一种卷积神经网络加速器的制作方法
本发明涉及电子信息与深度学习领域,尤其是一种卷积神经网络加速器。
背景技术:
近年来,卷积神经网络(cnn)引起了广泛的关注,推动着人工智能领域的高速发展,并取得巨大成功,其中以alphago/alphazero为典型代表。如今,以cnn为基础的深度学习吸引了来自工业界和学术界的目光,在多个领域得到应用,包括图像检测、目标识别和自然语言处理等。
神经网络具有巨大的计算量和访存次数,传统的通用处理器面对如此巨大的运算显得捉襟见肘。一种针对cnn的专用处理器—cnn加速器应运而生。业界和学术界不断提出新的架构,以期得到具有高能效比的cnn加速器。然而目前的cnn加速器设计都是基于同步方法学的,时钟信号是不可缺少的。随着电路规模的增大,系统本身的时钟网络也将变得更加复杂。加速器在时钟网络所消耗的功耗急剧上升,已有加速器时钟网络功耗的占比甚至达到了40%以上,导致加速器本身的能效降低。
技术实现要素:
为了解决至少一个上述技术问题,本发明的目的在于提供一种卷积神经网络加速器。
本发明所采取的技术方案是:本发明实施例包括一种卷积神经网络加速器,包括卷积模块、激活模块、池化模块、结果处理模块、控制模块和片内存储器;各个所述模块之间通过异步握手的方式完成数据通信的同步化;
所述卷积模块包括卷积计算单元,所述卷积模块用于读取片内存储器的权重数据和特征数据,并进行卷积计算,所述权重数据和特征数据以两级脉动的方式在所述卷积计算单元之间流动;
所述激活模块用于对所述卷积模块的卷积计算结果进行非线性处理,结果送入所述池化模块;
所述池化模块用于对所述激活模块的处理结果进行池化处理;
所述结果处理模块,用于根据控制信号将所述激活模块处理后的结果和/或所述池化模块处理后的结果送到片内存储器进行缓存;
所述控制模块,用于控制各个所述模块的工作。
进一步地,所述卷积模块包含至少一个卷积层,每个所述卷积层是由多个卷积计算单元组成的卷积运算阵列,所有卷积计算单元完成一轮卷积计算后,所述卷积模块的各个卷积层以列为单位将卷积计算的结果送到所述激活模块和所述池化模块依次处理。
进一步地,所述卷积模块中的每一个卷积层对应一个激活模块中的激活层和一个池化模块中的池化层;所述卷积层的计算结果将被送到对应同一层的所述激活层和所述池化层和依次处理。
进一步地,所述卷积层的计算结果经激活模块进行非线性处理后,送入所述池化模块进行池化处理,所述结果处理模块根据控制信号将所述池化模块处理后的结果送到片内存储器进行缓存;当检测到不用进行池化处理,所述控制模块使所述池化模块处于关闭模块,所述结果处理模块根据控制信号将所述激活模块处理后的结果送到片内存储器进行缓存。
进一步地,所述卷积计算单元包含一个bit-serial乘法器,所述乘法器采用流水线微结构,展开为七级流水线乘法器。
进一步地,所述卷积计算单元还实行部分和的累加计算,并将每次累加计算后的结果保存在所述卷积计算单元中。
进一步地,在所述异步握手过程中,采用四相双轨异步握手协议,并采用双轨方式对各模块的数据进行编码,以同步各个所述模块之间的数据传递。
进一步地,所述异步握手过程具体为:
数据发送端发送有效数据,以表示一次请求;
数据接收端接收并处理所述数据后,向数据发送端返回一个高电平的应答信号,以表示完成此次请求;
所述数据发送端接收到所述应答信号后,向数据接收端发送空的数据,以表示准备下一次请求;
所述数据接收端接收到空的数据后,返回一个低电平应答信号,以表示可以开始下一次的请求。
进一步地,所述异步握手过程是由数据发送端发起数据请求,而接收端返回应答信号。
进一步地,所述数据请求和所述应答信号通过推通道传送。
本发明的有益效果是:本发明所述的加速器通过采用两级脉动阵列运算架构,实现加速器内权重数据及特征数据的复用,又使卷积计算边界处的卷积计算单元(pe)能尽早开始工作,提高加速器在边界处的卷积计算单元(pe)利用率;卷积计算单元(pe)内部的bit-serial乘法器引入流水线微结构,展开为七级流水线乘法器,避免了卷积计算单元(pe)因为乘法运算导致的数据流停滞的出现,进一步提高加速器的计算并行度;加速器使用异步握手信号取代全局时钟信号,从根源上消除时钟网络的功耗,从而降低系统的总功耗,提高加速器的能效比,而且由于没有时钟信号,不需要进行时序分析,系统具有更好的可扩展性;此外,异步电路的等效工作频率是由电路中各级流水线的平均时延决定的,与同步电路相比具有相对较好的性能。将异步电路设计方法学应用于cnn加速器,能够得到更高能效比的cnn加速器。
附图说明
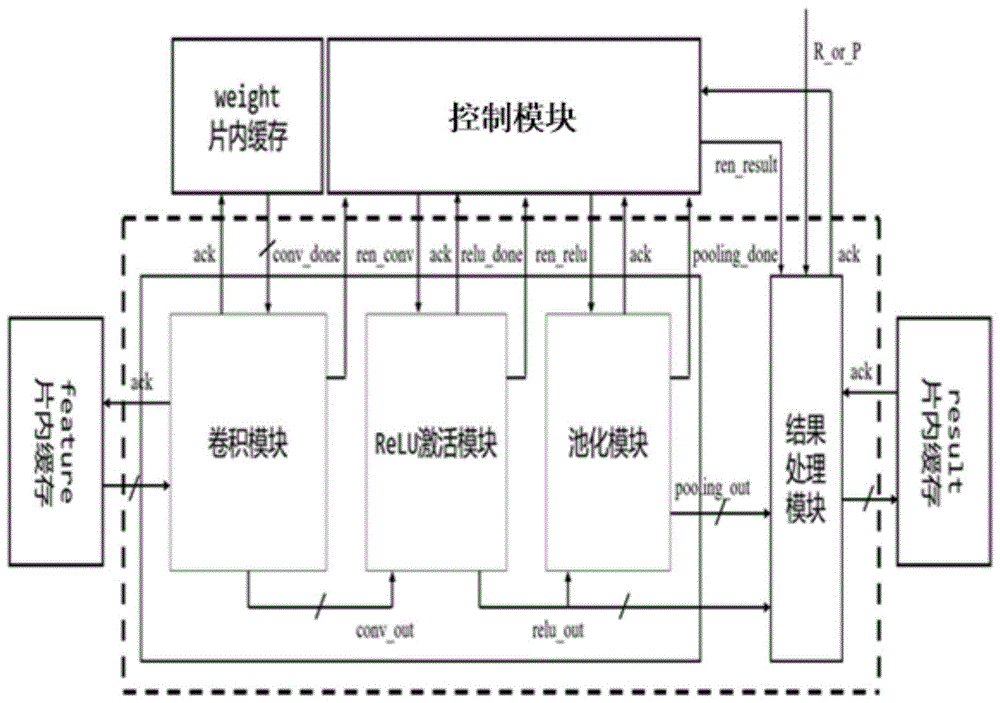
图1为本发明实施例所述卷积神经网络加速器的结构示意图;
图2为本发明实施例所述卷积模块的数据流示意图;
图3为本发明实施例所述卷积计算单元的结构示意图;
图4为本发明实施例所述四相双轨握手通信示意图、数据编码真值表、握手时序图和状态转换图;
图5为本发明实施例所述异步握手过程示例示意图。
具体实施方式
本实施例中,所述卷积神经网络加速器,包括卷积模块、激活模块、池化模块、结果处理模块和控制模块;各个所述模块之间通过异步握手的方式完成数据通信的同步化;
所述卷积模块包括卷积计算单元,所述卷积模块用于读取片内存储器的权重数据和特征数据,并进行卷积计算,所述权重数据和特征数据以两级脉动的方式在所述卷积计算单元之间流动;
所述激活模块用于对所述卷积模块的卷积计算结果进行非线性处理,结果送入所述池化模块;
所述池化模块用于读取所述激活模块的处理结果,并对所述处理结果进行池化处理;
所述结果处理模块,用于根据控制信号将所述激活模块处理后的结果和/或所述池化模块处理后的结果送到片内存储器进行缓存;
进一步地,所述卷积模块包含至少一个卷积层,每个所述卷积层是由多个卷积计算单元组成的卷积运算阵列,所有卷积计算单元完成一轮卷积计算后,所述卷积模块的各个卷积层以列为单位将卷积计算的结果送到所述激活模块和所述池化模块依次处理。
所述卷积模块中的每一个卷积层对应一个激活模块中的激活层和一个池化模块中的池化层;所述卷积层的计算结果将被送到对应同一层的所述激活层和所述池化层和依次处理。
所述卷积层的计算结果经激活模块进行非线性处理后,送入所述池化模块进行池化处理,所述结果处理模块根据控制信号将所述池化模块处理后的结果送到片内存储器进行缓存;当检测到不用进行池化处理,所述控制模块使所述池化模块处于关闭模块,所述结果处理模块根据控制信号将所述激活模块处理后的结果送到片内存储器进行缓存。
本实施例中,卷积模块可以包含一个或多个卷积层,每个卷积层是一个由256个pe组成的16×16的卷积运算阵列;256个卷积计算单元(pe)平均划分为4×4排列的16个阵列簇(cluster);每个阵列簇(cluster)包含16个pe,组成4×4排列的pe阵列;所有卷积层共享相同的weightfifo阵列(16个fifo)的weight数据,而每个卷积层则有单独的featurefifo阵列(16个fifo)提供feature数据。
采用的激活模块为relu激活模块,relu激活模块可以包含一层或多层,层数与卷积层的一致;relu激活模块紧跟在卷积模块后边,对卷积模块的卷积计算结果进行非线性处理;每一层relu激活层包含256个relu运算单元,可同时对同一层的卷积层输出的256个卷积计算结果进行非线性处理;每层激活层的256个relu运算单元分为16列,每一列包含16个relu运算单元,对应卷积层中的一列pe;
池化模块亦可以包含一层或多层,层数与卷积层的层数一致;池化模块紧跟在relu激活模块后面,本发明实施例采用2×2最大池化,对relu激活模块的输出结果降采样;每一层池化层包含64个池化运算单元,池化运算单元读取激活模块的4个计算结果,得到其中的最大值;对于不需要池化的卷积层,控制模块关断relu激活模块向池化模块的数据传输;64个池化运算单元分为16列,每一列包含4个池化运算单元,与relu激活模块中的激活层中的一列对应。
结果处理模块,用于依次读取relu激活模块或池化模块的计算结果,并将其送到片内存储器缓存。池化层中的一列池化运算单元保存的处理结果(8bit×4)和对应的relu激活模块中的激活层中的那列运算单元保存的处理结果(8bit×16)将被送到同一个fifo缓存;选择读取激活层的处理结果还是池化层的处理结果,由片外的控制模块发出的控制信号决定。
如图1所示,图1是本发明实施例所述的卷积神经网络加速器结构示意图,虚线方框为本发明的主体内容,包含卷积计算模块、relu激活模块、池化模块和结果处理模块。卷积神经网络加速器总体工作流程如下:
在加速器开始工作前,需要一个全局初始化信号对卷积神经网络加速器进行初始化。加速器完成初始化后,内部各个模块的数据均处于空状态,异步流动线处于被清空状态,加速器处于等待的状态中。本发明实施例的卷积神经网络加速器采用四相双轨握手协议,加速器是否进入工作状态是由数据进行驱动的。当加速器接收到有效的数据输入时,异步流水线开始工作,加速器进入工作状态。
卷积模块读取片内存储器(weightfifo和featurefifo)的权重数据和特征数据,同时读取卷积计算起点与终点的控制信号。相关数据被读入后,卷积计算单元开始做卷积计算,卷积计算的结果被暂存在卷积计算单元阵列中。进入卷积模块的权重及特征数据和控制信号都是采用双轨编码方式的;卷积模块读取数据后,向片内存储器和控制模块返回一个应答信号。卷积模块中所有卷积计算单元完成计算后,向控制模块传递一个conv_done信号,随后控制模块产生一个ren_conv(读使能信号)给relu激活模块。
relu激活模块接收到ren_conv信号后,读取缓存在卷积计算单元阵列中的卷积计算结果,对结果做非线性处理并缓存relu计算后的结果。激活模块从卷积模块读入的数据是双轨编码的,但一直保持有效状态,借助控制模块产生的ren_conv信号,使这些数据具有空和有效两种状态。激活模块读入ren_conv信号后,返回一个应答信号给控制模块;激活模块计算完成后,传递一个relu_done信号给控制模块;对于不需要做池化操作的卷积层,片外的控制模块选置r_or_p(选通信号)为1,并产生一个ren_result(读使能信号)送到结果处理模块;结果处理模块读取激活模块的计算结果,并逐个将结果缓存到片内存储器;对于需要池化的卷积层,relu激活模块运算完成后,控制模块接收到done信号后则产生一个ren_relu(读使能信号)给池化模块。
池化模块接收到ren_relu信号后,读取缓存在relu激活模块的relu运算单元中的计算结果,处理并缓存池化后的结果。同样地,池化模块从relu激活模块读入的数据是双轨编码且一直保持有效的;而池化模块借助ren_relu信号使这些数据具有空和有效两种状态。池化模块计算完成后,产生一个pooling_done信号给控制;片外控制模块选置r_or_p为0(默认值),并产生一个ren_result信号传给结果处理模块;结果处理模块读取池化模块的计算结果,并逐个缓存到片内存储器。
本实施例中,卷积模块采用两级脉动阵列运算架构,现有的脉动阵列架构,权重和特征在pe阵列中的数据传递只发生在相邻的pe之间。即运算阵列中每个pe只从阵列中位于该pe上方的pe和左边的pe读取数据(位于阵列边界的pe则从fifo中读取数据),再将数据传给该pe下方的pe和右边的pe。采用这种方式实现的脉动阵列架构具有简单、易实现的优点;但是具有大量pe的阵列来说,右下角的pe进入工作状态的时间要远远迟于左上角的pe,并且随着pe数量的增多,这个时间差越明显;现有的cnn加速器正是通过堆叠大量的计算单元(pe)实现硬件加速的,这意味在卷积计算的运算边界处会有较多的pe处于闲置状态,pe利用率低,对于中小规模的网络结构尤其明显。
本发明实施例针对现有脉动阵列的不足,对脉动阵列的运算架构进行改进,提出了两级脉动运算架构。具体的处理方法是,对简单脉动阵列的pe阵列进行划分,若干个空间位置相邻或相近的pe组成一个小规模的阵列。小规模阵列内部的数据流和简单脉动阵列的数据流相同。而在这些小规模阵列之间的一些pe之间搭建数据通路,即阵列中有些pe不仅向相邻的pe传递数据,也向相隔若干个pe距离的pe传递数据,这就是第二级脉动。这样处理后,阵列下方和左边靠后的pe会在更早的时间点进入工作状态,从而改善了简单脉动阵列架构的缺点。
参照图2,权重数据和特征数据在卷积模块的pe阵列中以两级脉动阵列的方式流动,卷积模块中每层卷积层的256个pe分为4×4的阵列簇(cluster)阵列,每个cluster包含16个pe,排列成4×4的cluster阵列。图2所示,阵列最上面一行的16个pe分别与16个weightfifo直接通信,读取数据,并返回应答信号;最左边一列的16个pe分别与16个featurefifo直接通信,读取数据,并返回应答信号。
卷积模块开始工作时,cluster第一行的4个pe从上方的cluster第一行的4个pe或者4个weightfifo(对于处于最上方的cluster)读取权重数据,再将数据送到下方cluster第一行的4个pe。特征数据的流动与权重数据的流动类似,只不过方向改为从左到右,cluster第一列的4个pe从左边cluster第一列的4个pe或者4个featurefifo(对于处于最左边的cluster)读取特征数据,再将数据送到右边cluster第一列的4个pe。cluster中pe数据流类似,pe接收上方pe的权重数据和左边pe的特征数据进行处理,对于最上方的pe或者最左边的pe将接收weightfifo或者featurefifo的数据,再将权重数据送到下方pe,特征数据送到右边pe。数据总是从上到下、从左到右流动的,左边的pe,上方的pe总是先于右边的pe、下方的pe,数据到达各个pe的先后顺序如图2中标示的数字所示。这即是两级脉动阵列运算架构的工作原理,它保持了脉动阵列运算权重数据和特征数据复用的特点,尽可能让数据在运算单元中流动,减少访存的次数,提高系统的吞吐率。引入两级脉动,原本从第一个pe工作或停止工作到所有pe工作或停止工作所需的时间从31次握手(等效于31个clockcycle)减少到13次握手(等效于13个clockcycle),提高了运算边界处卷积模块的pe利用率,从而提高整体的吞吐率。
进一步作为优选的实施方式,所述卷积计算单元包含一个bit-serial乘法器,所述乘法器采用流水线微结构,展开为七级流水线乘法器。
所述卷积计算单元还实行部分和的累加计算,并将每次累加计算后的结果保存在所述卷积计算单元中。
如图3所示,本发明实施例中,卷积计算单元(pe)的结构包含一个基于bit-serial实现的七级流水线乘法器;每个pe包含符号数转为无符号数(s2us)子模块、基于bit-serial实现的七级流水线乘法器、无符号数转为符号数(us2s)子模块及累加器;七级流水线乘法器每一级都由一个移位器和一个加法器组成,也就是说,七级流水线乘法器包含7个移位器和7个加法器,采用流水线微结构,使得每一个pe可以同时处理7组权重数据和特征数据的乘法。该乘法器用以完成两个8bit无符号数的乘法运算,最终结果为一个16bit无符号数。符号数和无符号数的转换由pe中两个转换单元负责。基于bit-serial的乘法器,使用移位和加法实现乘法运算,对于本发明实施例,由于最高位是符号位,因此只需要7次握手(等效于7个clockcycle)。本发明实施例对原来移位和加法实现的bit-serial乘法器的循环展开,实现七级流水线的乘法器,能够避免由于乘法导致数据流停滞的出现,显著提高加速器的数据吞吐率,进一步提高加速器性能;同时由于循环展开,数据只有前向的流动,避免握手信号嵌套,简化异步流水线的出现,避免乘法器内部引入记忆元件。
进一步地,pe既通过乘法器完成乘法计算,同时也能完成部分和的累加计算,并且将每次累加计算后的结果保存在pe中;也就是说,pe既具有运算功能,同时具有存储功能。
进一步作为优选的实施方式,在所述异步握手过程中,采用四相双轨异步握手协议,并采用双轨方式对各模块的数据进行编码,以同步各个所述模块之间的数据传递。
所述异步握手过程具体为:
数据发送端发送有效数据,以表示一次请求;
数据接收端接收并处理所述数据后,向数据发送端返回一个高电平的应答信号,以表示完成此次请求;
所述数据发送端接收到所述应答信号后,向数据接收端发送空的数据,以表示准备下一次请求;
所述数据接收端接收到空的数据后,返回一个低电平应答信号,以表示可以开始下一次的请求。
所述异步握手过程是由数据发送端发起数据请求,而接收端返回应答信号。
所述数据请求和所述应答信号通过推通道传送。
本实施例中,,卷积模块与片内存储器之间、pe和pe之间、卷积模块与激活模块之间、激活模块和池化模块之间的数据传递都通过异步握手处理完成同步化。例如,卷积模块读取片内存储器的权重数据和特征数据时,卷积模块为数据发送端向片内存储器发送数据请求,片内存储器为数据接收端接收所述数据并进行处理后返回一个应答信号;同样地,pe不仅向相邻的pe传递数据,也向相隔若干个pe距离的pe传递数据,例如,当pe向相邻的pe传递数据时,目前的pe作为数据发送端向相邻的pe发送数据请求,相邻的pe作为数据接收端接收所述数据并返回应答性;卷积模块与激活模块之间的数据传递时,卷积模块作为数据发送端发送数据请求,激活模块作为数据接收端接收数据并返回应答信号;而激活模块与池化模块之间的数据传递时,激活模块作为数据发送端发送数据请求,池化模块作为数据接收端接收数据并返回应答信号;也就是说,各模块之间除了前向传递的数据,还有反向传递的应答信号。
本实施例中,采用四相双轨握手协议的异步握手协议。每1bit的数据使用两根位线表示:{01}表示逻辑“0”,{10}表示逻辑“1”,{00}表示无效数据(空状态),{11}是禁止态。双轨编码是准延时不敏感(qdi)编码方式,请求信号被包含在数据当中,因此不需要额外的请求信号线,也不需要对请求信号进行延时匹配。结合数据编码方式和四相握手协议,卷积神经网络加速器的异步握手过程如下:数据发送端发送有效数据,表示一次请求;接收端接收并处理数据后,向发送端返回一个高电平的应答信号,表示完成此次请求;发送端接收到接收端返回的高电平应答信号,向接收端发送空的数据,表示准备下一次数据发送;接收端接收到空的数据后,返回一个低电平应答信号,表示可以开始一次新的请求。采用这种方式实现的卷积神经网络加速器是由数据驱动的,即加速器只在有效数据到达后才进入工作状态。
本发明实施例结合异步电路的设计方法学和两级脉动阵列运算架构两者,提出基于异步的两级脉动计算架构。由于没有同步时钟的存在,同步时钟网络引起的时钟网络功耗也就不存在了。时钟网络功耗占系统功耗的比重随着集成电路规模变大而增加,取消全局时钟可以使得总功耗显著减小。不同于同步卷积神经网络加速器,本发明实施例所述的卷积神经网络加速器异步加速器中各个模块接收到前一级的请求信号和数据就开始工作,并在任务完成后传递请求信号和数据给下一级。数据就这样一级一级地往前传,就像同步流水线一样,每个模块负责一部分工作。异步流水线不仅控制着异步电路各模块之间的异步通信,同时保证计算的并行度。
如图4所示,(a)为四相双轨握手通信示意图,(b)为数据编码真值表,(c)为握手时序图,(d)为状态转换图。本发明实施例采用四相双轨异步握手协议;由于取消了时钟信号,需要引入异步握手方式完成数据通信的同步化。本发明实施例采用双轨方式对数据进行编码,编码规则如图4(b)所示。参照图(a)、(c)、(d),本实施例所述的加速器采用双轨编码不需要提供额外的req(请求信号)线,req信号被包含在数据当中,接收端接收到有效数据就知道发送端发送了一次请求信号。双轨数据编码是一种qdi(准延时不敏感)编码方式,req信号可以认为是实时的,运算单元的动作完全是由数据驱动的。而在在握手协议的选择上,本发明选择了四相握手协议,而不是二相握手协议。一方面二相握手协议很难与双轨数据编码配合使用,电路实现也更复杂,且要同时检测信号的两个边沿,这在ic设计中一般是不推荐的;另一方面,四相握手协议配合双轨数据编码,电路系统具有更好的鲁棒性,同时由于双轨数据具有一个归零的中间态,电路中能够减少毛刺的产生。最终电路中模块间的通信过程如下:数据发送端检测到ack(应答信号)拉低,发送有效的数据;接收端接收到有效的数据,完成数据的处理,将ack(应答信号)拉高,并返回给数据发送端;发送端检测到ack(应答信号)拉高,发送空数据,准备下一次发送;接收端接收到空数据,将ack(应答信号)拉低,并返回给发送端,准备下一次接收数据。
配合异步握手协议,本发明实施例所述的卷积神经网络加速器中的运算单元都是基于双轨逻辑门搭建实现的。双轨逻辑门的逻辑功能与普通的逻辑门相同,区别在于双轨逻辑门处理的是双轨编码后的逻辑值,产生的逻辑输出也是双轨编码的。而且当双轨逻辑门的输入是有效的时,其输出也是有效的;当输入是空的状态时,输出也是空的状态。
如下表1所示,表1为本发明实施例的卷积神经网络加速器所用到的双轨逻辑门真值表。本发明所用到的双轨逻辑门的逻辑功能与普通的逻辑门相同,但其输入和输出均为双轨编码的。当双轨逻辑门的输入均为有效时,其输出也是有效的;而当双轨逻辑门的输入为空时,其输出也为空;当处于其它输入状态时,输出保持不变。这些双轨逻辑门都是由c单元和简单逻辑门实现的。c单元是异步电路的重要组成元件,是一个两输入单输出的电路元件,具有锁存功能。c在两个输入均为“1”时,输出“1”,两个输入均为“0”时,输出为“0”,而在其它输入条件下,输出保持不变。本发明实施例所述的卷积神经网络加速器实现的基本功能单元,如加法器,符号数和无符号数的转换运算单元等,都是基于双轨逻辑门实现的。相应的,这些基本逻辑单元也与双轨逻辑门具有相同的性质,即在输入均为双轨编码的有效数据时,输出也为双轨编码的有效数据;而在输入均为空时,输出也为空;在处于其它输入状态时,其输出也将保持不变。加速器的运算单元使用双轨逻辑门搭建,能够更好地配合所选择的异步握手通信协议。另外运算单元运算时,由于在两个有效的状态之间具有一个空的状态作为过渡态,能够消除竞争冒险的出现,减少毛刺的产生。
表1本发明实施例的卷积神经网络加速器所用到的双轨逻辑门真值表
进一步,如图5所示,图5为异步握手过程示例示意图,采用用了四相双轨握手协议的异步握手协议,四相双轨握手协议结合基于双轨逻辑门实现的功能单元,构成了卷积神经网络加速器的基础。它将作为异步流水线的一级。如图5所示,说明了异步流水线的前一级和后一级是如何进行握手通信的;异步加法器具有输入端口a{a1,a0}、b{b1,b0}、cin{cin1,cin0};输出端口s{s1,s0}、cout{cout1,cout0};sum和carry是异步加法器的具体实现,是基于表1中的双轨逻辑门实现的;在描述握手过程时,将输入端口看作黑盒子,只需要知道他们是a、b和cin的函数即可。在这样的前提下,具体的握手过程如下:①异步全加器接收有效的输入a、b、cin,产生有效的输出sum和carry;②该级电路看到来自下一级电路的应答信号ack[n+1]为低电平,将异步全加器的输出送到本级的输出端,输出s和cout变为有效;③输出端的输出变为有效后,本级将应答信号ack[n]拉高并返回给上一级;④上一级将a、b、cin变为空,异步加法器接收到空的输入,产生空的输出sum和carry;⑤该级电路看到下一级返回的ack[n+1]信号为高电平时,将本级的输出也变为空;⑥本级输出s和cout为空,返回一个低电平的ack[n]应答信号给上一级,准备下一次接收数据;⑦重复上述过程。这样的握手过程,确保电路的数据在被有效利用并不再需要后,才接收新的数据以及发送新的数据,能够保证异步通信的准确性;是构建异步电路原理与具体电路实现的桥梁,提供了具体实现的思路。本发明实施例提所述的卷积神经网络加速器正是使用verilog通过这种异步握手过程实现的。
综上所述,本实施例中的卷积神经网络加速器具有以下优点:
本实施例所述的卷积神经网络加速器采用两级脉动阵列运算架构,实现加速器内权重数据及特征数据的复用,又使卷积计算边界处的卷积计算单元(pe)能尽早开始工作,提高加速器在边界处的卷积计算单元(pe)利用率;卷积计算单元(pe)内部的bit-serial乘法器引入流水线微结构,展开为七级流水线乘法器,避免了卷积计算单元(pe)因为乘法运算导致的数据流停滞的出现,进一步提高加速器的计算并行度;加速器使用异步握手信号取代全局时钟信号,从根源上消除时钟网络的功耗,从而降低系统的总功耗,提高加速器的能效比,而且由于没有时钟信号,不需要进行时序分析,系统具有更好的可扩展性;此外,异步电路的等效工作频率是由电路中各级流水线的平均时延决定的,与同步电路相比具有相对较好的性能。将异步电路设计方法学应用于cnn加速器,能够得到更高能效比的cnn加速器。
以上所述,只是本发明的较佳实施例而已,本发明并不局限于上述实施方式,只要其以相同的手段达到本发明的技术效果,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明保护的范围之内。在本发明的保护范围内其技术方案和/或实施方式可以有各种不同的修改和变化。
- 还没有人留言评论。精彩留言会获得点赞!