方框图。
图5a及图5b是说明图形用户界面的图。
图6是说明分类模型的生成方法的图。
图7是说明分类模型的生成方法的图。
图8是说明分类模型的生成方法的图。
图9是说明图形用户界面的图。
图10是说明图形用户界面的图。
具体实施方式
在本实施方式中,使用图1至图10说明内容分类方法。
在本实施方式中说明的内容分类方法由在计算机设备中工作的程序控制。程序储存在计算机设备的存储器(memory)或者存储空间(storage)中。或者,程序储存在通过网络(lan(localareanetwork:局部网)、wan(wideareanetwork:广域网)、因特网等)而连接的计算机或包括数据库的服务器计算机中。
此外,在计算机设备所包括的显示装置上可以显示用户给程序提供的数据以及利用计算机设备所包括的运算装置的该数据的运算结果。注意,使用图4将详细说明设备的结构。
例如通过采用列出显示方式,用户容易确认显示在显示装置上的数据,操作性得到提高。因此,在说明中,将gui作为用户为通过显示装置简单地与计算机设备所包括的程序交互而使用的界面。
用户可以通过gui利用程序所具有的内容分类方法。用户可以利用gui使内容分类操作简单。另外,用户可以通过gui在视觉上容易对内容分类结果进行判断。另外,用户可以通过gui简单地操作程序。此外,该内容是指文字数据、图像数据、音频数据或视频数据等的信息。
接着,按照gui的操作步骤说明使用gui的内容分类方法。首先,说明数据处理部。数据处理部包括数据采集部和数据生成部。例如,数据采集部通过gui从数据库取得由多个内容构成的文件。另外,当用户通过gui给内容添加学习标签时,数据生成部可以生成学习内容。或者,也可以从数据库中取得添加有学习标签的学习内容。多个内容是指储存在计算机设备的存储器或存储空间中的文件或者储存在连接到网络的数据库、计算机或数据服务器等中的数据。
因此,该数据库中优选储存有列出的多个学习内容或多个未分类内容。另外,学习内容及未分类内容添加有多个特征量和学习标签。用户可以通过gui修改该学习标签。当将该学习标签添加到学习内容时,可以将被添加学习标签的学习内容储存在数据库中。
学习内容可以包括没有添加学习标签的验证内容。可以将验证内容用于使用学习内容生成的分类模型的验证。
作为一个例子,对内容为专利号的情况进行说明。作为专利号的特征量给专利号添加多个元信息。作为元信息例如有评价信息、经过天数、同族数量、同族的状态、申请类型、有效期限、同族中的待授权专利数量、同族中的放弃专利数量、费用、发明人人数、领域或权利要求数量等。就是说,元信息是指内容的管理参数。注意,同族包括专利家族或专利族等。
接着,说明学习处理部。学习处理部包括利用学习内容生成分类模型的步骤。学习处理部包括分类模型生成部或分类模型评价部。
分类模型生成部可以生成分类模型。分类模型生成部具有通过机械学习利用多个学习内容生成多个第一分类模型的步骤,并具有利用该多个第一分类模型生成第二分类模型的步骤。可以在gui上显示第一分类模型或第二分类模型的输出值。用户可以给该输出值添加(包括修改)对应于第一分类模型的学习标签。或者,用户可以给该输出值添加新的学习内容。
分类模型评价部利用验证内容对分类模型生成部中生成的分类模型进行评价。当利用该分类模型进行验证内容的推论时,该分类模型将推论结果作为判定信息输出。gui可以给各评价内容添加判定信息进行显示。
此外,用户可以对分类模型评价部的输出结果进行判定,根据需要修改学习标签,在分类模型生成部中更新分类模型。或者,可以通过追加学习内容在分类模型生成部中更新分类模型。
接着,说明判定处理部。判定处理部包括分类推论部和列表创建部。例如,分类推论部利用在分类模型生成部中生成的第一学习模型和第二学习模型进行多个未分类内容的推论及分类。该分类模型给各内容添加推论结果作为判定信息。
列表创建部可以使用被添加该判定信息的内容生成用户所要求的形式的列表,将其显示在gui上。例如,在根据专利申请国别管理各内容的情况下,可以将专利申请国用作分类信息。在专利申请国为分类信息的情况下,作为所生成的分类模型优选根据专利申请国别生成不同分类模型。注意,分类信息不局限于专利申请国。例如,可以将内容所包括的元信息之一用作分类信息。
对元信息为分类信息的情况进行说明。例如,也可以将专利家族的状态作为分类信息。专利号有时被添加原申请的专利号、分案申请的专利号等作为元信息。根据从原申请的专利号可以衍生出分案申请的状态、从原申请的专利号不能衍生出分案申请的状态、原申请的专利号的权利有效的状态、原申请的专利号的权利失效的状态、从分案申请的专利号可以再衍生出分案申请的状态、从分案申请的专利号不能再衍生出分案申请的状态、分案申请的专利号的权利有效的状态、分案申请的专利号的权利失效的状态等,可以生成不同分类模型,利用该分类模型可以分别进行推论。
就是说,判定处理部可以利用分类模型对多个未分类内容进行推论。判定处理部包括将推论结果作为判定信息添加到各内容且将其显示在gui上的步骤。判定信息至少包括分类标签、分数(概率)。另外,包括gui指定分数中的特定数值范围且列出显示相应内容的步骤。
示出与上述分类模型生成部不同的例子。分类模型生成部包括通过机械学习利用多个学习内容生成多个第一分类模型的步骤、从该多个第一分类模型的输出计算出平均值的步骤、以及利用多个该平均值生成第二分类模型的步骤。可以在gui上显示第一分类模型或第二分类模型的输出值。用户可以基于该输出值修改第一分类模型的学习标签。或者,用户可以给该输出值添加学习内容。注意,该平均值是指利用算术平均计算、几何平均计算和调和平均计算中的任一个而计算出的值。
第二分类模型利用多个该平均值而生成。因为第二分类模型中第一分类模型的输出平均化,所以可以减轻学习内容中的离群值等噪声成分的影响。
接着,示出与上述分类模型生成部不同的例子。分类模型生成部包括通过机械学习利用多个学习内容生成多个第一分类模型的步骤、多个第一分类模型中的每一个基于第一评价标准进行评价的步骤、多个第一分类模型中的每一个基于第二评价标准进行评价的步骤、以及根据基于多个第一评价标准的评价结果和基于第二评价标准的评价结果生成第二分类模型的步骤。可以在gui上显示第一分类模型或第二分类模型的输出值。用户可以基于该输出值修改第一分类模型的学习标签。或者,用户可以给该输出值添加学习内容。注意,第一评价标准为混淆矩阵的精度,第二评价标准为混淆矩阵的灵敏度。
利用基于第一评价标准及第二评价标准对多个第一分类模型的输出进行评价而得的结果生成第二分类模型。注意,在第一评价标准中,可以将混淆矩阵的精度换称为对学习标签的精确率。在第二评价标准中,可以将混淆阵列的灵敏度换称为学习标签的召回率。因此,所生成的分类模型可以包括多个第一分类模型的该精确率和该召回率。利用该多个第一分类模型生成的第二分类模型的分类精度得到提高。
在上述分类模型生成部中,例如,也可以利用所生成的m个(m表示自然数)第一分类模型生成第二分类模型。
另外,当上述分类模型生成部包括k个(k表示自然数)学习内容时,第一分类模型可以生成k个以下的任意学习内容。另外,在k个学习内容被选择的情况下,任意学习内容可以包括两个不同学习模型。另外,按号码排序的顺序使用k个分配有不同号码的学习内容中的每q个(q表示自然数)生成第一分类模型。
程序可以将从数据库读取的内容显示在gui上。内容优选包括列出的元信息。gui以gui所具有的显示方式显示该内容。注意,添加到内容的列出的元信息优选以被称为记录的单位管理。例如,各记录由绑定到号码的id(identification)、内容(图像数据、音频数据或视频数据)或元信息等构成。
在本说明书中,着眼于元信息而进行机械学习,通过该机械学习生成分类模型。分类模型分析元信息并对特征向量化的内容进行分类。
另外,在上述内容分类方法中,可以通过不使用学习标签作为监督数据的机械学习进行分类。例如,作为分类模型可以使用k-means或dbscan(具有噪声的基于密度的聚类方法)等算法。
另外,程序可以通过利用添加有多个元信息及学习标签的学习内容的机械学习生成分类模型。作为分类模型可以使用决策树、朴素贝叶斯、knn(k最近邻)、svm(支持向量机)、感知机、逻辑回归或神经网络等算法。
并且,程序可以根据学习内容数量切换分类模型。例如,在学习内容数量较少时,也可以使用决策树、朴素贝叶斯或逻辑回归,在学习内容数量为一定量以上时,也可以使用svm、随机森林或神经网络。本实施方式中使用的分类模型采用决策树的算法之一的随机森林。并且,作为元信息的选择方法、学习内容的选择方法或第一分类模型的选择方法可以使用随机取样或交叉验证。或者,可以根据分配号码的排序顺序按每q个进行选择。
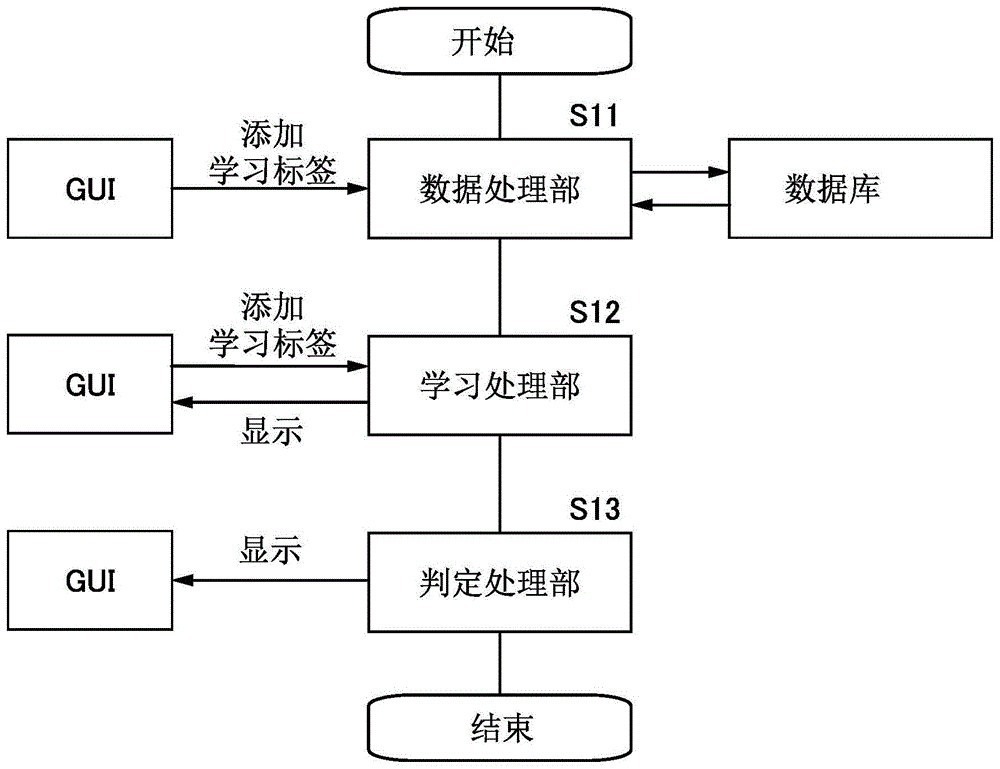
接着,使用附图说明内容分类方法。图1是说明本实施的一个方式的内容分类方法的流程图。注意,内容分类方法由在计算机设备中工作的程序控制。因此,通过程序包括数据处理部、学习处理部或判定处理部,可以进行内容分类。程序可以通过gui进行用户所要求的内容分类。就是说,在上述各处理部中被处理的内容相当于程序的步骤。
步骤s11中用户可以通过gui发出加载包括内容的文件的指令。该文件储存在数据处理部所包括的数据库中。文件包括学习内容、未分类内容等。
因此,该数据库中优选储存有列出的多个学习内容或多个未分类内容。用户可以添加或修改显示在gui上的学习内容的学习标签。文件可以包括没有添加学习标签的验证内容。
步骤s12是利用加载文件生成分类模型的学习处理部。所生成的分类模型可以对验证内容进行评价,可以将评价结果显示在gui上。用户可以发出基于该评价结果修改学习标签、追加学习内容等指令。
此外,用户可以预测学习内容所包括的元信息的随时间的变化来更新元信息。当用户更新元信息时,分类模型可以包括分类模型的随时间的变化。因此,用户可以得到内容的随时间的分类变化。分类模型可以将预测为价值增加的内容群和预测为价值下降的内容群分类。
步骤s13是判定处理部。使用步骤s12中生成的分类模型对未分类内容进行推论。该分类模型可以根据推论结果给未分类内容添加判定信息。在判定处理部中,可以以用户所要求的形式将该被添加判定信息的内容显示在gui上。该判定信息至少包括分类标签及分数。另外,gui可以指定分数中的特定数值范围且显示相应内容。
接着,使用图2更详细地说明图1的流程图。首先,详细地说明步骤s11。步骤s11的数据处理部包括步骤s21的数据采集部及步骤s22的数据生成部。
说明步骤s21的数据采集部。步骤s21的数据采集部可以从数据库中加载文件。元信息或内容等可以利用不同数据库管理。元信息可能根据处理内容的公司、组织或用户而不同。因此,数据采集部具有从不同数据库中采集与内容有关的元信息的功能。另外,各数据库可以设置在不同建筑物、不同地区或不同国家中。
接着,说明步骤s22的数据生成部。数据生成部可以以被称为记录的单位管理内容和元信息。例如,各记录由绑定到号码的id、内容(图像数据、音频数据或视频数据)或元信息等构成。另外,用户可以通过给显示在gui上的内容添加学习标签来生成学习内容。
接着,详细地说明步骤s12。步骤s12的学习处理部包括步骤s23的分类模型生成部、步骤s24的分类模型评价部及步骤s25的输出结果判定处理。
说明步骤s23的分类模型生成部。分类模型生成部可以生成内容的分类模型。分类模型生成部可以通过机械学习利用多个学习内容生成多个第一分类模型。可以利用该多个第一分类模型生成第二分类模型。可以在gui上显示第一分类模型或第二分类模型的输出值。
此外,在后述的步骤s25的输出结果判定处理之后,用户可以给该输出值添加(包括修改)第一分类模型的学习标签。或者,用户可以给该输出值添加新的学习内容。用户可以预测学习内容所包括的元信息的随时间的变化来更新元信息。注意,在用户更新元信息时得到的效果可以参照步骤s12的说明。
接着,说明步骤s24的分类模型评价部。分类模型评价部可以利用验证内容对分类模型生成部中生成的分类模型进行评价。该分类模型将验证内容的推论结果作为判定信息输出。gui可以给各评价内容添加判定信息进行显示。
接着,说明步骤s25的输出结果判定处理。例如,用户可以对步骤s24的分类模型评价部的输出结果进行判断且判定为内容的分类模型学好了。用户向gui发出分类模型的生成结束(ok)的指令。例如,用户可以判定为内容的分类模型的学习不够(ng)。用户返回到步骤s23,通过学习标签的变更、学习内容的追加或元信息的更新等进行分类模型的更新。
接着,详细地说明步骤s13。步骤s13的判定处理部包括步骤s26的分类推论部及步骤s27的列表创建部。
说明步骤s26的分类推论部。分类推论部利用在分类模型生成部中生成的第一学习模型和第二学习模型进行多个未分类内容的推论及分类。对分类推论部添加在步骤s22的数据生成部中生成的未分类内容。该分类模型给各内容添加推论结果作为判定信息。
说明步骤s27的列表创建部。列表创建部可以以用户所要求的形式列出该被添加判定信息的内容,将其显示在gui上。各内容也可以被添加与元信息不同的分类信息。例如,当将分类信息添加到学习内容时,所生成的分类模型可以根据分类信息生成不同分类模型。或者,可以将内容所包括的元信息之一用作分类信息。
该判定信息至少包括分类标签及分数。另外,gui可以指定分数中的特定数值范围且将相应内容列出显示在gui上。
图3是说明有上述内容分类方法的分类系统100与网络的连接的图。
分类系统100与通信网lan1连接。通信网lan1连接有数据库db1或客户端计算机cl1至cln(n是自然数)等。另外,通信网lan1可以通过网络与通信网lan2连接。作为网络可以使用因特网、通信网wan或卫星通信。通信网lan2连接有数据库db2或客户端计算机cl11至cl1n等。
分类系统100可以利用包括储存在数据库db1、数据库db2、客户端计算机cl1至cln或客户端计算机cl11至cl1n中的内容的文件进行内容生成、内容分类、模型生成以及未分类内容分类。
另外,用户可以利用在分类系统100中工作的程序向gui发出指令。例如,用户可以通过因特网利用设置在不同国家中的数据库中的信息生成上述分类模型,对未分类内容进行分类。就是说,内容或元信息也可以储存在不同数据库或不同客户端计算机中。
可以在gui上显示储存在数据库db1、数据库db2、客户端计算机cl1至cln或客户端计算机cl11至cl1n的计算机设备的存储装置中的被分类系统100分类的分类结果。
图4是说明在图3中说明的分类系统100的方框图。分类系统100包括gui(图形用户界面)110、运算部120及存储部130。gui110包括输入部111及输出部112。输入部111具有选择内容的加载源的功能以及输入学习标签的功能。输出部112具有显示从数据库等中加载的内容列表的功能以及显示分类模型所输出的判定信息的功能。注意,用户可以通过gui修改包括在显示内容中的元信息。
运算部120包括数据处理部121、学习处理部122及判定处理部123。数据处理部121包括数据采集部及数据生成部。学习处理部122包括生成分类模型的分类模型生成部以及将分类模型分类的分类模型评价部。另外,分类模型评价部的输出结果具有由用户判定的评价结果判定处理功能。判定处理部123具有分类推论部、列出由分类推论部分类的结果的输出列表创建部。在运算部120中,储存在计算机设备所包括的存储部中的程序使用微处理器进行运算处理。程序可以利用dsp(数字信号处理器)或gpu(图形处理器)进行运算处理。
在存储部130中,以列表形式暂时储存从数据库等中加载而生成的内容及元信息。
存储部130例如可以使用包括1t(晶体管)1c(电容器)型存储单元的dram(动态随机存取存储器)。另外,作为用于dram的存储单元的晶体管也可以使用os晶体管。os晶体管是在半导体层中包含金属氧化物的晶体管。将在存储单元中使用os晶体管的存储装置称为“os存储器”。在此,作为os存储器的一个例子,将包括1t1c型存储单元的ram称为“dosram(dynamicoxidesemiconductorram:动态氧化物半导体随机存取存储器)”。
os晶体管的关态电流(off-statecurrent)非常小。由此dosram可以减少刷新频率,而可以降低刷新工作所需要的功率。这里的关态电流是指在晶体管处于关闭状态时在源极和漏极之间流过的电流。在晶体管为n沟道型的情况下,例如当阈值电压为0v至2v左右时,可以将栅极和源极之间的电压为负电压时流在源极和漏极之间的电流称为关态电流。
图5a是说明gui30的结构的图。gui30作为一个例子显示列出显示p个学习内容的管理页面。学习内容以记录单位受管理。该记录包括号码(no)31、内容(id)32、表示特征量的元信息(feature)33(元信息(f1)33a至元信息(fm)33m)、分类信息(case)34(分类信息(c1)34a至分类信息(cq)34q)以及学习标签(j-label)35等。作为一个例子,图5a中学习标签35提供“yes”和“no”这二值中的任意值,学习标签35不局限于二值,也可以是三值以上。
图5b是说明gui30a的结构的图。gui30a在评价推论部中进行n个未分类内容的推论,显示列出显示该推论判定信息的管理页面。未分类内容与学习内容同样地包括号码31、内容32、元信息33及分类信息34。并且,各记录被添加分类标签(a-label)36及分数(score)37作为判定信息。
gui30及gui30a可以在同一显示页面上管理。在后述的图9或图10中,示出可以在同一管理页面上显示学习内容和判定信息的gui的显示例子。
图6是说明通过机械学习利用与上述学习内容sample相关联的多个特征feature生成分类模型的方法的图。各特征feature表示任一个元信息,并相当于用来管理内容的管理参数。注意,在本实施的一个方式中,利用运算部f、运算部s、运算部v、第一分类模型及第二分类模型说明分类模型生成方法。
学习内容sample(1)至学习内容sample(k)都被添加j个特征feature及学习标签label。作为一个例子,运算部f1可以从学习内容sample(1)生成计算机能够处理的形式的特征向量vlabel1(1)。另外,运算部fk可以从学习内容sample(k)生成计算机能够处理的形式的特征向量vlabel1(k)。另外,特征向量vlabel1(1)可以通过运算部f1对各特征给予不同权系数来生成。另外,特征向量vlabel1(1)可以使用随机选择的j个以下的特征feature生成。
接着,生成多个第一分类模型。运算部s1至运算部sm分别相当于不同第一分类模型。作为一个例子,运算部s1可以利用特征向量vlabel1(1)至特征向量vlabel1(k)生成第一分类模型。提供到运算部s1的特征向量vlabel1只要是k个以下即可。作为不同例子,运算部sm可以利用与上述不同的特征向量vlabel1(1)至特征向量vlabel1(k)生成第一分类模型。因此,两个不同第一分类模型可以各自包括k个以下的特征向量vlabel1,并且其中特征向量vlabel1中的任一个是同一的。
为生成第一分类模型而选择的k个学习内容sample可以随机选择,也可以按分配给学习内容的号码排序的顺序选择。在随机选择学习内容的情况下,第一分类模型可以包括学习内容的不均匀。另外,在按分配给学习内容的号码排序的顺序选择的情况下,可以包括按基于时间序列和元信息中的任一个特征分配的号码的倾向。
因此,第一分类模型可以利用从学习内容sample(1)至学习内容sample(k)生成的特征向量vlabel1生成特征向量vlabel2。
第二分类模型由运算部v1生成。作为一个例子,运算部v1包括利用m个特征向量vlabel2生成第二分类模型的步骤。此外,第二分类模型可以通过利用特征向量vlabel2(1)至特征向量vlabel2(m)生成具有不同特征的分类模型。
因此,第二分类模型可以利用从学习内容sample(1)至学习内容sample(k)生成的特征向量vlabel1输出输出值pout。gui可以显示输出值pout。此外,输出值pout包括为判定信息的分类标签及分数。因此,第二分类模型可以进行内容分类。此外,第二分类模型可以给各内容添加判定信息。
在利用图6中说明的该分类模型进行推论时,通过给该分类模型的学习内容sample添加未分类内容,得到判定结果。注意,与学习内容不同,未分类内容没有添加学习标签。
图7是说明不同于图6的分类模型的生成方法的图。在图7中说明与图6的不同点,在发明的结构(或实施例的结构)中,在不同的附图中共同使用相同的附图标记来表示相同的部分或具有相同功能的部分,而省略反复说明。
在图7中,计算出m个特征向量vlabel2的平均值av,生成特征向量vlabel_a。第二分类模型可以利用p个特征向量vlabel_a生成。第二分类模型可以通过计算出m个特征向量vlabel2的平均值av而生成具有不同特征的分类模型。所生成的分类模型可以使内容分类更加准确。
图8是说明不同于图7的分类模型的生成方法的图。在图8中说明与图7的不同点,在发明的结构(或实施例的结构)中,在不同的附图中共同使用相同的附图标记来表示相同的部分或具有相同功能的部分,而省略反复说明。
在图8中,将用来评价m个特征向量vlabel2的评价标准提供到评价判定部jg。例如,向评价判定部jg1作为第一评价标准提供精度(precision),可以进行各特征向量vlabel2(1)的评价。接着,向评价判定部jg1作为第二评价标准提供灵敏度(sensitivity),可以进行各特征向量vlabel2(1)的评价。评价判定部jg1输出评价结果vlabel_b(1)。
第二分类模型利用评价结果vlabel_b(1)至评价结果vlabel_b(p)生成。例如,多个特征向量vlabel2可以基于不同的第一评价标准及第二评价标准被评价,也可以基于相同的评价标准被评价。注意,虽然在图8中未图示,但是可以与图7同样地计算出基于第一评价标准及第二评价标准的评价结果vlabel_b的平均值。
第二分类模型可以通过使用m个特征向量vlabel2的评价结果而生成具有不同特征的分类模型。所生成的分类模型可以使内容分类更加准确。
图9是说明gui50的图。gui50具有内容(学习内容、未分类内容、已分类内容)的显示区域、选择包括内容的文件的下载源的图标58a、显示储存被选择的文件的地址信息的文本框58b以及执行机械学习的图标(learningstart)59。
作为一个例子示出在显示区域上加载八个记录的例子。各记录包括号码(no)51、id(index)52、特征量(feature)53、分类信息(case)54、学习标签(jl)55、分类标签(al)56及分数(prob)57等构成要素。特征量53可以作为详细信息显示特征量f(1)53a至特征量f(j)53j。j是自然数。另外,分类信息54可以作为详细信息显示分类信息c(1)54a至分类信息c(4)54d。分类信息可以有能够用自然数表示的种类。
此外,图9示出在gui50上显示由分类模型将学习内容和未分类内容分类的结果的例子。
作为一个例子,记录号码no1至no3相当于学习内容。学习内容被添加学习标签,记录号码no1至no3被添加分类信息。
记录号码no4至no8相当于已分类内容。已分类内容被添加分类标签56及分数57。在图9中,显示利用通过学习记录号码no1及记录号码no3来得到的分类模型将记录号码no4至记录号码no7分类的结果。作为一个例子,显示利用通过学习记录号码no2来得到的分类模型进行记录号码no8的分类的结果。在图9中,由于空间的关系仅显示八个记录,但是也可以处理多种记录。
但是,在处理大量的记录的情况下,在显示上有问题。因此,分类标签56或分数57优选具有排序功能。作为排序条件的一个例子,在gui上可以选择并显示分类标签56为“yes”的判定结果。另外,gui可以指定并显示分数57的数值范围。当向gui提供上述排序条件时,gui可以将具有与添加监督数据的学习内容同样的特征的内容分类并显示。
例如,说明内容为专利号的情况。专利号被添加多个元信息。在是权利有效的专利号的情况下,作为学习标签提供“yes”。在是专利权放弃的专利号的情况下,作为学习标签提供“no”。接着,执行机械学习生成分类模型。
上述分类模型可以给未分类内容添加判定信息。作为判定信息显示分类标签56及分数57。作为一个例子,用户利用排序功能作为分类标签56提供“no”。并且,将分数57设定为“0.8”至“1.0”。通过向gui提供上述排序条件,gui可以选择并显示具有与专利号被放弃的学习内容同样的特征的记录。
图10是说明不同于图9的gui50a的图。图10是在处理大量记录时有效率的gui的显示例子。注意,在图10中说明与图9的不同点,在发明的结构(或实施例的结构)中,在不同的附图中共同使用相同的附图标记来表示相同的部分或具有相同功能的部分,而省略反复说明。
图10的与图9的不同之处在于:可以按与任意选择的分类信息有关的记录进行分类及显示。在图10中,可以根据分类信息c(1)至分类信息c(4)的种类切换显示。
用户确认添加到记录的多个特征量53及分类模型的判定信息,得到十分的分类精度就结束分类模型的更新。在用户确认添加到记录的判定信息判断为分类精度不十分的情况下,用户给没有添加指定标签的记录添加学习标签并点击图标59,由此可以更新分类模型。此外,也可以预测学习内容所包括的元信息的随时间的变化,更新特征量53。在用户更新特征量53时,分类模型可以包括分类模型的随时间的变化。因此,用户可以得到内容的随时间的分类变化。分类模型可以将预测为价值增加的内容群和预测为价值下降的内容群分类。
虽然未图示,但是也可以改变特征量53、分类信息54a至分类信息54d、学习标签55、分类标签56或分数57所包括的数值或标签信息的显示排列顺序。或者,可以利用筛选功能按所需要的排列顺序进行排序来显示所选择的数值或标签信息。由此,用户可以高效地进行分类模型的判定结果的评价。
使用图1至图10说明的内容分类方法可以提供一种概率高的信息的分类方法。例如,gui适合于概率高的信息的分类。程序可以在分类模型被提供新的监督数据(学习标签)时更新分类模型。程序在更新分类模型时可以进行概率高的信息分类。
并且,可以将所生成的分类模型储存在电子设备主体或外部存储器中,在新的文件分类时调用并使用。并且,在追加新的监督数据的同时,可以按照上述说明的方法更新分类模型。
以上,本实施方式所示的结构、方法可以与其他实施方式所示的结构、方法适当地组合而使用。
[符号说明]
cl1:客户端计算机、cl1n:客户端计算机、cl11:客户端计算机、cln:客户端计算机、db1:数据库、db2:数据库、lan1:通信网、lan2:通信网、vlabel1:特征向量、vlabel2:特征向量、31:号码、32:内容、33:元信息、34:分类信息、35:学习标签、50:gui、50a:gui、51:号码、53:特征量、54:分类信息、56:分类标签、57:分数、58a:图标、58b:文本框、59:图标、100:分类系统、110:gui、111:输入部、112:输出部、120:运算部、121:数据处理部、122:学习处理部、123:判定处理部、130:存储部。
- 还没有人留言评论。精彩留言会获得点赞!