恶意网页识别模型、识别模型建立方法、识别方法及系统与流程
本发明属于恶意网页识别技术领域,具体涉及一种恶意网页识别模型、识别模型建立方法、识别方法及系统。
背景技术:
黑名单技术是恶意网址发现算法中最传统、最经典的技术,网页黑名单中包含已知的恶意网址列表,通常是由具有公信力的网站根据用户举报、网页内容分析等手段生成并发布。当用户浏览某一网址时,基于网页黑名单的数据库就开始进行搜索。如果这个网址在网页黑名单库中,它就会被认为是恶意网址,浏览器会出现警告信息;否则认为此网址是正常网址。在网址生成算法成熟的现在,每天都会有大量的恶意网址出现,黑名单技术不能够及时更新所有的恶意网址。因此,黑名单技术只能给与用户最低程度的保护,并不能及时检测出恶意网站,阻断用户对恶意网站的访问。虽然黑名单技术有着漏判严重、更新时效性低等缺点,但是其简单易用,因此仍是许多杀毒系统常用的技术之一。
启发式算法是对黑名单技术的一种补充算法,其主要原理是利用从恶意网址中发现的黑名单相似性规则来发现并识别恶意网页。此算法可以依靠现有的启发式规则识别(已有的以及部分之前未出现的)恶意网页,而不需要依靠黑名单的精确匹配来完成恶意网页识别。但是,这种方法只能为有限数量的相似恶意网页而设计,并不能针对所有的恶意网页,而且恶意网页要绕过此类的模糊匹配技术并不难。moshchuk等人提出了一种更具体的启发式方法,这些方法通过分析网页的执行动态,比如并不寻常的过程创建、频繁的重定向等寻找恶意网页的签名。但是启发式算法有比如误报率高以及规则更新难等一些众所周知的缺点。
机器学习算法是目前研究的热点之一,此类算法通过分析网页url以及网页信息,提取域名的重要特征表示,并训练出一个预测模型。目前用于恶意网页识别的机器学习算法主要分为无监督算法和有监督算法。有监督算法也叫分类算法,此类算法需要大量的已标注恶意/良性的网页地址作为训练集,抽取网页特征,然后利用现有的分类算法(svm、c5.0、决策树、逻辑回归等)进行恶意网页识别。有监督学习算法首先要对所有标注url的信息进行特征提取(域名特征、注册信息、生存时间等),然后从中选择出能够区别恶意/良性url的特征,之后再利用分类算法进行建模分析。此算法的准确率较高而且误报率相对较低,但是却对标注数据以及特征工程比较敏感,标注数据的准确率以及选择使用的特征会严重影响算法的准确率和效率。
无监督机器学习方法又称聚类方法。此类方法的具体分类过程主要由特征提取、聚类、簇标记和网页判别等步骤组成。主要做法是首先将url数据集划分为若干簇,使得同一簇的数据对象之间相似度较高,而不同簇的数据对象之间的相似度较低。然后通过构造和标记数据集中的簇来区分恶意网页和良性网页。
但由于恶意网页数据集少,大部分识别恶意网页的方法都基于学习正常的网页内容数据,做单分类的检测,建立单分类模型,如有恶意网页数据送入模型,即可识别是否属于正常网页,如果不属于,即识别为恶意网页。
技术实现要素:
为了解决上述技术问题,本发明提供一种恶意网页识别模型、识别模型建立方法、识别方法及系统,解决现有恶意网页识别方法中,恶意网页数据少,只能通过学习正常网络数据模型,从而使得模型分类结果不准确的问题。
本发明是这样实现的,提供一种恶意网页识别模型的建立方法,包括如下步骤:
1)使用爬虫工具在网络中进行爬虫,将爬取到的网页内容数据样本人为鉴别,分为恶意网页内容数据样本和正常网页内容数据样本;
2)基于恶意网页内容数据的页面内容特征,构建恶意网页的网页特征,基于正常网页内容数据的页面内容特征,构建正常网页的网页特征;
3)使用smote算法使恶意网页内容数据样本翻倍;
4)使用gan算法对翻倍后的恶意网页内容数据样本进行增强,使恶意网页内容数据样本数量与正常网页内容数据样本数量均衡;
5)将增强后的恶意网页内容数据样本与正常网页内容数据样本合并后随机划分为三个部分,即训练集、测试集和验证集;
6)利用训练集和测试集训练5个分类器,即5层隐藏层ann、随机森林、svm、logistic回归以及带权重的knn,利用5个分类器分别循环迭代,保留每个分类器f1值最高的,即对应生成5个模型,分别设为mdl_ann、mdl_rm、mdl_svm、mdl_logistic和mdl_wknn,分别设每个模型的初始权重为1/5,使用5个模型对训练分类器过程中产生的新的数据集进行预测,将预测结果使用下式形成初始融合模型:
1/5*mdl_ann.predict+1/5*mdl_rm.predict+1/5*mdl_svm.predict+1/5*mdl_logistic.predict+1/5*mdl_wknn.predict;
7)利用验证集的数据样本,对初始融合模型进行权重调节,得到最高准确率的识别模型,用于恶意网页的识别。
进一步地,所述步骤2)中,根据如下页面内容特征来构建恶意网页的网页特征和正常网页的网页特征:
文档代码内执行程序的数量、隐藏的可执行远程代码出现的次数、不匹配的link标签出现的次数、页面中含有链接的数量、网页中的图片内容是否具有黄色暴力赌博游戏的内容、image标签数量、script标签数量、embed标签数量、object标签数量、window.open函数个数、document.location函数个数、document.cookie函数个数、windows.location函数个数;
每个恶意网页内容数据样本由恶意网页的网页特征代表,每个正常网页内容数据样本由正常网页的网页特征代表。
进一步地,所述步骤3)中,使用smote算法使恶意网页内容数据样本翻倍的方法为:
301)设恶意网页内容数据样本数量为t,取恶意网页内容数据的1个样本,设为i,样本i用特征向量xi表示,i∈{1,……,t}:
302)从t个样本中找到样本xi的k个近邻,表示为xi(near),near∈{1,……,k};
303)从k个近邻中随机选择一个样本xi(nn),再生成一个0-1之间的随机数ζ1,合成一个新样本xi1,xi1=xi+ζ1*(xi(nn)-xi);
304)将步骤303)重复进行n次,形成n个新样本,xinew,new∈{1,……,n};
305)对全部t个样本进行步骤302)至步骤304),得到nt个新样本,即对t个样本翻了n倍。
进一步地,所述步骤4)中,采用wgan-gp网络对翻倍后的恶意网页内容数据样本进行增强,使恶意网页内容数据样本数量与正常网页内容数据样本数量均衡。
进一步地,所述步骤5)中,训练集、测试集和验证集的比例分别为70%、20%和10%。
进一步地,所述步骤7)中,对初始融合模型进行权重调节的方法为:
将步骤5)中的验证集数据分别输入到步骤6)训练的5个分类器的模型中,进行分类,得到五个准确率,按高低排序,排序最高的分类器权重值增加0.1,相应的排序最低的分类器减去0.1,循环迭代30次,输出权重调节后最高准确率的模型,用于恶意网页的识别。
本发明还对上述恶意网页识别模型的建立方法建立的恶意网页识别模型进行保护。
本发明还提供一种利用上述的恶意网页识别模型识别恶意网页的方法,包括如下步骤:
a)获取用户正在访问的网页的网页特征,利用网页特征来代表该网页,网页特征可以是一个或多个;
b)将获取到的用网页特征代表的该网页向量输入到上述方法建立的模型中,输出结果,判定该网页是正常网页还是恶意网页;
c)若为恶意网页,则通过前端弹窗告知用户。
本发明还提供一种识别恶意网页的系统,包括如下模块:
网页特征获取模块,用于获取用户正在访问的网页的网页特征,利用网页特征来代表该网页,网页特征可以是一个或多个;
网页识别模块,用于将获取到的用网页特征代表的该网页向量输入到上述方法建立的模型中,输出结果,判定该网页是正常网页还是恶意网页;
弹窗模块,用于将恶意网页的输出结果通过前端弹窗告知用户。
与现有技术相比,本发明的优点在于:
1)通过smote算法和gan算法对恶意网页的样本数量进行翻倍,在恶意网页样本数据与正常网页样本数据能够基本均衡的情况下建立模型,准确率高;
2)并不是选择出一个单一的模型来进行恶意网页的识别,而是通过对生成的5个模型进行融合,并且对不同模型的权重进行调整,得到最终的识别模型,能够避免用单一模型进行结果输出带来的误差,同样能够提高准确率。
附图说明
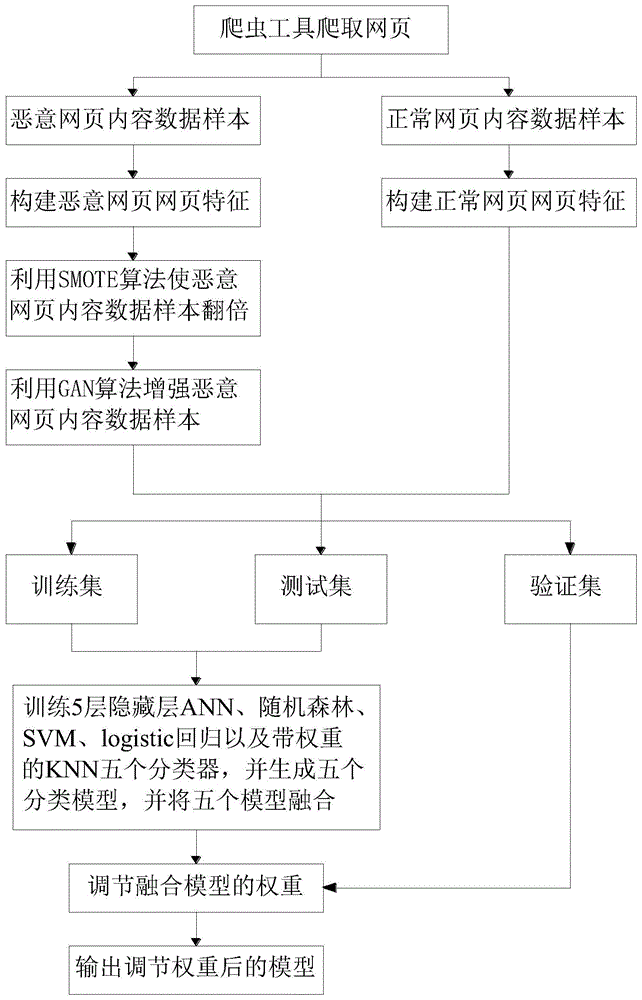
图1为本发明提供的恶意网页识别模型的建立方法流程图;
图2为利用本发明建立的恶意网页识别模型进行恶意网页识别的流程图;
图3为本发明提供的恶意网页识别系统图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图和实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
参考图1,本发明提供一种恶意网页识别模型的建立方法,包括如下步骤:
1)使用爬虫工具在网络中进行爬虫,将爬取到的网页内容数据样本保存到本地,通过人为鉴别,分为恶意网页内容数据样本和正常网页内容数据样本;
爬虫工具是一种按照一定的规则,自动的抓取万维网信息的程序或者脚本。在利用爬虫工具抓取网页内容数据样本时,先设置抓取条件或者抓取任务和抓取的样本数量,抓取条件或抓取认为的设置可以根据未来定向用户对恶意网页识别的要求进行设置,即不同类型的用户对恶意网页的判别是不同的,例如某类用户会认为产品推销类网页是恶意网页,而需要该类产品的用户则会认为这类网页是正常网页,另外,样本的数量需要足够大才能具有代表性,但是在爬虫工具抓取完网页内容数据样本后,需要进行人为鉴别,来区分恶意网页内容数据样本和正常网页内容数据样本,所以,样本的数量又不能设置的过于大,导致后续人为鉴别的过程过于繁琐,所以,在本发明提供的模型建立方法中,根据建立模型的需求以及后续人为鉴别的难度两个因素来确定需要爬虫工具爬取的样本数量,爬虫工具的网页抓取端根据条件或任务和目标样本数,可以在浏览网页的过程中随意抓取或者可以预先设定某类用户经常认定的恶意网页的ip,让爬虫工具进行有目标的抓取,抓取后将网页内容数据样本(也就是网页页面上的显示内容)保存在本地即可。
在爬虫工具按照任务和目标样本数量抓取完网页内容数据后,在人为鉴别的过程中,恶意网页的人为鉴别原则即根据常规认知,网页内容上存在恶意信息(比如博彩、黄色、暴力等信息)的,即可人为认定为恶意网页。
2)基于恶意网页内容数据的页面内容特征,构建恶意网页的网页特征,基于正常网页内容数据的页面内容特征,构建正常网页的网页特征;
根据如下页面内容特征来构建恶意网页的网页特征和正常网页的网页特征:
文档代码内执行程序的数量:所有扩展名中代表可以执行程序的有很多(如.exe、.tmp、.ini、.dll等),若页面中包含其中一种可执行程序,那么这个页面极有可能是恶意网页。
隐藏的可执行远程代码出现的次数:运行恶意命令的代码通常隐藏在path代码中。
不匹配的link标签出现的次数:利用不匹配标签,恶意页面中经常被隐式插入url地址,将当前页面转向其他海外的域名网页;
页面中含有链接的数量:经过分析采集样本,某些恶意网页嵌入链接数量很多;
网页中的图片内容是否具有黄色暴力赌博游戏的内容:利用训练好的cnn网络进行分类识别网页中的图片,恶意网页多数会具备以上内容的图片;
训练所使用的网络为alexnet,其中整个网络结构由5个卷积层和3个全连接层组成,深度总共8层。并采用通过imagenet数据库训练好的数据设置为迁移学习模型。使用cnn训练好的网络识别图片时,返回值为识别到哪一类的概率。故在此特征中,将得到识别为暴力图像的概率,识别为黄色图像的概率,识别为游戏图像的概率,识别为赌博图像的概率。
还有image标签数量、script标签数量、embed标签数量、object标签数量、window.open函数个数、document.location函数个数、document.cookie函数个数、windows.location函数个数;
每个恶意网页内容数据样本由恶意网页的一个或多个网页特征代表,每个正常网页内容数据样本由正常网页的一个或多个网页特征代表。
3)使用smote算法使恶意网页内容数据样本翻倍;
由于恶意网页内容数据样本的数量远远小于正常网页内容数据样本的数量,为了使结果更加准确,本发明使用smote算法使恶意网页内容数据样本翻倍,具体方法为:
301)设恶意网页内容数据样本数量为t,取恶意网页内容数据的1个样本,设为i,样本i用特征向量xi表示,i∈{1,……,t}:
302)从t个样本中找到样本xi的k个近邻,表示为xi(near),near∈{1,……,k};
303)从k个近邻中随机选择一个样本xi(nn),再生成一个0-1之间的随机数ζ1,合成一个新样本xi1,xi1=xi+ζ1*(xi(nn)-xi);
304)将步骤303)重复进行n次,形成n个新样本,xinew,new∈{1,……,n};
305)对全部t个样本进行步骤302)至步骤304),得到nt个新样本,即对t个样本翻了n倍。
如果样本的特征维数是2维,那么每个样本都可以用二维平面上的一个点来表示。smote算法所合成出的一个新样本xi1相当于是表示样本xi的点和表示样本xi(nn)的点之间所连线段上的一个点,所以说该算法是基于“插值”来合成新样本。
4)使用gan算法对翻倍后的恶意网页内容数据样本进行增强,使恶意网页内容数据样本数量与正常网页内容数据样本数量均衡;采用wgan-gp网络对翻倍后的恶意网页内容数据样本进行增强,使恶意网页内容数据样本数量与正常网页内容数据样本数量均衡。
gan进行数据扩增的原理是通过向生成器中输入真实数据,通过wgan-gp网络,输出一个高维向量,再将此高维向量输入到判别器中进行判别,判别器输出一个标量,标量越大,代表向判别器中输入的越接近真实数据。通过此方法来对经过翻n倍的恶意网页内容数据样本进行扩增,使其最终与正常网页内容数据样本数量均衡。
wgan-gp网络是wgan网络的改进版本,解决了wgan实现方式存在两个严重的问题:
1、判别器的loss希望尽可能拉大真假样本的分数差,实验发现基本上最终权重集中在两端,这样参数的多样性减少,会使判别器得到的神经网络学习一个简单的映射函数,是巨大的浪费;
2、很容易导致梯度消失或者梯度爆炸,若把clippingthreshold设的较小,每经过一个网络,梯度就会变小,多级之后会成为指数衰减;反之,较大,则会使得指数爆炸。这个平衡区域可能很小。
也就是说,wgan-gp使用梯度惩罚的方法替代权值剪裁,为了满足函数在任意位置上的梯度都小于1,可以考虑根据网络的输入来限制对应判别器的输出。对此更新目标函数,添加惩罚项,对于惩罚项中的采样分布,它的范围是真实数据分布与生成数据分布中间的分布。具体的实践方法是在真实数据分布和生成数据分布各进行一次采样,然后这两个点连线上再做一次随机采样,就是我们要的惩罚项。因此,wgan-gp的效果比wgan的效果更好。
5)将增强后的恶意网页内容数据样本与正常网页内容数据样本合并后随机划分为三个部分,即训练集、测试集和验证集;训练集、测试集和验证集的比例分别为70%、20%和10%。
6)利用70%的训练集和20%的测试集训练5个分类器,随机化训练数据集(50次),每次生成一种抽取训练数据集、测试数据集序列,并按照训练生成训练集与测试集,训练出5个分类器,即5层隐藏层ann、随机森林、svm、logistic回归以及带权重的knn,利用5个分类器分别循环迭代,保留每个分类器f1值最高的,即对应生成5个模型,分别设为mdl_ann、mdl_rm、mdl_svm、mdl_logistic和mdl_wknn,分别设每个模型的初始权重为1/5,使用5个模型对训练分类器过程中产生的新的数据集进行预测,将预测结果使用下式形成初始融合模型:
1/5*mdl_ann.predict+1/5*mdl_rm.predict+1/5*mdl_svm.predict+1/5*mdl_logistic.predict+1/5*mdl_wknn.predict;
7)利用验证集的数据样本,对初始融合模型进行权重调节,得到最高准确率的识别模型,用于恶意网页的识别,对初始融合模型进行权重调节的方法为:
将步骤5)中的验证集数据分别输入到步骤6)训练的5个分类器的模型中,进行分类,得到五个准确率,按高低排序,排序最高的分类器权重值增加0.1,相应的排序最低的分类器减去0.1,循环迭代30次,输出权重调节后最高准确率的模型,用于恶意网页的识别。
参考图2,利用上述的恶意网页识别模型识别恶意网页的方法,包括如下步骤:
a)获取用户正在访问的网页的网页特征,利用网页特征来代表该网页,网页特征可以是一个或多个;
此处的网页特征即上述方法中提到的文档代码内执行程序的数量、隐藏的可执行远程代码出现的次数、不匹配的link标签出现的次数、页面中含有链接的数量、网页中的图片内容是否具有黄色暴力赌博游戏的内容、image标签数量、script标签数量、embed标签数量、object标签数量、window.open函数个数、document.location函数个数、document.cookie函数个数、windows.location函数个数,通过这些特征,来建立代表网页的向量。
b)将获取到的用网页特征代表的该网页向量输入到上述方法建立的模型中,输出结果,判定该网页是正常网页还是恶意网页;
c)若为恶意网页,则通过前端弹窗告知用户。
参考图3,本发明还提供一种识别恶意网页的系统,包括如下模块:
网页特征获取模块,用于获取用户正在访问的网页的网页特征,利用网页特征来代表该网页,网页特征可以是一个或多个;
此处的网页特征即上述方法中提到的文档代码内执行程序的数量、隐藏的可执行远程代码出现的次数、不匹配的link标签出现的次数、页面中含有链接的数量、网页中的图片内容是否具有黄色暴力赌博游戏的内容、image标签数量、script标签数量、embed标签数量、object标签数量、window.open函数个数、document.location函数个数、document.cookie函数个数、windows.location函数个数,通过这些特征,来建立代表网页的向量。
网页识别模块,用于将获取到的用网页特征代表的该网页向量输入到上述方法建立的模型中,输出结果,判定该网页是正常网页还是恶意网页;
弹窗模块,用于将恶意网页的输出结果通过前端弹窗告知用户。
- 还没有人留言评论。精彩留言会获得点赞!