一种增强协同推荐系统鲁棒性的方法与流程
本发明提出了一种新的消费者-生产者推荐对抗训练解决方案,它是一种更健壮、更广义的用户生成内容推荐系统模型。目标是攻击和防御目标输入参数,提高鲁棒性和推荐系统性能,具体涉及一种增强协同推荐系统鲁棒性的方法。
背景技术:
随着用户生成内容平台的日益普及,大量的用户行为数据正以越来越大的规模不断生成。研究具有流数据输入的推荐系统具有重要的意义。一方面,必须克服用户生成内容推荐系统的挑战,比如处理大型、稀疏的数据集。另一方面,也出现了一些新的挑战,比如需要根据内容的三元动态对内容进行建模,比如对独立于所创建的项目的特定生产者的偏好。最近关于用户生成内容推荐的研究主要集中在探索消费者、项目及其生产者之间的三元关系,以提高推荐性能。然而,到目前为止,还没有研究用户生成内容表示的健壮性及其对推荐性能的影响。本发明提出了一种增强协同推荐系统鲁棒性的算法。
技术实现要素:
为了克服对推荐系统中用户生成内容表示的健壮性及其对推荐性能的影响研究的缺乏,本发明提出了一种增强协同推荐系统鲁棒性的方法,将模型训练得不那么容易受到对抗性干扰,可以提高模型的鲁棒性和泛化能力。
本发明采用的技术方案为:
一种增强协同推荐系统鲁棒性的方法,包括以下步骤:
步骤1:获得用户生成内容平台中用户和产品之间的交互数据;
步骤2:用矩阵分解法获得消费者、生产者和产品的潜在向量表示;
用两个投影矩阵将一个用户的核心嵌入到她的两个角色嵌入中,两个角色为生产者和消费者的角色,其公式如下:
其中
步骤3:用偏置矩阵因子法构建消费者、生产者及产品的三元交互模型;
通过用户对产品的偏好和对产品生产者的欣赏程度的总和来模拟用户的消费行为,其公式如下:
其中xui表示用户给产品的预测得分,α表示全局偏置项,βu和βi分别表示用户和产品的偏置项,γi表示产品的潜在向量表示;
步骤4:在提出的偏好预测模型上,采用贝叶斯个性化排序bpr框架学习所有参数;
bpr是基于矩阵分解的一种排序算法,bpr定义了偏好评分之间的差异,其公式如下:
xuij=xui-xuj
其中xuij表示偏好评分之间的差异,xui表示用户u对感兴趣产品i的评分,xuj表示用户u对不感兴趣产品j的评分;
步骤5:通过最大化后验来优化排名,用随机梯度下降sgd训练模型直到收敛,初始化收敛参数;
损失函数通常作为学习准则与优化问题相联系,即通过最小化损失函数求解和评估,其公式如下:
其中lbpr表示使用bpr优化的损失函数,σ(·)表示sigmoid激活函数,β表示正则化超参数,
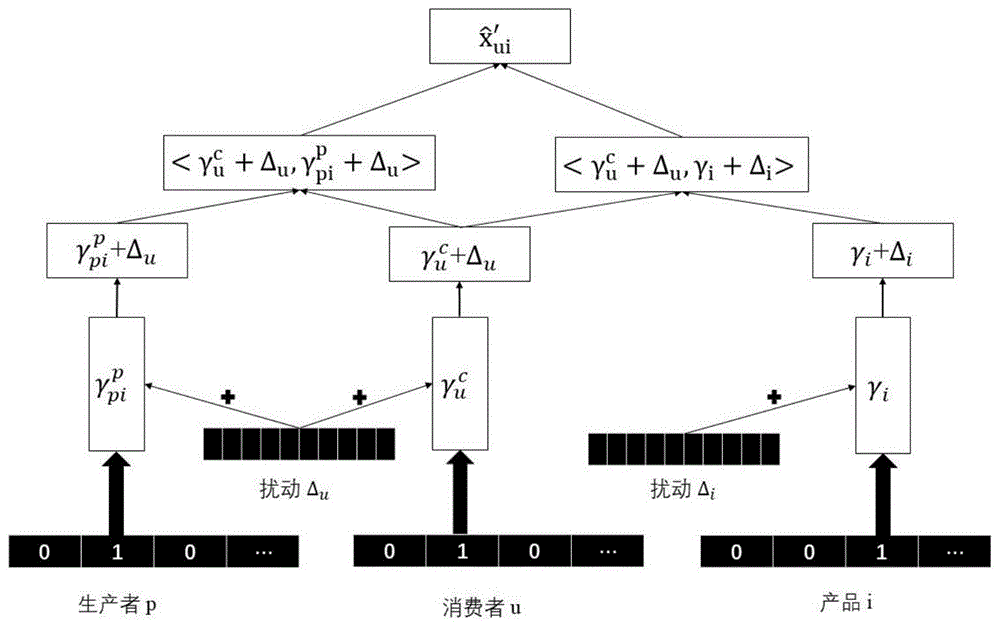
步骤6:对输入参数施加加性扰动,所述输入参数包括消费者、生产者和产品;
对抗性训练可以提高推荐模型的有效性,以改善ugc的推荐模式,通过这种方法,将模型训练得到不那么容易受到对抗性干扰,可以提高模型的鲁棒性(预测用户生成的偏好),其公式如下:
其中δu表示对用户的对抗性扰动,δi表示对产品的对抗性扰动;
步骤7:在施加了对抗扰动的模型上,重复步骤4;
步骤8:采用施加了对抗扰动的最小化损失函数,在初始化收敛参数基础上,用随机梯度下降sgd训练模型直到收敛;
为了获得对对抗扰动不太敏感的模型,除了最小化原始bpr损失之外,还应最小化对手的目标函数,其公式如下:
其中θ*表示对抗模型的优化函数,lbpr′表示施加了扰动的优化函数,
本发明的有益效果是:
1.这是第一项强调最先进的用户生成内容推荐系统漏洞问题的工作;
2.通过使用对抗性学习的最新发展,一种新方法被用于训练更健壮和有效的推荐者模型。
3.对代表性推荐任务进行了大量实验,以验证我们的方法。
附图说明
图1是协同推荐中消费者和生产者稳定性的方法框图;
图2是矩阵分解算法图;
图3是对抗学习算法图。
具体实施方式
下面结合附图对本发明的较佳实施例进行详细阐述,以使本发明的优点和特征能更易于被本领域技术人员理解,从而对本发明的保护范围做出更为清楚明确的界定。
参照图1~图3,一种增强协同推荐系统鲁棒性的方法,包括以下步骤:
步骤1:获得用户生成内容平台中用户和产品之间的交互数据;
步骤2:用矩阵分解法获得消费者、生产者和产品的潜在向量表示;
用两个投影矩阵将一个用户的核心嵌入到她的两个角色嵌入中,两个角色为生产者和消费者的角色,其公式如下:
其中
步骤3:用偏置矩阵因子法构建消费者、生产者及产品的三元交互模型;
通过用户对产品的偏好和对产品生产者的欣赏程度的总和来模拟用户的消费行为,其公式如下:
其中xui表示用户给产品的预测得分,α表示全局偏置项,βu和βi分别表示用户和产品的偏置项,γi表示产品的潜在向量表示;
步骤4:在提出的偏好预测模型上,采用贝叶斯个性化排序bpr框架学习所有参数;
bpr是基于矩阵分解的一种排序算法,bpr定义了偏好评分之间的差异,其公式如下:
xuij=xui-xuj
其中xuij表示偏好评分之间的差异,xui表示用户u对感兴趣产品i的评分,xuj表示用户u对不感兴趣产品j的评分;
步骤5:通过最大化后验来优化排名,用随机梯度下降sgd训练模型直到收敛,初始化收敛参数;
损失函数通常作为学习准则与优化问题相联系,即通过最小化损失函数求解和评估,其公式如下:
其中lbpr表示使用bpr优化的损失函数,σ(·)表示sigmoid激活函数,β表示正则化超参数,
步骤6:对输入参数施加加性扰动,所述输入参数包括消费者、生产者和产品;
对抗性训练可以提高推荐模型的有效性,以改善ugc的推荐模式,通过这种方法,将模型训练得到不那么容易受到对抗性干扰,可以提高模型的鲁棒性(预测用户生成的偏好),其公式如下:
其中δu表示对用户的对抗性扰动,δi表示对产品的对抗性扰动。
步骤7:在施加了对抗扰动的模型上,重复步骤4;
步骤8:采用施加了对抗扰动的最小化损失函数,在初始化收敛参数基础上,用随机梯度下降sgd训练模型直到收敛;
为了获得对对抗扰动不太敏感的模型,除了最小化原始bpr损失之外,还应最小化对手的目标函数,其公式如下:
其中θ*表示对抗模型的优化函数,lbpr′表示施加了扰动的优化函数,
消费者和生产者协同推荐是一种最先进的用户生成内容推荐方法,容易受到输入参数的对抗性扰动的影响。有目的的输入扰动参数显示了模型性能的优缺点。通过训练和学习具有不同通用sgd的新的对抗性训练推荐模型,本发明获得更好的参数,这使得模型更加稳健和有效。两个用户生成内容平台的广泛结果证明了我们方法的有效性。
以上所述仅为本发明的实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!